¿Dosis de cafeína en Panda 4.0?
Ahora leo que Matt Cutts dice que Panda 4.0 es también una nueva arquitectura, es decir, que a parte de aplicar el filtro para eliminar los resultados de baja calidad que era lo habitual en cada actualización de panda también hay detrás un cambio de arquitectura.

Y no puedo evitar el recordar su similitud con el update de Caffeine, dónde Google aumentó su índice para introducir Universal Search y tener también más dominios dentro de su índice principal, con lo que el long tail fue repartido entre muchos más competidores.

Y es que los síntomas PARECEN que son los mismos:
- Las grandes webs pierden como es el caso de Softonic, segundamano o milanuncios.
- Matt anunció que las pequeñas webs se verían favorecidas

- Afectación en un gran porcentaje de búsquedas, un 7,5%
Así que tal como sucedió con aquella actualización de su infraestructura estos cambios que ha habido serían para quedarse y poco se podría hacer para solucionar el problema si hemos sido afectados por este nuevo update, ya que el problema no es algo que los sites tengan culpa (en términos SEO hablando) sino que es una ampliación del número de sites que compiten por las serps.
Esto es sólo una impresión mia y no sé si algún día lo confirmarán o desmentirán, pero si es realmente un cambio de arquitectura estoy seguro que dentro de poco veremos unos cuantos updates seguidos donde Google regulará un poco los cambios recién hechos y para aprovechar las nuevas opciones que les dara este cambio de arquitectura.
Comentarios
2Lee otros artículos
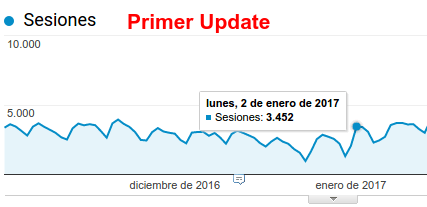
Google comienza el año con dos updates
Publicado por Lino Uruñuela el 23 de febrero del 2017 Este año 2017 ha empezado con movimientos comvulsivos en las gráficas de tráfico orgánico en muchas webs. Yo he notado varios updates de Google y con bastante impacto, vamos a resumirlos un poco. ¿Primer Update del año, 2 de enero? Comenzamos el día 2 de enero con…
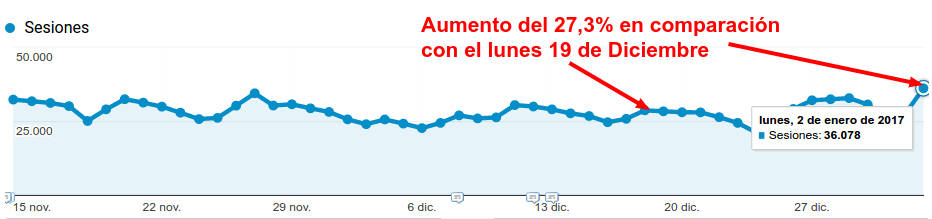
¿Christmas Update?
Publicado por Lino Uruñuela el 3 de enero del 2017, San Sebastián. Google no acostumbra a realizar cambios drásticos cuando llegan fechas críticas para los comercios, como por ejemplo en Navidad, donde se aumentan muchísimo las transacciones por causa de los regalos, y dónde un error podría hacerle perder mucho dinero…
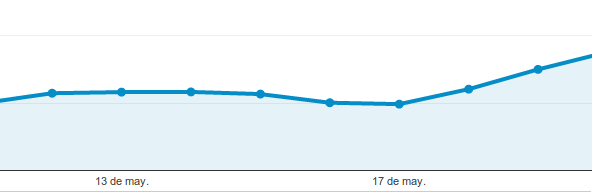
Nuevo Update de Panda, ¿qué ha cambiado?
Publicado por Lino Uruñuela ( Errioxa ) el 21 de mayo del 2014 Hoy nos hemos levantado con la confirmación por parte de Google de dos nuevas actualizaciones en su algoritmo, una Payday Loan Algorithm , que afecta búsquedas spam. Estas búsquedas suelen ser temas de porno de de "cómo ganar dinero" y cosas así y que no d…
El futuro es la búsqueda por voz
Publicado por Lino Uruñuela ( Errioxa ) el 29 de abril del 2014 Hoy he leído que Google Voice se va a extender a muchas más aplicacione de Google y no solo, como hasta ahora, a las búsquedas web (tanto en el móvil como en tablets, o el ordenador de sobremesa). En la cuestión de la búsqueda por voz, en vez de escribién…
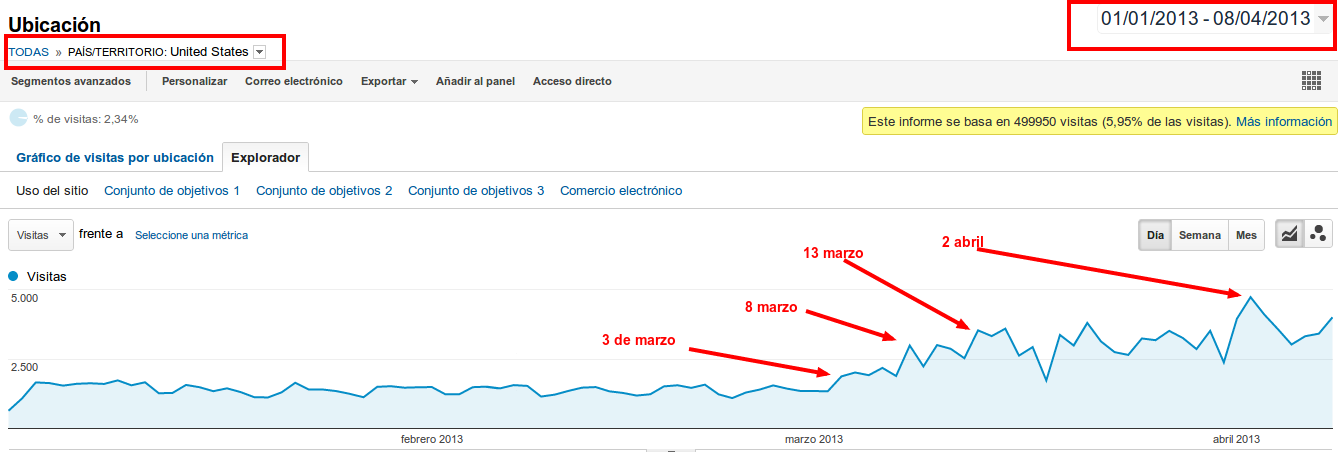
Aumento de visitas desde USA
Publicado el 10 de abril del 2013 by Lino Uruñuela Actualización: Sólo ocurre en el tráfico directo, en tráfico orgánico y tráfico de referencia no ocurre Desde comienzos de este mes de abril he notado algunos cambios en las visitas recibidas, al principio no sabía muy bien ya que coincidía con la Semana Santa y no es…
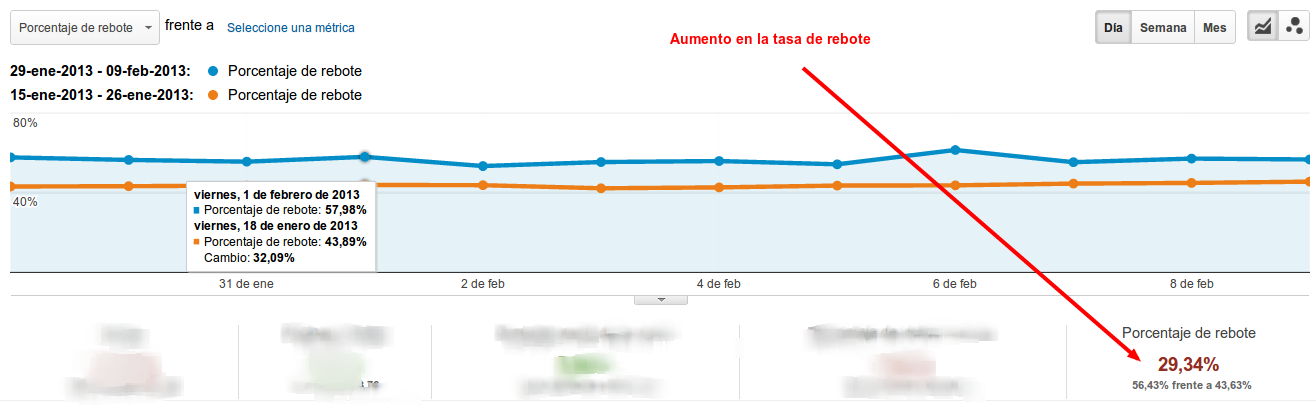
Atrapando al usuario en el nuevo Google Images
Publicado el 10 de febrero del 2013, by Lino Uruñuela ACTUALIZACIóN: El primer código del htaccess que puse al final del artículo tenía algún error. Estoy intentando hacer que funcione siempre, algo va mejorando. En estos momentos tengo así el htaccess, aunque parece que no llega a func ionar del todo . Con Firefox sí…
¿Cómo podría identificar Google las webs SEO?
Publicado el 20 de marzo del 2012 El otro día Matt Cutts comentó que en estas próximas semanas/meses habrá una actualización del algoritmo para identificar las páginas sobreoptimizadas en el aspecto SEO. Se ha comentado en varios sitios como WMT SER o SEL Los puntos que comenta la verdad que no son nada nuevo keyword…
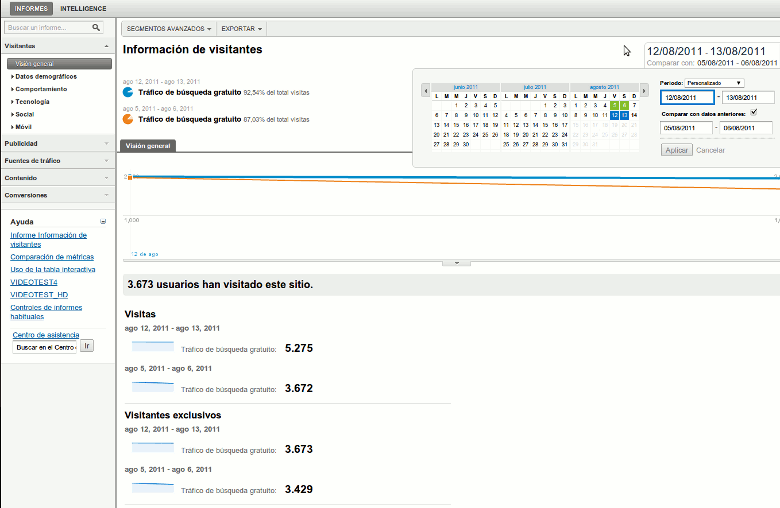
Cómo saber si estás afectado por Google Panda
Publicado el 14 de agosto del 2011, by Lino Uruñuela, Como bien sabemos todos Google lanzó el viernes la nueva actualización Panda . En un primer momento ha habido una euforia general porque todos veíamos como nuestras visitas subían en comparación con días anteriores pero es que Google Analytics ha aprovechado para c…
¿Pre-panda, Google caffeine o un poquito d ambas?
Pulbicado el 19 de junio del 2011 Ya se están viendo cambios en las estadísticas de muchos sites , ¿será Panda 2.2? Y es que el otro día Matt Cuts comentó que la actualización a Panda 2.2 llegará en breve, la verdad es que dijo que no era cosa de semanas sino de meses. Y justo unas semanas después comienza a ocurri es…
Sobre Google Panda
Publicado el 9 de junio del 2011, by Errioxa Nunca un animal había causado tanto miedo entre los negocios de internet, y es que puede llegar a ser muy peligroso si caza y te confunde con bambú. He leído mucho sobre esta actualización de Google, he visto casos, he oído todo tipo de conjeturas, pero no he visto a nadie…
Buena aportación, Añado info al post que hice ayer y te meto un enlace de esos que no se llevan...
Una pregunta ¿qué variables se usan para determinar q un site es pequeño o grande? ¿Cuándo un site es grande? ¿Se dejan de lado los sites medianos?