Intentando comprender Googlebot y los 301
¿Cómo se comportan los crawlers?
Normalmente cuando lanzamos un crawler como Secreaming Frog lo que hace es- Acceder a una url inicial y extraer todos los links que hay
- Anotar los links en su base de datos a modo de cola de proceso, la primera que entra es la primera que crawlea.
- Acceder una a una y por orden a las urls que tiene pendientes de rastrear
¿Cómo se comportará Google?
Pero Google no actúa así, o no en los mismos tiempos. Google cuando descubre una url la añade a su cola de proceso, y será rastreada no en ese mismo momento sino "cuando le toque".Esto depende de muchas cosas, sobretodo, de la autoridad de la url que la enlaza, en cambio crawlers como Screaming acceden a todas las urls por igual, las necesidades de uno y otro son distintas y por eso se comportan de manera diferente.
Una excepción de este comportamiento podría ser en las redirecciones 301, o al menos yo no lo descartaría. Quizás si lo pensamos bien, como si fuésemos quiénes han de diseñar ese proceso, ¿para qué querríamos guardar las urls intermedias que hacen redirección 301?. Almacenarlas por qué sí, pensando que no consume casi recursos, y además, que sale muy barato guardarlas, es ser muy poco exigente con tu proyecto, eso me lo enseñó David.
Lo lógico sería que lo único que guardase y valorase fuesen la url inicial y la url final, las intermedias lo único que hacen es traspasar los datos cuando son redirecciones 301. ¿Para que querrías guardarla en el sistema? implicaría procesarlas como el resto, sabiendo de antemano que tendrá que transferir esos datos a otra url. Y si lo único que hace es transfirir el valor de una a otra, volvemos al punto 1, ¿para qué las va a guardar?.
Las dudas
- ¿Se comportará igual con urls que tienen redirecciones 301?
Es una duda razonable, ya que su comportamiento ante un 301 podría ser distinto, por ejemplo
- Accede a una url inicial y extrae los links
- Añade los enlaces a su cola de procesos
- Cuando toque accederá a la url que hace redirección 301 y ve la url de destino..
- Añade la url de destino a la cola de procesos y accederá a ella cuando toque.
- Accede a una url inicial y extrae los links
- ¿Se comportará de distinta manera?
- Accede a una url inicial y extrae los links
- Añade los enlaces a su cola de procesos
- Cuando toque accederá a la url que hace redirección 301 y ve la url de destino.
- Rastrea la url de destino de la redirección inmediatamente, sin añadirla a su cola de procesos.
- Accede a una url inicial y extrae los links
Y es esto es una pregunta clave, si accediese de manera seguida podría indicar que Google unificará tanto la url que hace redirección como la url de destino, y para él, en su índice interno, estará guardada como un mismo elemento/registro (aunque tenga dos urls posibles) en el cuál los los datos sobre ambas urls recaerá sobre el mismo registro en su índice. Y puede que no guarde esas urls intermedias en su sistema, o puede que sí...
Quizás no actue así, y guarda en su índice cada una de las urls intermedias como una entidad o tupla propia, y que posteriormente, calcula y transfiere esos valores a las urls de destino.
En este caso cabría preguntarnos, ¿las urls con redirección 301 ocupan "sitio" en los índices de Google? ¿es bueno tener miles o cientos de miles de redirecciones que ocupan el sitio que quizás otras urls más eficaces podría ocupar? ¿debemos redireccionar masivamente las urls porque sí, o sería mejor hacerlo solo con aquellas urls que recibían visitas?
EL experimento
Vamos a enlazar a una url que Google no conoce y que no recibe ningún enlace ni de este, ni de otro site, que publicaré como muy tarde la semana que viene. También he creado una réplica de este experimento en otro dominio para asegurarnos que se comportan de la misma manera y no es fruto de uno u otro site.
Crearemos una palabra de señuelo, que no existen resultados en Google
para esa búsqueda, obviamente no la mencionaré en este post, la url a la
que lleva el enlace hace una redirección hacia una tercera url que
tampoco ha sido visitada por Google ni por nadie.
Poniéndolo un poco en orden, tenemos
- Una url inicial, que se la vamos a dar a Google mediante Google
Search Console -> Explorar como Google -> Enviar al índice la URL y las páginas enlazadas .
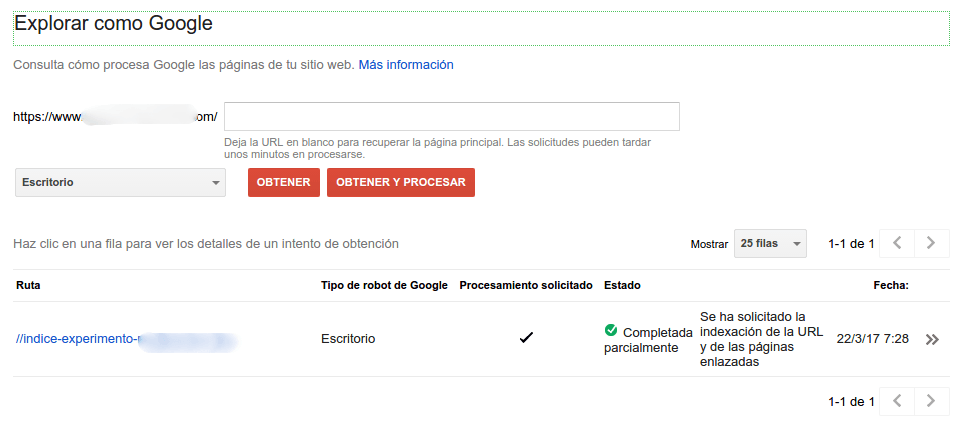
Haciéndolo de esta manera nos aseguramos que todo lo que ocurra en este test no es afectado por otros factores
- Primera
url intermedia, que hará una redirección 301 a la segunda url
intermedia, la cual no ha tenido nunca contenido (la he creado hoy y
solo redirecciona), ni Google la conoce en otro
estado
- Segunda url intermedia, vamos a provocar dos redirecciones consecutivas.
- Url de destino, la cual responderá correctamente, tiene algo de contenido, y es la que debería posicionar Google para la palabra que usamos de señuelo en el enlace de la url inicial del experimento.
¿Que podría ocurrir?
Intentamos averiguar cómo se comporta el bot de Google a la hora de
contabilizar y traspasar valor en las redirecciones 301, y sí, va a ser
difícil sacar algo en claro, pero quién sabe...
Las posibles comportamientos que creo que podrían ocurrir son
- Google comienza en la página inicial, y puede acceder ahora o en
otro momento a la primera url intermedia. En este caso no nos interesa
saber si accede en el mismo momento que rastrea la url de inicio, lo más
seguro es que no, y que la anote en su cola de urls a rastrear cuado
toque, dependiendo esto de muchos factores.
- Cuando Google acceda a la primera url intermedia, ¿accederá
inmediatamente a la url de destino de la redirección? ¿o se comportará
de la misma manera que cuando accede a una url "normal" que se guarda
esa url hacia dónde lleva la redirección para rastrearla cuando toque?
Saber esto es algo interesante, no sé si útil, pero sí interesante, ya que, en MI opinión, si Google accede inmediatamente es muy probable que la url intermedia no la almacene en su sistema y que directamente la hará equivalente a la url de destino de la redirección.
Comprobación de cómo se comporta Google
Para comprobarlo vamos a hacer un seguimiento de los logs de acceso al servidor para saber cuánto tiempo transcurre entre el acceso a las distintas urls.
Realmente pienso que Google hará una equivalencia, o un enlace simbólico de la url que genera la redirección 301 y la url de destino, anotando solo como una ambas urls
Se abren las apuestas!!
Comentarios
4Lee otros artículos
¿Se está impidiendo a los bots de Inteligencia Artificial acceder al contenido?
¿Cómo ha ido incrementando el número de robots.txt en los que aparecen rastreadores asociados a la Inteligencia Artificial?
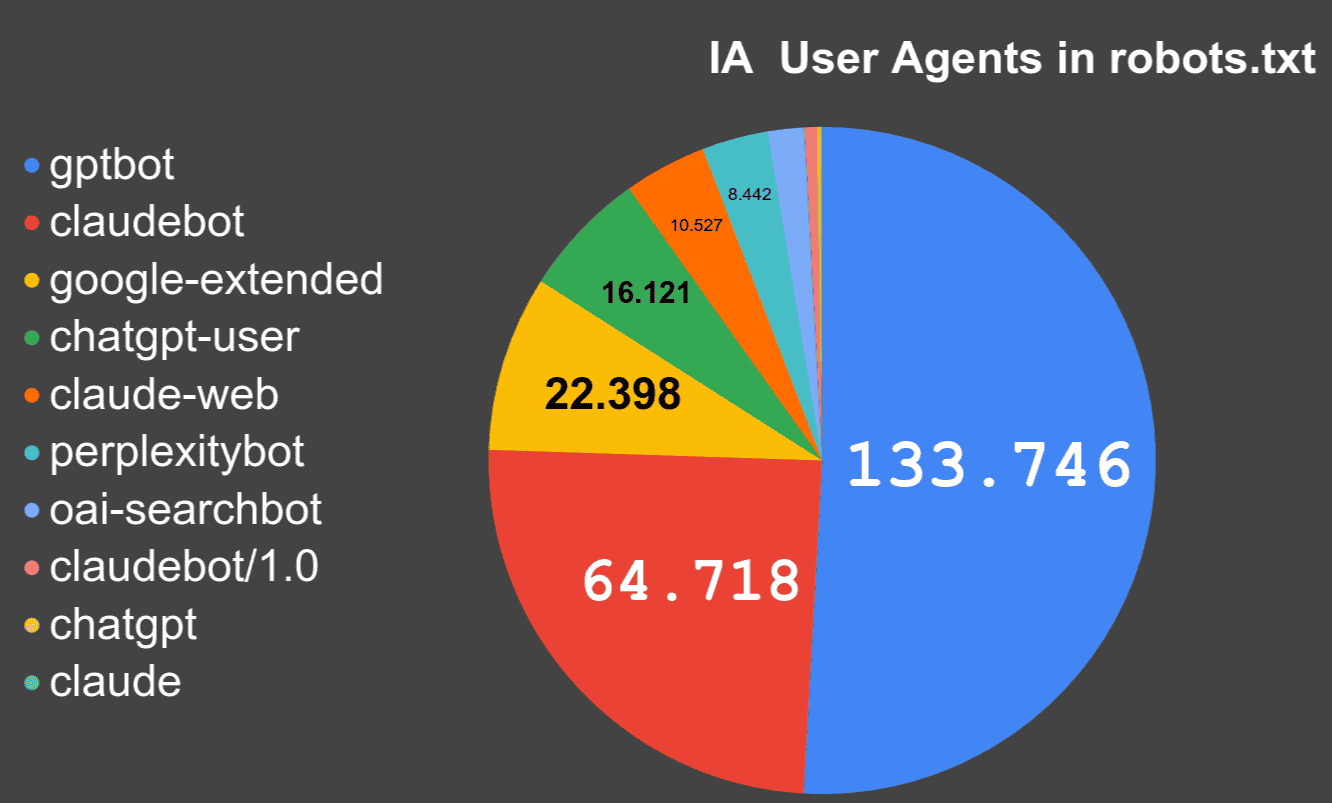
Analizando más de 72 millones de robots.txt
¿Cuántos dominios, subdominios y robots.txt estén bloqueando a los crawlers de Inteligencia Artificial?
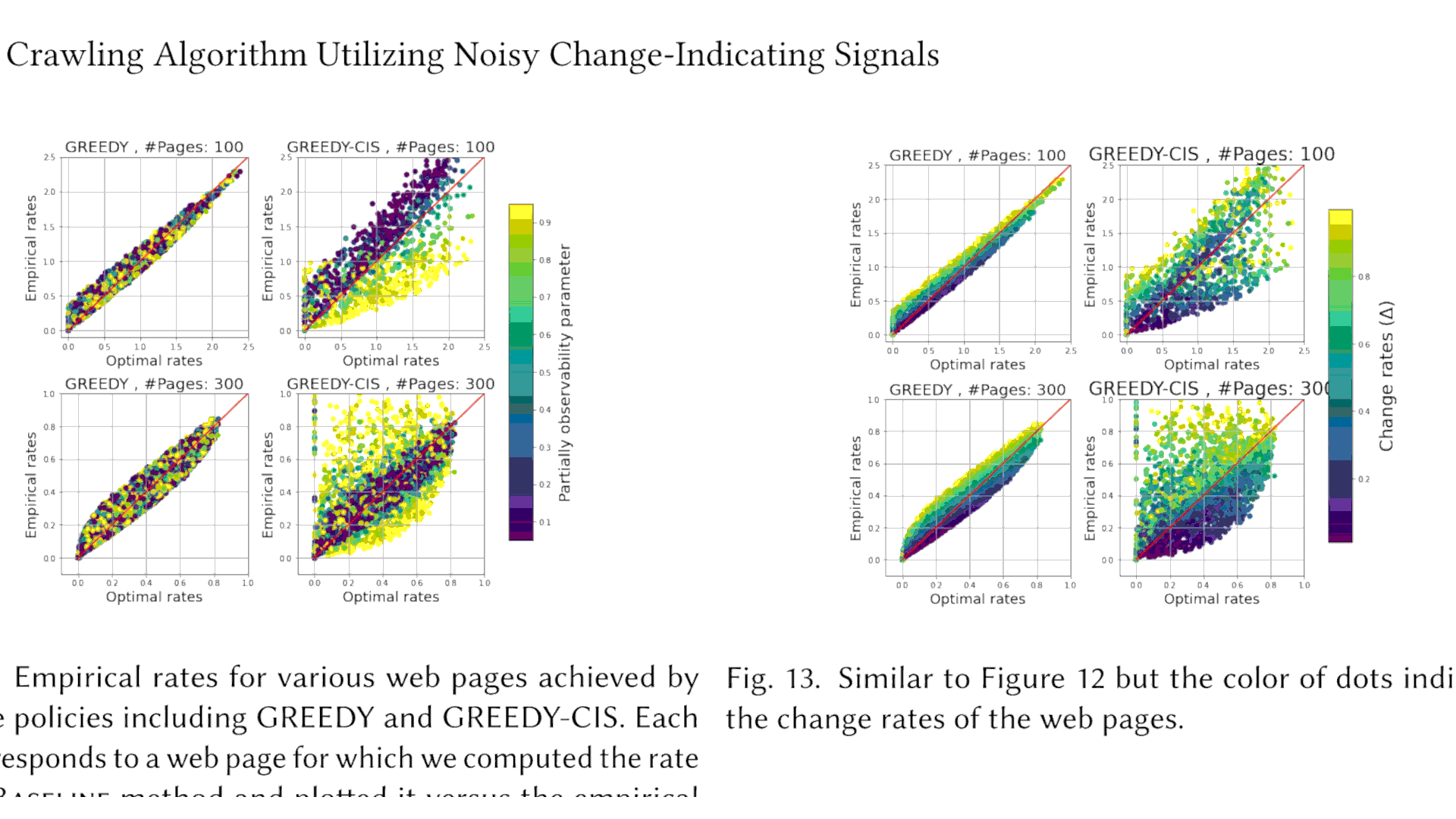
¿Cómo decide Google que URL debe rastrear?
Hoy he descubierto este paper de Google (A Scalable Crawling Algorithm Utilizing Noisy Change-Indicating Signals) dónde describe una mejora del método descrito en el artículo inicial
Búsqueda semántica de contenidos en los vídeos de Youtube
n la segunda parte mostré un caso de uso un poco más complejo para crear un buscador de contenidos dentro de los vídeos de Youtube. En este post voy a detallar la segunda parte, cómo podemos utilizar la línea de comandos + Bert + SQL para crear un buscador de contenidos dentro de los vídeos.
Google podria no querer el HTML de una URL
Publicado por Lino Uruñuela el 10 de diciembre del 2019 Llevaba tiempo preparando un post, pero me cuesta, porque quiero redactarlo bien, explicadito y al final o no lo comienzo por la pereza que me da eso de currármelo en vez de soltarlo así según viene, o directamente no lo termino jamás.... Pero hoy vuelvo a mis or…
Crawl Budget, qué es y cómo afecta a tu site según Google
Publicado por Lino Uruñuela el 16 de enero del 2017 en Donostia Desde hace ya mucho tiempo llevo analizando, probando y optimizando el Crawl Budget o Presupuesto de Rastreo. Ya en los primeros análisis vi que esto era algo relevante para el SEO, que si bien no afecta directamente a los rankings de una KW determinada,…
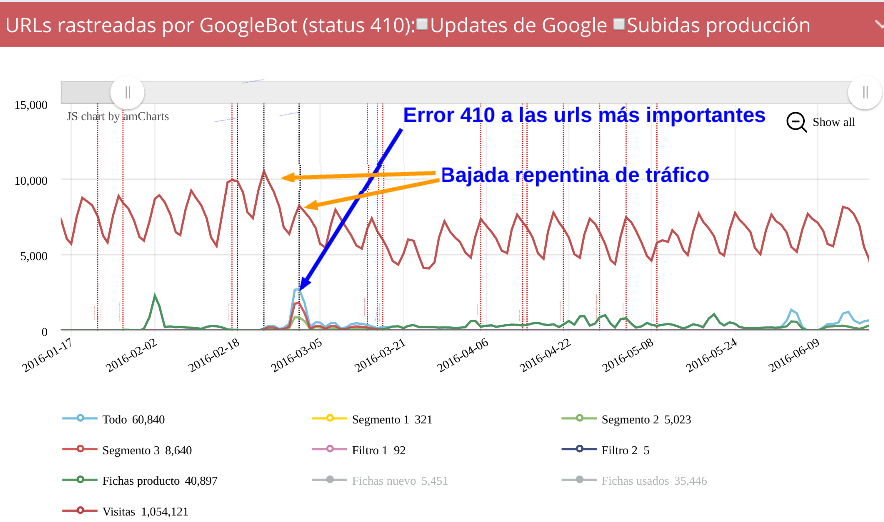
El valor de los logs para el SEO
Publicado el martes 6 de septiembre del 2016 por Lino Uruñuela Hace poco escribí el primero de una serie de post sobre el uso de Logs, Big Data y gráficas, en este caso continúo el análisis de la bajada que comenzamos a ver en Seo y logs (primera parte): Monitorización de Googlebot mediante logs , una caída importante…
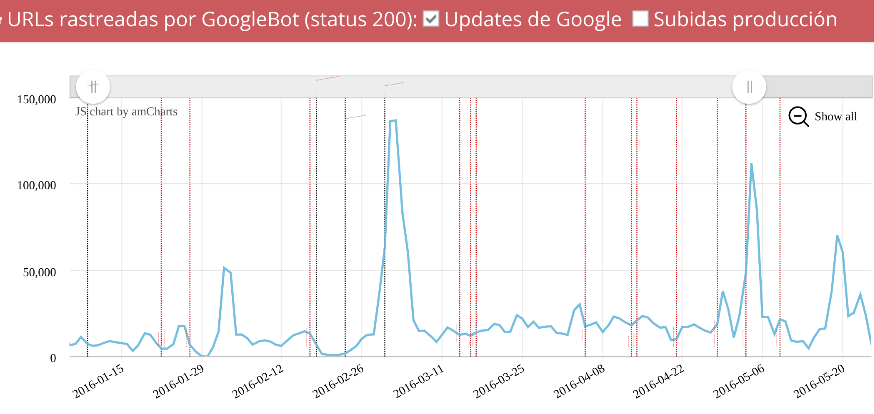
Seo y logs (primera parte): Monitorización de Googlebot mediante logs
Publicado por Lino Uruñuela el 27 de junio del 2016 Una de las ventajas de analizar los datos de los logs es que podemos hacer un seguimiento de lo que hace Google en nuestro site, pudiendo desglosar y ver independientemente el comportamiento sobre urls que dan error, o urls que hacen redirecciones, o urls que son cor…
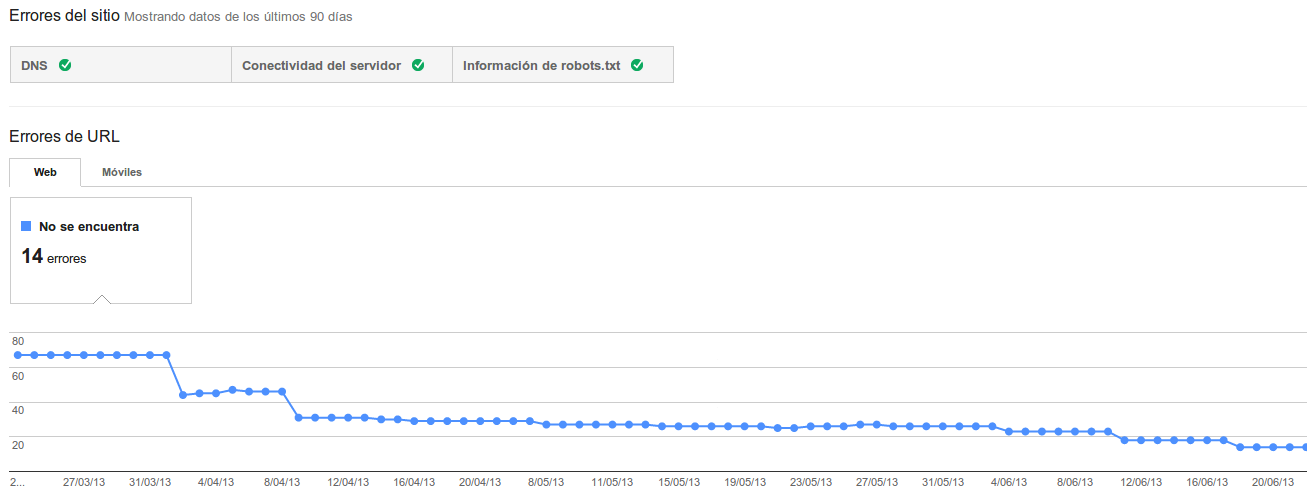
Dime que logs tienes, y te dire si Googlebot te quiere
Publicado el 23 de junio del 2013 By Lino Uruñuela Algo muy común en el día a día de un SEO es mirar las distintas herramientas que Google nos proporciona dentro de WMT para saber el estado de nuestra web en cosas como la frecuencia de rastreo, el número de páginas indexadas, errores 404, errores 503, etc... No está m…
Comprobando comportamiento de Google con meta canonical
Publicado el 10 de abril del 2012, by Lino Uruñuela Hace tiempo hice unos tests para comprobar que Google interpretaba el meta canonical y cómo lo evaluaba. No recuerdo si publiqué el experimento, pero sí recuerdo que Google contaba los links que había hacia una URL que contenía el meta canonical y traspasaba el valor…
Opción 1. Pero te dejas de nombrar la clave, si hay inlinks hacia esos 301
@javi sí, ese va a ser la evolución de este experimento. Añadir links hacia las 301 intermedias para comprobar si así accede más habitualmente. Y si además eso conlleva que accede más a la url final, este experimento va a dar mucho juego :)
Opción 1!!
Seguro que guarda la URL original. Así ahorra volver a crawlearla. Pero a efectos de calificarla la cuenta como una destino final. Es decir para calcular el pr usa todas pero el pr lo asigna a la url final.