Búsqueda semántica de contenidos en los vídeos de Youtube
- Línea de comandos
- Insertar datos en nuestra Base de Datos
- Genearar embeddings del texto
- Ejecutar python desde nuestra base de datos
- Resultados de la búsqueda utilizando embeddings
- Vídeo de mi presentación en el Seonthebeach
El otro día realicé una presentación en el Seonthebeach (el mejor evento SEO en mi opinión), que podemos dividir en dos partes. En la primera parte expliqué algunos comandos en el terminal de linux y cómo se podrían aprovechar para fines SEO, en los próximos artículos mostraré más ejemplos. En la segunda parte mostré un caso de uso un poco más complejo para crear un buscador de contenidos dentro de los vídeos de Youtube.
En este post voy a detallar la segunda parte, cómo podemos utilizar la línea de comandos + python(Bert) + SQL para crear un buscador de contenidos dentro de los vídeos.
Línea de comandos
Cómo expliqué en la presentación, además de los comandos nativos de linux, existen multitud de software fácilmente instalable que también podemos ejecutar desde la línea de comandos, para este ejemplo en concreto vamos a ver el programa yt-dlp mediante el cual obtendremos las transcripciones de cada vídeo de lista de reproducción en Youtube, y obtendremos estas transcripciones en español.
Obtener lista de vídeos dentro de una playlist de youtube
yt-dlp tiene una infinidad de posibilidades, como podemos ver aquí, nosotros usaremos solamente alguna de ellas. En este caso, lo primero que necesitamos es extraer el id o URL de cada uno de los vídeos de la lista de reproducción de youtube y para ello podemos usar este comando: con el parámetro '--flat-playlist'
yt-dlp --flat-playlist <id de la lista de reproducción>
Cojamos los vídeos de Search off the Record, que están todos dentro de una lista de reproducción de Youtube, y en la url de esta lista de reproducción (https://www.youtube.com/playlist?list= PLKoqnv2vTMUMxMs2PdBlDULqybdlPZxrk) el ID es "PLKoqnv2vTMUMxMs2PdBlDULqybdlPZxrk", dato que necesitarremos.
Para listar el id o la URL de cada uno de los vídeos en esa lista ejecutaremos el siguiente comando, dónde el parámetro '-j' indica que queremos obtener la información de cada vídeo en formato json.
yt-dlp --flat-playlist PLKoqnv2vTMUMxMs2PdBlDULqybdlPZxrk -j
El resultado de este comando es algo parecido a esto
{"_type": "url", "ie_key": "Youtube", "id": "H2PPep6gV-g", "url": "https://www.youtube.com/watch?v=H2PPep6gV-g", "title": "SEO Starter Guide: What\u2019s all the drama?", "description": null, "duration": 2591, "channel_id": "UCWf2ZlNsCGDS89VBF_awNvA", "channel": "Google Search Central", "channel_url": "https://www.youtube.com/channel/UCWf2ZlNsCGDS89VBF_awNvA"}
{"_type": "url", "ie_key": "Youtube", "id": "lpP9xS-Geh4", "url": "https://www.youtube.com/watch?v=lpP9xS-Geh4", "title": "Monetized websites, search experiments, and more!", "description": null, "duration": 2537, "channel_id": "UCWf2ZlNsCGDS89VBF_awNvA", "channel": "Google Search Central", "channel_url": "https://www.youtube.com/channel/UCWf2ZlNsCGDS89VBF_awNvA"}
Este fichero json contiene por cada línea la información de cada vídeo listado en la playlist. Para obtener solamente los campos que nos interesan concatenamos este comando con el comando 'jq' de linux, que sirve para formatear de diversas maneras archivos json, así que nuestro comando para obtener la URL de cada vídeo es:
yt-dlp --flat-playlist PLKoqnv2vTMUMxMs2PdBlDULqybdlPZxrk -j | jq -r .url
Nos devolerá una lista con las URLs de cada vídeo en esa playlist.
https://www.youtube.com/watch?v=T2RwEr4bkBw
https://www.youtube.com/watch?v=AyeD6Y_fLdk
https://www.youtube.com/watch?v=92jciJsXtx0
https://www.youtube.com/watch?v=Jm51YBz1jwY
https://www.youtube.com/watch?v=rBjeB3HCT-M
https://www.youtube.com/watch?v=SOyeNx80fKY
https://www.youtube.com/watch?v=-QalyAdm4uY
https://www.youtube.com/watch?v=M0SYUi-__Hs
https://www.youtube.com/watch?v=xxk2zfPSEP4
https://www.youtube.com/watch?v=NnWuKmXm85w
https://www.youtube.com/watch?v=tBjTPxz6gdQ
https://www.youtube.com/watch?v=4iizNFnrRWk
https://www.youtube.com/watch?v=m1YP4ptUjCM
https://www.youtube.com/watch?v=TaPhj4-bxkQ
https://www.youtube.com/watch?v=sWcBQgF2kyc
https://www.youtube.com/watch?v=2gXO6qpcQXY
Si queremos guardar esta lista de URLs en un fichero solo debemos añadir '>> nombreArchivoDestino.txt' al final de la orden, y añadirá el resultado de la ejecución del comando en un fichero que se llamará nombreArchivoDestino.txt. Para nuestro ejemplo guardaremos el listado de URLs en un fichero que llamaremos SORVideos.txt:
yt-dlp --flat-playlist PLKoqnv2vTMUMxMs2PdBlDULqybdlPZxrk -j | jq -r .url>>SORVideos.txt
Con ell comando 'cat' podemos ver el contenido del fichero SORVideos.txt que acabamos de generar, lo que nos muestra la url de cada vídeo.
cat SORVideos.txt
Contenido del fichero:
https://www.youtube.com/watch?v=T2RwEr4bkBw
https://www.youtube.com/watch?v=AyeD6Y_fLdk
https://www.youtube.com/watch?v=92jciJsXtx0
https://www.youtube.com/watch?v=Jm51YBz1jwY
https://www.youtube.com/watch?v=rBjeB3HCT-M
https://www.youtube.com/watch?v=SOyeNx80fKY
https://www.youtube.com/watch?v=-QalyAdm4uY
https://www.youtube.com/watch?v=M0SYUi-__Hs
https://www.youtube.com/watch?v=xxk2zfPSEP4
https://www.youtube.com/watch?v=NnWuKmXm85w
https://www.youtube.com/watch?v=tBjTPxz6gdQ
https://www.youtube.com/watch?v=4iizNFnrRWk
https://www.youtube.com/watch?v=m1YP4ptUjCM
https://www.youtube.com/watch?v=TaPhj4-bxkQ
https://www.youtube.com/watch?v=sWcBQgF2kyc
https://www.youtube.com/watch?v=2gXO6qpcQXY
Obtener subtitulos de un vídeo de Youtube
Una vez tenemos estas URLs queremos extraer para cada vídeo la transcripción que el propio Youtube ha generado automáticamente. Youtube genera subtítulos en muchos idiomas automáticamente, de momento, nosotros solo queremos los que estén traducidos al español.
Cuando los subtítulos son en otro idioma y han sido automáticamente traducidos por Youtube al español, el valor correspondiente será 'es'. Pero cuando el audio del vídeo es en español, los subtítulos tendrán el valor 'es-original'.
Si ejecutamos yt-dlp utilizando el parámetro --list-subs nos mostrará los subtitulos disponibles. Al ser vídeos originalmente en inglés los subtítulos disponibles en español traducidos por Youtube tendrán el valor 'es'.
yt-dlp --list-subs https://www.youtube.com/watch?v=AyeD6Y_fLdk
Esto nos mostrará la lista de subtítulos disponibles:
Language Name Formats
af Afrikaans vtt, ttml, srv3, srv2, srv1, json3
ak Akan vtt, ttml, srv3, srv2, srv1, json3
sq Albanian vtt, ttml, srv3, srv2, srv1, json3
am Amharic vtt, ttml, srv3, srv2, srv1, json3
ar Arabic vtt, ttml, srv3, srv2, srv1, json3
hy Armenian vtt, ttml, srv3, srv2, srv1, json3
as Assamese vtt, ttml, srv3, srv2, srv1, json3
ay Aymara vtt, ttml, srv3, srv2, srv1, json3
az Azerbaijani vtt, ttml, srv3, srv2, srv1, json3
bn Bangla vtt, ttml, srv3, srv2, srv1, json3
eu Basque vtt, ttml, srv3, srv2, srv1, json3
be Belarusian vtt, ttml, srv3, srv2, srv1, json3
bho Bhojpuri vtt, ttml, srv3, srv2, srv1, json3
bs Bosnian vtt, ttml, srv3, srv2, srv1, json3
bg Bulgarian vtt, ttml, srv3, srv2, srv1, json3
my Burmese vtt, ttml, srv3, srv2, srv1, json3
ca Catalan vtt, ttml, srv3, srv2, srv1, json3
ceb Cebuano vtt, ttml, srv3, srv2, srv1, json3
zh-Hans Chinese (Simplified) vtt, ttml, srv3, srv2, srv1, json3
zh-Hant Chinese (Traditional) vtt, ttml, srv3, srv2, srv1, json3
co Corsican vtt, ttml, srv3, srv2, srv1, json3
hr Croatian vtt, ttml, srv3, srv2, srv1, json3
cs Czech vtt, ttml, srv3, srv2, srv1, json3
da Danish vtt, ttml, srv3, srv2, srv1, json3
dv Divehi vtt, ttml, srv3, srv2, srv1, json3
nl Dutch vtt, ttml, srv3, srv2, srv1, json3
en-orig English (Original) vtt, ttml, srv3, srv2, srv1, json3
en English vtt, ttml, srv3, srv2, srv1, json3
eo Esperanto vtt, ttml, srv3, srv2, srv1, json3
et Estonian vtt, ttml, srv3, srv2, srv1, json3
ee Ewe vtt, ttml, srv3, srv2, srv1, json3
fil Filipino vtt, ttml, srv3, srv2, srv1, json3
fi Finnish vtt, ttml, srv3, srv2, srv1, json3
....
sl Slovenian vtt, ttml, srv3, srv2, srv1, json3
so Somali vtt, ttml, srv3, srv2, srv1, json3
st Southern Sotho vtt, ttml, srv3, srv2, srv1, json3
es Spanish vtt, ttml, srv3, srv2, srv1, json3
su Sundanese vtt, ttml, srv3, srv2, srv1, json3
sw Swahili vtt, ttml, srv3, srv2, srv1, json3
sv Swedish vtt, ttml, srv3, srv2, srv1, json3
tg Tajik vtt, ttml, srv3, srv2, srv1, json3
ta Tamil vtt, ttml, srv3, srv2, srv1, json3
tt Tatar vtt, ttml, srv3, srv2, srv1, json3
te Telugu vtt, ttml, srv3, srv2, srv1, json3
th Thai vtt, ttml, srv3, srv2, srv1, json3
Cada línea indica el idioma en el que están disponibles y sus diferentes formatos, a nosotros, para este caso de uso nos interesa los subtítulos en español, a poder ser en formato srv1.
Para guardar en un fichero los subtítulos en español de este vídeo usaremos:
yt-dlp --no-abort-on-error --write-auto-sub --sub-lang es --sub-format srv1 --skip-download -o ./"%(id)s---%(title)s" https://www.youtube.com/watch?v=AyeD6Y_fLdk
Esto descargará un fichero llamado "AyeD6Y_fLdk---Q&A You asked on Linkedin, we answered in here.es.srv1" (el título del vídeo) que contiene la transcripción en español de ese vídeo.
Si vemos el contenido de este fichero veremos algo parecido a este fragmento de ejemplo:
<?xml version="1.0" encoding="utf-8" ?><transcript><text start="3.06" dur="6.949">[Música]</text><text start="10.16" dur="4.96">hola y bienvenidos a otro episodio de</text>
Es decir tenemos el texto de la transcripción, además de otra información etiquetada en el fichero.
Transformación de las transcripciones
También nos interesa dividir este texto en diferentes párrafos, ya que luego añadiremos una fila en nuestra tabla de la base de datos con el contenido de cada uno para poder buscar de manera más concreta qué parte de qué vídeos responden a una determinada consulta, además, también nos valdrá para poder leer más fácilmente el contenido de cada vídeo.
Vamos a usar una expresión regular para dividir el texto de cada vídeo en frases creando un salto de línea cuando encontremos la etiqueta "<text start" seguida de una letra en mayúscula. Las transcripciones de Youtube pone en mayúsculas cuándo hay un punto y seguido o un punto y aparte (que en el vídeo o cuando hablamos en una breve pausa entre oriaciones) para dividir la transcripción en párrafos.
Algo curioso es que si el vídeo es original en inglés y obtenemos la transcripción en español que ha sido generada automáticamente por Youtube, Estos puntos y aparte, mayúsculas y otras puntuaciones del texto también serán transcritas, mientras que si el vídeo es oiriginal en español, no obtendremos estos punto y aparte, y en muchas ocasiones no pone en mayúscula la primera letra de cada oración.....
Vamos a crear los saltos de línea utulizando el comando 'sed', que reemplaza un texto por otro:
sed -i -E 's/(<text ([^>]+)>)([A-Z])/
\1\3/g' 'AyeD6Y_fLdk---Q&A You asked on Linkedin, we answered in here.es.srv1'
Ahora tenemos el fichero de subtítulos con un salto de línea por cada etiqueta <text start.... y con el valor del atributo 'start' que nos indica el segundo exacto en el que comienza ese párrafo en la reproducción del vídeo.
<text start="53.6" dur="4.88">Pueden elaborar un poco más?</text><text start="57.28" dur="3.2"></text>
<text start="58.48" dur="3.68">No los he visto</text><text start="60.48" dur="4.399">en mucho tiempo.</text>
<text start="62.16" dur="3.6">Trabajamos juntos en nuestro pequeño sofá.</text><text start="64.879" dur="4.081"></text>
<text start="65.76" dur="6.16">Recuerden, y yo trabajo en algo llamado</text><text start="68.96" dur="5.12">compinche. Bien, chico. Genial, qué compinche.</text>
Por último necesitamos obtener los subtitulos para cada URL en el fichero, ejecutaremos esta orden en paralelo gracias al parámetro '-P100' del comando 'xargs', lo que acelerará x100 la descarga de los subtítulos, ya que en vez de esperar a que termine de descargar una transcripción para comenzar la descarga de otra, lo hace de cien en cien (en paralelo):
cat SORVideos.txt | xargs -P100 -I{} bash -c 'yt-dlp --no-abort-on-error --write-auto-sub --sub-lang es --sub-format srv1 --skip-download -o ./"%(id)s---%(title)s" {}'
Ahora ya tenemos las transcripciones en español de cada vídeo guardados en una carpeta!
Para añadir un salto de línea por cada etiqueta '<text star' en todos los ficheros con extensión '.srv1' dentro de la carpeta usamos el siguiente comando (el '*srv1" indica que realizará la sustitucion en los ficheros que contengan 'srv1' en el nombre):
sed -i -E 's/(<text ([^>]+)>)([A-Z])/
\1\3/g' ./*srv1
Como resultado, tenemos en una carpeta todas las transcripciones en español, y en cada una de ellas hay tantas líneas como "párrafos" hayamos creado con nuestra sustitución.
Recordemos que el separar en diferentes líneas la transcripción es para que al realizar una búsqueda no realicemos solamente una búsqueda sobre todo el texto de un vídeo, sino para cada fila. De esta forma la coincidencia con la consulta realizada será más ajustada y además podremos enlazar exactamente a esa parte del vídeo y no solamente al comienzo del mismo.
Insertar datos en nuestra Base de Datos
Para hacer un buscador funcional deberemos almacenar los datos disponibles en una base de datos así que vamos a ver cómo insertar estos datos en una base de datos de una manera eficaz para nuestro propósito, en este caso yo utilizo ClickHouse como base de datos y algunas sentencias SQL difieren de otras bases de datos, pero más o menos son iguales. El que tenga algo de experiencia con SQL y bases de datos no tendrá ningún problema en entender lo que realizo y adaptar el código a su caso de uso.
Lo primero que voy a realizar es formatear el contenido dentro de nuestros ficheros para darle el formato que quiero utilizar en la tabla que crearé en la BBDD y dónde guardaré cada una de las líneas de cada fichero. Para ello voy a usar un comando que ejecuta una SQL desde la propia línea de comandos y que obtendrá el contenido de cada uno de los ficheros que coincidan con el patrón dentro del directorio dónde lo ejecuto, por ello, lo primero que haremos es acceder a la carpeta dónde hemos descargado todas las transcripciones, y ejecuto el siguiente comando:
clickhouse local -q "select '2023-01-01' as fecha,_file as fichero,extractTextFromHTML(line) as texto,line as linea,toFloat32OrZero(replaceRegexpAll(line,'.*dur=\"([^\"]+)\".*','\\1')) as duracion,splitByRegexp('start=',line) as comienza,arrayMap(x->replaceRegexpAll(x,'.*\"(\d+[^\"]+)\" dur=.*','\1 '),comienza)[2]as tiempo from file('*.srv1',LineAsString) INTO OUTFILE 'salidaTranscripcionestsv.gz' FORMAT TabSeparated"
Resumiendo este comando, lo que hago es, que por cada fichero en el directorio que termine en 'srv1' obtengo cada línea, la cual contiene un campo al que llamo 'linea' que contiene el texto de esa línea, otro campo al que llamo duración, que extraigo desde el campo 'linea' aplicando una expresión regular para obtener el valor del atributo 'start' en las etiquetas <text. Este campo es el segundo en el cual se reproduce ese texto en concreto.
También extraigo el atributo 'dur' que es la duración de ese párrafo en segundos y genero un archivo .tsv.gz (salidaTranscripcionestsv.gz) con todos el resultados de esta consulta en formato csv con tabulaciones como delimitador. Aquí un ejemplo de una fila devuelta en la consulta, que es guardada en fichero de texto comprimido llamado 'salidaTranscripcionestsv.gz'
fecha: 2023-01-01
fichero:
texto: [Música] hola y bienvenidos a otro episodio de búsqueda del registro un podcast del equipo de búsqueda de Google que habla sobre todo lo relacionado con el cirujano divirtiéndonos en el camino mi nombre es Martin y hoy me acompañan John y Gary del equipo de relaciones de búsqueda del que también formo parte hola John hola Gary hola John hola Gary hola
linea: <?xml version="1.0" encoding="utf-8" ?><transcript><text start="1.73" dur="8.309">[Música]</text><text start="10.099" dur="5.08">hola y bienvenidos a otro episodio de</text>
duracion: 7.5
comienza: ['<?xml version="1.0" encoding="utf-8" ?><transcript><text ','"1.73" dur="8.309">[Música]</text><text ','"10.099" dur="5.08">hola y bienvenidos a otro episodio de</text>
tiempo: 1.73
El siguiente paso es crear una tabla en nuestra base de datos, concretamente utilizo estos campos:
CREATE TABLE default.VideosSaarchOffRecord
(
`fecha` Date,
`fichero` String,
`texto` String,
`linea` String,
`duracion` Float32,
`comienza` Array(String),
`tiempo` String
)
ENGINE = MergeTree
ORDER BY fecha
SETTINGS index_granularity = 8192
Y ahora insertamos los datos desde nuestro fichero tsv.gz en la tabla de la base de datos, en clickhouse lo realizo de la siguiente manera:;
zcat salidaTranscripcionestsv.gz |clickhouse-client -u default --password=password --query "insert into default.VideosSaarchOffRecord(fecha,fichero,texto,linea,duracion,comienza,tiempo) FORMAT TabSeparatedWithNames"
Este comando hará que para cada línea en cada fichero añadamos una fila a nuestra base de datos, aquí una muestra parcial de como quedará la tabla.
| SELECT fecha,fichero ,substring(texto,1,20) as texto, substring(linea,1,20), duracion FROM VideosSaarchOffRecord | ||||
|---|---|---|---|---|
| fecha | fichero | texto | substring(linea, 1, 20) | duracion |
| 2023-01-01 | T2RwEr4bkBw Why is my site not indexed .es.srv1 | Música, nos hemos... | <text start="1603.49" | 8.36 |
| 2023-01-01 | T2RwEr4bkBw Why is my site not indexed .es.srv1 | Gary oh oh lo siento | <text start="1631.4" | 3.29 |
| 2023-01-01 | SOyeNx80fKY Site moves Are they getting any easier .es.srv1 | [Música] hola y bie | <?xml version="1.0" | 4.499 |
| 2023-01-01 | SOyeNx80fKY Site moves Are they getting any easier .es.srv1 | No puedo entender si | <text start="125.52" | 3.62 |
| 2023-01-01 | SOyeNx80fKY Site moves Are they getting any easier .es.srv1 | Básicamente, la may | <text start="159.54" | 5.3389997 |
| 2023-01-01 | Jm51YBz1jwY JavaScript at Google.es.srv1 | Ito Pereira, que ha trabajado con | <text start="25.14" | 5.52 |
| 2023-01-01 | Jm51YBz1jwY JavaScript at Google .es.srv1 | Gary durante más de una década y, más recientem | <text start="28.199" | 5.04 |
| 2023-01-01 | Jm51YBz1jwY JavaScript at Google .es.srv1 | Gary aquí porque le encanta JavaScript, pero siem | <text start="59.52" | 3.779 |
Si os fijáis hay más de una fila por cada fichero, ya que hemos creado una entrada por cada salto de línea antes introducido, y de esta forma podemos "afinar" más tanto en la similaridad del texto en cada párrafo con la consulta que haga el usuario. Haciéndolo de esta manera podemos obtener más de un resultado por cada vídeo, que debería estar más "cercano" a si realizamos la búsqueda sobre el texto completo de cada vídeo y que además nos permitirá enlazar al momento exacto dónde se habla sobre la consulta del usuario.
Generar embeddings del texto:
Tal como lo teníamos anteriormente podría valer para realizar una búsqueda de texto en nuestra base de datos para buscar aquellos vídeos que contengan determinado texto por el que el usuario quiere buscar. Una búsqueda tradicional devolvería aquellas filas en la base de datos que contengan todo o parte del texto buscado, pero podemos mejorar esta búsqueda utilizando embeddings de cada texto para realizar la búsqueda por similaridad, o distancia vectorial.
Recordemos que los embeddings son una forma de vectorizar los textos en base a grandes modelos de lenguaje. Existen muchos métodos / librerías para realizarlo, por ejemplo utilizar el mismo método que GPT-3, o utilizar el método que usa Bert y que es "gratis", por esta razón usaremos este método para obtener los embeddings de cada texto.
Un típico script en python para vectorizar un texto pasado como parámetro:
#!/usr/bin/python3
import sys
import json
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
for size in sys.stdin:
# Collect a batch of inputs to process at once
texts = []
for row in range(0, int(size)):
texts.append(sys.stdin.readline())
# Run the model and obtain vectors
embeddings = model.encode(texts)
# Output the vectors
for vector in embeddings:
print(json.dumps(vector.tolist()))
sys.stdout.flush()
Este script podríamos ejecutarlo con la orden
printf '1
Hola mundo
' |sudo -u clickhouse /usr/bin/python3 /var/lib/clickhouse/user_scripts/embeddings_Bert.py
Que nos devolverá el vector
[-0.04199904203414917, 0.13960981369018555, 0.007648408878594637, -0.008638427592813969, -0.030084844678640366, -0.037934545427560806, 0.0822339802980423, -0.041045524179935455, 0.016841711476445198, -0.023829331621527672, 0.07294703274965286, -0.05593234300613403, -0.06710375100374222, 0.0472036711871624, 0.033242080360651016, -0.029389839619398117, -0.01530377846211195, 0.04366403445601463, -0.02420889213681221, -0.012866905890405178, 0.08425087481737137, 0.013933478854596615, -0.02842390350997448, 0.04238486289978027, -0.049202337861061096, 0.03641732037067413, 0.01972183585166931, 0.02481144852936268, 0.03426500782370567, -0.07241944968700409, -0.01753469742834568, 0.07905507832765579, 0.016529593616724014, -0.040509507060050964, -0.08154590427875519, 0.05055529624223709, -0.028894834220409393, -0.02995210699737072, 0.009921396151185036, 0.034930840134620667, 0.010792665183544159, -0.07333944737911224, -0.0054008555598556995, -0.014019480906426907, -0.0005941041163168848, -0.09178341180086136, -0.010883600451052189, -0.00708233006298542, 0.003270557848736644, -0.012240445241332054, -0.14230726659297943, -0.004390847869217396, 0.026795662939548492, 0.05081256106495857, -0.008623597212135792, 0.033804528415203094, 0.07172141224145889, -0.03031413070857525, 0.10885188728570938, -0.02889156900346279, -0.01904139295220375, -0.006701341830193996, -0.06806103140115738, 0.0853772982954979, 0.020298609510064125, -0.07683150470256805, 0.034933414310216904, -0.005603966768831015, -0.10337091237306595, 0.06730879098176956, 0.0537664070725441, -0.024213625118136406, 0.08368657529354095, 0.02756670117378235, 0.02140444703400135, 0.08419595658779144, -0.04826994985342026, -0.04871179535984993, -9.794793731998652e-05, 0.06209588423371315, 0.08632632344961166, 0.006478661205619574, -0.09793300926685333, 0.03871214762330055, 0.028589485213160515, 0.03621281683444977, -0.05055749788880348, 0.01790824718773365, 0.02058469131588936, -0.05667934939265251, -0.0437498576939106, 0.005730689037591219, 0.0456370934844017, 0.04757525399327278, -0.0020667060744017363, 0.05715548247098923, 0.028719782829284668, 0.03277605399489403, -0.0906100869178772, 0.12587730586528778, 0.06639298796653748, 0.005992457736283541, 0.053580883890390396, 0.06593992561101913, 0.040995385497808456, 0.016743037849664688, 0.06607839465141296, 0.0739123597741127, -0.002513291547074914, 0.07128007709980011, -0.12378540635108948, -0.05826696753501892, -0.05932343378663063, -0.037397198379039764, -0.005278975237160921, 0.0037001478485763073, 0.04669644311070442, 0.017673034220933914, -0.03252536803483963, -0.09936690330505371, 0.05525816231966019, -0.02495403029024601, -0.024970827624201775, -0.008718525059521198, 0.060849450528621674, -0.06169966980814934, -0.049643635749816895, -1.896650951502145e-33, 0.035834524780511856, -0.04613729193806648, 0.02929198555648327, 0.05799620598554611, 0.03665629401803017, 0.010424246080219746, -0.04316972941160202, -0.02108553797006607, -0.06405272334814072, -0.022632423788309097, -0.04274889454245567, 0.0694173276424408, -0.06972216814756393, 0.01961706578731537, -0.024675190448760986, 0.060609687119722366, 0.03989558666944504, 0.017317157238721848, 0.018096784129738808, 0.049756407737731934, 0.021741630509495735, 0.005746669601649046, -0.017922760918736458, 0.04651373252272606, -0.0428398922085762, 0.05122672766447067, 0.0240436140447855, -0.1418837606906891, -0.03499980270862579, 0.07556980848312378, 0.051515884697437286, -0.0414578951895237, 0.06318636983633041, -0.05213036760687828, -0.04498465359210968, 0.01859280653297901, -0.06857464462518692, -0.03496541082859039, -0.020537348464131355, -0.06931724399328232, 0.029996929690241814, 0.011907050386071205, 0.058591119945049286, 0.027938779443502426, -0.03156522288918495, 0.045413870364427567, 0.006624022964388132, 0.04271116480231285, -0.001658146153204143, 0.05897922441363335, -0.02278592623770237, -0.09169534593820572, -0.12034202367067337, -0.006563062313944101, -0.0018543920014053583, -0.004620619583874941, 0.024285273626446724, 0.04840331897139549, 0.00885080173611641, 0.02980783022940159, -0.01595468260347843, -0.0023600582499057055, -0.03256172314286232, 0.06440457701683044, -0.014571010135114193, -0.06305282562971115, -0.0019907557871192694, 0.01276276633143425, -0.05041608586907387, -0.0031974371522665024, -0.06017622724175453, -0.002759600291028619, -0.020972613245248795, 0.08658663928508759, 0.00254844781011343, -0.050894323736429214, 0.04843318834900856, -0.041602473706007004, -0.05058710649609566, 0.042176637798547745, -0.03057844378054142, 0.018877513706684113, 0.031749021261930466, 0.07107159495353699, 0.07135584950447083, -0.00596516253426671, 0.021364040672779083, 0.029932966455817223, 0.01082742027938366, 0.05899651348590851, -0.03602606803178787, -0.03048749640583992, 0.03865346312522888, -0.018112199380993843, -0.055843062698841095, 1.2305213536006904e-33, -0.06501530855894089, -0.04677985981106758, 0.06346800923347473, -0.006408133544027805, 0.034267306327819824, -0.022301020100712776, -0.05296303331851959, 0.11874464154243469, -0.006765930447727442, -0.0333804152905941, 0.036877021193504333, -0.09045889973640442, 0.08084123581647873, -0.0035445543471723795, -0.002107099397107959, 0.004589652642607689, 0.06773506850004196, -0.053342368453741074, 0.0012062598252668977, 0.09916513413190842, -0.04492269456386566, -0.00485033355653286, -0.03917763754725456, -0.04270639643073082, -0.028304826468229294, 0.035415779799222946, 0.12462770938873291, 0.0937652438879013, -0.12820661067962646, 0.04440838471055031, -0.046009503304958344, -0.013273520395159721, -0.03647918626666069, 0.044417545199394226, -0.02132279984652996, 0.07656694948673248, -0.0028914951253682375, 0.03420861437916756, 0.02896856889128685, -0.05618029832839966, -0.009980850853025913, -0.05728386715054512, -0.04410269483923912, 0.009954768233001232, 0.0364120677113533, 0.04409724473953247, 0.030696652829647064, 0.01634378358721733, 0.015580064617097378, 0.053735557943582535, -0.012293570674955845, 0.043308325111866, -0.0549783855676651, 0.006525897420942783, -0.009081407450139523, -0.050665028393268585, -0.04599490389227867, -0.02757147327065468, 0.0202951617538929, 0.009481864050030708, 0.05840805917978287, 0.07413375377655029, -0.05685637891292572, 0.09917301684617996, -0.038851987570524216, 0.011468695476651192, -0.05069488659501076, 0.00041301638702861965, -0.08608953654766083, 0.037832409143447876, -0.014711880125105381, 0.06539095193147659, -0.14342516660690308, -0.03198571503162384, -0.0033705029636621475, -0.020002800971269608, -0.17558690905570984, -0.02125943824648857, -0.02018655650317669, -0.0565401129424572, -0.04465191438794136, -0.03280883654952049, -0.07115878909826279, 0.018652180209755898, 0.06888549774885178, 0.03801665082573891, 0.01806298829615116, 0.017738180235028267, -0.05204074829816818, 0.012796897441148758, 0.007534584496170282, 0.06253349781036377, -0.0492401085793972, -0.024069886654615402, -0.03183335065841675, -1.4100907996805745e-08, -0.0491684265434742, 0.03519303724169731, 0.02483055554330349, -0.030196692794561386, -0.011617899872362614, 0.049192607402801514, -0.02363523095846176, -0.06348849833011627, 0.09175548702478409, 0.08474089205265045, 0.04066804423928261, 0.04354138299822807, 0.034671276807785034, -0.004136207513511181, 0.013150271959602833, -0.00956172775477171, -0.016549943014979362, 0.07267919927835464, 0.040358949452638626, 0.0004999084048904479, 0.10180217772722244, 0.00646891538053751, 0.053114961832761765, -0.012673328630626202, 0.03320998325943947, -0.010648265480995178, 0.03456759452819824, -0.012266568839550018, 0.02008812315762043, -0.11286407709121704, 0.011546851135790348, 0.03998633101582527, -0.08668231219053268, 0.016832154244184494, -0.025121532380580902, -0.0256007369607687, -0.06420417875051498, -0.07032977044582367, -0.00921657681465149, -0.022286081686615944, 0.0009254160104319453, 0.041980087757110596, -0.04785114899277687, -0.044159673154354095, -0.01471828855574131, 0.014036706648766994, 0.10096295922994614, -0.07365816831588745, 0.029009735211730003, -0.053417228162288666, -0.09208549559116364, -0.06747417151927948, 0.0717347040772438, -0.03993741422891617, 0.07237406075000763, -0.0515059232711792, 0.05855737254023552, 0.060367073863744736, -0.04067757725715637, 0.03514241799712181, 0.08882798254489899, -0.07751718163490295, 0.013403071090579033, 0.0015069871442392468]
Es importante saber que si quieres realizar una búsqueda semántica utilizando embeddings el método que uses para generar estos embeddings ha de ser siempre el mismo, tanto para crear los embeddings a partir del texto que luego querremos buscar como para vectorizar la consulta que el usuario realice con el texto a buscar. Si utilizamos un método para obtener los embeddings de nuestro texto y otro para la consulta del usuario no funcionará..
Ejecutar python desde nuestra base de datos
No estoy seguro si muchas bases de datos se puede definir que determinada función de SQL ejecute un script en python (u otros lenguajes), pero en ClickHouse sí se puede, simplemente debemos añadir un fichero en nuestro directorio de configuración que haga referencia al tipo de función que es, dónde se encuentra el script en python que se ejecutará y a que nombre de función SQL asignaremos este script.
En mi caso utilizo este fichero de configuración para indicar que debe ejecutar el script 'embeddings_Bert.py' cuando en la consulta SQL invoque a la función 'embeddingsBert', y me devolverá el vector correspondiente al texto que le pase como parámetro
<functions>
<function>
<type>executable_pool</type>
<name>embeddingsBert</name>
<return_type>Array(Float32)</return_type>
<argument>
<type>String</type>
</argument>
<format>TabSeparated</format>
<command>embeddings_Bert.py</command>
<command_read_timeout>1000000</command_read_timeout>
</function>
</functions>
Es decir, cuando realice una consulta SQL como esta:
SELECT embeddingsBert('HOLA Seonthebeach! Estoy creando un buscador de vídeos')
Devolverá el embedding para el texto 'HOLA Seonthebeach! Estoy creando un buscador de vídeos' utilizando el script python de antes, concretamente:
[0.025904791,-0.008754695,0.0024956395,-0.13338439,0.01864505,0.05029957,-0.009462273,0.060423102,0.018565167,0.013814554,0.052767802,0.0024675315,-0.017760934,-0.018805891,-0.048940554,-0.07448278,-0.040682632,0.06135456,0.02646966,-0.0031299598,0.122386|
Ciertamente una auténtica maravilla!!
Ahora podríamos ejecutar una sentencia SQL como la siguiente para obtener las filas en nuestra tabla que más se parezcan semánticamente (similaridad) con la frase de búsqueda:
WITH embeddingsBert('como evitar penalizaciones') as txtBusqueda
SELECT url, tiempo, L2SquaredDistance(embeddingsBert(texto), txtBusqueda) as distancia, texto, contexto
from( SELECT concat('https:www.youtube.com/', replaceAll(replaceAll(fichero, '.es.srv1', ''), '.cc.srv1.es-en-j3PyPqV-e1s.srv1', ''), '&t=', replaceRegexpAll(tiempo, '\..*', ''), 's') as url, texto, neighbor(texto,-2) as vecino2, neighbor(texto,-1) as vecino1, neighbor(texto, 1) as vecinoIn1, neighbor(texto, 2) as vecinoIn2, concat(vecino2, ' ', vecino1, ' ', texto, ' ', vecinoIn1, ' ', vecinoIn2) as contexto, vector, tiempo
FROM default.VideosSaarchOffRecord)
order by distancia
limit 100
En esta consulta SQL, lo que hago es que para un texto que queremos buscar 'txtBusqueda' obtenemos los registros en la base de datos que más se parecen al texto de la consulta. Para ello debemos vectorizar tanto el texto de búsqueda 'txtBusqueda' como el campo 'texto' en cada fila de la tabla en nuestra base de datos, y una vez vectorizado obtener la distancia entre el texto de búsqueda y cada campo 'texto' en la base de datos ordenando el resultado por la distancia vectorial.
En este caso he usado la función L2SquaredDistance(embeddingsBert(texto), txtBusqueda) que nos mostrará un número en base a su similaridad, por lo que ordenará los resultados en base a esta distancia y así obtener las filas en la tabla con el texto más parecido al texto de búsqueda.
Existen otras funciones como 'cosineDistance' pero que en mi caso ofrece peores resultados.
Si os habéis fijado también tengo otros campos en la consulta, como son vecinos1, vecinos2, etc y el campo 'contexto'. Este campo contexto lo genero con el valor del texto en las x filas anteriores e y filas posteriores, ¿para qué?, primero para ir probando diferentes combinaciones de valores/campos para aprender cuál se ajusta mejor, y segundo, para poder generar una respuesta utilizando un modelo de lenguaje como GPT-3.5 con el texto que rodea a la respuesta y poder generar a partir de esos párrafos una respuesta mucho más elaborada al usuario.
En este último paso estoy ahora mismo, ya que no me gusta demasiado el pagar (aunque sea relativamente poco) por cada búsqueda que se realice. Además he de mejorar el prompt que uso para generar esta respuesta en base al texto y su contexto para que se ajuste totalmente a mis resultados, en breve nuevo post dónde lo veremos :).
Resultados de la búsqueda utilizando embeddings
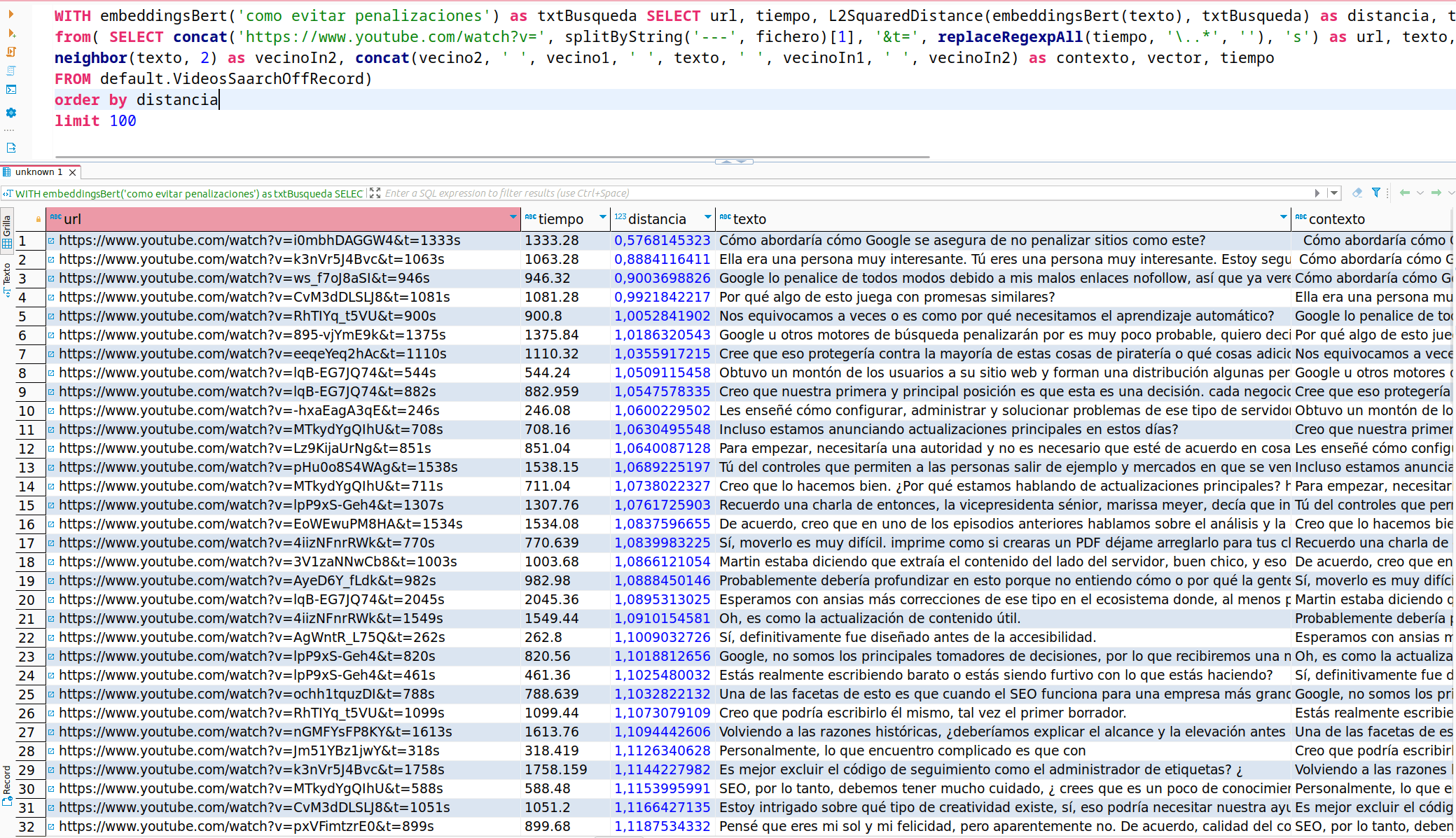
En la propia SQL estoy generando la url del fragmento de vídeo que más similaridad tenga con nuestra consulta de búsqueda, por ejemplo para la búsqueda "como evitar penalizaciones" obtenemos la siguiente URL como mejor resultado https://www.youtube.com/watch?v=i0mbhDAGGW4&t=1333s que si accedemos a ella podemos ver cómo es el momento exacto dónde hablan de las penalizaciones.
En esta consulta SQL realizo una comparación del embedding del texto de búsqueda con los embeddings del texto en la base de datos, esta forma de hacerlo es muy ineficiente, ya que para cada fila en la base de datos he de crear los embeddings al vuelo, lo ideal es añadirlos en otro campo a la vez que se insertan los datos en la tabla.
Aun así, cuando tenemos una tabla de decenas de miles de filas, o millones, esta consulta SQL podría eternizarse, ya que para obtener la distancia entre el texto de búsqueda y cada registro en la base de datos ha de realizar una comparación por cada fila en la tabla, lo que es inescalable. Si tenemos millones de registros posiblemente no sea viable ponerlo en producción...
Para resolver este problema se utilizan índices especiales para la búsqueda de vectores, Approximate Nearest Neighbors, o aproximación vecinos más cercanos, que en vez de realizar una comparación en cada fila de la tabla, realiza una aproximación, y nos devuelve una cantidad pequeña de resultados, que son muy parecidos a los resultados obtenidos si hiciésemos esa comparación para cada valor pero que ahorra el realizarlo con cada fila en la tabla por lo que es una forma muy muy rápida de ordenar este tipo de resultados.
Existen diferentes algoritmos para crear un índice ANN, yo en concreto utilizo uno que ha implementado ClickHouse aprovechando el algoritmo de Spotify, annoy, existen otros métodos, cada cual con sus pros y sus contras, pero esto también será otro post :).
Vídeo de mi presentación en el Seonthebeach
Os comparto aquí el vídeo de mi presentación, mientras tanto voy a ir creando el interface web para este buscador de contenido dentro de los vídeos, a ver qué tal me queda :)
Lee otros artículos
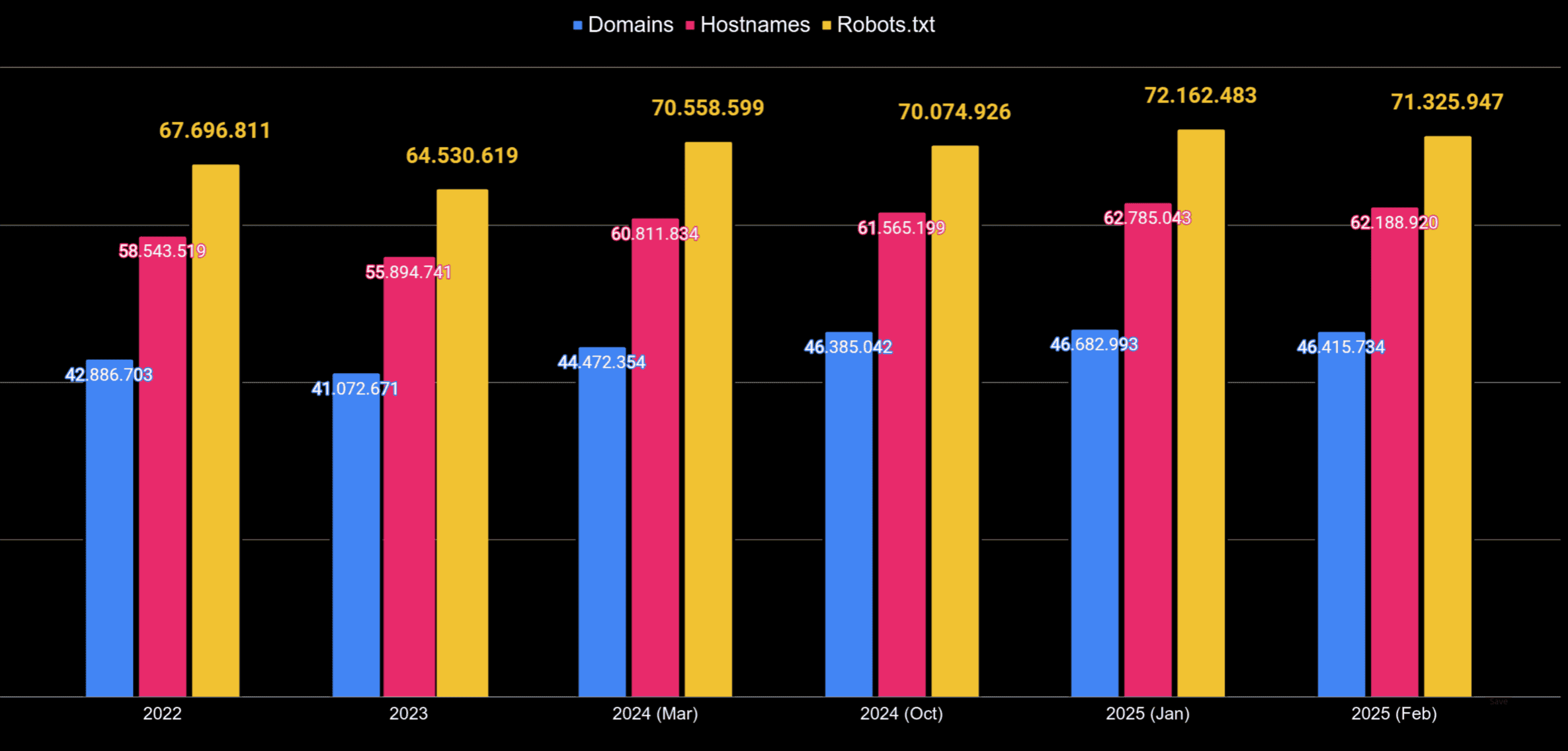
¿Se está impidiendo a los bots de Inteligencia Artificial acceder al contenido?
¿Cómo ha ido incrementando el número de robots.txt en los que aparecen rastreadores asociados a la Inteligencia Artificial?
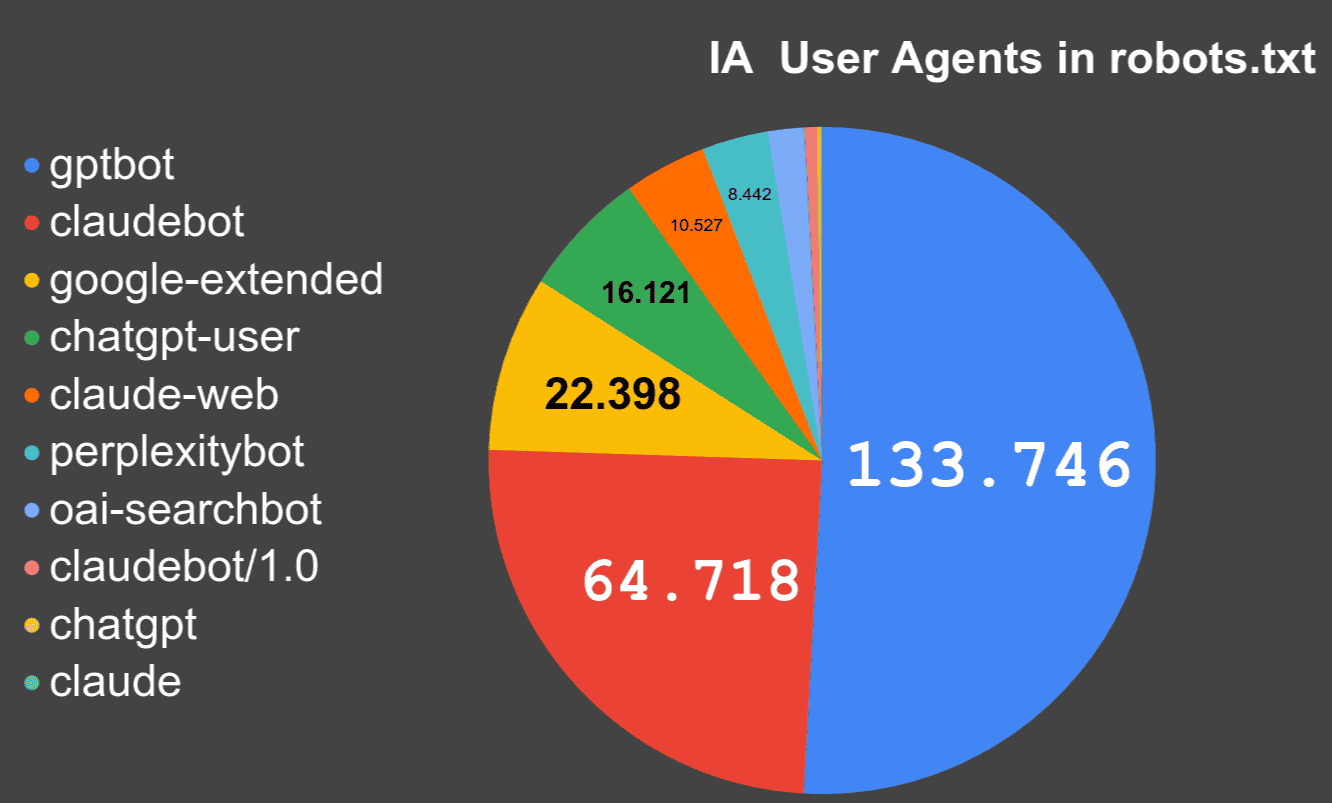
Analizando más de 72 millones de robots.txt
¿Cuántos dominios, subdominios y robots.txt estén bloqueando a los crawlers de Inteligencia Artificial?
¿Cómo decide Google que URL debe rastrear?
Hoy he descubierto este paper de Google (A Scalable Crawling Algorithm Utilizing Noisy Change-Indicating Signals) dónde describe una mejora del método descrito en el artículo inicial
Google podria no querer el HTML de una URL
Publicado por Lino Uruñuela el 10 de diciembre del 2019 Llevaba tiempo preparando un post, pero me cuesta, porque quiero redactarlo bien, explicadito y al final o no lo comienzo por la pereza que me da eso de currármelo en vez de soltarlo así según viene, o directamente no lo termino jamás.... Pero hoy vuelvo a mis or…
Intentando comprender Googlebot y los 301
Publicado por Lino Uruñuela el 22 de marzo del 2017 El otro día hubo un debate sobre qué método usará Google a la hora de interpretar, seguir y valorar las redirecciones 301. Las dudas que me surgieron fueron ¿Cómo se comportan los crawlers? Normalmente cuando lanzamos un crawler como Secreaming Frog lo que hace es Ac…
Crawl Budget, qué es y cómo afecta a tu site según Google
Publicado por Lino Uruñuela el 16 de enero del 2017 en Donostia Desde hace ya mucho tiempo llevo analizando, probando y optimizando el Crawl Budget o Presupuesto de Rastreo. Ya en los primeros análisis vi que esto era algo relevante para el SEO, que si bien no afecta directamente a los rankings de una KW determinada,…
El valor de los logs para el SEO
Publicado el martes 6 de septiembre del 2016 por Lino Uruñuela Hace poco escribí el primero de una serie de post sobre el uso de Logs, Big Data y gráficas, en este caso continúo el análisis de la bajada que comenzamos a ver en Seo y logs (primera parte): Monitorización de Googlebot mediante logs , una caída importante…
Seo y logs (primera parte): Monitorización de Googlebot mediante logs
Publicado por Lino Uruñuela el 27 de junio del 2016 Una de las ventajas de analizar los datos de los logs es que podemos hacer un seguimiento de lo que hace Google en nuestro site, pudiendo desglosar y ver independientemente el comportamiento sobre urls que dan error, o urls que hacen redirecciones, o urls que son cor…
Dime que logs tienes, y te dire si Googlebot te quiere
Publicado el 23 de junio del 2013 By Lino Uruñuela Algo muy común en el día a día de un SEO es mirar las distintas herramientas que Google nos proporciona dentro de WMT para saber el estado de nuestra web en cosas como la frecuencia de rastreo, el número de páginas indexadas, errores 404, errores 503, etc... No está m…
Comprobando comportamiento de Google con meta canonical
Publicado el 10 de abril del 2012, by Lino Uruñuela Hace tiempo hice unos tests para comprobar que Google interpretaba el meta canonical y cómo lo evaluaba. No recuerdo si publiqué el experimento, pero sí recuerdo que Google contaba los links que había hacia una URL que contenía el meta canonical y traspasaba el valor…
Comentarios
Todavía no hay comentarios publicados.