Logs y Big Data
Estuve hablando sobre logs y SEO, aquí la presentación, de cómo analizando los logs de una web se puede hacer un seguimiento muy detallado de que hace Google en tu site, además de obtener datos de los enlaces entrantes en un site.
Como me faltó tiempo para verlo todo en profundidad voy a empezar una serie de posts sobre logs y SEO para ver los datos que podemos obtener de ellos, el cómo usarlos y el gran valor que para un SEO tienen. Aquí os dejo un primer borrador del índice con el pimer post "Monitorización de Googlebot en tu site"
- Monitorización de Googlebot en tu site
- El valor de los logs para el SEO
- Análisis a fondo de errores 404 y 410
- Redirecciones y el gran valor de los logs en una migración
- Ordenando urls y prioridades
- Backlinks
- Parámetros
Para el que no sepa muy bien que es un log, aquí dejo una breve intro.
¿Qué son los logs?
Cada vez que un usuario (o un bot de un buscador o scraper) hace una petición desde el navegador de una url de tu página web el servidor lo registra en un fichero de texto, donde queda reflejado quién ha hecho la petición, cuándo la hizo, que url ha pedido, información de sistema operativo y navegador de quién la ha hecho.Por ejemplo, cuando cargamos la home de este site, podemos ver como nuesrtro navegador pide al servidor una serie de ficheros.
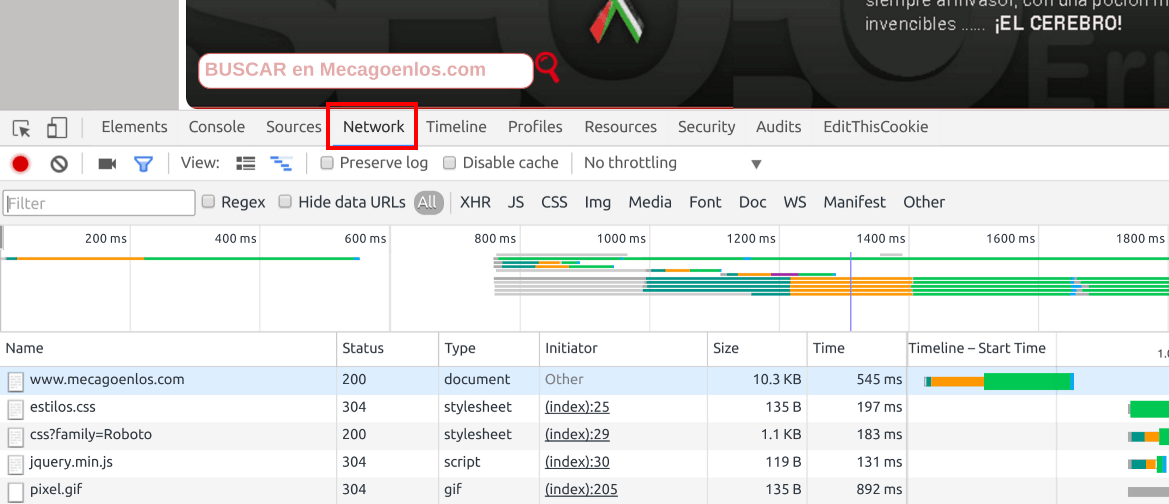
Si miramos los logs mientras carga la página podemos ver las siguientes líneas
Podemos ver como las urls que señalo son exactamente las mismas que el navegador del cliente está pidiendo.
En los logs, no solo se guarda la url que pide el usuario desde la barra de direcciones del navegador, sino que también se guardan todas las peticiones que se hacen desde el html devuelto al cliente, por ejemplo las hojas de estilos (ficheros css,) imágenes, ficheros js o cualquier petición que se haga.
¿Que información nos ofrecen los logs?
Los campos que aquí veremos y manejaremos son- Fecha
Cualquier análisis de logs no valdrá de nada si no filtramos los datos por fecha, ya sea por días, ya sea comparando datos entre dos fechas. Los datos sin fecha no son relevantes, y aquí lo que queremos es ver que ocurre en nuestro site cada día, para así poder ver o analizar los cambios que en ellos se produzcan.
- URL
Queremos ver los datos de una url o en un grupo de urls y para ello usaremos este campo. En la mayoría de ocasiones necesitamos saber qué ocurre con un grupo determinado de urls como podrían ser las distintas secciones del site, sus distintos filtros, las paginaciones, las fichas de producto, listados etc.
- Código de estado (200, 301, 302, 404, 410, etc)
Este campo como os podéis imaginar es uno de los más importantes, ya que nos interesa ver que hacen las urls de nuestro site, cómo responden ante Google y a dónde le llevan.
- Referer
Normalmente cuando es un bot de un buscador como el caso de Google, este campo suele ir vacío "-",. - User Agent
Este campo lo usaremos para identificar a GoogleBot, si este campo contiene "Googlebot" es Google, aunque lo ideal es hacer un reverse DNS para ver si es Google realmente o algún otro crawler que se hace pasar por el?
Comentarios
2Artículos en Logs y Big Data
11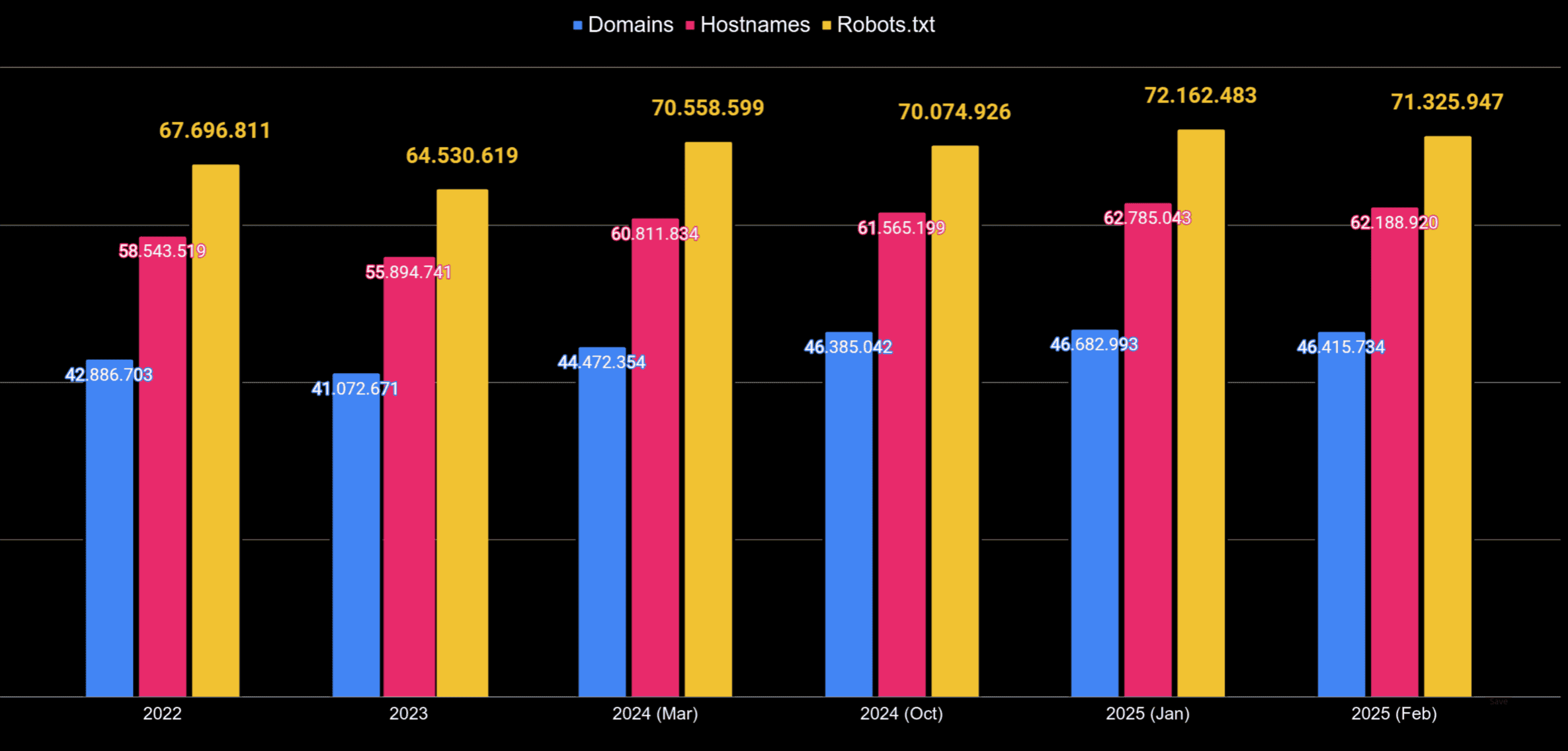
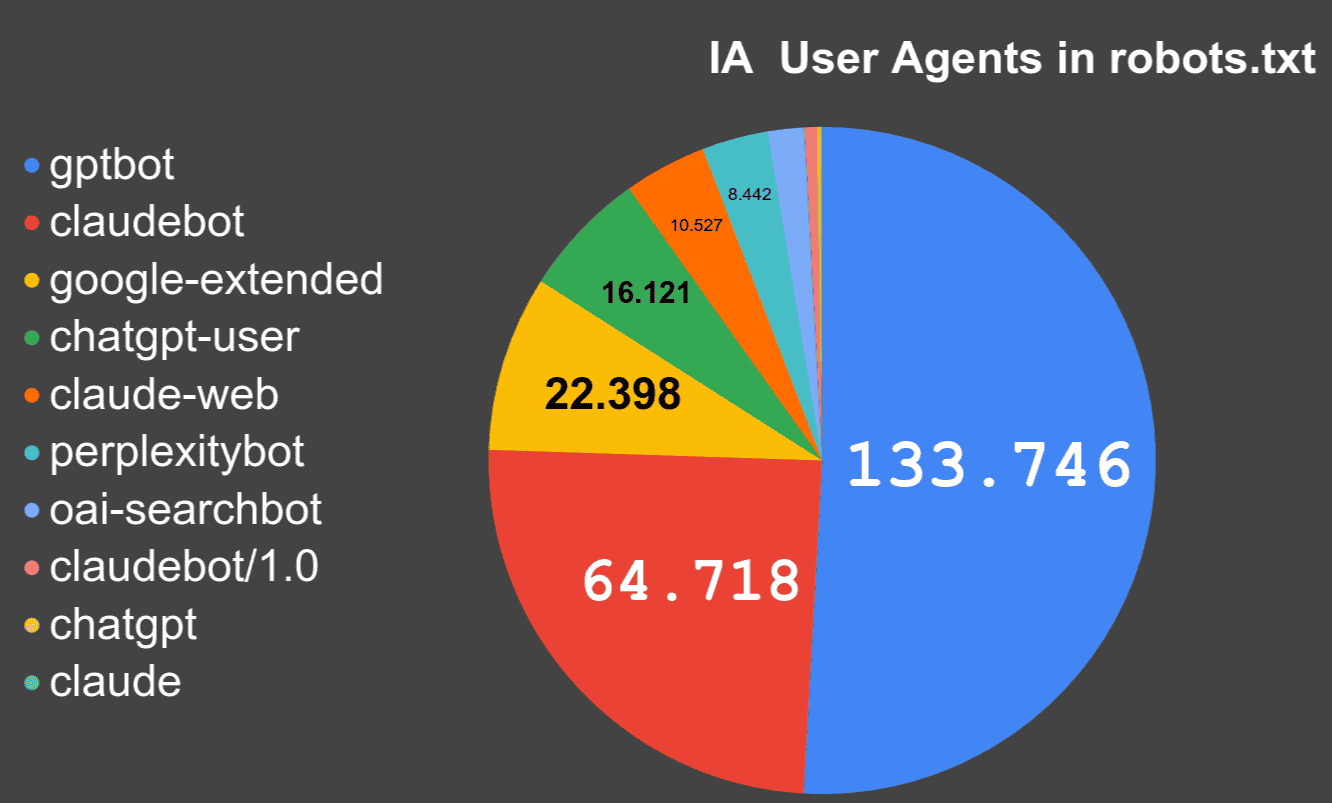
¿Se está impidiendo a los bots de Inteligencia Artificial acceder al contenido?
¿Cómo ha ido incrementando el número de robots.txt en los que aparecen rastreadores asociados a la Inteligencia Artificial?
Analizando más de 72 millones de robots.txt
¿Cuántos dominios, subdominios y robots.txt estén bloqueando a los crawlers de Inteligencia Artificial?
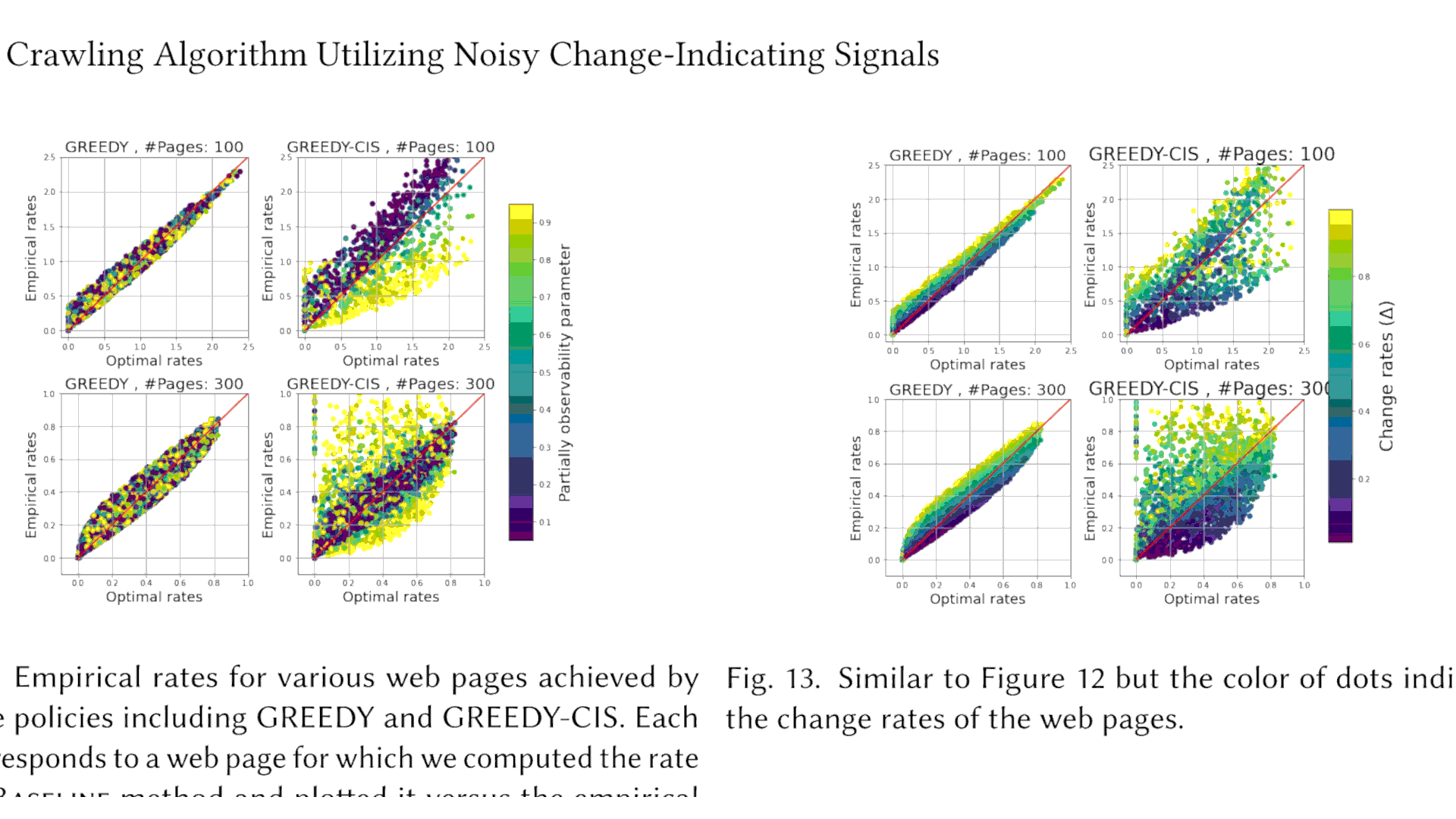
¿Cómo decide Google que URL debe rastrear?
Hoy he descubierto este paper de Google (A Scalable Crawling Algorithm Utilizing Noisy Change-Indicating Signals) dónde describe una mejora del método descrito en el artículo inicial
Búsqueda semántica de contenidos en los vídeos de Youtube
n la segunda parte mostré un caso de uso un poco más complejo para crear un buscador de contenidos dentro de los vídeos de Youtube. En este post voy a detallar la segunda parte, cómo podemos utilizar la línea de comandos + Bert + SQL para crear un buscador de contenidos dentro de los vídeos.
Google podria no querer el HTML de una URL
Publicado por Lino Uruñuela el 10 de diciembre del 2019 Llevaba tiempo preparando un post, pero me cuesta, porque quiero redactarlo bien, explicadito y al final o no lo comienzo por la pereza que me da eso de currármelo en vez de soltarlo así según viene, o directamente no lo termino jamás.... Pero hoy vuelvo a mis or…
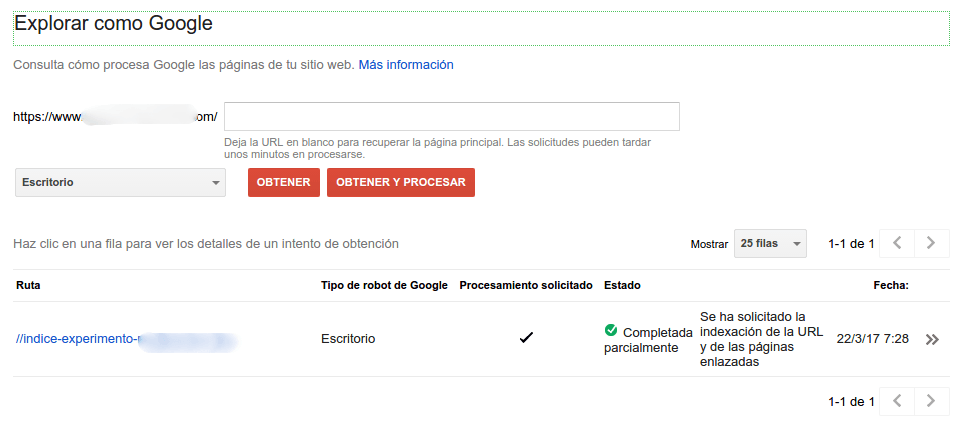
Intentando comprender Googlebot y los 301
Publicado por Lino Uruñuela el 22 de marzo del 2017 El otro día hubo un debate sobre qué método usará Google a la hora de interpretar, seguir y valorar las redirecciones 301. Las dudas que me surgieron fueron ¿Cómo se comportan los crawlers? Normalmente cuando lanzamos un crawler como Secreaming Frog lo que hace es Ac…
Crawl Budget, qué es y cómo afecta a tu site según Google
Publicado por Lino Uruñuela el 16 de enero del 2017 en Donostia Desde hace ya mucho tiempo llevo analizando, probando y optimizando el Crawl Budget o Presupuesto de Rastreo. Ya en los primeros análisis vi que esto era algo relevante para el SEO, que si bien no afecta directamente a los rankings de una KW determinada,…
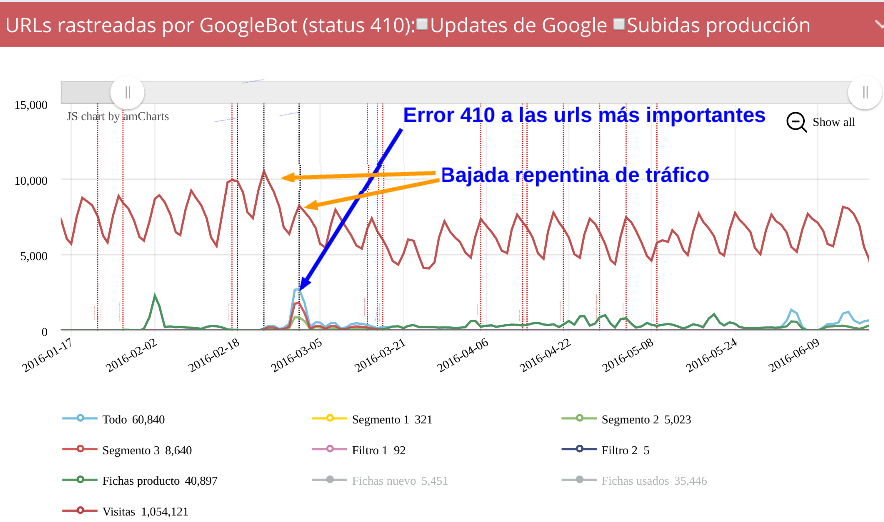
El valor de los logs para el SEO
Publicado el martes 6 de septiembre del 2016 por Lino Uruñuela Hace poco escribí el primero de una serie de post sobre el uso de Logs, Big Data y gráficas, en este caso continúo el análisis de la bajada que comenzamos a ver en Seo y logs (primera parte): Monitorización de Googlebot mediante logs , una caída importante…
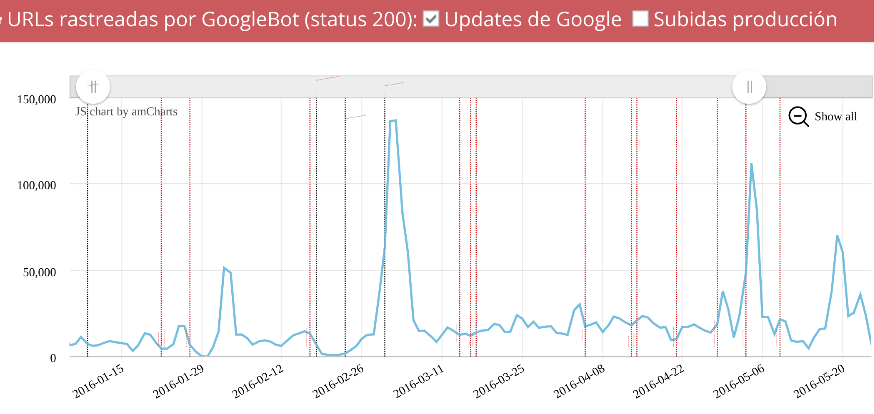
Seo y logs (primera parte): Monitorización de Googlebot mediante logs
Publicado por Lino Uruñuela el 27 de junio del 2016 Una de las ventajas de analizar los datos de los logs es que podemos hacer un seguimiento de lo que hace Google en nuestro site, pudiendo desglosar y ver independientemente el comportamiento sobre urls que dan error, o urls que hacen redirecciones, o urls que son cor…
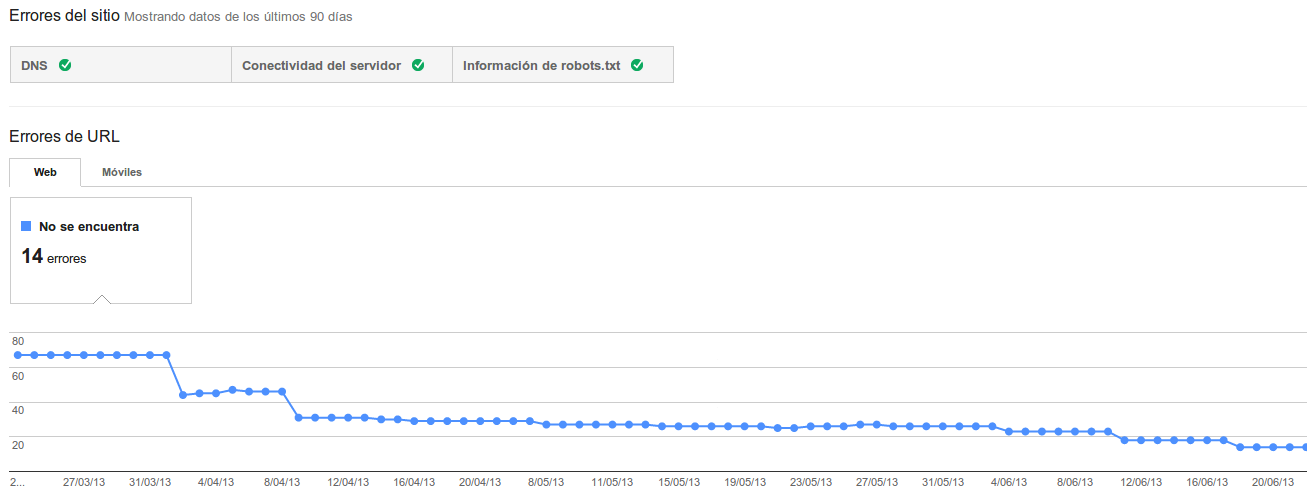
Dime que logs tienes, y te dire si Googlebot te quiere
Publicado el 23 de junio del 2013 By Lino Uruñuela Algo muy común en el día a día de un SEO es mirar las distintas herramientas que Google nos proporciona dentro de WMT para saber el estado de nuestra web en cosas como la frecuencia de rastreo, el número de páginas indexadas, errores 404, errores 503, etc... No está m…
Comprobando comportamiento de Google con meta canonical
Publicado el 10 de abril del 2012, by Lino Uruñuela Hace tiempo hice unos tests para comprobar que Google interpretaba el meta canonical y cómo lo evaluaba. No recuerdo si publiqué el experimento, pero sí recuerdo que Google contaba los links que había hacia una URL que contenía el meta canonical y traspasaba el valor…
Hola, Hay vídeo de la charla de Seonthebeach? saludos,
Hola @RicOriFra sí lo hay :), <a href="https://www.youtube.com/watch?v=CM9HOh3micE">al vídeo sobre Search Console</a> en el <a href="https://seonthebeach.es/">SEonthebeach</a>