Nuevo Google Search Console ¿qué información nos ofrecerá?
El otro día Google anunció que en breve pondrá a disposición de todos los usuarios la nueva versión de Google Search Console, a la cuál solo unos pocos han podido tener acceso en su versión Beta.
Si bien es cierto que no se ha dado mucha información por parte de estos privilegiados usuarios, la ayuda sobre esta nueva versión ya está online, y nos da muy buenas pistas de lo que se podrá ver en la nueva versión de Google Search Console.
En este último año hemos podido comprobar que Google intenta ofrecer más información a los webmasters sobre cómo ve Google cada site, tanto con problemas detectados como en recomendaciones para una mejor experiencia de los usuarios al navegar por nuestro site.
Creo que es un acierto por parte de Google intentar dar más información sobre determinados temas que ayudarán a resolver problemas que pueden estar influyendo negativamente en la visibilidad de su web y que son debidos a cuestiones técnicas.
Si Google consiguiese que todos los sites estuviesen libres de problemas y todo estuviese perfecto, todas las webs competirían en igualdad de condiciones para salir en los resultados de búsqueda, y en los factores para ordenar los resultados no entrarían en juego las dificultades técnicas de cada site. Como consecuencia los resultados que mostrase serían mejores que los actuales.
¿Qué información de Google Search Console podemos obtener de esta documentanción?
Voy a exponer aquí lo que más me ha llamado la antención, en algunas cosas hay que leerlas entre líneas para comprender de su posible importancia, pero creo que son estos detalles los que nos aportan información que antes no sabíamos o no teníamos la certeza de cómo eran.Vamos a analizar la documentación para las distintas funcionalidades de la nueva versión de Google Search Console y también vamos a ver una "antigua" versión de esta documentación, de hace un mes (Diciembre del 2017) para ver qué ha cambiado en este mes, y si esta es una información relevante.
En la antigua versión se informaba de que el número de urls que aparecenen los informes de Estado de la indexación podría disminuir en comparación con la versión clásica de GSC debido a que en la nueva versión solo muestra la información de las urls que actualmente se muestran en los resultados del buscador, mientras que en la versión clásica se mostraban todas las urls, estuviesen o no saliendo en las serps.
Classic Search Console reported many stale URLs that no longer appear in Search results. Therefore, if you used the Index Status report in classic Search Console, you may notice that the total indexed numbers shown in the new Index Status report are lower than the total indexed numbers in the older Index Status report. This is because the new report focuses on pages that are actually seen in Google Search in order to provide more useful and fresher data.
Esta información ha desparecido en la nueva versión de la documentación, no tengo ni idea del por qué....
Cobertura del índice

Podríamos decir que ya casi da más información que el actual GSC, te dirá que urls no están incluídas, cosa que hasta ahora no ofrecía.
Me llama la atención que en la descripción de "Excluida" porque tiene, en mi opinión, una contradicción. Dice "no se ha incluido la página en el índice por motivos que están fuera de tu alcance"mientras que también dice en esta misma línea "(por ejemplo, mediante una directiva noindex)".
El meta noindex es introducido por el webmasterpor lo que es un motivo que sí está al alcance del webmaster, pero bueno, no es una información relevante como SEO, quizás sí como miembro de la R.A.E., pero no SEO ;)
URLs con Errores

Aunque esta información la teníamos casi en su totalidad en la versión clásica de GSC (en diferentes informes), se ha añadido el estado de "Error de redirección" que podría ser provocado por causas como demasiadas redirecciones, redirecciones infinitas, longitud de url excesiva, etc.
Nos vendrá bien ya que no tendremos que pasar un crawler para poder saber el estado y funcionamiento de las urls que hacen redirección en nuestro servidor. En mi opinión, aquí podrían haber ofrecido también urls que hacen redirección a una url que da error404, algo muy habitual y que los webmasters no pueden obtener a no ser que sea mediante un crawler o un análisis de logs.
URLs con incidencias
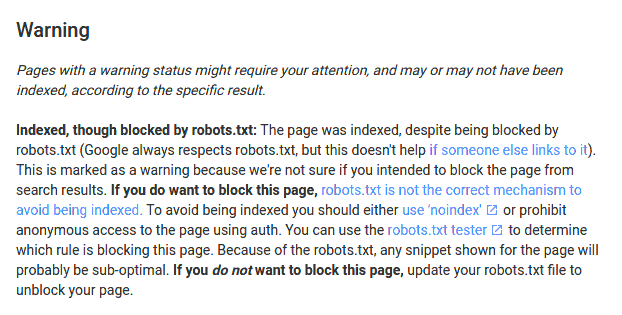
URLs válidas

Nos econtramos con un dato interesante, "Indexed; consider marking as canonical", la url fue indexa y debería ser marcada como canónica debido a que tiene urls dupliacadas.
Esta información como SEOs nos puede ser relevante, si Google nos da la lista de urls que cree son duplicadas, o si tenemos una sospecha muy clara de que urls podrían ser las duplicadas de esta url podríamos saber que url es la preferida de Google y así poner canonical desde las otras a esta, o modificar el enlazado interno para comprobar si cambia, o añadir contenido diferencial.
También podremos hacer a la inversa, si tenemos un grupo de urls duplicadas o con probabilidad de estar duplicadas podemos intentar averiguar cuándo dos urls dejan de ser duplicadas entre ellas y saber cuál es el mínimo que tenemos que trabajar para conseguir su diferenciación.
Otro dato muy relevante existía en la versión de Diciembre del 2017 como podemos ver en esta imagen, pero en la versión actual no está, Indexed, low interest.

Indexed, low interest la página fue indexada, pero aparece muy rara vez en los resultados de búsqueda....
GSC quizás nos de pistas de que urls (contenido) no está siendo mostrado en los resutaldos de Google por su baja calidad, si Google nos ofrece esta información podría ser una piedra angular del SEO. Nos daría mucho valor para la toma de decisiones sobre diferntes aspectos.
Decisiones técnicas:
- paginaciones, ¿las considera de baja calidad si están muy profundas? ¿sabe que son paginaciones?
- comentarios, ¿están aportando valor si son indexados?
- parámetros, aunque realmente ya existe posibilidad de "configurarlos" desde el actual GSC.
- mayúsculas / minúsculas, ¿tenemos problemas de duplicidad por esto?.
- etc
Aspectos de calidad:
- Contenido generado por usuarios.
- Calidad de los distintos tipos de contenido (textos, galerías de imágenes).
- Saber cuánto tenemos que trabajar el contenido para que deje de ser de bajo interés.
- Segmentar por urls y ver que secciones no están rindiendo como debiesen.
- Conocer cómo está tratando determinadas tipologías de páginas.
URLs excluidas
En este apartado vamos a ir por partes, porque hay bastante información y muy interesante.

Estos mensajes no nos dan nada nuevo que no supiéramos con la
versión clásica de GSC, quizás el mensaje de "Crawled - currently not
indexed ",que también nos podría dar pistas de qué urls no está mostrando
Goolge en los resultados de búsqueda.
Además, dice que estas urls puede
que se indexen y puede que no en el futuro. ¿Estarán en la cuerda
floja? ¿las estará tomando como contenido especial? habrá que
comprobarlo cuándo lo tengamos, pero podría ser interesante.
Ahora vamos a ver lo que más me ha llamado la atención, seguimos con los posibles estados de las urls marcadas como excluídas.

"Discovered - currently not indexed"
Un dato que me parece que valdrá para saciar la curiosidad de cuánto tarda Google desde que la rastrea hasta que la evalua y envia al índice. Pero creo que poco más valor nos ofrecerá.
"Alternate page with proper canonical tag"
Estosí me parece muy interesante, ya que con el grupo que antes he comentado " Indexed; consider marking as canonical" nos podría ayudar asaber que grupos de urls tiene Google de nuestro site marcadas como duplicadas, y cuál de ellas es la "buena" para el buscador. Nos ayudará aver si Google está entendiendo nuestras señales, o si por el contrario tenemos un problema porque no conseguimos hacer ver a Google que dos urls son contenidos duplicados y cuál queremos que sea la "buena". Sin duda una gran ayuda para el SEO, ya sea con buenas o malas intenciones.
"Duplicate page without canonical tag"
Otro estado dirigido a darnos pistas sobre qué urls está considerando Google como duplicadas, y en este caso, que no tienen el meta canonical. Parece que no, pero ya puestos estaría bien que nos indicara cuál cree él que es la url a la que debemos apuntar con el canonical de estas urls... por pedir que no quede!
"Duplicate non-HTML page"
Nosservirá de ayuda para nuestros archivos multimedia o PDF, ¿quizás también para detectar algún error como ficheros XML oJson que esté crawleando y contenga ese contenido? habrá que verlo :)
"Google chose different canonical than user"
Sobre canonicals casi era la única información que faltaba en esta lista,
Google nos dice que desde otras urls se está poniendo un meta canonical
hacia esta url, y que él piensa que no es la adecuada para serlo, que
hay otra mejor. Y que como él piensa que esta es duplicada de otra
entonces no la indexará, porque solo indexa las urls "buenas" (o url
canónica).
¿Nos está diciendo Google que confía más en su decisión algorítmica que
en nuestra decisión? pues claramente sí!!. Creoque Google debería dar
más valor a las señales que los SEOs / Webmasterle enviamos, por lo
menos en determinados casos como las urls canonicals.
Podría haber mil
motivos razonables por los que querríamos indicar a Google que url es la
buena, aunque Google piense que es otra. Por ejemplo si el webmaster
sabe que las urls viejas se van duplicar porculpa de una migración de
plataforma, o porque el CMS en cuestión tratadeterminadas cosas de
deteriminada manera... creo que habría que convertir más señales en
directivas. Pero esto será otro post;)
"Submitted URL dropped"
Parece que Google nos informará de las urls que ya no están en el índice, no sé si se referirá a porque han tenido algún problema o bien por otras causas.Ambas cosas nos servirán seguro para ver si hay urls que podrían estar desindexándose por algún fallo no controlado, lo que sin lugar a dudas será de gran utilidad cuándo en el equipo de IT haya algún kamikaze que sube sin ton ni son, o para despiestes que tengamos cualquiera a la hora de configurar algún meta, robots, etc.
Filtro desplegable de descubrimiento de URL

De esto solo tengo una duda, dónde pone "Se considera que una URL se ha enviado mediante un sitemap aunque también se haya descubierto a través de otro mecanismo" ¿querrá decir que si cruzamos los datos de páginas conocidas con las páginas enviadas podremos obtener las urls descubiertas por google que no encontramos en el sitemap.
Si Google marca cualquier url que aparece en los sitemaps como "url de sitemaps" se podría comprobar las urls que están en "Todas las páginas conodica" y que no están en "Todas las páginas enviadas" son las urls que Google está rastreando y que no tenemos incluídas en sitemaps, información útil para detectar qué URLs no previstas está viendo Google de tu site.
Solución de problemas
Esta es otra de las grandes novedades que parece tendrá la nueva versión de GSC, un proceso más serio para avisar a Google de la resolución de los problemas vistos en los informes anteriores, a ver si con suerte tenemos un botón de "ocultar este error en futuras ocasiones" para que no arroje ruido errores de los que ya somos conscientes y no podamos / creamos / queramos solucionar, y con opción de ver estos errores ocultos en los informes y poder volver a marcarlos como visibles cuándo queramos... por pedir que no quede!
Esperemos que Google implemente esta información, de momento en la documentación ha desaparecido.
Más o menos esto eslo que he visto relevante de esta documentación, seguro que se me escapan cosas que son importantes y no he mencionado, no dudes en añadirlas en los comentarios, en Twitter o dónde quieras, pero compártelo, compartir es saber!
Comentarios
3Lee otros artículos
Diferencia de datos en Search Console para webs pequeñas dependiendo del método que usemos
Comparativa de los datos en la nueva exportación que Search Console a través de Big Query en sites PEQUEñOS
Diferencias entre la exportación de datos de Search Console usando BigQuery o usando la API
Características de la exportación de Search Console a BigQuery
Keywords grouping using Google Search Console data
Publish at October, 25 of 2021 by Lino Uruñuela Table of Contents Classifying keywords vs. grouping search terms Classifying keywords based on a previously defined list Grouping search terms Usually, the simpler, the better it works. Looking at the code Create a dictionary for specific words Accept that there are thin…
Agrupación - Clustering de keywords SEO en Google Search Console
Publicado el día 30 de agosto del 2021 por Lino Uruñuela índice de contenido Agrupación de Keyword SEO Objetivos Tokenización Normalización Lematizació Vs Stemming Código Machine Learning para SEO Quiero dejar algo claro, no soy experto en Machine Learning, pero sí de sus tecnologías o hacia dónde va la cosa, que es m…
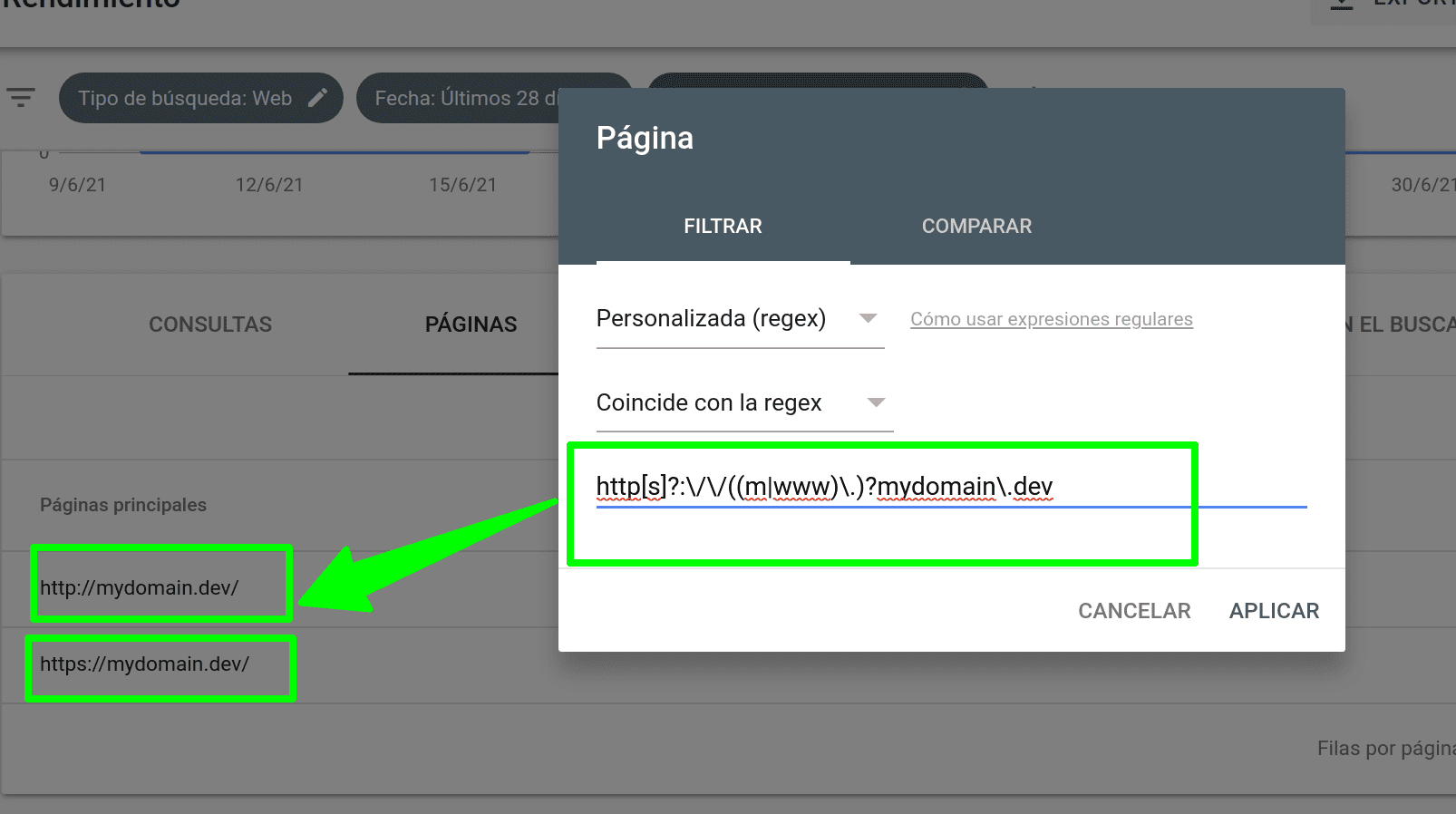
Expresiones regulares para SEO (Google Search Console)
Publicado el 8 de julio del 2021 por Lino Uruñuela Hace poco Google Search Console a nunciaba una de sus opciones más deseadas, poder filtrar usando expresiones regulares. No voy a ponerme a explicar qué son las expresiones regulares y para qué se pueden usar, ya hay información muchísimo mejor que la que yo pueda ofr…
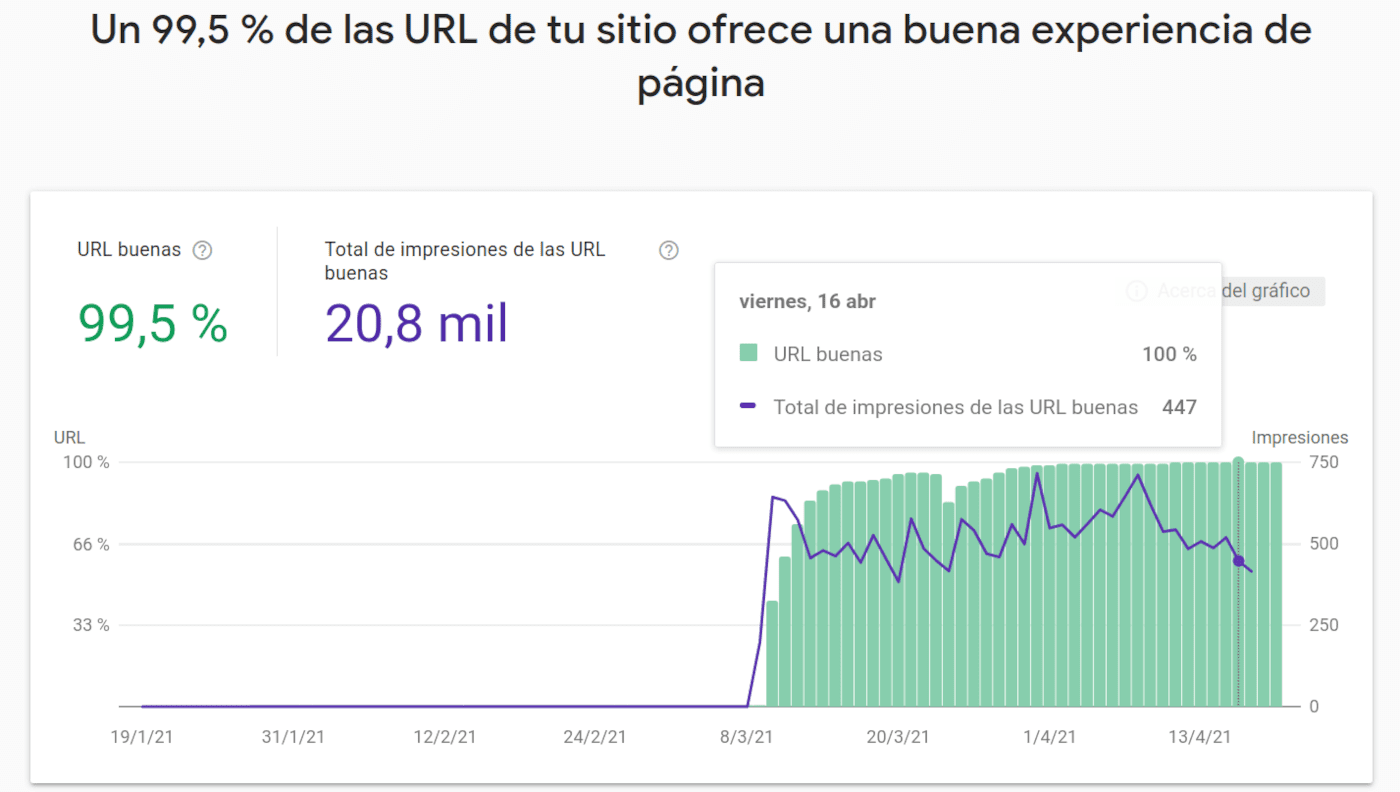
Informe de experiencia en la página - Google Search Console
Por Lino Uruñuela Desde hace tiempo Google avisa e informa de determinados cambios en cómo trata, evalúa o muestra determinados resultados. En mi opinión, cuando Google avisa de algo con cierto margen de tiempo para que nos vayamos preparando es que no tendrá apenas repercusión, por ejemplo, tal y como ha hecho anteri…
Comprender los datos Google Search Console
Publicado el 14 de enero del 2021 Índice de contenido Límite de filas usando la API de Google Search Console Consultas por Propiedad o por Página Cuantas más dimensione, menos URLs únicas Algo que normalmente la gente que no se ha pegado mucho con los datos de Google Search Console no conoce es cómo funciona el l ímit…
Informes y gráficas usando la API de Google Search Console
Mediante la API de Google Search Console creamos informes que no podrás obtener mediante el interface web
Datos incoherentes y cálculo de la posición media en Search Console
Publicado el lunes 29 de julio del 2019 por Lino Uruñuela Métricas Posición Cálculo de la posición media Impresiones Clicks Dimensiones Informe de Rendimiento vía Web Limitaciones del interface web Consolidación de datos Hace muchos años que Google lanzó Search Console , aunque su nombre inicialmente fue Google Sitema…
Consolidación de urls canónicas en Google Search Console
Publicado el 27 de febrero del 2019 por Lino Uruñuela En el año 2018 Google parece haber apretado el acelerador en el desarrollo y mejora de Google Search Console con nuevos diseños y nuevas funcionalidades, pero también desaparecen, al menos de momento, otras funcionalidades. No voy a entrar en cada novedad o cada fu…
Gracias Lino! Para "ocultar" errores en plan de andar por casa tiro de robots. Por otro lado, estamos ante una genial actualización que debería haber llegado hace 10 años. Es interesantísimo todo lo que comentas. Se va a poder sacar mucha chicha para portales grandes. Si tuviese que quedarme con una tool de todo el universo seo, sería esta. Echo en falta detección de los típicos errores de cosas en rojo de los crawlers, comentabas 301 a 404, pero también 301 a canonicals, etc. Hablas que debería fiarse más de los canonicals, pero hablas de tu experiencia y con confianza en que lo haces bien. Hay mucho cafre por ahí y muchos canonicals muy mal puestos y en muchos casos Google favorece a sus dueños obviando sus meteduras de pata. Un saludo
@Javi sí, sobre que hay mucho cafre por ahí, tienes razón, pero es como el robots.txt es "peligroso" en manos inadecuadas, igual que el noindex, y debería ser igual con canonical. El SEO cada vez es más complejo y cada vez con más especificaciones, protocolos, etc. Creo que debería dar más capacidad de decisión a los propietarios del site, por lo menos para determinadas cosas
Gracias por la información!