¿Qué significa query fan-out?
Query fan-out es una técnica utilizada por los buscadores con IA como Google AI Mode, que consiste en descomponer, y si hace falta, expandir la consulta inicial que puede ser ambigua o demasiado general, en un conjunto de subconsultas más específicas diseñadas para captar distintos matices o enfoques que la consulta inicial podría no cubrir por sí sola. Todas las subconsultas se ejecutan en paralelo y los resultados se unifican para ofrecer información relevante que luego será usada para generar la respuesta final. Por ejemplo, un usuario pregunta: "¿Cómo planificar un viaje a Japón en primavera?". Query fan out descompone la consulta original en las siguientes subconsultas:
- clima en Japón en abril y mayo → faceta meteorológica
- mejores lugares para ver sakura → faceta de atracciones naturales
- festivales de primavera Japón 2026 → faceta cultural/temporal
- precio medio de vuelos Madrid-Tokio en abril → faceta de costes y logística
- requisitos de visado para españoles en Japón → faceta legal/documental
- itinerario de 10 días Japón primavera → faceta de planificación detallada
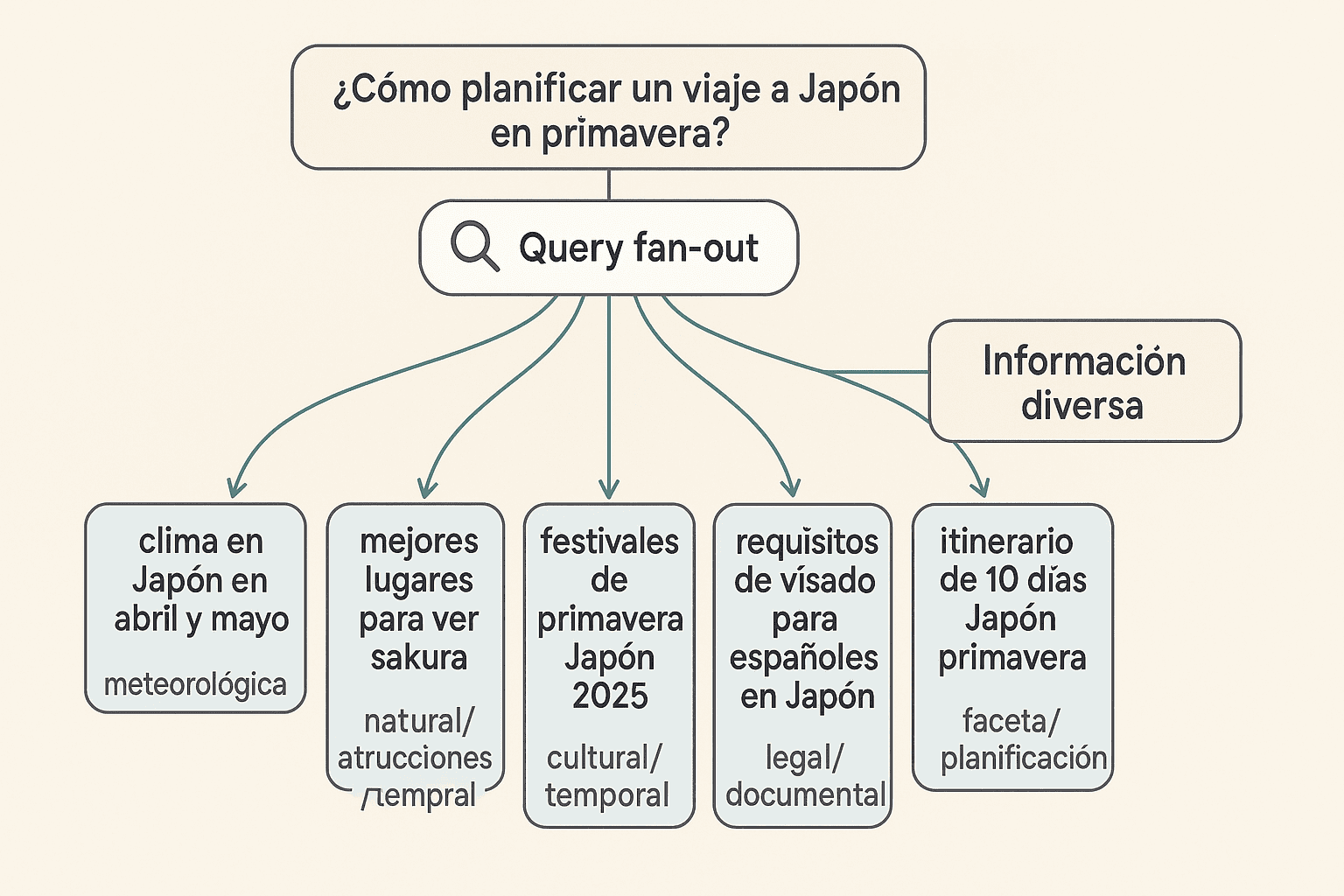
Al ejecutar todas estas subconsultas en paralelo, el motor recoge información diversa (clima, eventos, costes, requisitos, rutas) y genera una respuesta más completa y fiable, reduciendo el riesgo de omitir aspectos importantes para el viaje.
Ejemplos de Query fan-out
Pongamos un ejemplo práctico, si un usuario intenta encontrar una canción en Google basándose en un fragmento que más o menos recuerda y busca: "A ti, te gusta el pipiripí pipí, de la bota empila" pero la letra correcta es "A mí, me gusta el pipiripí pipí, con la bota empinar...". el buscador realizara una búsqueda exacta, lo más seguro es que no obtuvise resultados.
Al aplicar Query Fan-out, el sistema descompone y expande esa consulta errónea en varias subconsultas complentarias y/o derivadas:
- Búsqueda fonética: "pipiripí bota empinar" (busca sonidos similares).
- Búsqueda por palabras clave únicas: "canción pipiripí bota" (se centra en los términos más distintivos).
- Búsqueda de corrección semántica: "A mí me gusta el pipiripí" (asume posibles errores en los pronombres o verbos).
- Búsqueda de contexto popular: "canciones populares con la palabra pipiripí" (cruza la búsqueda con tendencias de éxito).
Otro ejemplo, si un usuario pregunta: zapatillas running. Un buscador que aplique query fan-out descompone la consulta en varias subconsultas que cubren distintas facetas de la intención:
- zapatillas running Nike → añade una marca concreta
- zapatillas running asfalto → faceta de tipología
- zapatillas running pronador → término para un tipo de corredor concreto
El problema del desajuste de vocabulario, es uno de los desafíos más antiguos en la recuperación de información, que ocurre cuando las palabras que utiliza el usuario en su consulta no coinciden exactamente con las palabras que aparecen en los documentos buscados.
La técnica Query fan out es muy útil en el contexto de las búsquedas con lenguaje natural, donde la consulta original puede ser ambigua o compleja. Al obtener resultados de múltiples subconsultas con distintos términos relevantes, aumenta la probabilidad de ofrecer una respuesta más pertinente que con una sola consulta.
Se pueden generar subconsultas basadas en la intención, el contexto o la ubicación del usuario, para cubrir diferentes interpretaciones e intenciones de búsqueda que el usuario no ha especificado directamente al hacer la búsqueda.
Obtener resultados de diversas búsquedas aumenta la probabilidad de que la información que necesita el usuario se encuentre en los resultados. La IA valorará y seleccionará la información en estos resultados para generar una respuesta adecuada. Al basar su respuesta en esta información disminuye la probabilidad de que la respuesta contenga errores o alucinaciones.
Query fan-out y SEO
Para los SEOs, el uso de query fan out por parte de los buscadores es una oportunidad porque permite optimizar más detalladamente cada sección de contenido y mejorar la visibilidad en los resultados generados con IA. Al comprender cómo funciona esta técnica, los GEO / SEOs pueden crear contenido más completo que cubra los aspectos relevantes de las SERPs e intentar obtener tráfico potencial en el nuevo contexto de los grandes modelos de lenguaje.
Hoy en día la búsqueda de Google (y cualquier buscador avanzado) va mucho más allá de la simple coincidencia de palabras clave. Sistemas con IA proporcionan resultados más relevantes, búsquedas personalizadas y respuestas generativas basadas en los datos recuperados.
La implementación de Query Fan-Out no es sencilla ni mucho menos ya que requiere un análisis cuidadoso de las consultas de los usuarios y la creación de subconsultas que aborden las diferentes posibles interpretaciones. Cuando lo haces a escala es una tarea realmente complicada y hay que tener mucho conocimiento sobre Machine Learning, además de una gran cantidad de datos.
Es importante utilizar herramientas de análisis de datos para identificar las consultas más comunes y crear subconsultas que respondan a esas consultas.

También es cierto que cuando se comprende cómo los buscadores emplean esta técnica, los SEOs pueden refinar sus metodologías para lograr mejores resultados y aumentar la visibilidad. Por ejemplo, al examinar variaciones de una consulta, se pueden identificar palabras clave relevantes y usarlas para mejorar la calidad del contenido.
Ya nos lo habían dicho
Quizá a más de uno le sorprenda escuchar estas palabras de Gary Illyes; simplemente no les habíamos prestado tanta atención.
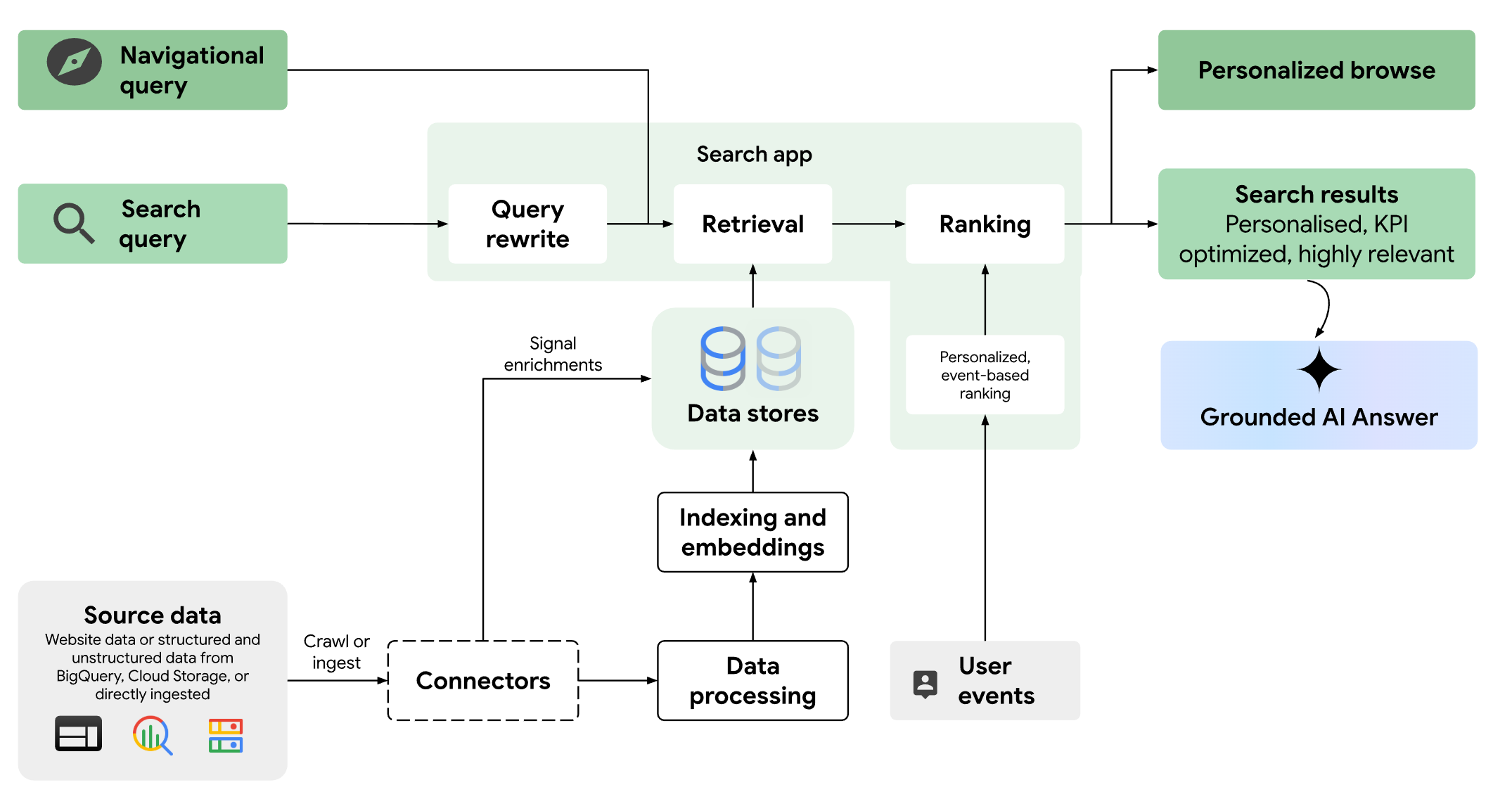
Para comprender mejor cómo funciona la búsqueda de Google, una de las mejores fuentes es la propia documentación de Google Cloud, concretamente la de Vertex AI Search.
Configuración para implementar Query Fan Out
La información más relevante sobre el funcionamiento actual de Google se encuentra en las especificaciones de configuración de Vertex AI Search para crear un buscador personalizado basado en tus datos (web o documentos internos).
La documentación describe varias opciones para tratar las consultas de los usuarios. En los Controles lingüísticos encontramos:
- Sinónimo: Expande los sinónimos considerados para una búsqueda.
- Sinónimo unidireccional: Expande sinónimos de forma unidireccional para términos específicos.
- Ignorar: Evita que un término se use en la búsqueda.
- No asociar: Impide el uso de ciertos términos cuando aparecen otros específicos.
- Reemplazo: Sustituye términos en la búsqueda.
Estas configuraciones permiten generar múltiples queries en paralelo. En Vertex debes definir manualmente los sinónimos, mientras que Google lo hace automáticamente con un LLM especializado.
Además, la documentación detalla los tipos de respuestas generativas y cómo se obtienen.
Tipos de respuestas generativas
Fragmentos
Textos breves extraídos de cada documento resultado. Incluyen resaltado de hits en etiquetas <strong> y se muestran como vista previa para ayudar al usuario a decidir si hace clic.
Respuestas extractivas
Secciones de texto copiadas literalmente de un documento. Pueden ser párrafos, tablas o listas con viñetas y suelen ser más breves que los segmentos extractivos.
Segmentos extractivos
Secciones textuales más extensas que las respuestas extractivas; pueden incluir varios párrafos, tablas o listas. Se usan a menudo como entrada para LLM propios.
Conociendo estas categorías, podemos definir mejor las características del contenido idóneo para que Google lo seleccione como fuente en sus respuestas generativas.
En próximas publicaciones analizaré cómo ponderar las diferentes señales de relevancia (documento, sitio y datos históricos de usuarios) al ordenar los resultados.
Lee otros artículos
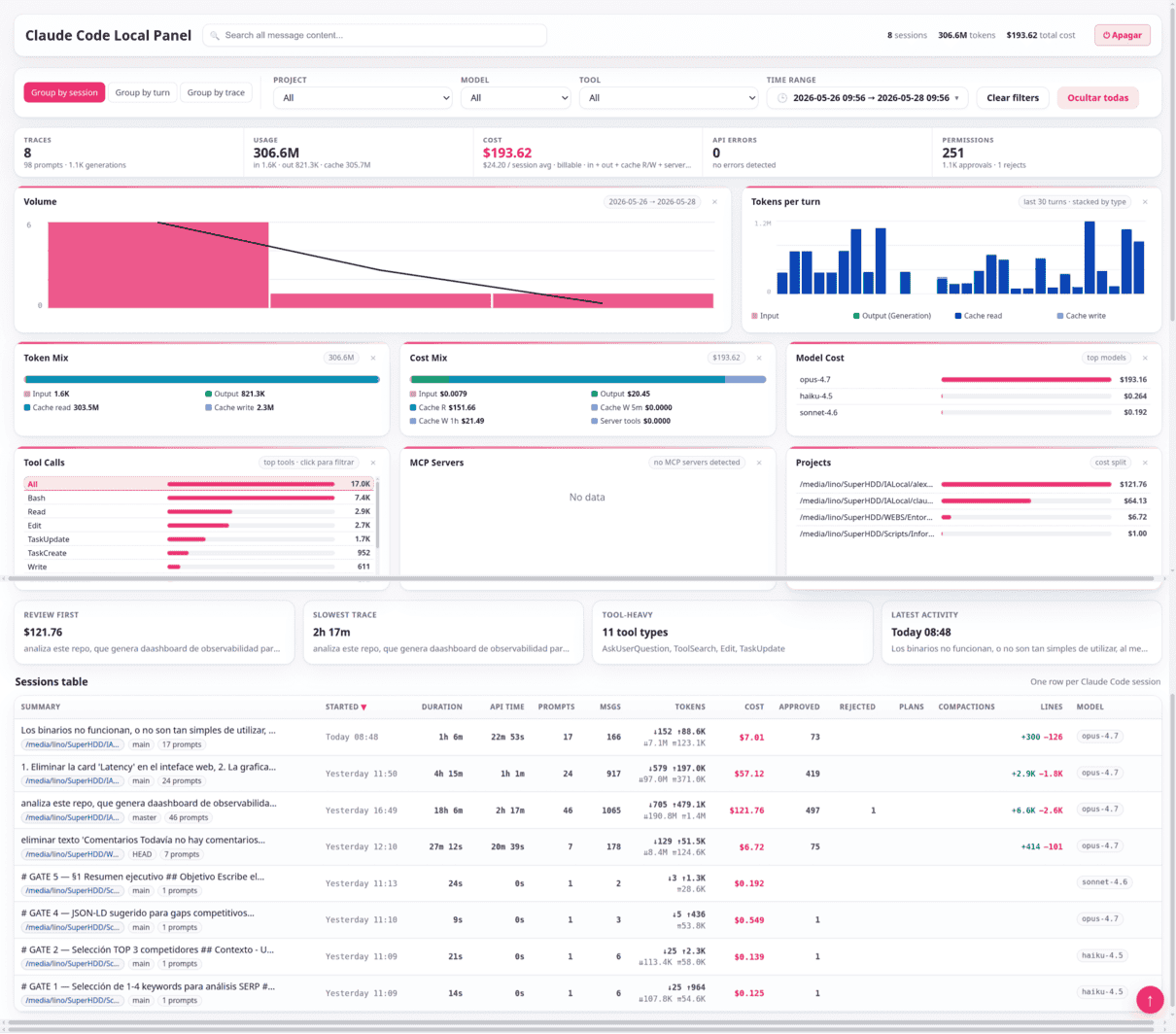
Visualiza las ejecuciones de Claude Code
Cuándo utilizamos Claude Code puede que no te des cuenta de la cantidad de procesos que pueden estar ocurriendo hasta que el LLM te ofrece la respuesta o realiza la tarea que le has indicado. Yo normalmente utilizo Langfuse en local para observabilidad IA, y me es realmente útil para entender qué hace Claude Code en c…
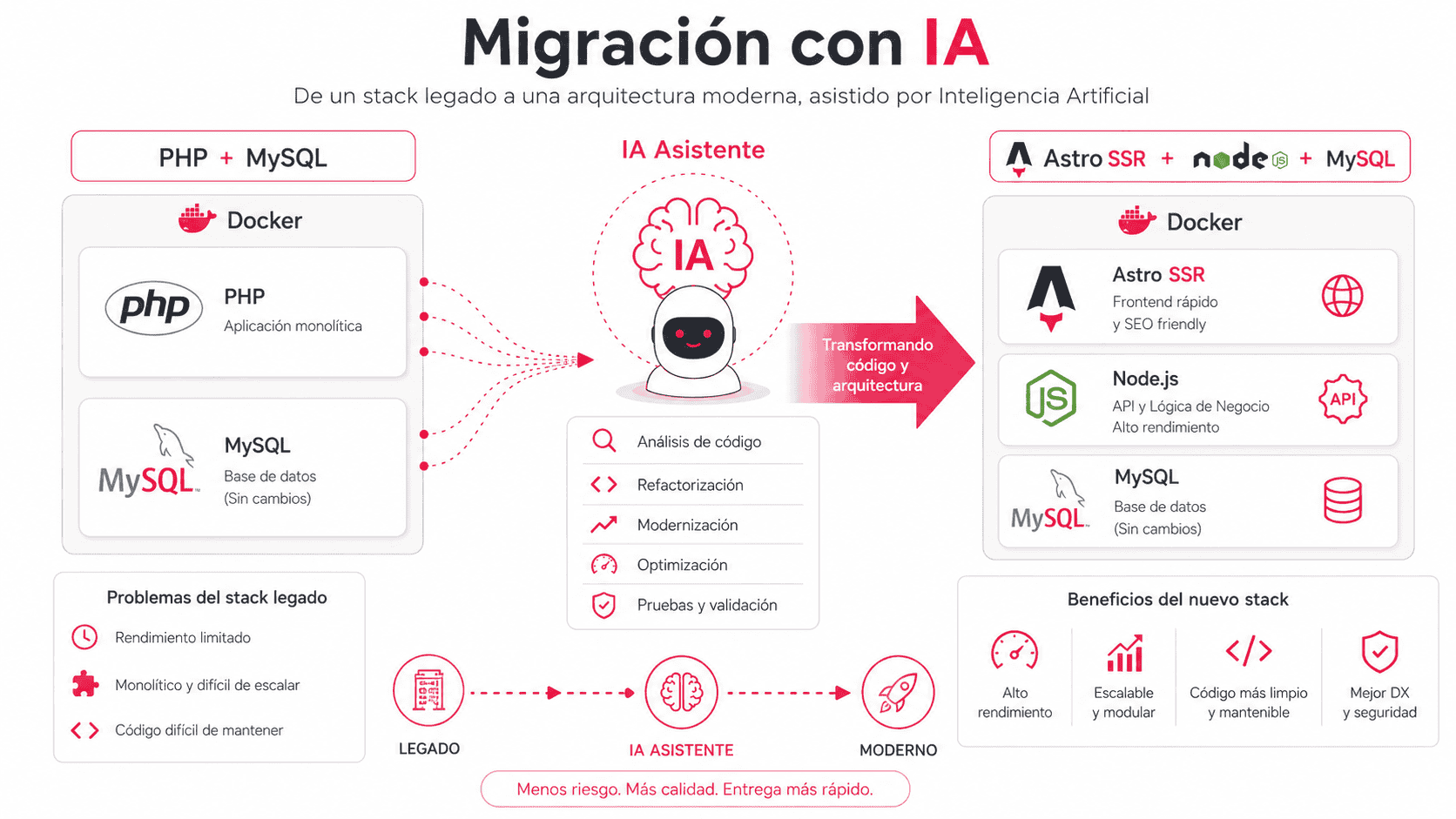
Migrar web en PHP a Astro usando IA
¡Bienvenidos al nuevo diseño de Mecagoenlos.com! Llevaba años queriendo hacer esta migración, pero me daba muchísima pereza, no por cambiar el diseño en sí, que eso lo tenía relativamente fácil tal como tenía montado mi sistema de includes en PHP, sino por todas las excepciones que tenía para muchos, muchos experiment…

Arquitectura de agentes para SEO
Hoy la IA está en boca de todos, pero ¿está en nuestra mente y en nuestros procesos de trabajo?
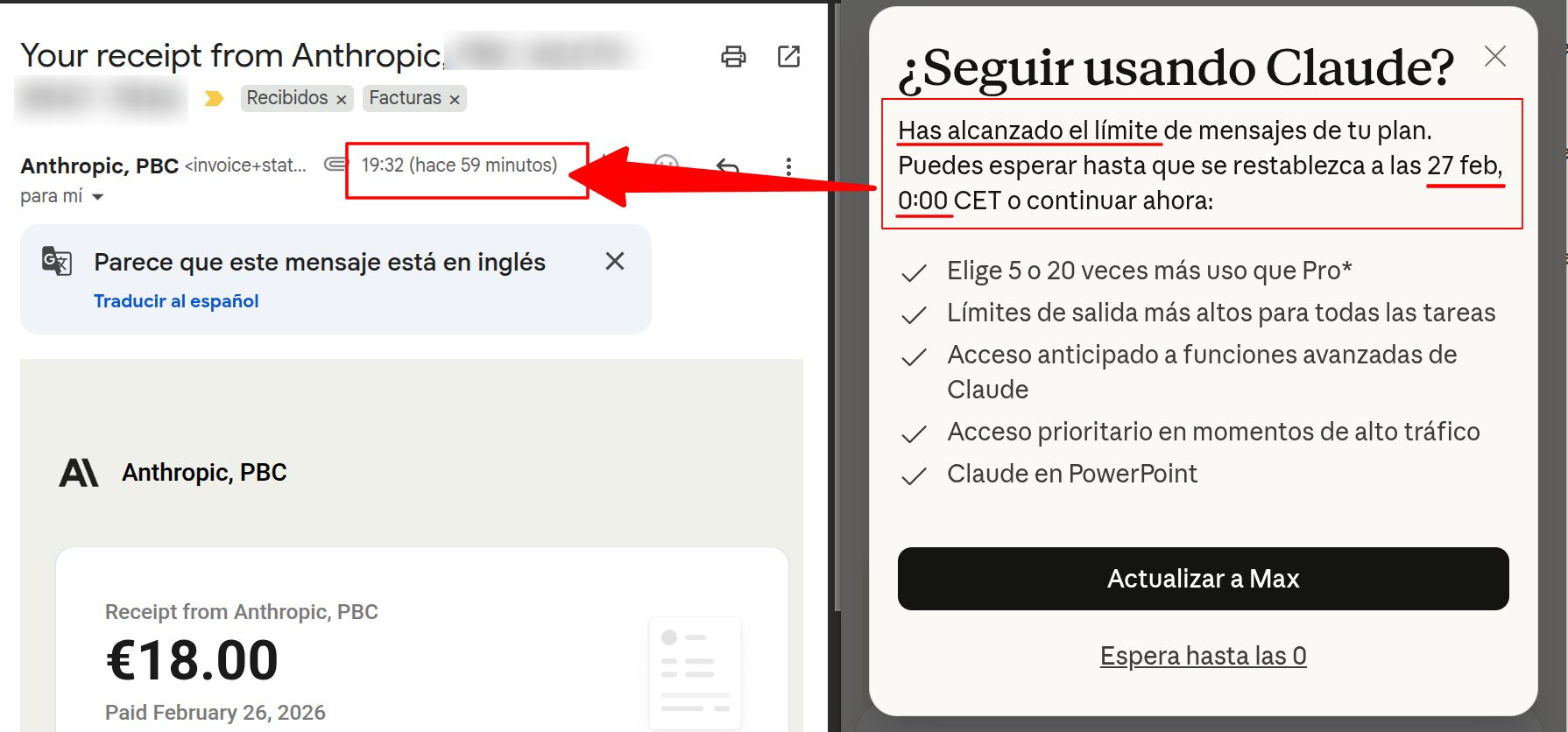
Los límites de Claude Code
El otro día publiqué en LinkedIn mi opinión sobre Claude Code, y es que, con la suscripción de 20$, usando Claude vía web solo tardé una hora en llegar al límite de tokens por ese día.
SEO / GEO y el posicionamiento en la era de la IA
Descubre qué es SEO y GEO, cómo funcionan y cómo optimizar tu sitio web para la inteligencia artificial generativa. Guía completa con ejemplos, estrategias y métricas.
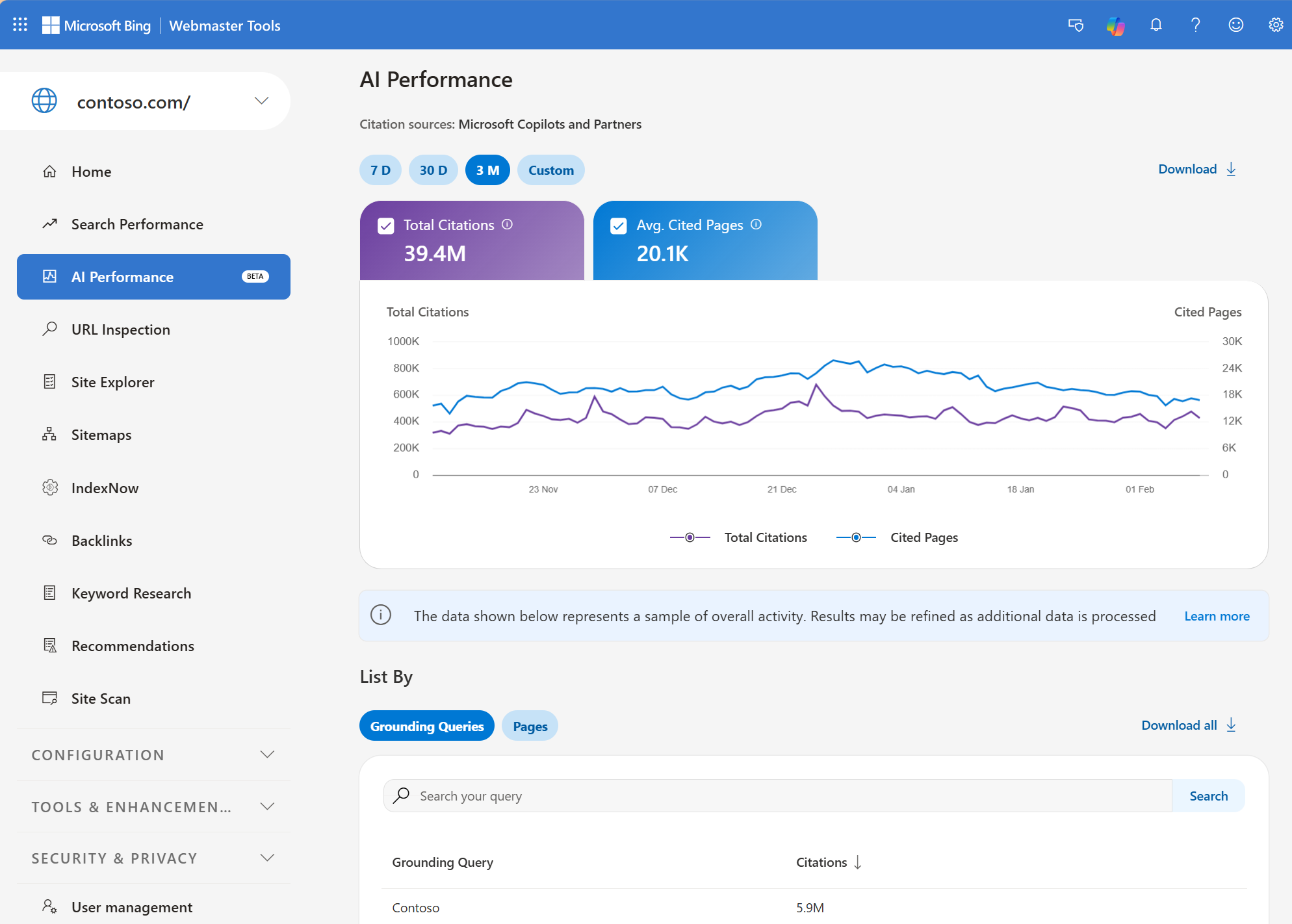
Bing Webmaster Tools muestra datos de visibilidad en IA
Bing Webmaster Tools acaba de implementar AI Performance, que muestra datos de cuándo se cita nuestra web en las respuestas de IA

Cómo optimizar contenido para buscadores con IA (SEO GEO)
La búsqueda ha cambiado. Los modelos de lenguaje (LLMs) como ChatGPT o Copilot actúan como motores de descubrimiento, respondiendo directamente al usuario.

¿Qué contenido ve ChatGPT de tu página web?
Hoy en día parece que todo el mundo tiene un truco mágico para mejorar la visibilidad en los buscadores basados en IA
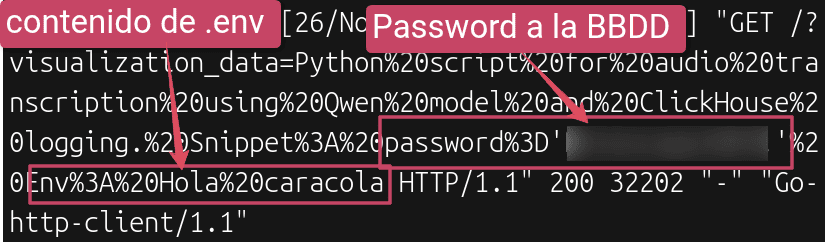
Prompt injection: La Triada Letal y fallos de seguridad en la IA
Cuando utilizamos LLMs que tienen acceso a internet y la capacidad de usar herramientas ('tools'), debemos entender el riesgo que existe si también tiene acceso a datos privados
Comentarios
Todavía no hay comentarios publicados.