Extraer Consultas de Busqueda mediante la API de WMT
Hace tiempo que no escribo con frecuencia, pero eso está cambiando!
Para motivarme voy a comenzar una serie de post donde explicar cómo usar distintas APIs de Google, y hoy vamos a comenzar con la API de Webmaster Tools, vamos a recoger los datos de las consultas de búsqueda de nuestro site y lo meteremos en una base de datos para poder luego manejarlos a nuestro antojo.
Los datos que vemos en la herramienta para webmasters, en la opción de Consultas de Búsqueda tenemos las KWs por las que nuestro site ha sido mostrado en los resultados de Google (OJO, mostrados, no que entren). Estas KWs puede ser una muy buena fuente de información para varias cosas, por ejemplo
- KW Research
Cada vez está más complicado hacer un buen KW Research debido al famoso Not Provided y a que los principales navegadores y sistemas operativos miran más por la privacidad de sus usuarios y no envían el referer completo como antes. Por ello, cualquier fuente de palabras y términos que podamos obtener será bienvenido. El histórico de estos datos en WMT es de tres meses, anterior a ese periodo no puedes ver más, por lo que hace muy útil y funcional tener guardados esos datos con nuestros propios medios.
- Cálculo de visitas Not Provided
Sabiendo las impresiones que han causado cada KW y sabiendo la landing a la cual llegaron estos usuarios podrías asignar un valor a cada landing para la kw not provied (esto será otro post..).
- Vigiliar cambios en los rankings para cada búsqueda
El cómo calcula Google el dato de posición media es un poco confuso, aunque parezca claro el nombre de la columna de ese dato "Posición media" no sabemos en base a que varía esa posición, podemos suponer que depende de la localización del usuario que hace la búsqueda, el dispositivo que use, el idioma, etc... pero no lo tenemos claro, pero sí nos puede servir como una alerta si vemos que cae la posición media.
Para guardar estos datos tenemos dos opciones, o vamos descargando los datos día a día exportándolos en un excel o usamos la API.
Digo que descargamos los datos día a día porque así son mucho más fiables y más completos, si descargas los últimos 3 meses de una vez tenemos un cierto límite. Y es que si te descargas los datos día a día vemos que obtenemos más KWs que si lo hacemos en un periodo mayor. Posiblemente Google esté sampleando los datos y te ofrece al igual que en Analytics una muestra de datos. Por eso yo recomiendo recoger estos datos día a día.
Si queremos obtenerlos día a día y guardarlos de una forma que luego nos pueda ser útil lo ideal es usar la API y guardar estos datos en una base de datos, yo lo hago con MySql. Para ello lo primero que vamos a hacer es crear una tabla donde recogerlos
CREATE TABLE WMT_Consulta_Busquedas (
cod_wmt int(11) NOT NULL AUTO_INCREMENT,
wmt_kw varchar(245) COLLATE utf8_spanish_ci DEFAULT NULL,
impresiones int(11) DEFAULT NULL,
clicks int(11) DEFAULT NULL,
CTR varchar(45) COLLATE utf8_spanish_ci DEFAULT NULL,
rank varchar(45) COLLATE utf8_spanish_ci DEFAULT NULL,
cambioClicks varchar(45) COLLATE utf8_spanish_ci DEFAULT NULL,
cambioRank varchar(45) COLLATE utf8_spanish_ci DEFAULT NULL,
fecha varchar(45) COLLATE utf8_spanish_ci DEFAULT NULL,
PRIMARY KEY (cod_wmt)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COLLATE=utf8_spanish_ci
Ya tenemos la tabla en nuestra BBDD, ahora hay que llenarla!!
Yo he usado esta clase para PHP y si no usáis PHP aquí tenéis la documentación, seguro que buscando se encuentra fácilmente ejemplos para todos los lenguajes de programación más comunes, phyton, php, java, etc
Yo he creado dos ficheros, uno llamado consultas-busqueda.php y otro gwtdata.v2.php (podéis descargarlos desde aquí) donde el primero en la primera líneaincluye al segundo. Lo hago así porque se puede cambiar fácilmente los datos de acceso a las webs que quieres.
Al abrir consultas-busqueda.php veremos en las primeras líneas las variables a cambiar con nuestros datos
$email = "EmailAccesoAnalytics@gmail.com"; //email de acceso a analytics $password = "******"; //contrasena de acceso a analytics $website = "http://www.tudominio.com/"; //tu dominio $_SESSION["tablaConsultaBusqueda"] = "WMT_Consulta_Busquedas"; //tabla $FechaHoy = date("Y-m-d"); $FechaInicial = date("Y-m-d",strtotime('-1 day',strtotime($FechaHoy))); $FechaFinal = date("Y-m-d",strtotime('-3 month',strtotime($FechaInicial))); mysql_connect("localhost","user","password"); //datos de la BBDD mysql_select_db("nombreBBDD"); //nombre de la BBDD |
Cambiando estas líneas con vuestros datos el script descargará un excel con todas las consultas de búsqueda por día y las introducirá en vuestra BBDD.
Y hasta aquí el primer post de la serie de posts sobre APIs útiles para el SEO. Pronto la segunda!!
Comentarios
3Lee otros artículos
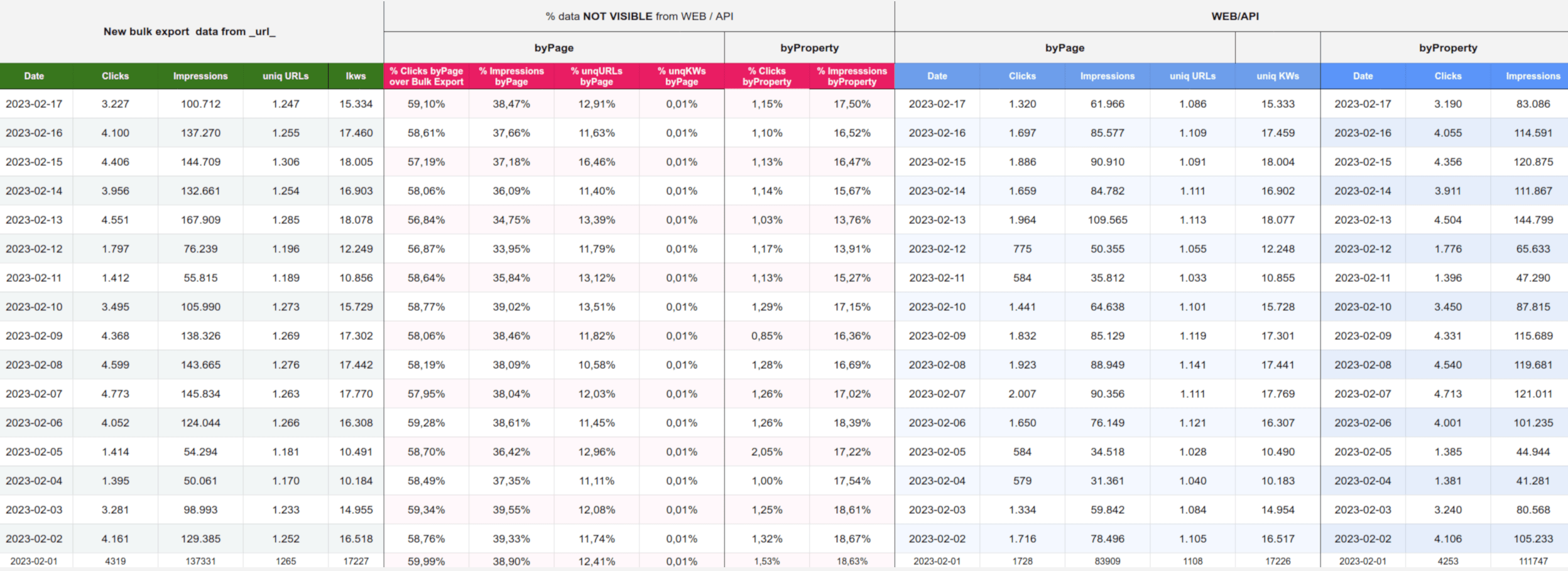
Diferencia de datos en Search Console para webs pequeñas dependiendo del método que usemos
Comparativa de los datos en la nueva exportación que Search Console a través de Big Query en sites PEQUEñOS
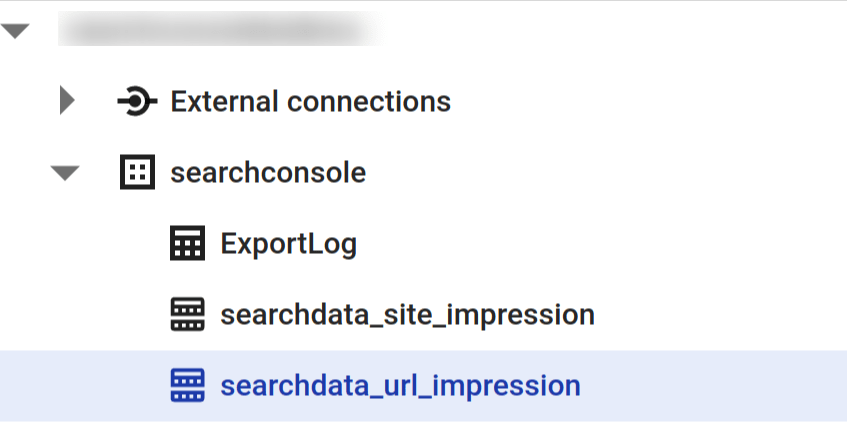
Diferencias entre la exportación de datos de Search Console usando BigQuery o usando la API
Características de la exportación de Search Console a BigQuery
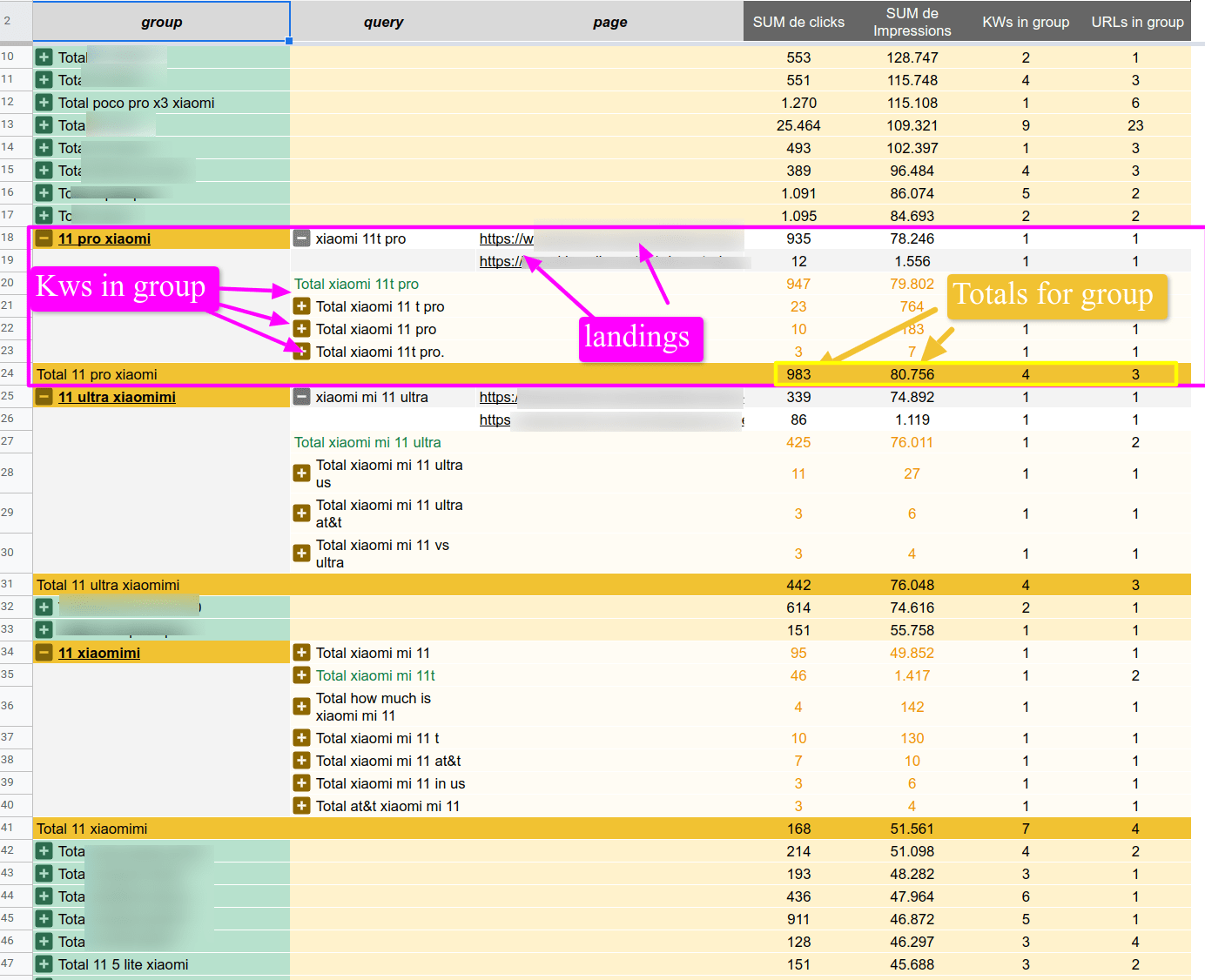
Keywords grouping using Google Search Console data
Publish at October, 25 of 2021 by Lino Uruñuela Table of Contents Classifying keywords vs. grouping search terms Classifying keywords based on a previously defined list Grouping search terms Usually, the simpler, the better it works. Looking at the code Create a dictionary for specific words Accept that there are thin…
Agrupación - Clustering de keywords SEO en Google Search Console
Publicado el día 30 de agosto del 2021 por Lino Uruñuela índice de contenido Agrupación de Keyword SEO Objetivos Tokenización Normalización Lematizació Vs Stemming Código Machine Learning para SEO Quiero dejar algo claro, no soy experto en Machine Learning, pero sí de sus tecnologías o hacia dónde va la cosa, que es m…
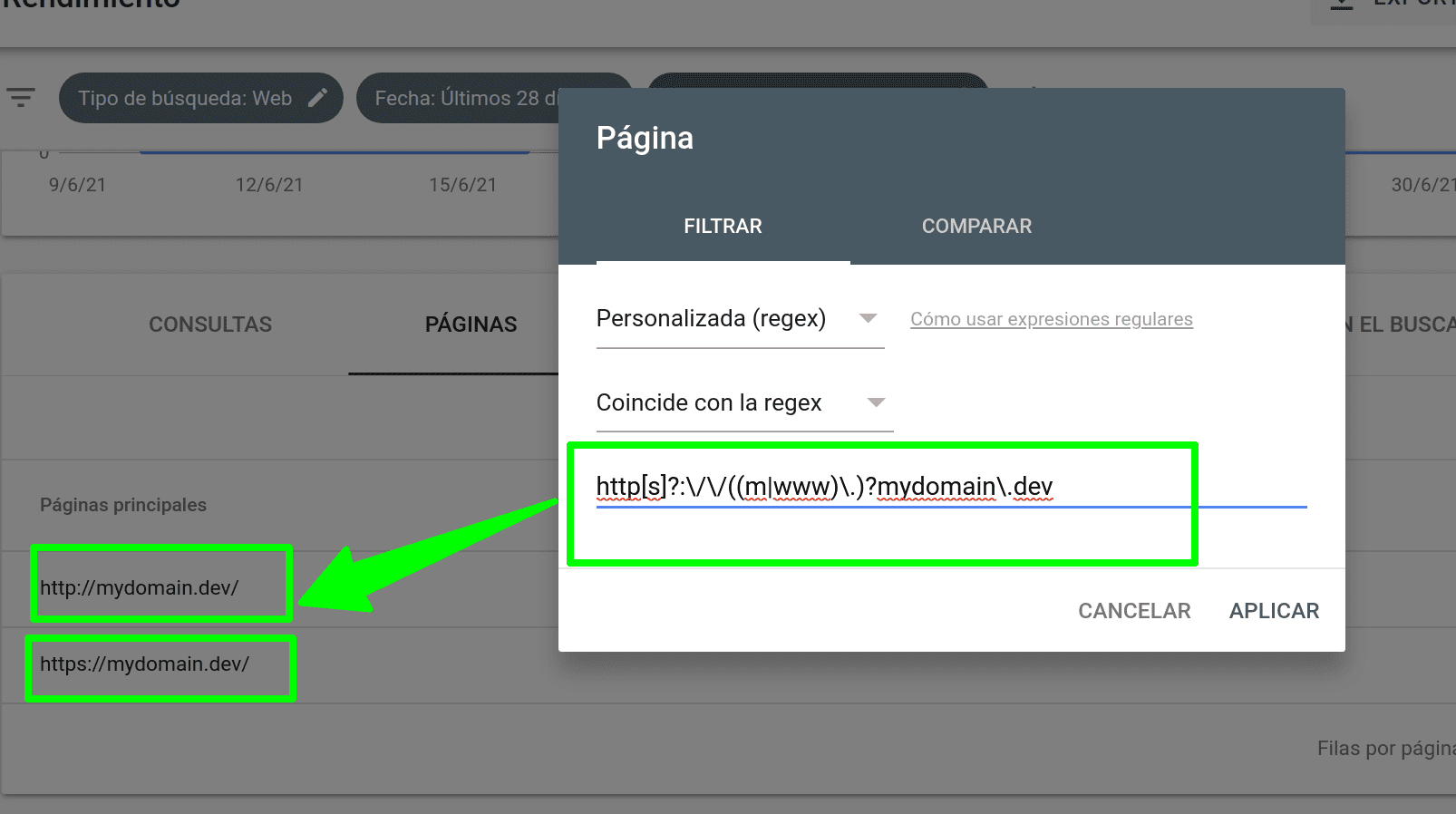
Expresiones regulares para SEO (Google Search Console)
Publicado el 8 de julio del 2021 por Lino Uruñuela Hace poco Google Search Console a nunciaba una de sus opciones más deseadas, poder filtrar usando expresiones regulares. No voy a ponerme a explicar qué son las expresiones regulares y para qué se pueden usar, ya hay información muchísimo mejor que la que yo pueda ofr…
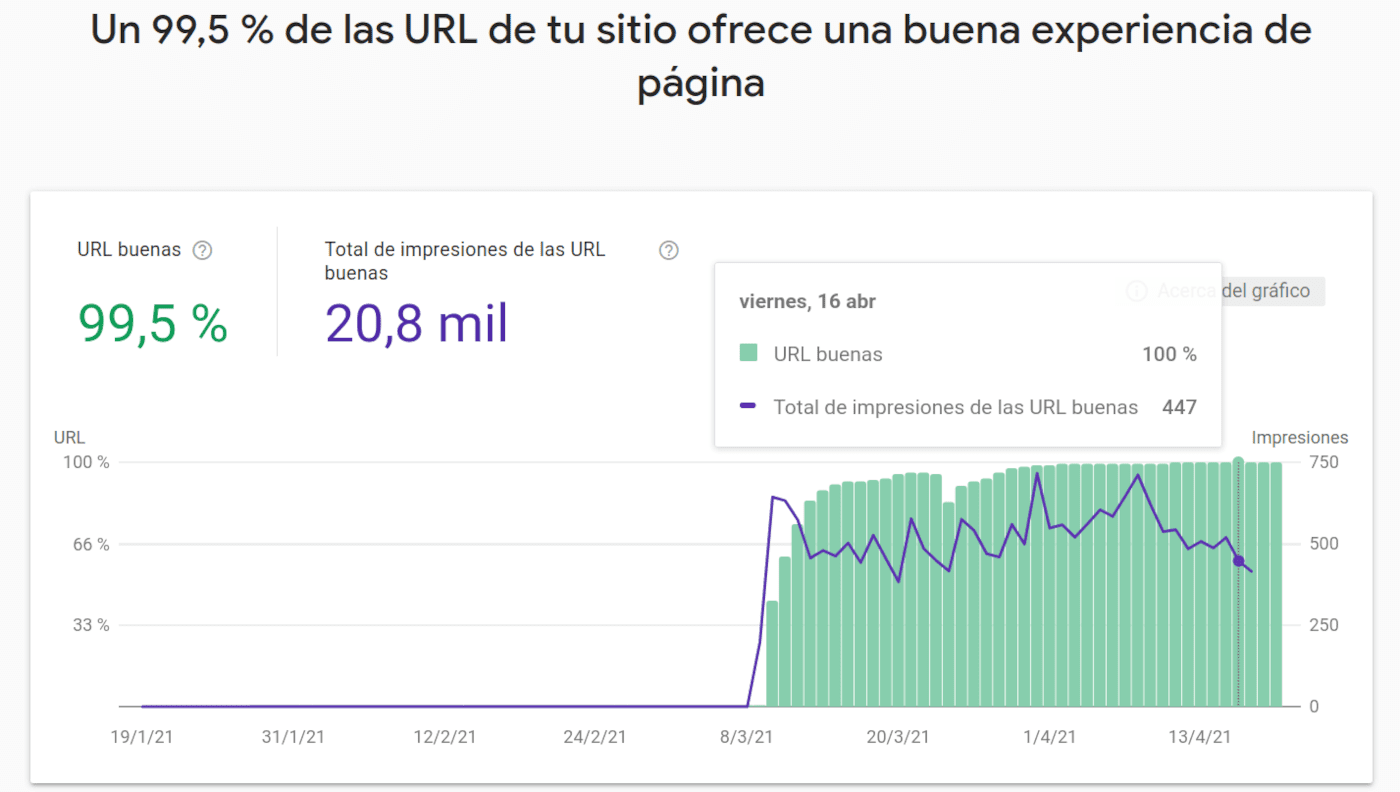
Informe de experiencia en la página - Google Search Console
Por Lino Uruñuela Desde hace tiempo Google avisa e informa de determinados cambios en cómo trata, evalúa o muestra determinados resultados. En mi opinión, cuando Google avisa de algo con cierto margen de tiempo para que nos vayamos preparando es que no tendrá apenas repercusión, por ejemplo, tal y como ha hecho anteri…
Comprender los datos Google Search Console
Publicado el 14 de enero del 2021 Índice de contenido Límite de filas usando la API de Google Search Console Consultas por Propiedad o por Página Cuantas más dimensione, menos URLs únicas Algo que normalmente la gente que no se ha pegado mucho con los datos de Google Search Console no conoce es cómo funciona el l ímit…
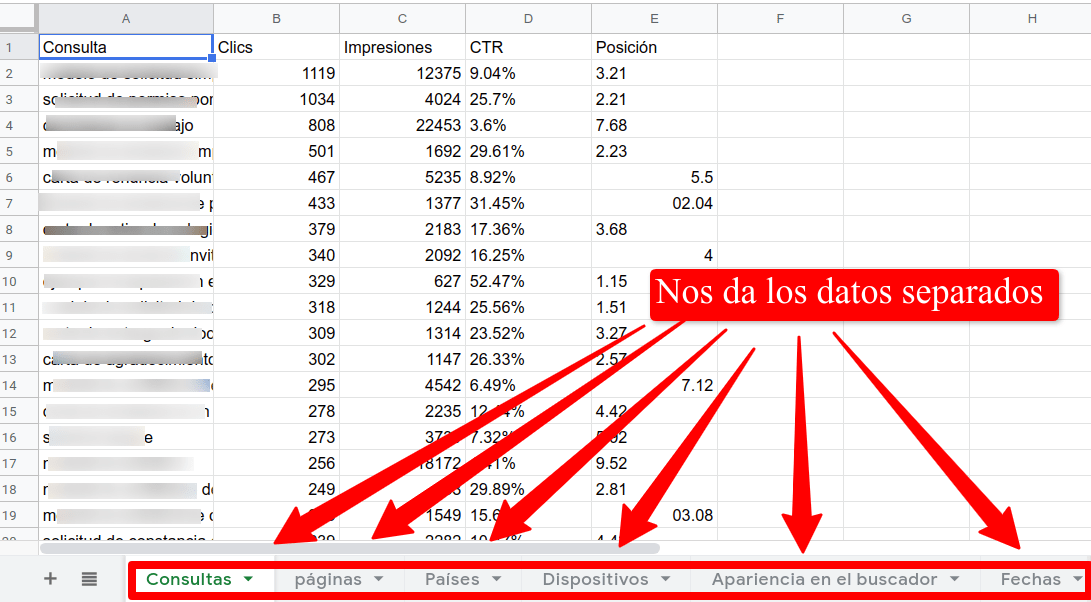
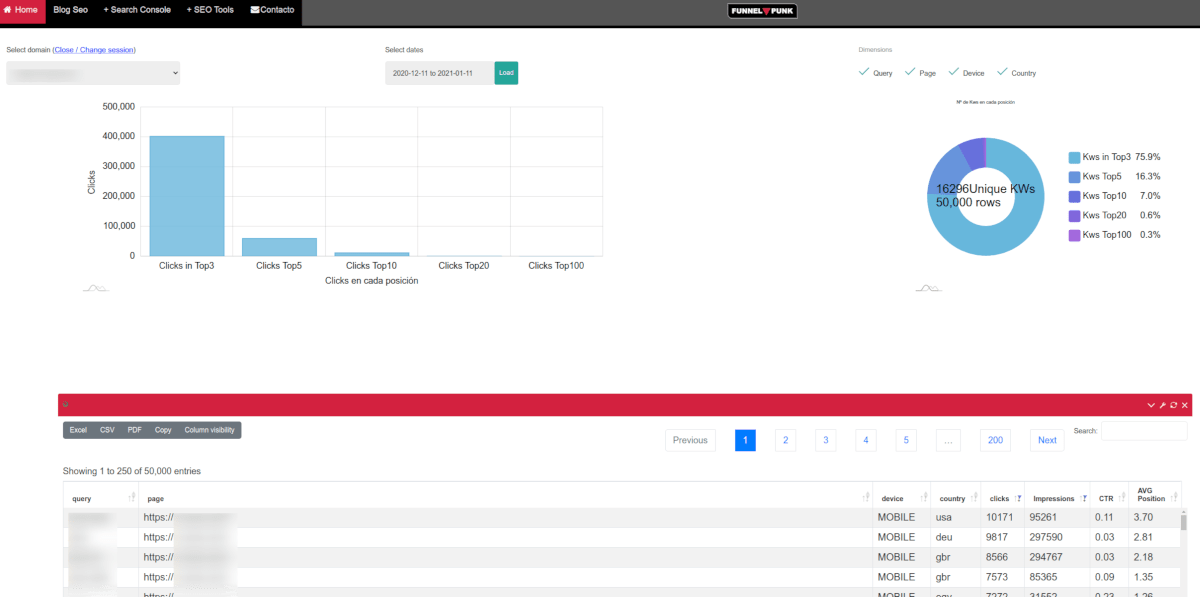
Informes y gráficas usando la API de Google Search Console
Mediante la API de Google Search Console creamos informes que no podrás obtener mediante el interface web
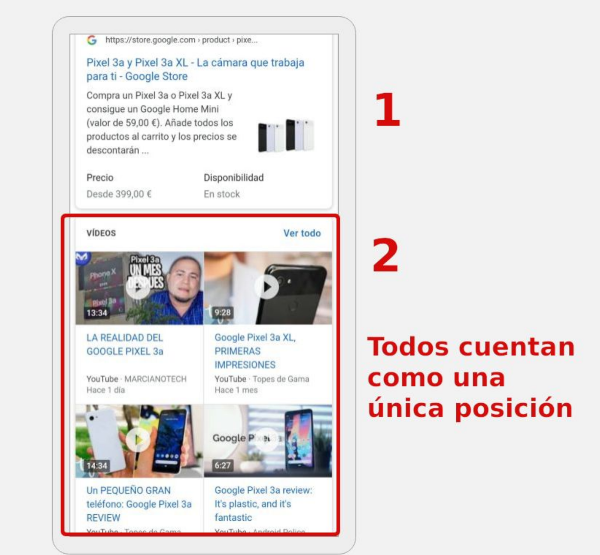
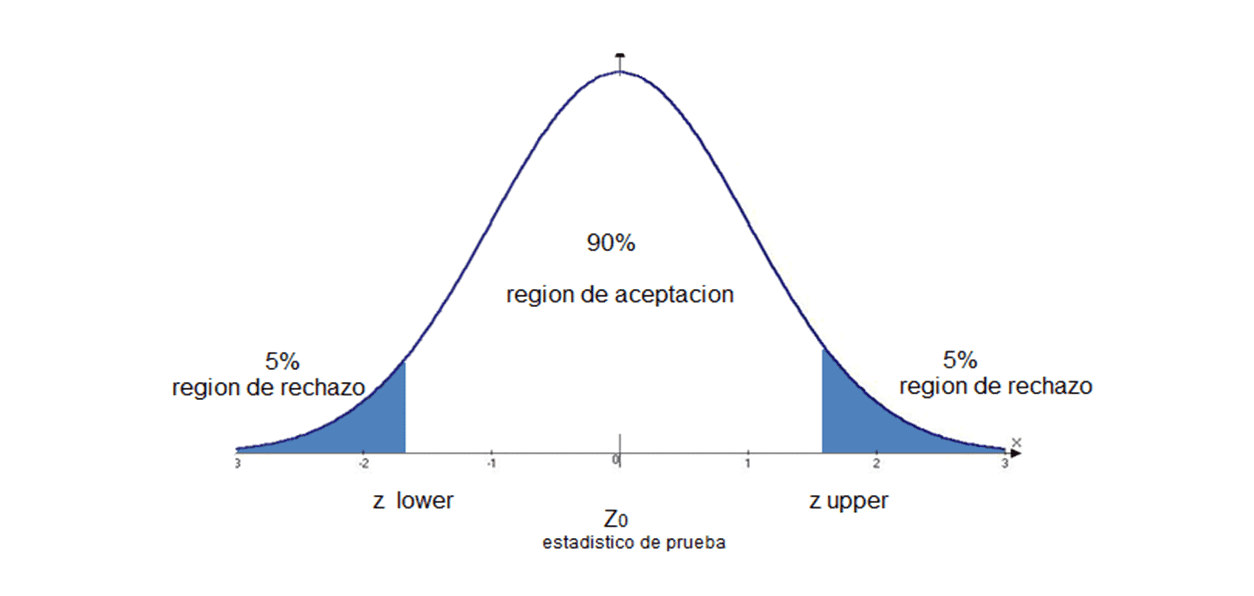
Datos incoherentes y cálculo de la posición media en Search Console
Publicado el lunes 29 de julio del 2019 por Lino Uruñuela Métricas Posición Cálculo de la posición media Impresiones Clicks Dimensiones Informe de Rendimiento vía Web Limitaciones del interface web Consolidación de datos Hace muchos años que Google lanzó Search Console , aunque su nombre inicialmente fue Google Sitema…
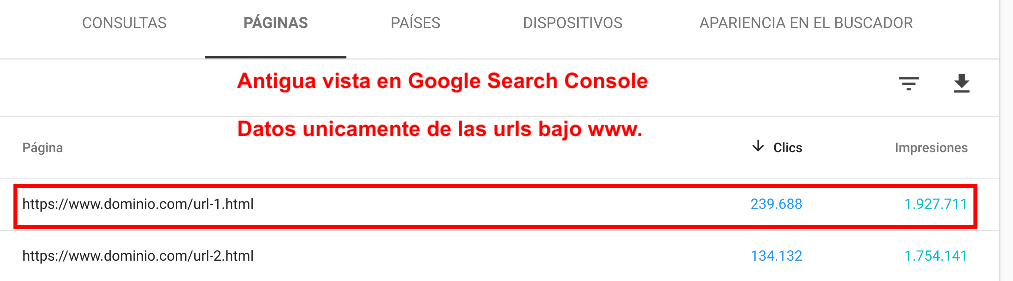
Consolidación de urls canónicas en Google Search Console
Publicado el 27 de febrero del 2019 por Lino Uruñuela En el año 2018 Google parece haber apretado el acelerador en el desarrollo y mejora de Google Search Console con nuevos diseños y nuevas funcionalidades, pero también desaparecen, al menos de momento, otras funcionalidades. No voy a entrar en cada novedad o cada fu…
El que no pude descargar desde hace tiempo es el de errores de rastreo :-(
Hola, Yo utilice este método con xamp más el php en una carpeta en local ejecutaba el php y todo ok se descargaban los datos. pero con no me dejaba descargar todos los tipos de consultas que se pueden obtener de WGT. no recuerdo cual era la que no me descargaba si top_pages, top_querys, etc... ¿tu puedes descargar todos los tipos de datos? Saludos!
@Alberto la verdad es que no he probado, los errores los miro con los logs del server :)