Keywords grouping using Google Search Console data
Publish at October, 25 of 2021 by Lino Uruñuela
Table of Contents
First of all, special thanks to Gaston Riera for helping me with the translation!
At Funnel Punk we have been working on grouping data for quite a while, some of which are based on keywords. Some of the uses we have for these databases are finding duplicates or title tag analyses.
As a sneak peak, this is an example of the final result we will get at the end of the article, a table grouping keywords (that for 99% of the cases mean the same), and we will also be able to see a breakdown for each term and for each URL.
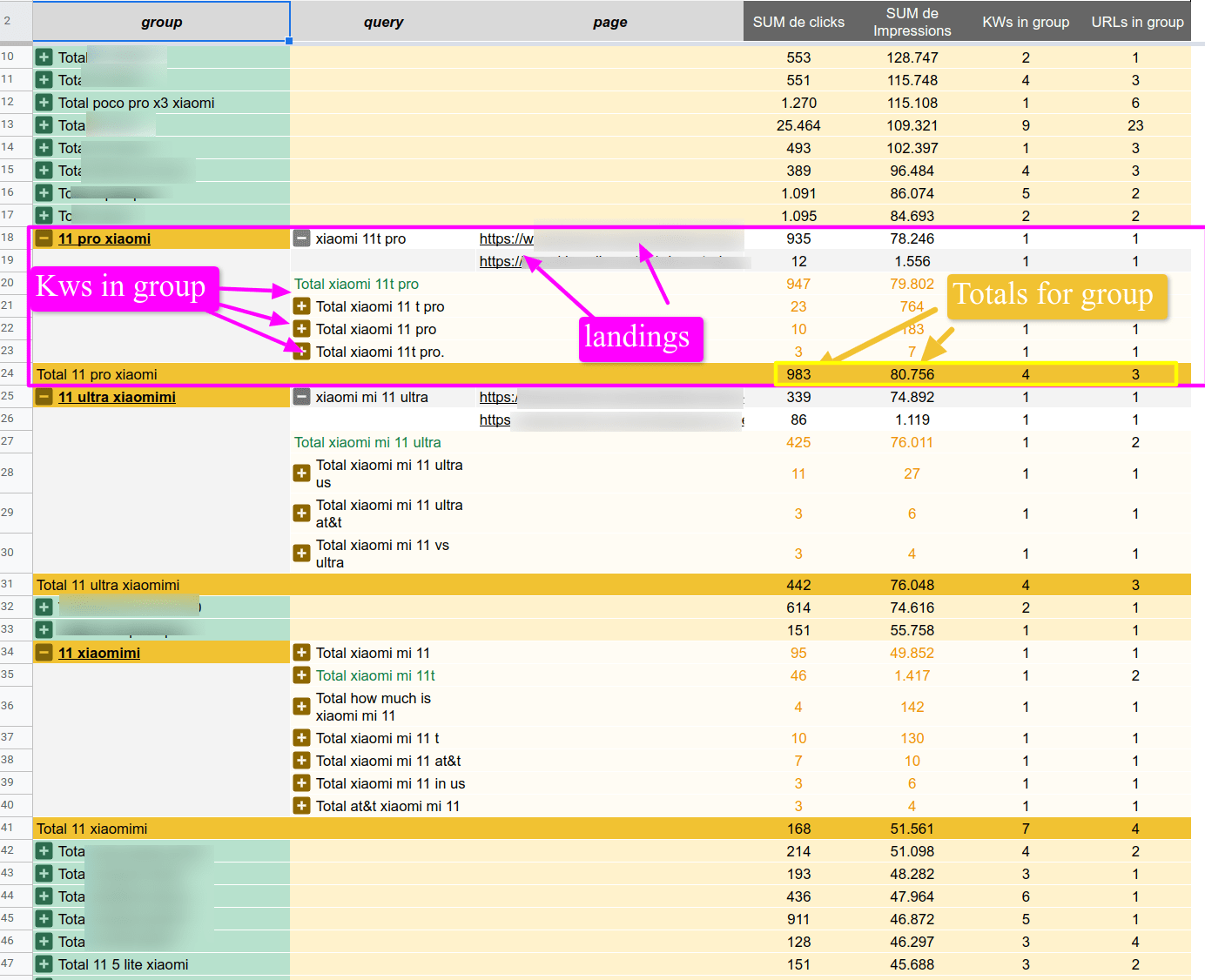
Classifying keywords vs. grouping search terms
Classifying keywords based on a previously defined list
There are already lots of articles and templates that use different methods to classify keyword intention as transactional, informational and others, but I haven’t yet found an actionable grouping method that significantly improves the understanding of the variety of keywords by their meaning and not just by their search intent.
Classifying by search intent is helpful to find out if these keywords are relevant to the business, or for example, to customers in their buying journey. Yet, that does not help understand the entire universe of keywords, and it doesn’t make sense for all sites.
At FunnelPunk, we are actively trying to improve the grouping and classification of keywords… As long as it makes sense for the website :)
To me, grouping or clustering is different from applying rules that determine whether a keyword falls into any given category. In my opinion, that is classifying or categorising. As I said earlier, it’s very helpful for certain things, yet not so much to understand the whole universe of search terms that users use, related to the different topics of our website.
Grouping search terms
This method will show you clicks or impressions and URLs for the keywords in each particular cluster, and all of this without losing the search intent behind each term.
Having this info will help us have a complete view of each search intention and get other useful insights, such as having a better understanding of whether the clusters are well defined and that there are no ambiguous or incorrect terms.
It could also help find out if there is any other issue due to cannibalisation. However, if that was the case, a way deeper analysis would be required, as there can be cases of either positive or negative cannibalisation.
Usually, the simpler, the better it works.
In this example, we won’t use words vectors such as word2vec, nor will we use semantics to determine if a word is a name, adjective, verb, etc to assign one or another meaning depending on that. Won't even use the usual 'King - male + female = Queen' (I don’t like repeating what others are already doing).
The keywords that we SEOs use contain a few words and knowing that users usually don't follow proper grammar nor semantics when searching makes it useless to try to assign a meaning according to that keyword being contained within a "phrase".
As we did in a previous article when lemmatising, there won't be as many groupings and, verbs that have the same search intent or meaning within that keyword can be included in different groups when differentiating them depending on their tense or position in the sentence.
Let's use an example of lemmatisation vs. stemming, for those who didn't read that other article
print("Stem")
print(stem_sentences(normalize("ESP8266 module connect to arduino")))
print(stem_sentences(normalize("ESP8266 module connected to arduino")))
print(stem_sentences(normalize("ESP8266 module to arduino connecting")))
print(stem_sentences(normalize("Connected ESP8266 modules to arduino")))
print(stem_sentences(normalize("Connected ESP8266 module to arduino")))
print(stem_sentences(normalize("ESP8266 module connected to Arduino")))
print("Lemmatize")
print(lematizar(normalize("ESP8266 module connect to arduino")))
print(lematizar(normalize("ESP8266 module connected to arduino")))
print(lematizar(normalize("ESP8266 module to arduino connecting")))
print(lematizar(normalize("Connected ESP8266 modules to arduino")))
print(lematizar(normalize("Connected ESP8266 module to arduino")))
print(lematizar(normalize("ESP8266 modules connected to Arduino")))
Result
Stem
arduino connect esp8266 modul
arduino connect esp8266 modul
arduino connect esp8266 modul
arduino connect esp8266 modul
arduino connect esp8266 modul
arduino connect esp8266 modul
Lemmatize
arduino connect esp8266 module
arduino connect esp8266 module
arduino connect esp8266 module
arduino connected esp8266 modules
arduino connected esp8266 module
arduino connect esp8266 modules
We can see how the lemmatisation method is not the best one for our goal.
On the contrary, the stemming method gets it every time, grouping every term under the same group. That's why I think getting stems for the keyword grouping leads to much better results than lemmatisation, even though the latter is more sophisticated.
Taking a look at the code
I will explain a few things about this code.
Create a dictionary for specific words
It is important to mention that this dictionary is different from having a list of STOPWORDS, that is because the dictionary is a list of words that otherwise would be excluded, and the STOPWORDS list contains words that will be omitted (unless you don’t use that list)
Other than STOPWORDS, we are using rules to value or not specific words. Taking a look at the code, within the normalisation function there is code that looks like this:
words = [t.orth_ for t in doc if not t.is_punct | t.is_stop]
lexical_tokens = [t.lower() for t in words if len(t) > 2 and t.isalpha() or re.findall("\d",t)]
The first line stores every word, according to two conditions, with "if not t.is_punct | t.is_stop":
-
- is_punct: looks for punctuation to be omitted, for example (. , : ;). Keep in mind that we don't want to omit every one of them, there might be cases where punctuation is an important part of our keywords.
For example, when users search "how to set up a robots.txt to block Google from crawling?" the word 'robots.txt' is a relevant keyword for SEOs. - is_stop: filters out keywords that are in the stopwords list. The following line, lexical_tokens = [t.lower() for t in words if len(t) > 2 and t.isalpha() or re.findall("\d+", t)] has another three conditions:
- len(t)>2: considers words valid only when they have more than 3 characters. Don't forget to check what 2 characters words we have in our database.
- isalpha(): filters out anything that is not alphanumeric, such as emojis.
- re.findall("\d",t): this one prevents the code from omitting numbers.
- is_punct: looks for punctuation to be omitted, for example (. , : ;). Keep in mind that we don't want to omit every one of them, there might be cases where punctuation is an important part of our keywords.
Imagine that we are working on a website that writes about technology and in their keyword list they have: "xiaomi mi 11", "xiaomi mi 11 12 gb", "xiaomi mi 5g", "xiaomi mi 11 5g", "xiaomi mi 11 6 gb", every keyword contains ‘mi’ and this is why it is important to capture 2 character words, otherwise we would end up grouping them all under ‘xiaomi’.Clearly they have to be in their own group: ‘xiaomi mi’
With the last line, the one with re.findall("\d",t) we are capturing all digits and preventing them from being ignored. This step will vary in importance, depending on the project.
Continuing with the earlier example, without ignoring digits the list should look like this:
-
- "xiaomi mi 11" → "xiaomi 11"
- "xiaomi mi 11 12 gb" → "xiaomi 11 12"
- "xiaomi mi 5g" → "xiaomi 5g"
- "xiaomi mi 11 5g" → "xiaomi 11 5g"
- "xiaomi 11 6 gb" → "xiaomi 11 6"
Yet, this is not enough as it is not capturing the phone model (‘mi’). To fix that, we can use the dictionary, and what needs to be done is to update the terms “xiaomi mi” with “xiaomimi”.
Given that the term ‘mi’ has two characters, is in the STOPWORDS list and we want to prevent it from being ignored, taking it out of the STOPWORDS list is not a good idea. That would allow that word to be used in other keywords that don’t have anything to do with the cluster, such as “Precio de mi Movil” (Spanish for “how much is my phone worth”) is not closely related to “Xiaomi”, however, if the term was “precio de mi Xiaomi mi” it should be included.
A way to do that substitutions is by using regular expressions, such as the one below which every 2 letter word that is of interest for us is substituted by the merge of the two words. With that substitution, these words will not be ignored. Suggestions to improve this part are always welcome!
re.compile(r'^mi (.*)'): r'xiaomimi \1',
re.compile(r'(.*) mi (.*)'): r'\1 xiaomimi \2',
re.compile(r'(.*) mi$'): r'\1 xiaomimi'
Accept that there are things out of our control
When it comes to Machine Learning, (although this example isn’t “Learning”) most of us copy code we find on the internet, and that’s ok! It is important to know that depending on the project and/or the problem at hand, things can get very complex quickly. Even more if you have never worked in production environments, it is even worse in large companies.
I won’t stop repeating myself; remember that to become a Data Scientist, you need five years of Math studies and at least another four of a PhD to have enough experience and knowledge to fully abstract any real-life problem, particularly when working out all the math and statistics.
With all this, I want to make it clear that there might be other ways to do all this and that my code can be improved. If you work with Python and find improvements to it, please let me know in the comments! I’m more than happy to read them. :)
The code in Python
You will need data from Google Search Console, you can use my tool to download up to 50.000 keywords, as many times as you want for free!
- Export from Punk Export all the Google Search Console data. Use the “CSV” button to export 50.000 rows.
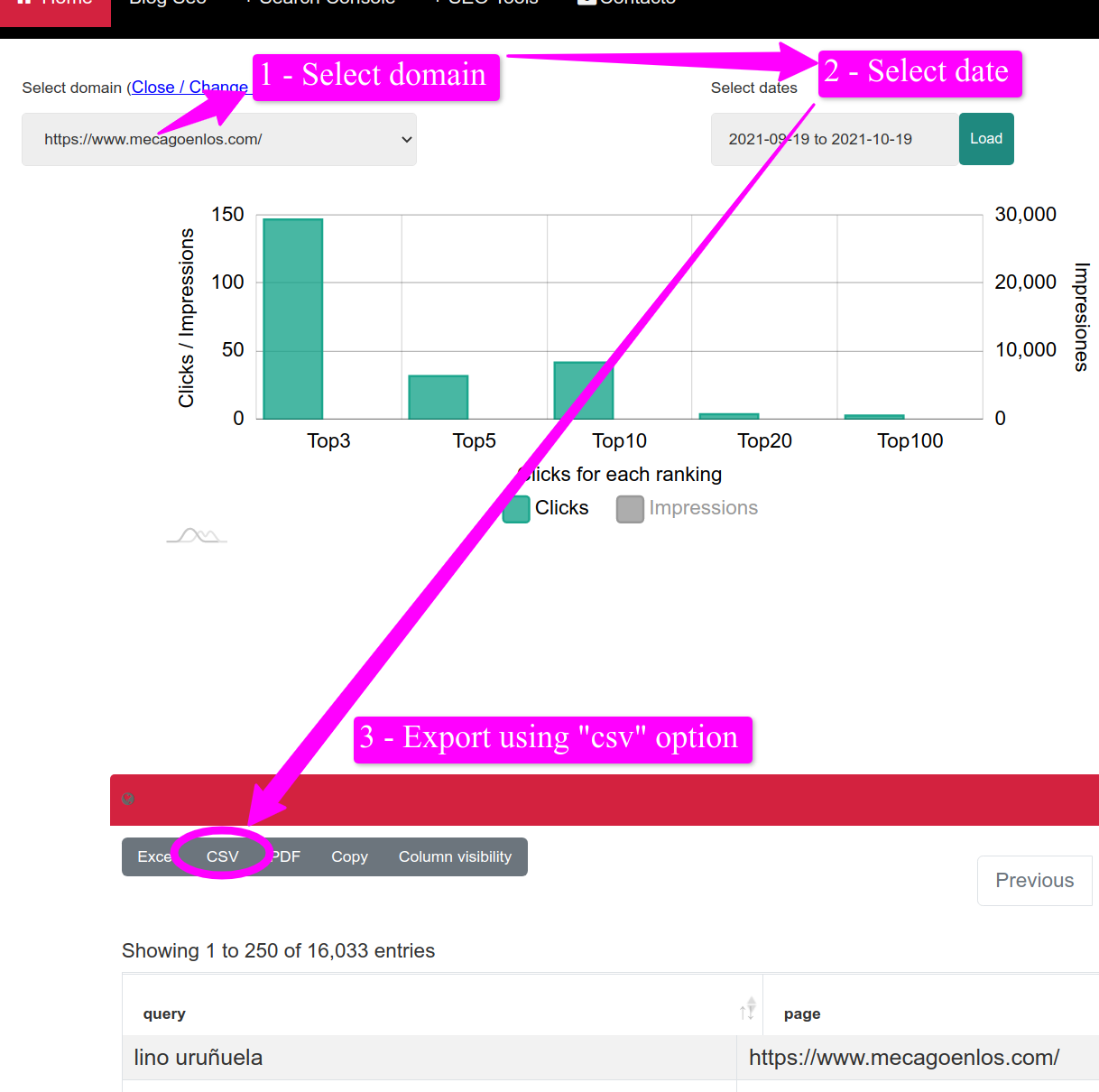
Once you have exported it, go to the python code and replace the CSV file name with the one you have in your files. The line you have to update looks like this one: "df = pd.read_csv(‘Google-Search-Console-data.csv')". Just replace ‘Google-Search-Console-data.csv' with the name of your file.
!python -m spacy download en_core_web_sm
!pip install Unidecode
!pip install "dask[dataframe]"
#@title
import argparse
import sys
import pandas as pd
from dask import dataframe as dd
from dask.diagnostics import ProgressBar
from nltk import SnowballStemmer
import spacy
import en_core_web_sm
from tqdm import tqdm
from unidecode import unidecode
import glob
import re
import requests
import json
from google.colab import files
"""After running the following core, we will be asked to slect the file we exported from [PunkExport](https://www.mecagoenlos.com/tools/en/)."""
uploaded = files.upload()
for fn in uploaded.keys():
print('User uploaded file "{name}" with length {length} bytes'.format(
name=fn, length=len(uploaded[fn])))
df = pd.read_csv(fn)
#mostramos 10 límeas para asegurarnos de que se ha subid correctamente
df.head(10)
"""We need to select the file with the Search Console data. In order to get as much data as possible you can use the tool I developed that will allow you to [download up to 50.000 rows of Search Console data](https://www.mecagoenlos.com/tools/es/), for free ;)
Depending on the project, you should delete some stopwords as explained in the last article. In one of my projects, I delete the following words from the stopwords list
"""
from spacy.lang.en.stop_words import STOP_WORDS
nlp = en_core_web_sm.load()
englishstemmer=SnowballStemmer('english')
#add kws to be ignored
nlp.Defaults.stop_words -= {"one","two","with"}
#kws ignored
print(STOP_WORDS)
"""The following code **can take up to 20 minutes to finish**, you just need to be patient :)"""
def normalize(text):
text = unidecode(str(text))
doc = nlp(text)
words = [t.orth_ for t in doc if not t.is_punct | t.is_stop]
lexical_tokens = [t.lower() for t in words if len(t) > 2 and t.isalpha() or re.findall("\d+", t)]
return ' '.join(lexical_tokens)
def lematizar(text):
lemma_text = unidecode(str(text))
doc = nlp(lemma_text)
lemma_words = [token.lemma_ for token in doc if not token.is_punct | token.is_stop]
lemma_tokens = [t.lower() for t in lemma_words if len(t) > 2 and t.isalpha() or re.findall("\d+", t)]
return ' '.join(sorted(lemma_tokens))
def stem_sentences(sentence):
tokens = sentence.split()
stemmed_tokens = [englishstemmer.stem(token) for token in tokens]
return ' '.join(sorted(stemmed_tokens))
#Exmpple using :'xiaomi mi' to 'xiaomimi and 'no index' to 'noindex'
replace_dict = {re.compile(r'^xiaomi mi (.*)'): r'xiaomimi \1',
re.compile(r'(.*) xiaomi mi (.*)'): r'\1 xiaomimi \2',
re.compile(r'(.*) xiaomi mi$'): r'\1 xiaomimi',
re.compile(r'^no index (.*)'): r'noindex \1',
re.compile(r'(.*) no index (.*)'): r'\1 noindex \2',
re.compile(r'(.*) no index$'): r'\1 noindex'}
def normalize(text):
text = unidecode(str(text))
doc = nlp(text)
words = [t.orth_ for t in doc if not t.is_punct | t.is_stop]
lexical_tokens = [t.lower() for t in words if len(t) > 2 and t.isalpha() or re.findall("\d+", t)]
return ' '.join(lexical_tokens)
def lematizar(text):
lemma_text = unidecode(str(text))
doc = nlp(lemma_text)
lemma_words = [token.lemma_ for token in doc if not token.is_punct | token.is_stop]
lemma_tokens = [t.lower() for t in lemma_words if len(t) > 2 and t.isalpha() or re.findall("\d+", t)]
return ' '.join(sorted(lemma_tokens))
def stem_sentences(sentence):
tokens = sentence.split()
stemmed_tokens = [englishstemmer.stem(token) for token in tokens]
return ' '.join(sorted(stemmed_tokens))
df_parallel=dd.from_pandas(df,npartitions=10)
df_parallel['kw_sustituida']=df_parallel['query'].replace(replace_dict, regex=True)
df_parallel['kw_nomrmalizada'] = df_parallel['kw_sustituida'].apply(normalize,meta=('kw_sustituida', 'object'))
df_parallel['kw_lematizar'] = df_parallel['kw_nomrmalizada'].apply(lematizar,meta=('kw_nomrmalizada', 'object'))
df_parallel['raiz'] = df_parallel['kw_nomrmalizada'].apply(stem_sentences,meta=('kw_nomrmalizada', 'object'))
#Ahora unirá los datos de los diferentes procesos en paralelo que ha creado Dask, esto es lo que más tardará, paciencia :)
with ProgressBar():
out = df_parallel.compute()
"""We download the results file, we can also save it in Colab"""
out.to_csv('export-colab-nombre_en_colab.csv', header=None, encoding='utf-8-sig', sep='\t', index=False)
out.to_csv('resultado-'+fn, header=None, encoding='utf-8-sig', index=False,sep='\t')
files.download('resultado-'+fn)
"""Now import data,
1. Open the "datos-exportados-PunkExport" sheet of [the template's copy](https://docs.google.com/spreadsheets/d/1kVFdBOdcHCaX1m38Vg-wQoJx2EBbvLGTk73CgytsGLU/edit#gid=1854650416) you did before.
2. Menu --> "File" -> "Import":
3. Select "Upload" -> select and upload csv exported from colab
4. "Import location" option -> "Replace data at selected cell"
# Go to "Result KWs" sheet and Ready!
"""
When the code finishes you will have a file with the output data.
The next step will be to create a dynamic table, for that follow these steps
-
- Open and create a copy of THIS TEMPLATE.
- Open the generated output file
- Copy all rows into the “data-exported-PunkExport” sheet.
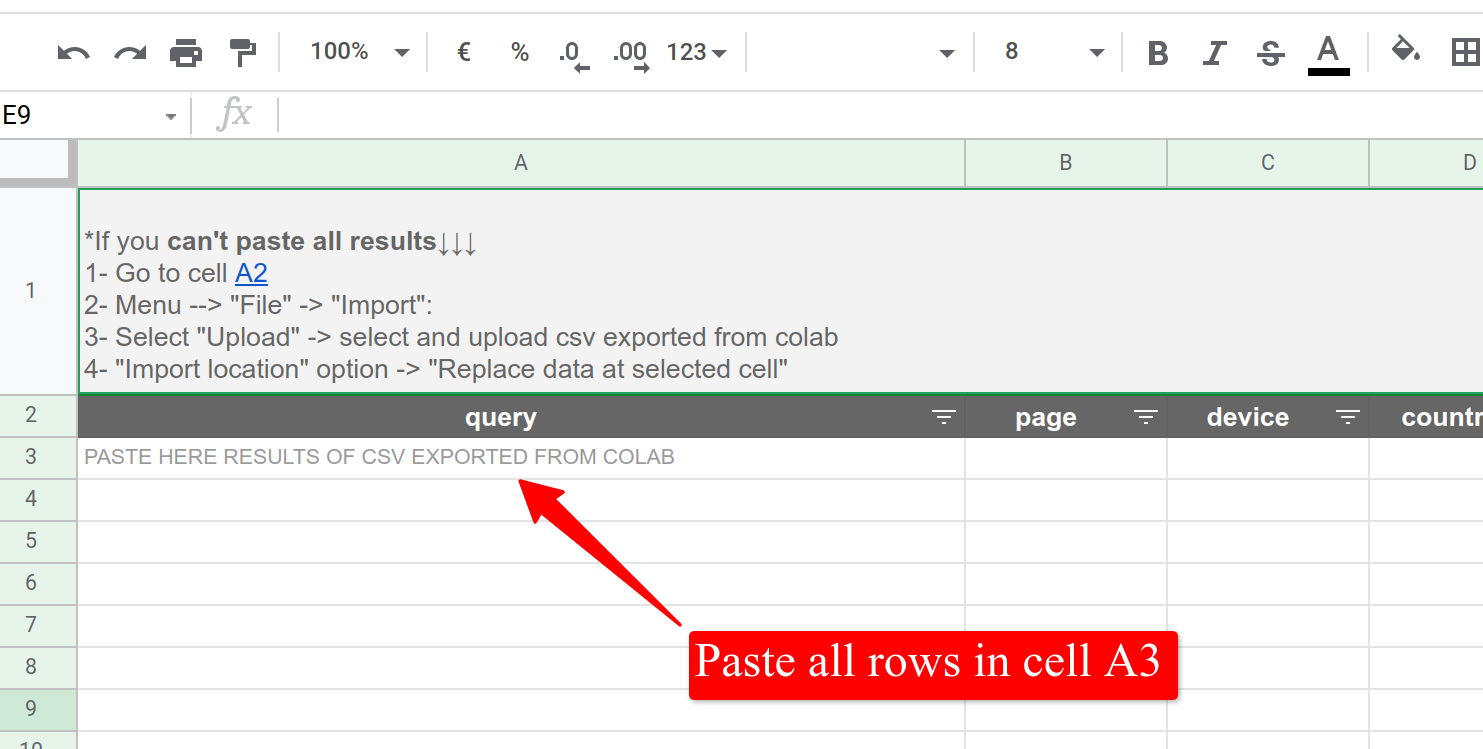
If you can't paste all rows in spreadsheet of Google, you can try this:
- Open the "datos-exportados-PunkExport" sheet of the template's copy you did before.
- Menu --> "File" -> "Import"
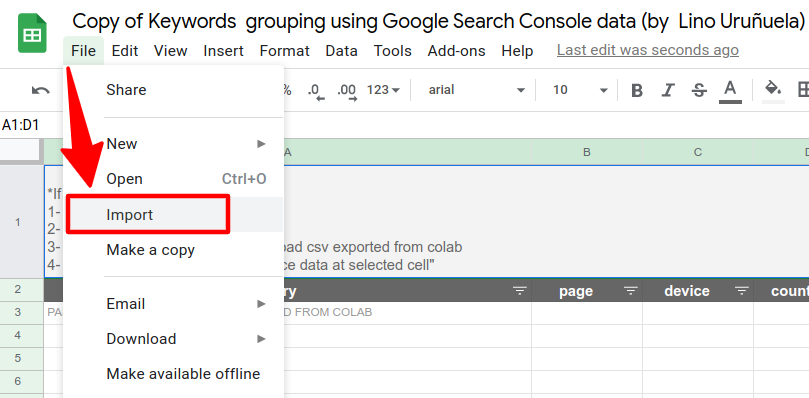
- Select "Upload" -> select and upload csv exported from colab
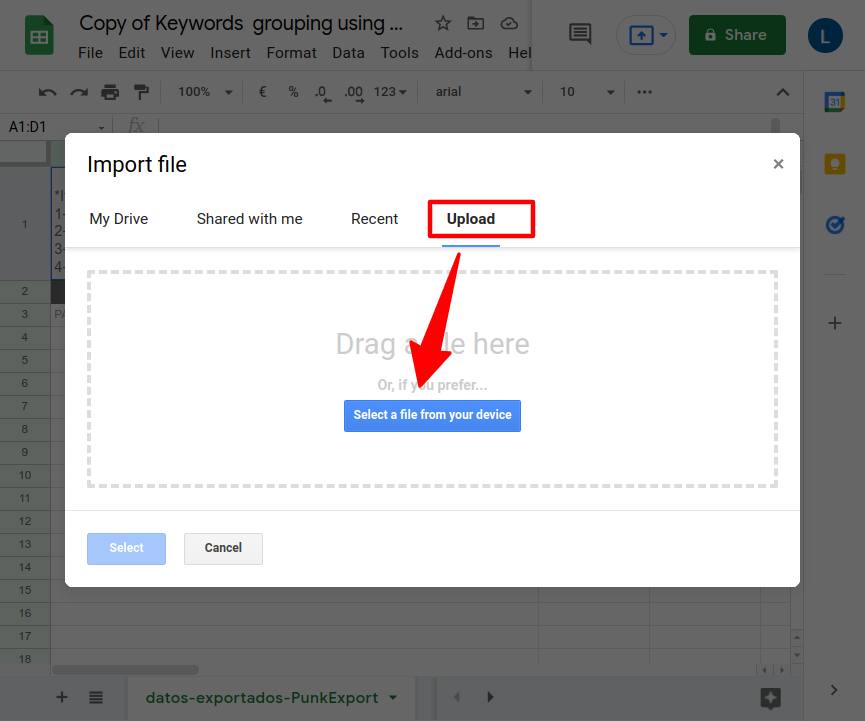
- "Import location" option -> "Replace data at selected cell"
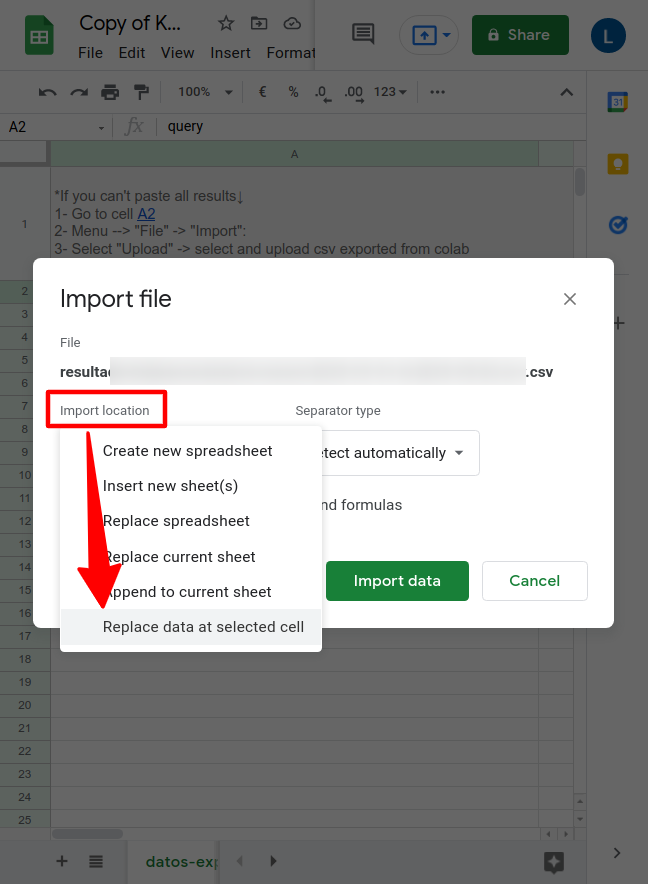
- Go to "Result KWs" sheet and Ready!
Code in Colab
You can run the code from this Google Colab notebook. This way, you won't need to install anything on your computer to run it, with all the steps to create the dynamic table.

Lee otros artículos
Diferencia de datos en Search Console para webs pequeñas dependiendo del método que usemos
Comparativa de los datos en la nueva exportación que Search Console a través de Big Query en sites PEQUEñOS
Diferencias entre la exportación de datos de Search Console usando BigQuery o usando la API
Características de la exportación de Search Console a BigQuery
Agrupación - Clustering de keywords SEO en Google Search Console
Publicado el día 30 de agosto del 2021 por Lino Uruñuela índice de contenido Agrupación de Keyword SEO Objetivos Tokenización Normalización Lematizació Vs Stemming Código Machine Learning para SEO Quiero dejar algo claro, no soy experto en Machine Learning, pero sí de sus tecnologías o hacia dónde va la cosa, que es m…
Expresiones regulares para SEO (Google Search Console)
Publicado el 8 de julio del 2021 por Lino Uruñuela Hace poco Google Search Console a nunciaba una de sus opciones más deseadas, poder filtrar usando expresiones regulares. No voy a ponerme a explicar qué son las expresiones regulares y para qué se pueden usar, ya hay información muchísimo mejor que la que yo pueda ofr…
Informe de experiencia en la página - Google Search Console
Por Lino Uruñuela Desde hace tiempo Google avisa e informa de determinados cambios en cómo trata, evalúa o muestra determinados resultados. En mi opinión, cuando Google avisa de algo con cierto margen de tiempo para que nos vayamos preparando es que no tendrá apenas repercusión, por ejemplo, tal y como ha hecho anteri…
Comprender los datos Google Search Console
Publicado el 14 de enero del 2021 Índice de contenido Límite de filas usando la API de Google Search Console Consultas por Propiedad o por Página Cuantas más dimensione, menos URLs únicas Algo que normalmente la gente que no se ha pegado mucho con los datos de Google Search Console no conoce es cómo funciona el l ímit…
Informes y gráficas usando la API de Google Search Console
Mediante la API de Google Search Console creamos informes que no podrás obtener mediante el interface web
Datos incoherentes y cálculo de la posición media en Search Console
Publicado el lunes 29 de julio del 2019 por Lino Uruñuela Métricas Posición Cálculo de la posición media Impresiones Clicks Dimensiones Informe de Rendimiento vía Web Limitaciones del interface web Consolidación de datos Hace muchos años que Google lanzó Search Console , aunque su nombre inicialmente fue Google Sitema…
Consolidación de urls canónicas en Google Search Console
Publicado el 27 de febrero del 2019 por Lino Uruñuela En el año 2018 Google parece haber apretado el acelerador en el desarrollo y mejora de Google Search Console con nuevos diseños y nuevas funcionalidades, pero también desaparecen, al menos de momento, otras funcionalidades. No voy a entrar en cada novedad o cada fu…

Nuevo Google Search Console ¿qué información nos ofrecerá?
Publicado por Lino Uruñuela el 11 de enero del 2018 índice de contenido Novedades en el nuevo Google Search Console Cobertura del índice URLs con Errores URLs con Incidencias URLs Válidas URLs Excluidas Filtro desplegable de descubrimiento de URL El otro día Google anunció que en breve pondrá a disposición de todos lo…
Comentarios
Todavía no hay comentarios publicados.