Seo y logs (primera parte): Monitorización de Googlebot mediante logs
Esta información nos es útil para poder ver rápidamente si está ocurriendo algo fuera de lo normal en tu site, o si por el contrario todo va según lo previsto. Muchas veces los SEOs definimos que urls deben dar un estado 200, o cuando deben hacer un tipo de redirecciones o si deben responder un código de error u otro.
Hay ocasiones en el que al hacer la implementación técnica se comete algún error de programación o un error en la definición que les pasamos, y que como consecuencia estemos dando algo erróneo a Google sin darnos cuenta,.
Hoy vamos a ver unos ejemplos de cómo con los logs obtendremos información útil sobre que está haciendo Google en tu site, de lo fácil que es darse cuenta de que algo ha ocurrido y de identificar dónde está ocurriendo.
Estos ejemplos son sacados de una tool propia que usamos en FunnelPunk con nuestros clientes, así cada día podemos comprobar de un vistazo si todo va bien.
En este ejemplo vamos a filtrar los logs de la siguiente manera
- Fecha: Desde comienzo de año
- User Agent: que contiene "Googlebot"
- Código de estado: = 200
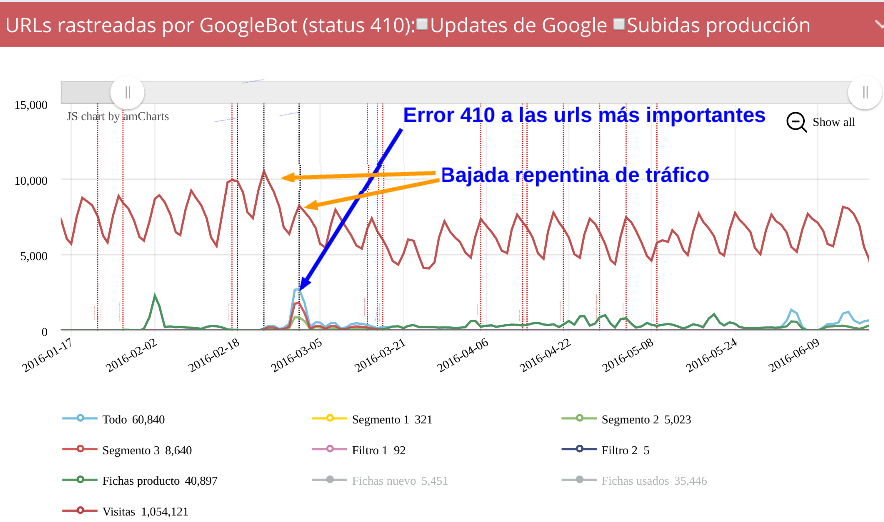
Y mostramos una gráfica como esta, la cual nos dice cuántas urls con estado 200 rastrea Google en nuestro site cada día
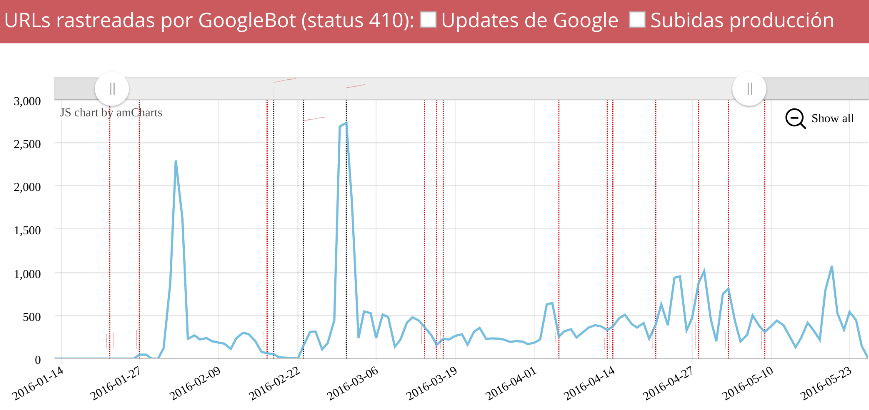
*Las líeneas verticales son guías que indican una implementación en el site para poder relacionar los cambios en el site con el comportamiento de Google.
Vemos como de repente en un día Google se puso a rastrear más de 100.000 urls mientras que anteriormente su frecuencia no era tan alta, algo había pasado. Y es que se cometió un error de programación que nos duplicó todo el site unas cuantas veces y creó miles de enlaces a páginas tanto correctas como inexistentes.
Filtrando
igual que antes pero en vez de código de estado = 200 lo hacemos por
los 410, vemos los distintos incrementos en este tipo de errores..
- Fecha: Desde comienzo del año
- User Agent: que contiene "Googlebot"
- Código de estado: = 410
No solo se crearon miles de urls correctas, también muchas dieron 410, pero ¿que fue lo que las causó? Para ello debemos segmentar el site por secciones, para saber en que secciones ocurrió y si fueron urls que antes daban 200 o han sido nuevas.
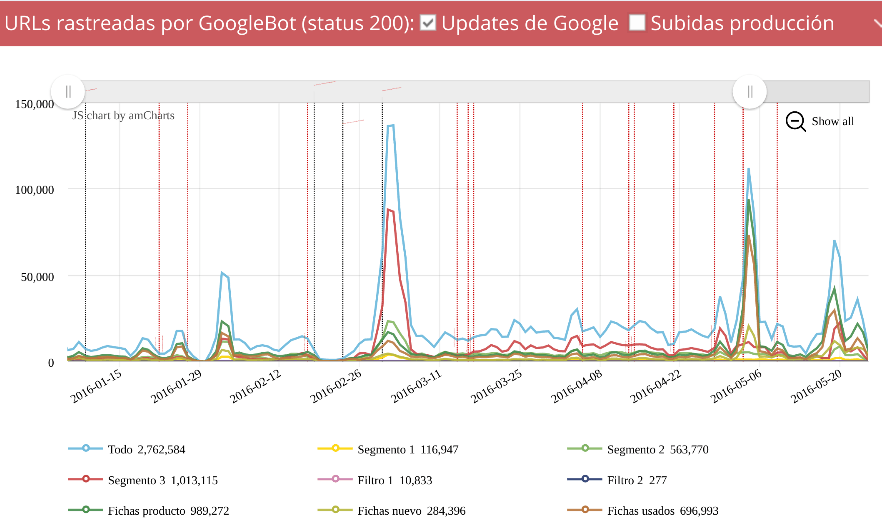
Podemos ver rápidamente como las fichas crearon el primer pico de 410, algo que era correcto ya que eran fichas caducadas que no daban tráfico y queríamos eliminar, pero vemos que el segundo pico se genera en los segmentos 3 y 2, las dos secciones que más tráfico orgánico aportaban al site.
Para facilitarnos la investigación podemos supoponer las visitas, obtenidas desde la API, esto nos dará una información vital para entender cómo afecto al site aquel error cometido.
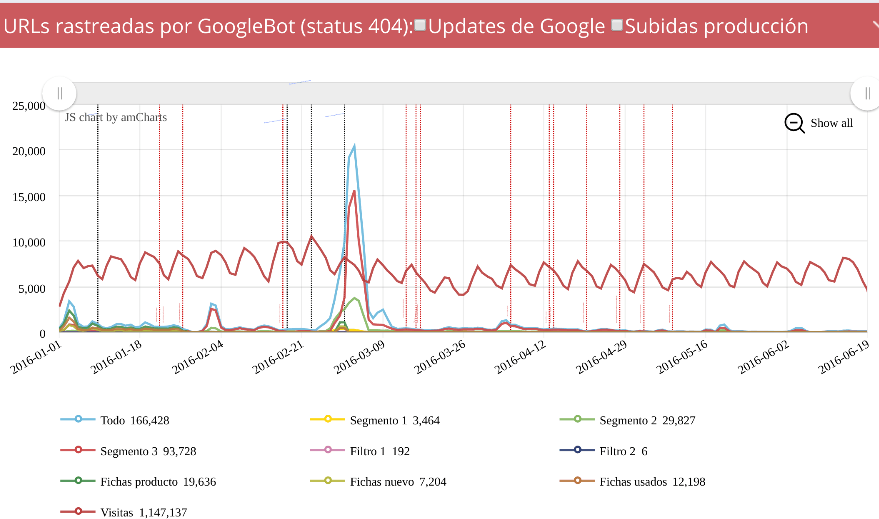
Como se ve, poco a poco se va recuperando el tráfico una vez resuelto los errores, pero claro, después de marear a Google con esos errores en miles y miles de urls, está siendo costoso, pero poco a poco parece que recupera :)
En el siguiente post veremos información igual o más útil que esta pero que no se puede representar en gráficos ;)
Comentarios
2Lee otros artículos
¿Se está impidiendo a los bots de Inteligencia Artificial acceder al contenido?
¿Cómo ha ido incrementando el número de robots.txt en los que aparecen rastreadores asociados a la Inteligencia Artificial?
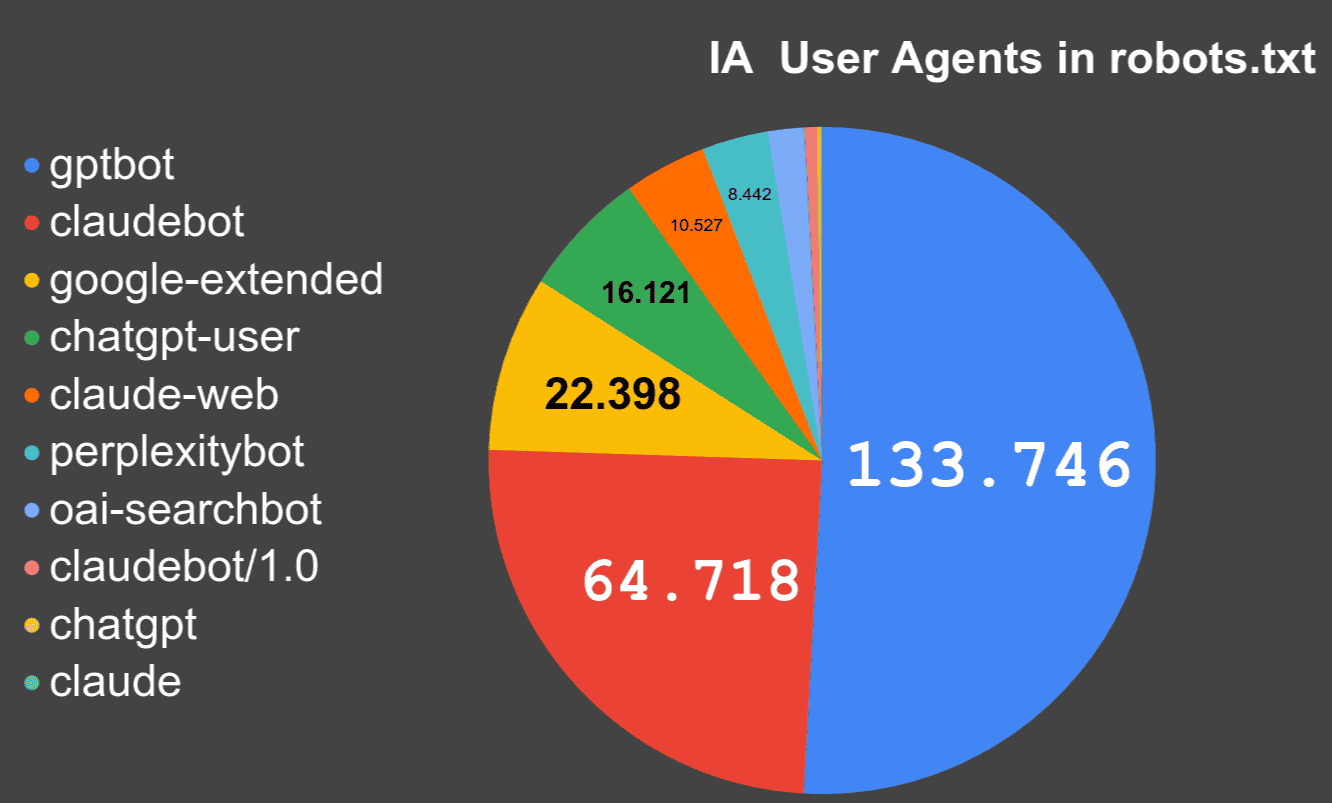
Analizando más de 72 millones de robots.txt
¿Cuántos dominios, subdominios y robots.txt estén bloqueando a los crawlers de Inteligencia Artificial?
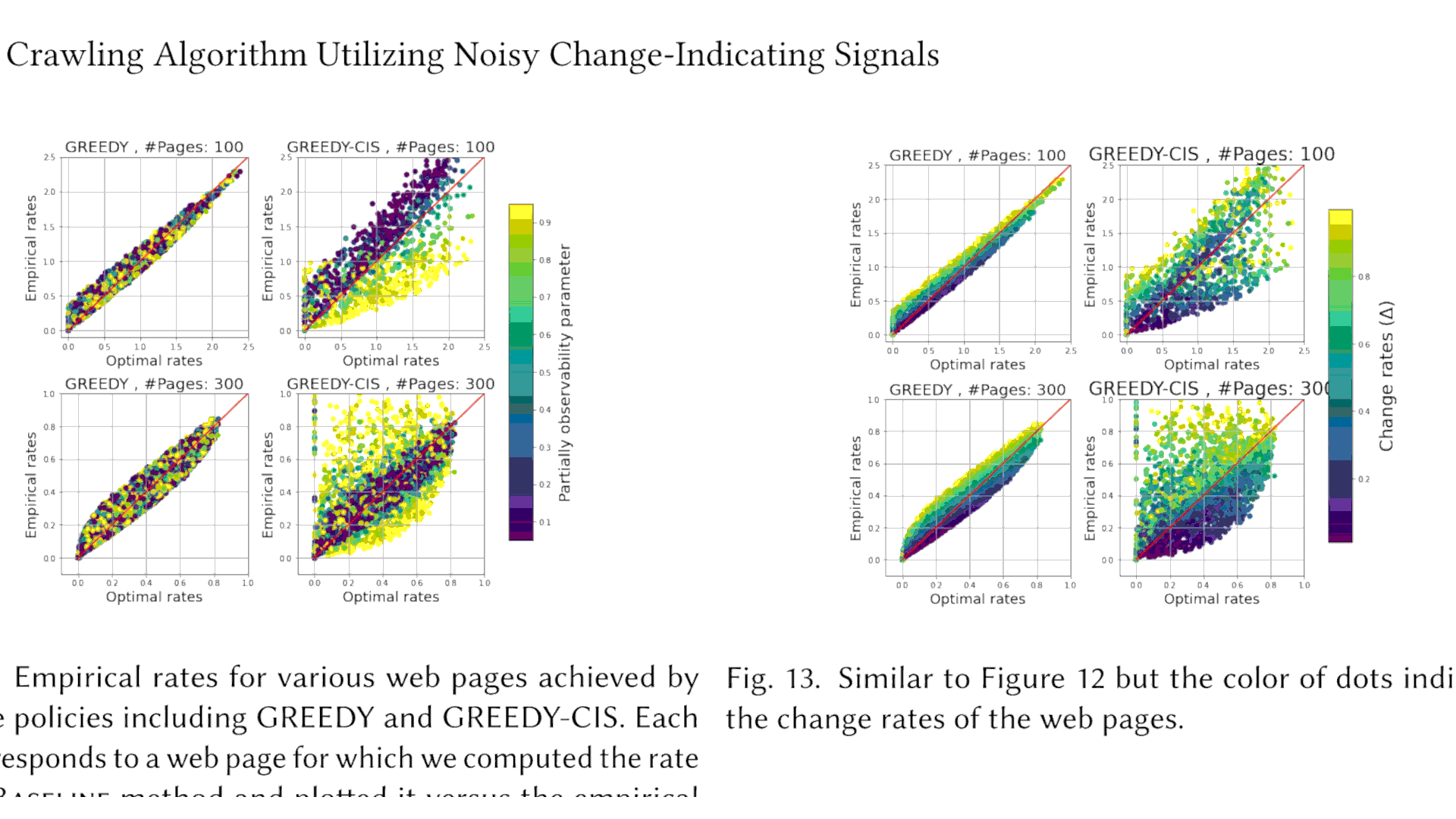
¿Cómo decide Google que URL debe rastrear?
Hoy he descubierto este paper de Google (A Scalable Crawling Algorithm Utilizing Noisy Change-Indicating Signals) dónde describe una mejora del método descrito en el artículo inicial
Búsqueda semántica de contenidos en los vídeos de Youtube
n la segunda parte mostré un caso de uso un poco más complejo para crear un buscador de contenidos dentro de los vídeos de Youtube. En este post voy a detallar la segunda parte, cómo podemos utilizar la línea de comandos + Bert + SQL para crear un buscador de contenidos dentro de los vídeos.
Google podria no querer el HTML de una URL
Publicado por Lino Uruñuela el 10 de diciembre del 2019 Llevaba tiempo preparando un post, pero me cuesta, porque quiero redactarlo bien, explicadito y al final o no lo comienzo por la pereza que me da eso de currármelo en vez de soltarlo así según viene, o directamente no lo termino jamás.... Pero hoy vuelvo a mis or…
Intentando comprender Googlebot y los 301
Publicado por Lino Uruñuela el 22 de marzo del 2017 El otro día hubo un debate sobre qué método usará Google a la hora de interpretar, seguir y valorar las redirecciones 301. Las dudas que me surgieron fueron ¿Cómo se comportan los crawlers? Normalmente cuando lanzamos un crawler como Secreaming Frog lo que hace es Ac…
Crawl Budget, qué es y cómo afecta a tu site según Google
Publicado por Lino Uruñuela el 16 de enero del 2017 en Donostia Desde hace ya mucho tiempo llevo analizando, probando y optimizando el Crawl Budget o Presupuesto de Rastreo. Ya en los primeros análisis vi que esto era algo relevante para el SEO, que si bien no afecta directamente a los rankings de una KW determinada,…
El valor de los logs para el SEO
Publicado el martes 6 de septiembre del 2016 por Lino Uruñuela Hace poco escribí el primero de una serie de post sobre el uso de Logs, Big Data y gráficas, en este caso continúo el análisis de la bajada que comenzamos a ver en Seo y logs (primera parte): Monitorización de Googlebot mediante logs , una caída importante…
Dime que logs tienes, y te dire si Googlebot te quiere
Publicado el 23 de junio del 2013 By Lino Uruñuela Algo muy común en el día a día de un SEO es mirar las distintas herramientas que Google nos proporciona dentro de WMT para saber el estado de nuestra web en cosas como la frecuencia de rastreo, el número de páginas indexadas, errores 404, errores 503, etc... No está m…
Comprobando comportamiento de Google con meta canonical
Publicado el 10 de abril del 2012, by Lino Uruñuela Hace tiempo hice unos tests para comprobar que Google interpretaba el meta canonical y cómo lo evaluaba. No recuerdo si publiqué el experimento, pero sí recuerdo que Google contaba los links que había hacia una URL que contenía el meta canonical y traspasaba el valor…
hola dar la gracias por el port bastante interesante. les tengo una preguanta cuando uno tiene un server dedicado como puedo adquirir los log
@henry si tu sistema es linux suelen estar en /var/log/apache/access.log