Diferencia de datos en Search Console para webs pequeñas dependiendo del método que usemos
Publicado el 9 de marzo del 2023 por Lino Uruñuela.
El otro día comenté la direncia que hay en la cantidad de datos obtenidos dependiendo del método que usemos para consultarlos, ya sea usando la propia web de Search Console, la API de Search Console o el nuevo método de exportación que acaba de implementar Search Console a través de Big Query.
Vimos una tabla dónde mostraba las diferencias que hay entre el nuevo método de exportación de datos de Search Console y el consultar los datos a través de la propia web de Search Console o de la API.
Hoy comparto esta misma tabla pero con datos de una web pequeña, con pequeña quiero decir que es una web con las siguientes características:
- Web con unos 3.000 ~ 4.000 usuarios diarios
- Web con menos de 1.000 URLs
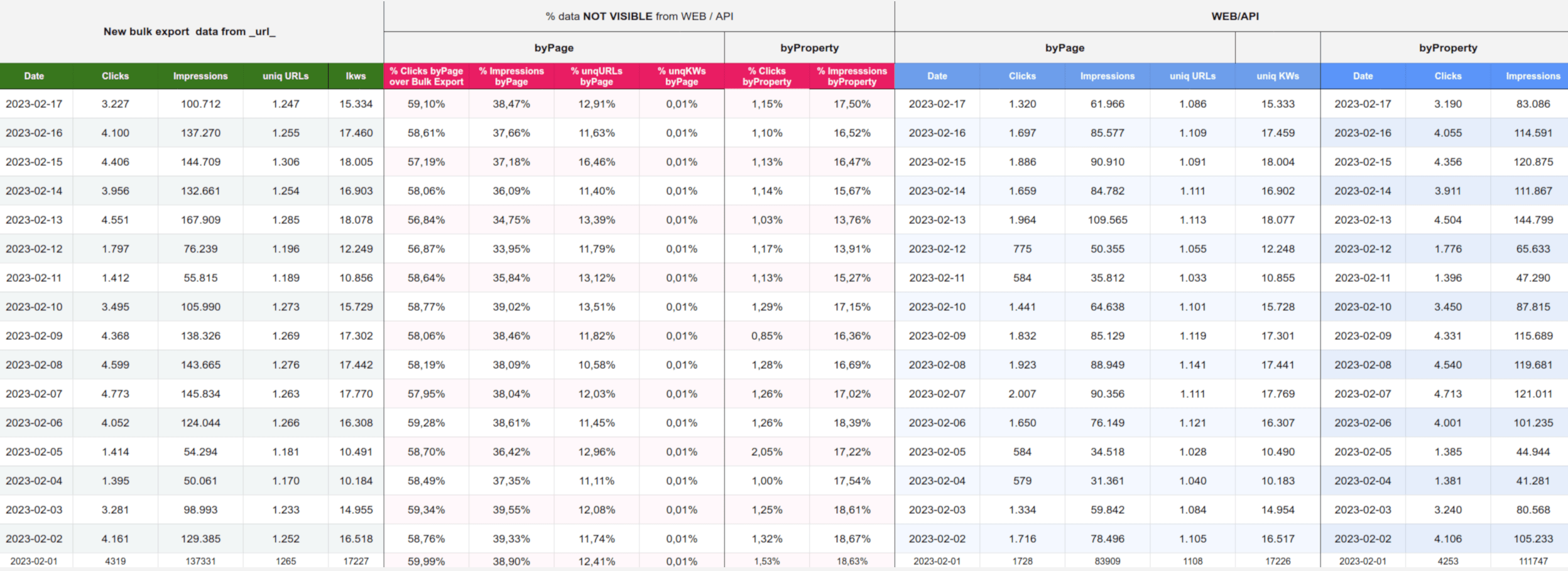
Tabla con los datos según el método de consultarlos
- New bulk export (datos filtrados por "search_type" = "WEB"): Son los datos extraídos mediante el nuevo método de exportación, por ejemplo, los clicks recibidos el día 17 de febrero sonn 3.227, y hay 100.712 impresiones, 1.247 URLs únicas y hay 15.324 keywords diferentes..
- DATOS VIA WEB por propiedadEstos datos son obtenidos mediante la api, sin solicitar ni filtrar por las dimensiones de "query" o "page", este es el número que vemos encima de las gráficas de Search Console cuándo vemos los clicks o impresiones sin filtrar. Es el valor máximo de clicks que se pueden obtener tanto mediante la API como del interface WEB
- % de datos que no veíamos usando la API y/o WEB:muestra qué porcentaje de clicks y de impresiones representan los datos que antes no podíamos ver a través de la WEB o usando AP cuando lo comparamos con el nuevo método de exportación.
Por ejemplo para el día 17 de febrero, sin filtrar ninguna URL, cuando utilizamos el nuevo método obtenemos 3.227 clicks, mientras que para el mismo día si consultaos el dato de clicks mediate la web de Search Console o usando la AP es de 3.190 clicks. Por lo tanto la diferencia es de 3.227 - 3.190 = 37 clicks que representan al 1,15% del total de clicks, es decir, con el nuevo método para exportar datos de Search Console obtenemos un 1,15% más de clicks.
Mientras que si filtramos por URL o por keyword, o solicitamos la lista de URLs o de kws los datos son más altos, De los 3.227 clicks que obtenemos utilizando el nuevo método de exportación pasamos a solo 1.320 clicks, lo que supone una pérdida del 59% de los clicks, de las 100.712 impresiones utilzando el nuevo método pasamos a 61.966 lo que representa una pérdida del 38,47%
Me quedo bastante más tranquilo que cuándo realicé esta misma comparación con los datos de un site muy grande, unos 2 millones de usuarios diarios y con más de 100 millones de URLs dónde vimos que los datos "perdidos" si no utilizamos la exportación de Search Console a Big Query eran de más del 11% de clicks y más del 48% de las impresiones si no aplicábamos filtros, y si lo hacíamos la cifra se disparaba hasta un 78% de clicks y un 98% de las impresiones, 98% de las URLs diferentes y el 97% de las palabras clave.
Aun así, vemos que cuando aplicamos algún tipo de filtro de dimensión la brecha entre los datos según la fuente de dónde los obtengamos es más relevante, y cómo vimos en el anterior artículo es exageradamente grande cuando el site es también exagerada,ente grande!!
Lee otros artículos
Diferencias entre la exportación de datos de Search Console usando BigQuery o usando la API
Características de la exportación de Search Console a BigQuery
Keywords grouping using Google Search Console data
Publish at October, 25 of 2021 by Lino Uruñuela Table of Contents Classifying keywords vs. grouping search terms Classifying keywords based on a previously defined list Grouping search terms Usually, the simpler, the better it works. Looking at the code Create a dictionary for specific words Accept that there are thin…
Agrupación - Clustering de keywords SEO en Google Search Console
Publicado el día 30 de agosto del 2021 por Lino Uruñuela índice de contenido Agrupación de Keyword SEO Objetivos Tokenización Normalización Lematizació Vs Stemming Código Machine Learning para SEO Quiero dejar algo claro, no soy experto en Machine Learning, pero sí de sus tecnologías o hacia dónde va la cosa, que es m…
Expresiones regulares para SEO (Google Search Console)
Publicado el 8 de julio del 2021 por Lino Uruñuela Hace poco Google Search Console a nunciaba una de sus opciones más deseadas, poder filtrar usando expresiones regulares. No voy a ponerme a explicar qué son las expresiones regulares y para qué se pueden usar, ya hay información muchísimo mejor que la que yo pueda ofr…
Informe de experiencia en la página - Google Search Console
Por Lino Uruñuela Desde hace tiempo Google avisa e informa de determinados cambios en cómo trata, evalúa o muestra determinados resultados. En mi opinión, cuando Google avisa de algo con cierto margen de tiempo para que nos vayamos preparando es que no tendrá apenas repercusión, por ejemplo, tal y como ha hecho anteri…
Comprender los datos Google Search Console
Publicado el 14 de enero del 2021 Índice de contenido Límite de filas usando la API de Google Search Console Consultas por Propiedad o por Página Cuantas más dimensione, menos URLs únicas Algo que normalmente la gente que no se ha pegado mucho con los datos de Google Search Console no conoce es cómo funciona el l ímit…
Informes y gráficas usando la API de Google Search Console
Mediante la API de Google Search Console creamos informes que no podrás obtener mediante el interface web
Datos incoherentes y cálculo de la posición media en Search Console
Publicado el lunes 29 de julio del 2019 por Lino Uruñuela Métricas Posición Cálculo de la posición media Impresiones Clicks Dimensiones Informe de Rendimiento vía Web Limitaciones del interface web Consolidación de datos Hace muchos años que Google lanzó Search Console , aunque su nombre inicialmente fue Google Sitema…
Consolidación de urls canónicas en Google Search Console
Publicado el 27 de febrero del 2019 por Lino Uruñuela En el año 2018 Google parece haber apretado el acelerador en el desarrollo y mejora de Google Search Console con nuevos diseños y nuevas funcionalidades, pero también desaparecen, al menos de momento, otras funcionalidades. No voy a entrar en cada novedad o cada fu…

Nuevo Google Search Console ¿qué información nos ofrecerá?
Publicado por Lino Uruñuela el 11 de enero del 2018 índice de contenido Novedades en el nuevo Google Search Console Cobertura del índice URLs con Errores URLs con Incidencias URLs Válidas URLs Excluidas Filtro desplegable de descubrimiento de URL El otro día Google anunció que en breve pondrá a disposición de todos lo…
Comentarios
Todavía no hay comentarios publicados.