¿Repartiendo el long tail?
Desde ayer se están viendo un número muy elevado en el número de resultados de páginas indexadas de muchos dominios cuando haces la búsqueda site:dominio.com . Creo que todo apunta a que tiene que ver con Google caffeine.
Decía que estaba actualizando la estructura de sus índices, para que estos fuesen mucho mayores y más rápidos.
Creo además que con este cambio veremos un gran cambio en el algoritmo que clasifica el orden de los resultados, como puede ser links el que ignore algunos wide-links (links en todas las URLs de un dominio), resultados más geolocalizados para determinadas temáticas y cosas como estas para intentar hacer menos manipulables sus resultados.
Yo creo que el cambio de algoritmo que llevará a cabo Google se irá viendo poco a poco, lo primero que ha hecho ha sido modificar su infraestructura para poder acometer estas mejoras a la hora de mostrar resutados.
Antaño, si se me permite este expresión para hace menos de 2 años, existía lo que llamábamos índice suplementario. Era un índice en el que estaban las URLs que menos veces se mostraban como posibles resultados y que para que saliesen se tenía que haber hecho una búsqueda que no tuviera muchos resultados, por ejemplo con frases largas, o con algún truquito (poniendo por ejemplo site:mecagoenlos.com *** -patatinpatatan).
En su día nos dijeron que ese índice iba a actualizarse diariamente para luego decirnos que iba a desaparecer, y de repente dejaron de funcionar esos truquitos para ver si una URL estaba o no en el índice supementario, pero yo creo que en realidad nunca dejó de existir.
Ahora creo que el índice general será mucho más amplio, y además, tendrá capacidad para aplicar determinados filtros para evitar spam.
Creo que esto conllevará a que por los términos de long tail haya muchas más URLs que compitan, y no como antes, que había determinadas URLs que tenían ventaja sobre otras al estar en ese índice principal. Por eso, creo que páginas con gran tráfico por long tail pueden verse perjudicadas si esta actualización fuese como digo.
La verdad es que puedo estar muy confundido y no ser nada así, esto es como la teología, si Dios no nos dice nada, crearemos nuestras propias teorías para intentar explicar lo que vemos. Lo bueno es que podremos comprobarlo en un espacio de tiempo cercano... y sin tener que morirnos!
Comentarios
6Lee otros artículos
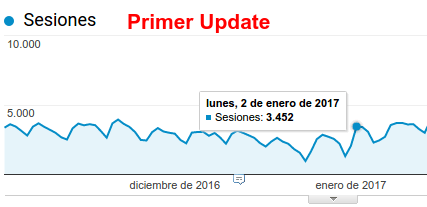
Google comienza el año con dos updates
Publicado por Lino Uruñuela el 23 de febrero del 2017 Este año 2017 ha empezado con movimientos comvulsivos en las gráficas de tráfico orgánico en muchas webs. Yo he notado varios updates de Google y con bastante impacto, vamos a resumirlos un poco. ¿Primer Update del año, 2 de enero? Comenzamos el día 2 de enero con…
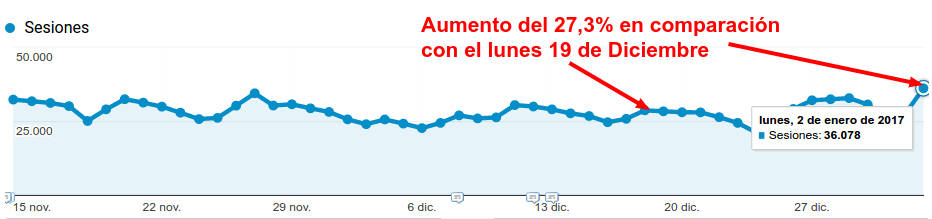
¿Christmas Update?
Publicado por Lino Uruñuela el 3 de enero del 2017, San Sebastián. Google no acostumbra a realizar cambios drásticos cuando llegan fechas críticas para los comercios, como por ejemplo en Navidad, donde se aumentan muchísimo las transacciones por causa de los regalos, y dónde un error podría hacerle perder mucho dinero…

¿Dosis de cafeína en Panda 4.0?
Publicado por Lino Uruñuela ( Errioxa ) el 27 de mayo del 2014 El otro día comentamos alguna cosa que percibimos con el último update de Google, Panda 4.0 , y decíamos que una de las cosas que más destacan es la reducción del número de resultados de un mismo dominio en la primera página de las serps. Ahora leo que Mat…
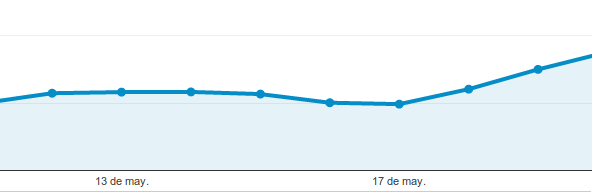
Nuevo Update de Panda, ¿qué ha cambiado?
Publicado por Lino Uruñuela ( Errioxa ) el 21 de mayo del 2014 Hoy nos hemos levantado con la confirmación por parte de Google de dos nuevas actualizaciones en su algoritmo, una Payday Loan Algorithm , que afecta búsquedas spam. Estas búsquedas suelen ser temas de porno de de "cómo ganar dinero" y cosas así y que no d…
El futuro es la búsqueda por voz
Publicado por Lino Uruñuela ( Errioxa ) el 29 de abril del 2014 Hoy he leído que Google Voice se va a extender a muchas más aplicacione de Google y no solo, como hasta ahora, a las búsquedas web (tanto en el móvil como en tablets, o el ordenador de sobremesa). En la cuestión de la búsqueda por voz, en vez de escribién…
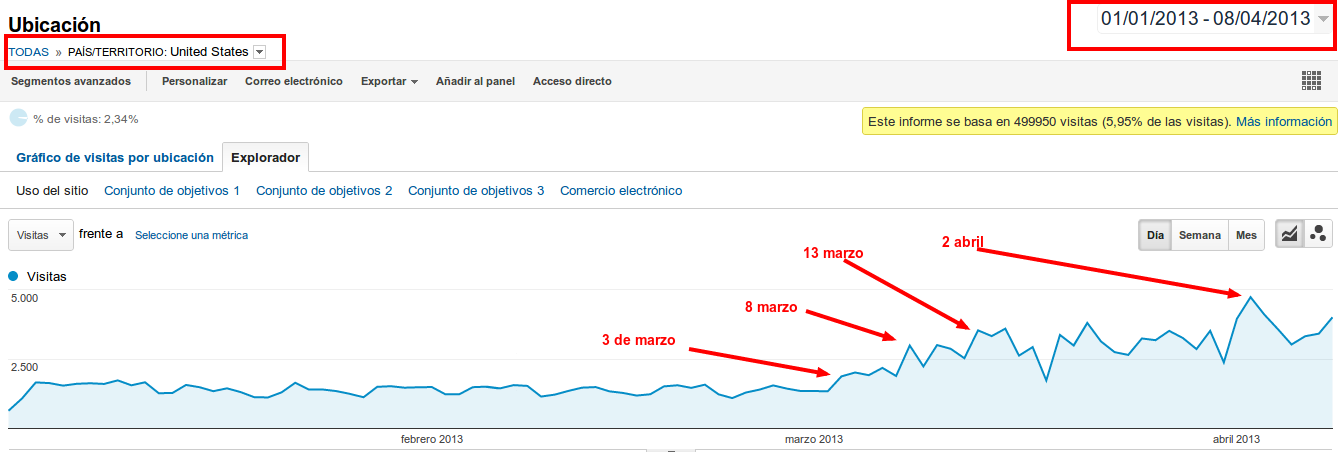
Aumento de visitas desde USA
Publicado el 10 de abril del 2013 by Lino Uruñuela Actualización: Sólo ocurre en el tráfico directo, en tráfico orgánico y tráfico de referencia no ocurre Desde comienzos de este mes de abril he notado algunos cambios en las visitas recibidas, al principio no sabía muy bien ya que coincidía con la Semana Santa y no es…
Atrapando al usuario en el nuevo Google Images
Publicado el 10 de febrero del 2013, by Lino Uruñuela ACTUALIZACIóN: El primer código del htaccess que puse al final del artículo tenía algún error. Estoy intentando hacer que funcione siempre, algo va mejorando. En estos momentos tengo así el htaccess, aunque parece que no llega a func ionar del todo . Con Firefox sí…
¿Cómo podría identificar Google las webs SEO?
Publicado el 20 de marzo del 2012 El otro día Matt Cutts comentó que en estas próximas semanas/meses habrá una actualización del algoritmo para identificar las páginas sobreoptimizadas en el aspecto SEO. Se ha comentado en varios sitios como WMT SER o SEL Los puntos que comenta la verdad que no son nada nuevo keyword…
Cómo saber si estás afectado por Google Panda
Publicado el 14 de agosto del 2011, by Lino Uruñuela, Como bien sabemos todos Google lanzó el viernes la nueva actualización Panda . En un primer momento ha habido una euforia general porque todos veíamos como nuestras visitas subían en comparación con días anteriores pero es que Google Analytics ha aprovechado para c…
¿Pre-panda, Google caffeine o un poquito d ambas?
Pulbicado el 19 de junio del 2011 Ya se están viendo cambios en las estadísticas de muchos sites , ¿será Panda 2.2? Y es que el otro día Matt Cuts comentó que la actualización a Panda 2.2 llegará en breve, la verdad es que dijo que no era cosa de semanas sino de meses. Y justo unas semanas después comienza a ocurri es…
Joder Lino la has clavao. Siguiendo tu lógica que tiene mucho sentido creo que pronto veremos algo gordo que esta pasando. Es cierto que el índice nunca ha dejado de existir, de hecho según recuerdo Google no comento que desapareciera físicamente sino que se dejaría de ver. Tiene mucha lógica porque esta indexando contenidos duplicados que antes entraban en el suplementario. Bueno en breve tendremos que ver las consecuencias de la cafeina, mas vale que yo deje el café hace años y tomo té, jajaja ;-) Saludos!
@Dani el té tiene teina! no sé que será peor jajaja.<br>Ya te digo que a saber que es lo que se cuece, esto podría ser una consecuencia de ello, pero eso... a saber!
Yo creo que con eso al menos el SEO se volvería más interesante que solo optimizar para aparecer en la cola larga, ya que entonces si se tendría lo que llamamos "Posicionamiento" XD Por cierto q para una web q tenia 2000 resultados en el indice ayer que ustedes comentaban esto, revise y ahora tiene 6000! Slds desde Guatemala!
Jajaja por eso pero a Google le gusta el café y no el té al menos por ahora. Has podido comprobar si indexa urls duplicadas o con variables largas o cosas raras que antes se comía el índice suplementario? Voy a mirarlo ;-) Por cierto como comenta @elqudsi en Google images también esta afectando y están de baile por la cafeína.
Hola Errioxa! Más que cuánto, la pregunta es qué está indexando Google. En función de qué sea lo que esté indexando, tendrá sentido tu afirmación de que va a afectar al longtail. Es decir, si todo ese contenido que se está indexando es duplicado ¿porqué debería afectar al longtail? En cambio, si el contenido indexado es gracias a que google puede navegar a través de js. y está accediendo a la web invisible, sí que es posible que afecte al longtail. Por cierto, a ver si me aceptas como follower tuyo en twitter (pserrano) ;)
Dani Pinillos: Y el té no lleva cafeína?