Agrupación - Clustering de keywords SEO en Google Search Console
Publicado el día 30 de agosto del 2021 por Lino Uruñuela
Machine Learning para SEO
Quiero dejar algo claro, no soy experto en Machine Learning, pero sí de sus tecnologías o hacia dónde va la cosa, que es muy diferente de ser un "Data Science", como he dicho siempre y volveré a repetir, para ser un Data Science necesitas 5 años de carrera de matemáticas y otros 4 de doctorado que te aportaráan conocimientos suficientes para abstraer matemáticamente un problema real, un ejemplo que nos resultará familiar es el cómo los ingenieros de Google idearon desde la idea matemática una solución óptima para calcular cuándo Google debe volver a rastrear una URL, o lo que es lo mismo, el Crawl Budget del que tanto hemos hablado., veréis que las matemáticas usadas no son las típicas que aprendimos en el instituto.
También me gustaría diferenciar lo que son problemas analticos, es decir de "echar cuentas" numéricas, ya sean estadísticas o probabilísticas, de los problemas con el manejo y procesado de texto.
¿Por qué lo diferencio?, porque cuándo se trata de problemas analíticos como la previsión de visitas futuras (forecasting), o el cálculo del CTR para una determinada consulta de búsqueda en una determinada posición o de ventas previstas en base a ambas cosas, CUIDADO, porque podemos estar usando fórmulas/modelos que no son idóneos dados los datos de los que disponemos.
Por ejemplo, si quieres usar una regresión lineal para calcular cómo se comporta una variable con respecto a otra, deberían cumplirse los siguientes 5 supuestos:
-
Linealidad: la relación entre las variables debe ser lineal, es decir en forma de "S" no vale.
-
Independencia: los errores en la medición de las variables deberían ser independientes entre sí.
-
Homocedasticidad: los errores deben tener una varianza más o menos constante.
-
Normalidad: las variables tienen una distribución normal, típica campana de Gaus como la siguiente.
[Ejemplo de gráfica con distribución normal]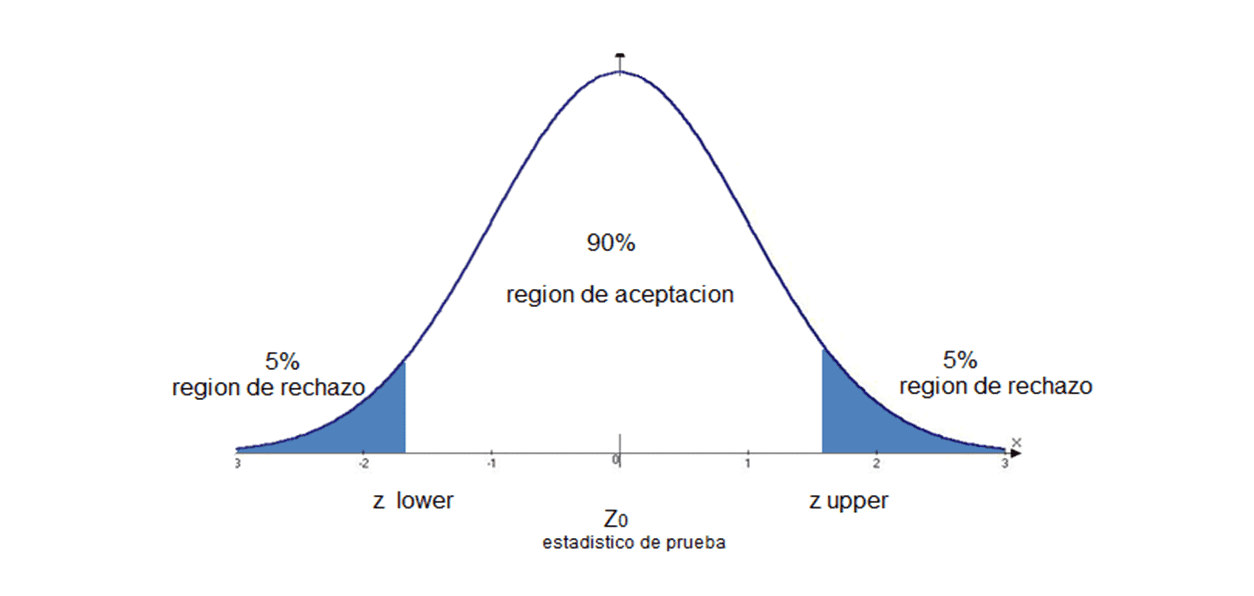
-
No colinealidad: las variables independientes no deben estar correlacionadas entre ellas.
Y estamos hablando de la función matemática relativamente más sencilla...
Por supuesto, lo anterior tiene sus grandes matices, pero es para hacernos una idea de que para aplicar según qué soluciones matemáticas debemos tener unos mínimos conocimientos que no se adquieren en cuatro cursos online... si usamos una regresión lineal para calcular el CTR dependiendo de su posición estaremos haciéndolo mal y los resultados no se ajustarán a la realidad ya que la distribución en este caso suele ser exponencial y no "normal".
[Ejemplo de gráfica exponencial]
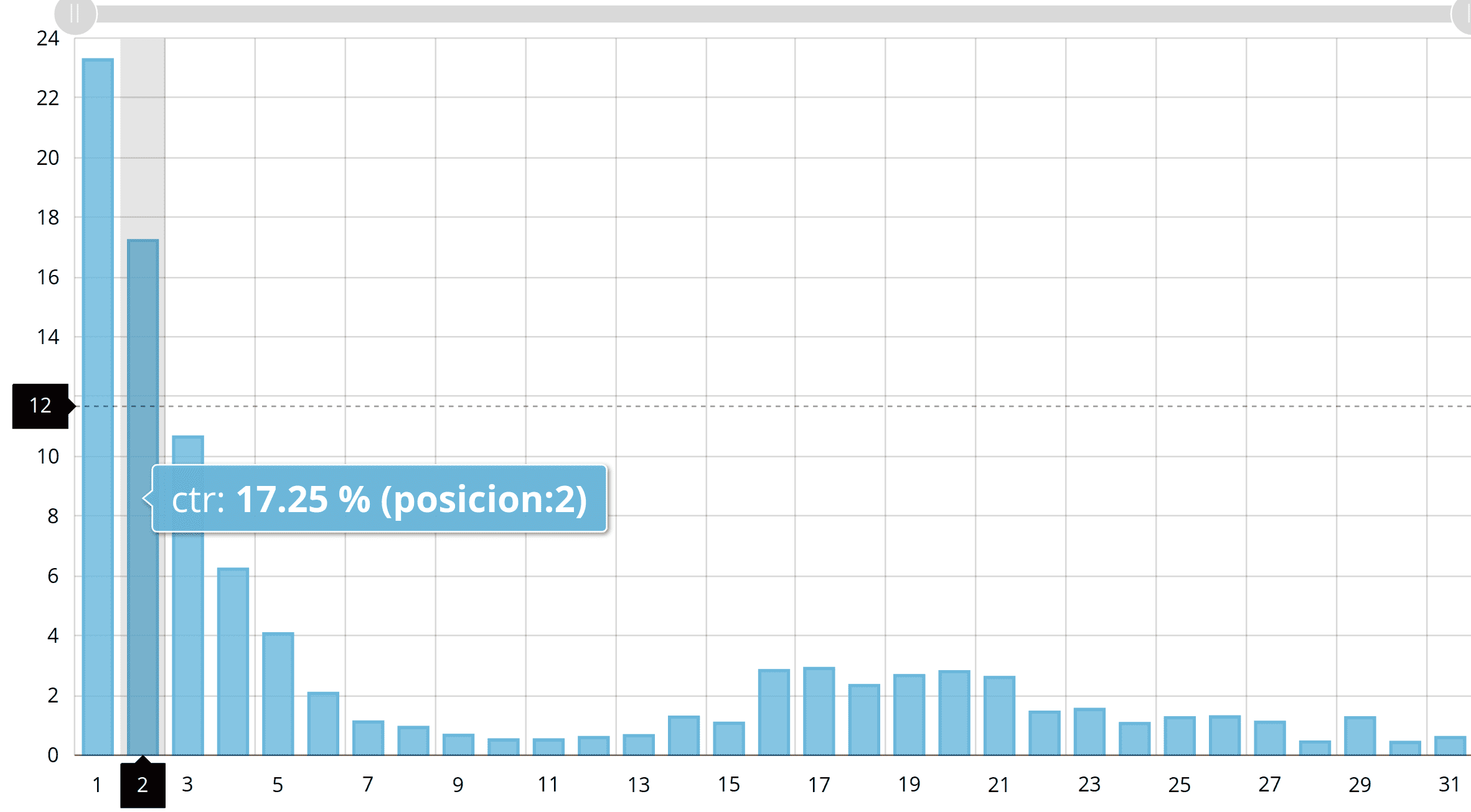
Dicho esto, lo cierto es que siempre podemos probar e intentar entender lo mejor posible cuándo usar cada cosa a la hora de realizar cálculos analíticicos.
A diferencia del estudio de datos analíticos hay otras ramas del Machine Learning dónde no nos es tan necesario conocimientos matemáticos tan profundos para poder saber si la solución planteada (o el código copiado de algún tutorial) funciona correctamente y si realmente está cumpliendo la función para la que la diseñamos, una de estas ramas del Machine Learning es el Procesamiento del Lenguaje Natural (PLN) o NPL en inglés, y que cada vez tiene más relevancia en SEO.
No es necesario saber estadística para comprender qué "Posicionamiento web", "posicionamiento web", "posicionamiento SEO", etc, son términos con el mismo significado, o saber que "Hola, vamos a seos queridos por todos" es una frase mal formada o muy extraña., eh ahí la diferencia con los análisis estadísticos.
No voy a enrollarme más por lo que pasaré a mostrar las herramientas que yo he usado para crear la Matriz de Keywords Agrupada.
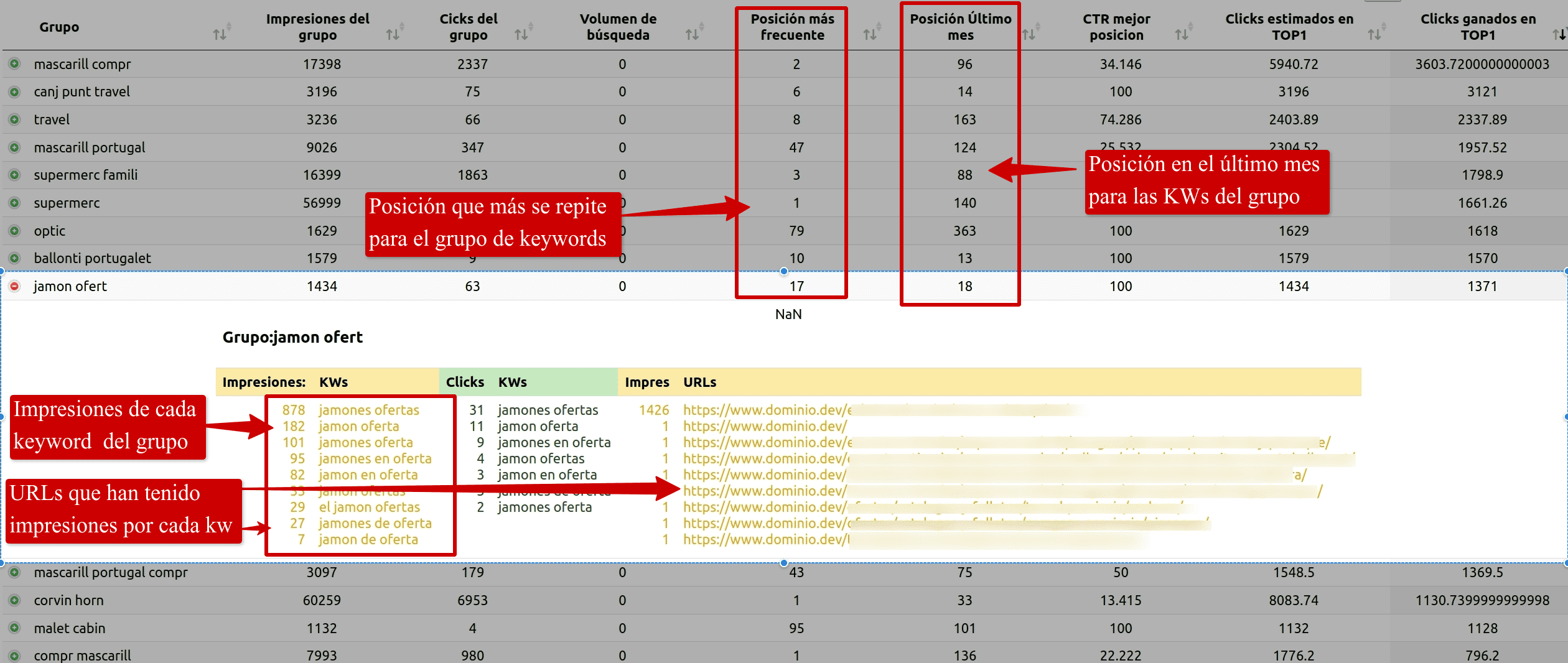
Aquí vemos una tabla dónde por cada fila tenemos un grupo de palabras clave que tienen la misma intención de búsqueda, en este caso "jamones en oferta", además por cada grupo de keywords tenemos datos de impresiones totales, clicks totales, posición media, posición más frecuente de esas KWs, la posición en el último mes, en otros posts profundizaremos en cómo calcularlas son morir en el intento.
Así obtendremos por cada cluster de keywords los datos desglosados!

Agrupación de Keyword SEO en una Matriz de Datos
En Funnel Punk llevamos tiempo trabajando las agrupaciones de datos, alguna como esta, basada en palabras clave, pero también lo usamos para otras muchas cosas, como localización de duplicados, análisis de títles, etc.. Podemos calcular el potencial de cada grupo para saber cuál es el que más beneficios nos aportará si lo mejoramos, algo muy útil cuando el proyecto dedica recursos significativos a la redacción y contenido, ya que podrá ver la evolución tanto en posiciones a lo largo del tiempo, como el resto de datos, todo sin abrumarles demasiado :)
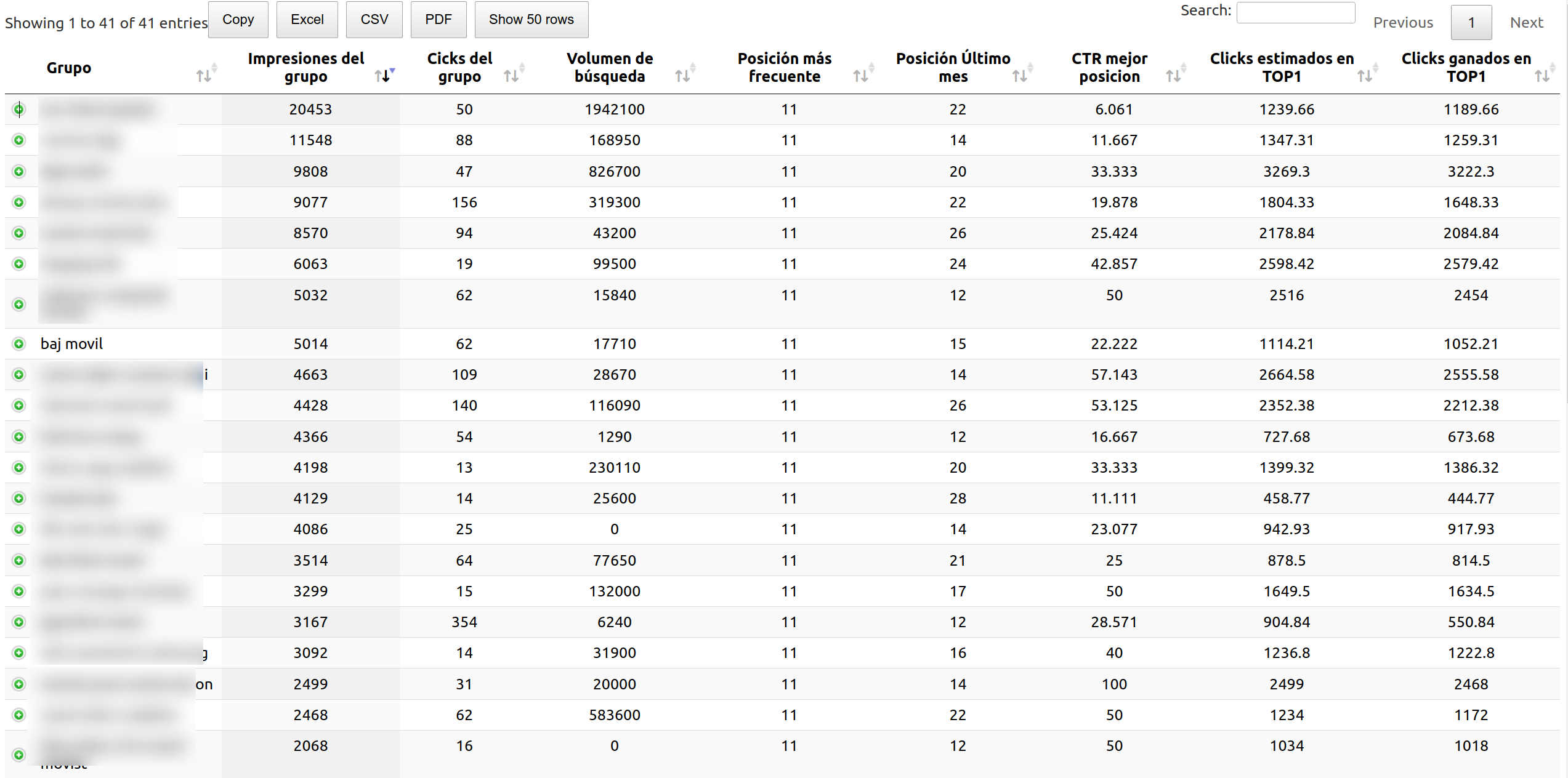
Aquí podemos ver cuando hacemos clicks en una fila, todas las KWs, y URLs para las que han tenido impresiones y clicks
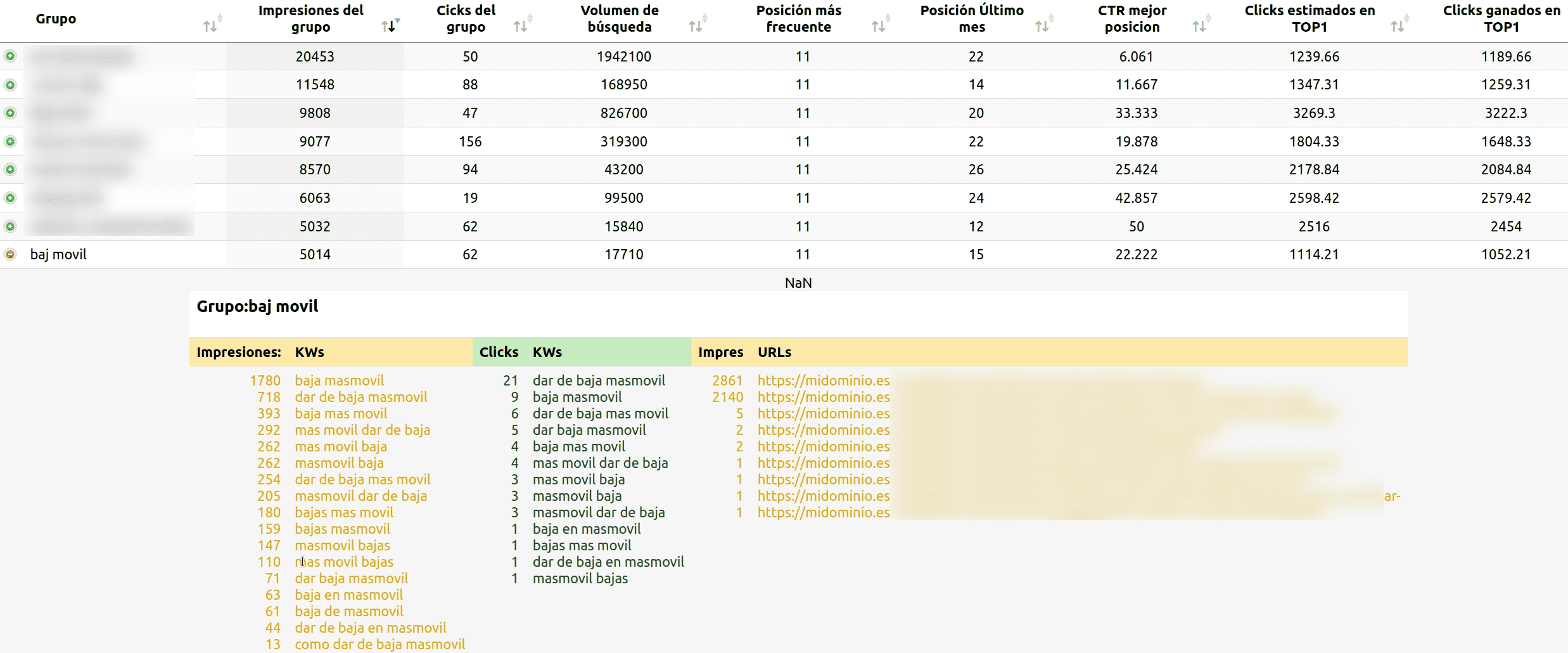
En los próximos artículos de esta "saga" veremos más a fondo esta tabla, hoy quiero explicar las diferentes maneras por las que he probado esta agrupación
Objetivo
Con este procesado de datos lo que queremos conseguir es unificar keywords que significan lo mismo pero que son diferentes entre sí, de esta manera facilitaremos la comprensión de cada grupo de consultas de una manera mucho más completa, ya que serán keywords cuasi sinónimas. Además, no queremos perder los datos de cada kw dentro de cada grupo, tanto de métricas como impresiones, clicks, ctr, etc de cada KW como para las URLs que ha salido cada una de las KWs, así en el caso de que queramos profundizar en alguna KW en concreto podemos ver todos sus datos.
Haciendo un pequeño resumen queremos obtener
- Visualizar los datos de Google Search Console de otra manera, primero, agrupando las diferentes variaciones de cada KW.
- Poder ver los datos agregados de cada grupo de Keywords, es decir, cuántos clicks, impresiones, CTR, etc de cada cluster de palabras.
- Poder ver los datos individuales de cada una, a ser posible con un simple click.
- Poder filtrar por fechas, o por palabra clave, por URL o por cualquier dimensión que tenemos.
- Priorización de contenido, os mostraré cómo hacemos con algunos clientes en FunnelPunk para los que es esencial saber dónde existe más oportunidad de negocio.
Comencemos!
Sinceramente, no voy a ponerme a contar qué es el NPL, que si python pa quí que si python pa cá.... creo que lo más importante es querer aprender las cosas un poco a fondo, programes o no programes, sepas SQL o no, seas un puto máquina con el Excel o te vaya más el bloc de notas, esto de la tecnología es cosa de actitud y pasión por el conoocimiento, si es de lo que trabajas mejor. Quiero decir, que no hace falta saber lo que yo voy a mostraros, sino simplemente saber qué existe y sobretodo, debemos profundizar en aquello que creamos que es importante y relevante.
El procesamiento de lenguaje natural es algo muy presente e irá a más, lo mismo que la analítica web, ya sea analizando tráfico SEO en Google Search Console cómo tráfico de campañas mediante Google Analytics y Google Marketing Platform, la cuestión que saber qué se puede hacer, cómo es de eficaz, hasta dónde llegan los recursos de tu empresa y qué se puede plantear y qué no.Si la empresa tiene músculo técnico (o de cartera para contratar o probar ..) Luego ya es cosa de plantear cosas realistas y útiles, si no, nos valdrá de mucho a parte de pasar un buen rato investigando...
Así que sepas programar, estadística o hacer malabares debajo del agua lo importante es saber qué puedes hacer tú, o tu empresa, para que cuándo haya un problema a resolver o un objetivo a cumplir poder saber qué sería lo más eficaz para conseguirlo.
Antes de nada, como veréis esto no es ni mucho menos magia, sino ocho mil pasos agrupados en algunas librerías, pero que muchos de nosotros ya venimos haciendo de una u otra manera a nuestra forma... pero
Tokenización
La tokenización es básicamente hacer una lista de palabras de lo que vayas a tratar, en nuestro caso cada consulta de búsqueda extraída de Google Search Console.
Por ejemplo para una KW como "¿cuál es el horario del corte ingles coruña?"
Primero debemos instalar spacy con pip o con conda
$ pip install -U spacy
o con conda
$ conda install -c conda-forge spacy
Ahora vamos a tokenizar una frase, por ejemplo "¿cuál es es el horario del corte ingles Coruña?"
texto = "¿cuál es es el horario del corte ingles Coruña?"
doc = nlp(texto)
tokens = [t.orth_ for t in doc] #y creamos la lista de
print(tokens)
Resultado:
['¿', 'cuál', 'es', 'el', 'horario', 'del', 'corte', 'ingles', 'Coruña', '?']
Vemos que simplemente ha separado el resto en palabras
Normalización
La normalización es el eliminar acentos, poner todas las palabras en minúscula, eliminar caracteres extraños o que no sean convenientes que entren en nuestros procesos.
Y ahora vamos a eliminar dos listados de palabras aquellas que por defecto están como palabras sin significado relevante
-
aquellas que por defecto están como palabras sin significado relevante
-
Las que existen en la lista de stopwords alfanumérico etc
palabras = [t.orth_ for t in doc if not t.is_punct | t.is_stop]
tokens_normalizados = [t.lower() for t in words if len(t) >= 3 and t.isalpha() ]
print(tokens_normalizados)El resultado es el siguiente
['horario', 'corte', 'ingles', 'coruña']
Vamos a probar con otra keyword "¿Cuáles son las mejores ofertas que hay en Vodafone?"
texto_2 = "¿Cuáles son las mejores ofertas que hay en Vodafone?""
doc = nlp(texto_2)
palabras = [t.orth_ for t in doc if not t.is_punct | t.is_stop]
tokens_normalizados = [t.lower() for t in palabras if len(t) >= 3 and t.isalpha() ]
print(tokens_normalizados)['mejores', 'ofertas', 'vodafone']Podemos observar que ha eliminado algunas palabras en ambos ejemplos, en el primero ha omitido la palabra "cuál" ,y en el segundo "cuáles", "son", "las", etc
Podemos (y debemos) revisar qué palabras serán excluidas por defecto en el análisis, eso lo podemos hacer así.
from spacy.lang.es.stop_words import STOP_WORDS
print(STOP_WORDS) {'contigo', 'estará', 'ésas', 'éste', 'señaló', 'buenos', 'estuvo', 'nuevos', 'pueda', 'igual', 'hacen', 'sabes', 'sabemos', 'horas', 'tuyas', 'afirmó', 'usamos', 'otros', 'fue', 'alli', 'tenemos', 'qué', 'eso', 'esas', 'tiempo', 'ninguna', 'ahora', 'intentar', 'proximo', 'haya', 'usar', 'donde', 'aunque', 'conseguimos', 'indicó', 'nada', 'total', 'solas', 'modo', 'vosotras', 'nuevo', 'podrias', 'alrededor', 'puede', 'demás', 'tuyo', 'tu', 'sabeis', 'realizar', 'llevar', 'haces', 'considera', 'hacia', 'quizas', 'ésta', 'ampleamos', 'primer', 'tendrá', 'ahi', 'tendrán', 'cualquier', 'próximo', 'tercera', 'cuáles', 'dicen', 'salvo', 'habrá', 'como', 'dado', 'intenta', 'pesar', 'cierta', 'verdadera', 'qeu', 'es', 'junto', 'he', 'diferente', 'cosas', 'momento', 'conseguir', 'cuántos', 'cuales', 'trabajan', 'despues', 'estas', 'aquéllos', 'algún', 'cuando', 'segundo', 'el', 'nosotros', 'dan', 'último', 'ni', 'quién', 'suyo', 'trabajo', 'tuyos', 'valor', 'dónde', 'aproximadamente', 'acuerdo', 'trabajar', 'nuestras', 'dicho', 'entonces', 'tambien', 'ademas', 'ciertos', 'muchas', 'todavia', 'ciertas', 'algunos', 'este', 'hay', 'deben', 'al', 'cuál', 'ver', 'varias', 'dijeron', 'dijo', 'informo', 'mí', 'poner', 'conocer', 'segun', 'se', 'tú', 'mi', 'cinco', 'pais', 'sin', 'queremos', 'luego', 'entre', 'mucho', 'mas', 'dos', 'intentais', 'habla', 'sería', 'sino', 'fin', 'todo', 'despacio', 'mismo', 'estaban', 'ésos', 'somos', 'fui', 'vuestro', 'cuanta', 'aquellos', 'mias', 'da', 'me', 'supuesto', 'mis', 'quien', 'cuanto', 'ir', 'lejos', 'intento', 'van', 'día', 'haceis', 'detras', 'mal', 'aquel', 'su', 'mucha', 'existen', 'anterior', 'tres', 'pasado', 'mayor', 'te', 'consigues', 'ejemplo', 'siendo', 'dieron', 'así', 'en', 'cuánta', 'vosotros', 'tan', 'largo', 'debido', 'tuya', 'sean', 'consigo', 'allí', 'estados', 'consigue', 'alguna', 'consiguen', 'hemos', 'ninguno', 'todas', 'puedo', 'poder', 'usted', 'ésa', 'debajo', 'sólo', 'aquí', 'vuestra', 'primera', 'sola', 'repente', 'menos', 'temprano', 'incluso', 'poca', 'tengo', 'estos', 'había', 'habia', 'usas', 'varios', 'enseguida', 'trata', 'muchos', 'alguno', 'siempre', 'otra', 'encuentra', 'nadie', 'peor', 'mia', 'paìs', 'poco', 'otras', 'lleva', 'sido', 'uso', 'podria', 'contra', 'aquella', 'mio', 'no', 'quienes', 'tiene', 'manifestó', 'hicieron', 'le', 'estan', 'vamos', 'realizado', 'unos', 'os', 'nosotras', 'podrian', 'vuestros', 'manera', 'podriais', 'sobre', 'agregó', 'tenido', 'ningunos', 'aquellas', 'nunca', 'ambos', 'antano', 'arriba', 'soy', 'nueva', 'estar', 'podría', 'intentamos', 'tarde', 'partir', 'sera', 'última', 'pocas', 'que', 'uno', 'nuestros', 'pero', 'yo', 'lugar', 'aquello', 'ellas', 'últimas', 'voy', 'mías', 'dice', 'todos', 'verdadero', 'delante', 'apenas', 'está', 'quedó', 'algo', 'míos', 'realizó', 'de', 'cuántas', 'medio', 'porque', 'llegó', 'serán', 'próximos', 'será', 'excepto', 'aun', 'actualmente', 'informó', 'ayer', 'ningún', 'comentó', 'mismas', 'sé', 'pocos', 'primeros', 'tus', 'eres', 'embargo', 'nuestro', 'bajo', 'antes', 'más', 'veces', 'antaño', 'las', 'era', 'podeis', 'estamos', 'eran', 'estado', 'usan', 'últimos', 'también', 'hoy', 'toda', 'intentan', 'muy', 'cuándo', 'podrían', 'podriamos', 'pueden', 'grandes', 'estaba', 'añadió', 'cuantas', 'mediante', 'bien', 'atras', 'ex', 'durante', 'asi', 'cuantos', 'lo', 'pues', 'va', 'cual', 'aseguró', 'unas', 'suya', 'nos', 'usa', 'trabajamos', 'con', 'principalmente', 'quiénes', 'trabajas', 'están', 'final', 'aún', 'si', 'mismos', 'expresó', 'parte', 'general', 'tras', 'propio', 'siete', 'ella', 'éstos', 'demasiado', 'enfrente', 'eras', 'hablan', 'ya', 'misma', 'pronto', 'son', 'pudo', 'tal', 'cada', 'ultimo', 'tanto', 'empleas', 'conmigo', 'fuera', 'gueno', 'trabajais', 'hago', 'buen', 'dentro', 'bueno', 'cerca', 'suyas', 'través', 'los', 'otro', 'esto', 'además', 'mientras', 'pasada', 'él', 'lado', 'deprisa', 'creo', 'siguiente', 'fueron', 'teneis', 'encima', 'haciendo', 'verdad', 'vaya', 'hacemos', 'buena', 'bastante', 'empleais', 'según', 'un', 'por', 'diferentes', 'éstas', 'podrá', 'haber', 'ti', 'quiere', 'esos', 'primero', 'algunas', 'mios', 'cierto', 'sí', 'solo', 'sus', 'saber', 'solos', 'dias', 'aquél', 'claro', 'dio', 'segunda', 'eramos', 'hacer', 'adelante', 'emplear', 'desde', 'dar', 'quizás', 'detrás', 'hubo', 'tienen', 'buenas', 'casi', 'seis', 'debe', 'ahí', 'mencionó', 'fuimos', 'ser', 'explicó', 'posible', 'respecto', 'tenga', 'cuatro', 'esta', 'aquélla', 'gran', 'tenía', 'podemos', 'hacerlo', 'solamente', 'les', 'parece', 'hizo', 'sois', 'vuestras', 'días', 'todavía', 'mejor', 'usais', 'nuevas', 'intentas', 'habían', 'mía', 'para', 'breve', 'aquéllas', 'tampoco', 'ello', 'quizá', 'ningunas', 'emplean', 'aqui', 'podrán', 'cuánto', 'mío', 'existe', 'ése', 'hecho', 'una', 'hasta', 'vais', 'soyos', 'cuenta', 'sigue', 'ustedes', 'decir', 'cómo', 'propia', 'esa', 'ante', 'sabe', 'tuvo', 'raras', 'después', 'estoy', 'quiza', 'adrede', 'consideró', 'dia', 'hace', 'vez', 'ocho', 'ellos', 'nuestra', 'han', 'tener', 'trabaja', 'ha', 'arribaabajo', 'menudo', 'del', 'sea', 'dejó', 'propios', 'la', 'estais', 'propias', 'ese', 'saben', 'empleo'}
['¿', 'Cuáles', 'son', 'las', 'mejores', 'que', 'hay', 'en', 'Vodafone', '?']
En el contexto de crear esta matriz SEO las palabras como "qué", "cuándo", dónde","cómo" no nos van a ser útiles. Puede tener sentido en muchos otras tareas diferenciar las distintas intenciones que podrían representar cada uno de esos términos.
Pero para el caso concreto de esta matriz no quiero que las valore, porque como os he mostrado antes, en el resultado final podremos desplegar todas los términos de búsqueda originales que existen en cada cluster,. Así tenemos por un lado los datos agrupamos de todas las Kws como clicks totales del cluster, impresiones totales del cluster, y cada métrica que sacamos de GSC, y además podremos desplegar y ver las consultas de búsqueda originales... lo mejor de los dos mundos :p.
Si quisiéramos que Google valorase alguna de las palabras que están como STOP_WORDS lo podemos hacer de la siguiente forma
nlp.Defaults.stop_words -= {"cual", "que", "como", "donde"}
Y si quisiéramos que ignore alguna palabra lo podemos hacer así
nlp.Defaults.stop_words |= {"no", "mas"}
print(STOP_WORDS)
Para focalizar lo visto hasta ahora vamos a crear una función para normalizar las palabras que le pasemos.
def normalize(text):
text = unidecode(str(text))
doc = nlp(text)
words = [t.orth_ for t in doc if not t.is_punct | t.is_stop]
lexical_tokens = [t.lower() for t in words if len(t) > 3 and t.isalpha() or re.findall("\d+", t)]
return ' '.join(lexical_tokens)
Lematización Vs Raíz (stemming)
Lematización
De manera resumida, la lematización es extraer para cada palabra su lexema qué puede ser diferente para una misma palabra. es decir. es dependiente de su contexto.
La manera compleja "La lematización es el proceso mediante el cual las palabras de un texto que pertenecen a un mismo paradigma flexivo o derivativo son llevadas a una forma normal que representa a toda la clase" (fuente).
Stemming
Mientras que el stemming, es quedarse con la raíz pero no tiene en cuenta el contexto. Para esta tarea usaremos Stemming ya que rinde mejor al ser frases cortas. La lematización seguramente sea mejor con textos más largos dónde la posición en la oración indica tiene significado, y es capaz de asociar dos palabras completamente diferentes pero que tienen el mismo significado.
Como se suele decir, lo ideal es probar ambos e identificar cuál es mejor para según qué cosas...
Vamos a ver algunos ejemplos de ambos para comprender la diferencia, vamos a crear otras dos funciones, una para la lematización y otra para el stemming
Lematización:
def lematizar(text):
lemma_text = unidecode(str(text))
doc = nlp(lemma_text)
lemma_words = [token.lemma_ for token in doc if not token.is_punct | token.is_stop]
lemma_tokens = [t.lower() for t in lemma_words if len(t) > 3 and t.isalpha() or re.findall("\d+", t)]
return ' '.join(sorted(lemma_tokens))
Stemming:
def stem_sentences(sentence):
tokens = sentence.split()
stemmed_tokens = [spanishstemmer.stem(token) for token in tokens]
return ' '.join(sorted(stemmed_tokens))
lemas = [tok.lemma_.lower() for tok in doc]
print(lemas)['¿', 'cuáles', 'ser', 'los', 'mejorar', 'ofertar', 'que', 'haber', 'en', 'vodafone', '?']Y ahora vamos a normalizar y luego lematizar y stemming
texto = "Cuál es es el horario del CorteIngles de A Coruña?"
texto_normalizado = normalize(texto)
texto_stem = stem_sentences(texto_normalizado)
texto_lemaa = lematizar(texto_normalizado)
print("Texto Original:\t",texto)
print("Texto Lematizado:\t",texto_lemaa)
print("Texto setmming:\t",texto_stem)
Resultado:
Texto Original: Cuál es es el horario del CorteIngles de A Coruña?
Texto Lematizado: horario corteingles coruna
Texto setmming: horari corteingl corun
Vamos a probar con otra keyword
texto = "¿Cuáles son las mejores ofertas que hay en Vodafone?"
texto_normalizado = normalize(Ejemplo_KW)
texto_stem = stem_sentences(texto_normalizado)
texto_lemaa = lematizar(texto_normalizado)
print("Texto Original:\t",texto)
print("Texto Lematizado:\t",texto_lemaa)
print("Texto setmming:\t",texto_stem)Resultado:
Texto Original: ¿Cuáles son las mejores ofertas que hay en Vodafone?
Texto Lematizado: mejorar ofertar vodafone
Texto setmming: mejor ofert vodafonPodemos ver que hay cierta diferencia entre lo que hace la lematización, y lo que hace el stemming. Para la agrupación de Keywords que estamos haciendo es mejor Stemming ya que reduce significativamente el número de clusters resultantes
Por último en este artículo he añadido también un pequeño diccionario para reemplazar determinados términos que tienen menos de 3 caracteres pero que quizás sí queremos que sean valorados, por ejemplo para la palabra "Windos XP" no queremos que ignore el término "XP" por lo que lo reemplazamos para que quede "WindowsXP" así no ignorará ese par de KWs que realmente aportan significado y valor.
Posiblemente el diccionario se puede mejorar mucho, pero lo dejaré para el próximo artículo de esta saga
eplace_dict = {
re.compile(r'^windows xp(.*)'): r'windowsxp \1',
re.compile(r'(.*) windows xp (.*)'): r'\1 windowsxp \2',
re.compile(r'(.*) windows xp'): r'\1 windowsxp'}
Solo nos falta una cosa.. las KWs y datos de Google Search Console. Podéis exportar hasta 50.0000 filas de datos de >Google Search Console usando la Punk Tool que desarrollé totalmente gratuita.
df = pd.read_csv ('nombreCSV.csv')
Código fuente del script para agrupar keywords de Google Search Console
Este código incialmente fue inspirado tras leer este post, lo he modificado un poco, y veremos en los siguientes posts como este código no es del todo útil para grandes cantidades de datos, pero fue inspirador :)
Aquí dejo mi código en un cuaderno de Colab
Recordad
- Subir el fichero csv a la carpeta razí de colab o dónde lo ejecutéis
- Cambiar el nombre del fichero a "nombreCSV.csv"
En el próximo artículo veremos cómo mejorar este código par hacerlo mucho más eficiente en cuanto a la programación, porque veréis que tarda un rato en procesar todas las KWs. El que usamos nosotros, digamos que es instantáneo :)
!python -m spacy download es_core_news_sm
!pip install Unidecode
#@title
import argparse
import sys
import pandas as pd
from nltk import SnowballStemmer
import spacy
import es_core_news_sm
from tqdm import tqdm
from unidecode import unidecode
import glob
import re
import requests
import json
nlp = es_core_news_sm.load()
spanishstemmer=SnowballStemmer('spanish')
#CAMBIAR EK NOMBRE DEL CSV POR EL TUYO QUE SUBAS A COLAB
df = pd.read_csv('nombreCSV.csv')
def normalize(text):
text = unidecode(str(text))
doc = nlp(text)
words = [t.orth_ for t in doc if not t.is_punct | t.is_stop]
lexical_tokens = [t.lower() for t in words if len(t) > 3 and t.isalpha() or re.findall("\d+", t)]
return ' '.join(lexical_tokens)
def lematizar(text):
lemma_text = unidecode(str(text))
doc = nlp(lemma_text)
lemma_words = [token.lemma_ for token in doc if not token.is_punct | token.is_stop]
lemma_tokens = [t.lower() for t in lemma_words if len(t) > 3 and t.isalpha() or re.findall("\d+", t)]
return ' '.join(sorted(lemma_tokens))
def stem_sentences(sentence):
tokens = sentence.split()
stemmed_tokens = [spanishstemmer.stem(token) for token in tokens]
return ' '.join(sorted(stemmed_tokens))
texto = "¿Cuáles son las mejores ofertas que hay en Vodafone?"
texto_normalizado = normalize(texto)
texto_stem = stem_sentences(texto_normalizado)
texto_lemaa = lematizar(texto_normalizado)
print("Texto Original:\t",texto)
print("Texto Lematizado:\t",texto_lemaa)
print("Texto setmming:\t",texto_stem)
lace_dict = {
re.compile(r'^windows xp(.*)'): r'windowsxp \1',
re.compile(r'(.*) windows xp (.*)'): r'\1 windowsxp \2',
re.compile(r'(.*) windows xp'): r'\1 windowsxp'}
loop = tqdm(total = len(df.index), position = 0, leave = False)
print(df.head())
loop = tqdm(total = len(df.index), position = 0, leave = False)
df['Grupo'] = ''
df['kw_nomrmalizada'] = ''
df['kw_lematizar'] = ''
df['raiz'] = ''
for i in df.index:
loop.set_description("Agrupando...".format(i))
kw = df.loc[i,'query'];
df.loc[i,'kw_nomrmalizada'] = normalize(kw)
df.loc[i,'kw_lematizar'] = lematizar(df.loc[i,'kw_nomrmalizada'])
df.loc[i,'raiz'] = stem_sentences(df.loc[i,'kw_nomrmalizada'])
print('
\tkw=>\t',kw)
print("Normalñizada=>\t", df.loc[i,'kw_nomrmalizada'])
print("Steemeada'=>\t",df.loc[i,'raiz'])
print("Lemmatizada'=>\t",df.loc[i,'kw_lematizar'])
loop.update(1)
loop.close()
print('Agrupado... OK')
df.to_csv('kw_procesado.csv', index=False, encoding='utf-8-sig')
print('Archivo kw_procesado.csv creado... OK')
print('Proceso finalizado... OK')
Este proceso devolverá el mismo csv pero añadiendo dos columnas nuevas
- "kw_normalizada": como su nombre indica es la columna "query" pero con el texto normalizado
- "kw_lematizar": la keyword lemtaizada
- "kw_raiz": la raíz de la keyword
Hasta aquí el post de hoy, en los próximos artículos veremos como hacer que este proceso sea rápido, ya que con muchos datos puede ser internminable, tanto que no es factible ponerlo en producción, pero os enseñaré cómo hacerlo con otra herrramienta más rápida que Pandas.
Artículos en Agrupación - Clustering de keywords SEO en Google Search Console
1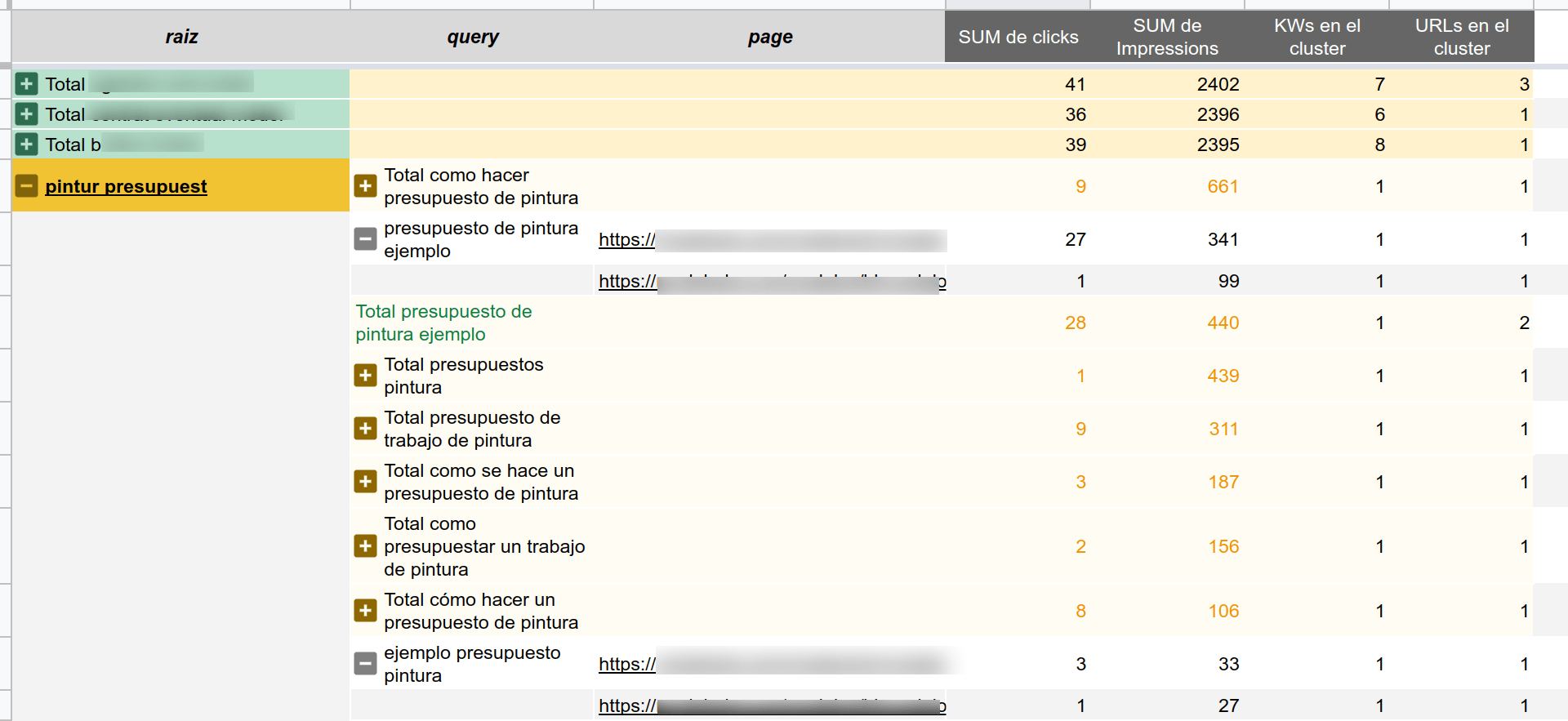
Clustering de keywords SEO en Google Search Console - Parte II
Publicado el 6 de septiembre del 2021 por Lino Uruñuela índice de contenidos Categorizar / clasificar palabras clave Vs Agrupar términos de búsqueda Categorizar / Clasificar kws en base a una lista previamente definida Agrupar términos de búsqueda A veces lo simple funciona mejor Tabla dinámica de palabras clave para…
Comentarios
Todavía no hay comentarios publicados.