¿Pre-panda, Google caffeine o un poquito d ambas?
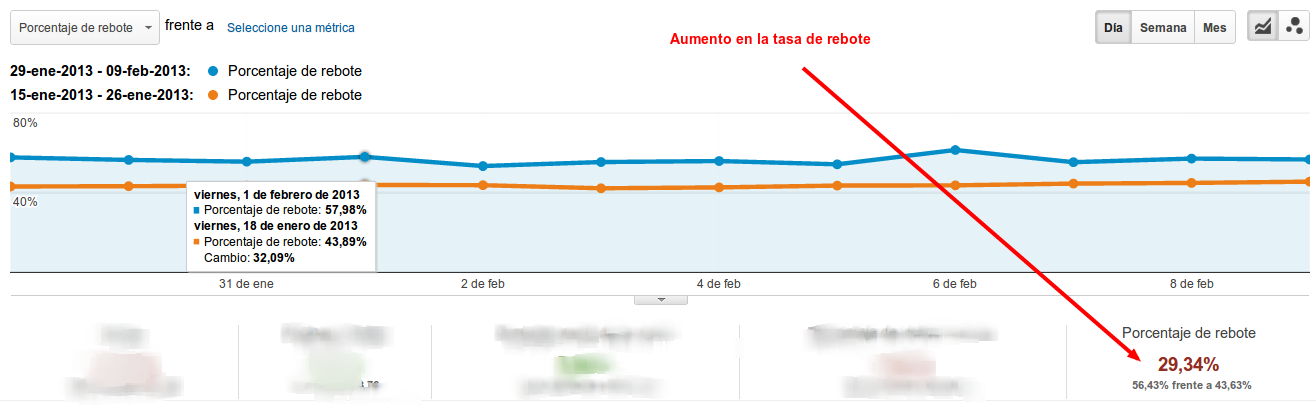
Ya se están viendo cambios en las estadísticas de muchos sites, ¿será Panda 2.2?
Y es que el otro día Matt Cuts comentó que la actualización a Panda 2.2 llegará en breve, la verdad es que dijo que no era cosa de semanas sino de meses. Y justo unas semanas después comienza a ocurri esto. Una de dos o el tío nos dio una pista sobre que este cambio no era Panda 2.2 o es un cabrón ;)
Se puede ver si vas a Motores de busqueda -> Google organic y comparamos este miércoles, jueves, viernes con los de las semanas anteriores y veremos si estamos o no afectados.
El cambio que hizo Google con Panda Update tenía como objetivo, o eso decían, las granjas de contenidos que se dedicaban a copiarlos de otras webs o a crearlos de muy baja calidad con el objetivo de salir por términos poco competidos pero muy buscados. estas páginas podían/pueden llegar a tener una grandísima cantidad de tráfico, pero de muy mala calidad, ej taringa.net
También decían que tenía como objetivo detectar y eliminar contenido duplicado de sus resultados. Y es que realmente son muy pocas las descripciones distintas que hay sobre un mismo producto. Hay muchísimas webs que tienen mucho contenido entre si, puede que organizado de distintas maneras pero el usuario que busca en Google un determinado producto, entrará en el primer resultado, y luego le dará atrás para ver otras opciones, y pinche en el segunda resultado, entrará en la web, que será distinta a la primera en cuanto a diseño pero luego en el texto que se refiere al producto y que es lo que realmente quiere ver el usuario es exactamente igual al de la primera página. Volverá a darle atrás y entrará en el tercer resutlado y sería lo mismo, y en el cuarto y en el quinto... Internet está lleno de contenido duplicado!!! y Google está intentando ofrecer mayor variedad de resultados a sus usuarios.
Pero la verdad es que la actualización de estos días no parece hacer nada con ese tipo de webs. Las caídas de tráfico son indiferentes a si es duplicado ese contenido o no. Tengo webs que han descendido un 15%, dentro de la sección que es contenido duplicado baja de igual manera que en las secciones que no lo son.
Tampoco tenemos noticias de sites considerados como granjas de contenidos hayan sido especialmente afectados, parece que es general que el que se ve afectado sea a la baja, muy muy pocos sites han suido.
Otro punto a tener en cuenta es que las webs pequeñitas casi casi no se ven afectadas, y alguna de estas sí se ve un aumento, pero no muy grande.
Interesante son estos puntos para mi:
- El número de URLs que traen tráfico desde Google haya descendido
- El número de keywords que traen tráfico hacia una URL también desciendan
- Llas palabras principales para cada URL siguen bien posicionadas, las que pierden son las de Long Tail
- Algunos aseguran que han vuelto a las posiciones anteriores al primer lanzamiento de Panda, así que algo de Panda tiene seguro, supongo!
No sé si es pre-panda (test que Google hace oara comprobar la calidad de la actualización que se prepara) o si es algo relacionado al índice de Google y aquello de la cafeina...
Habrá que seguir atentos esta semana para ver qué ocurre ya que puede ser bastante importante el cambio.
Comentarios
7Lee otros artículos
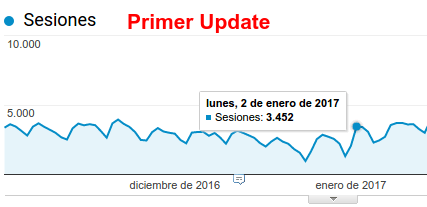
Google comienza el año con dos updates
Publicado por Lino Uruñuela el 23 de febrero del 2017 Este año 2017 ha empezado con movimientos comvulsivos en las gráficas de tráfico orgánico en muchas webs. Yo he notado varios updates de Google y con bastante impacto, vamos a resumirlos un poco. ¿Primer Update del año, 2 de enero? Comenzamos el día 2 de enero con…
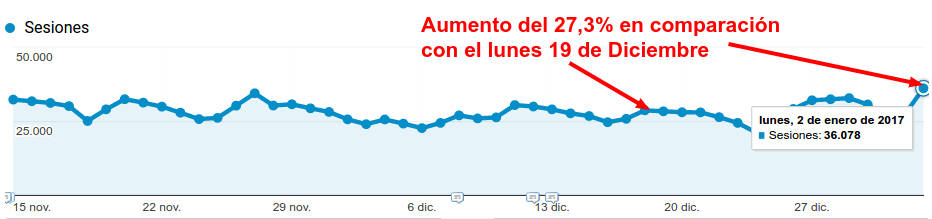
¿Christmas Update?
Publicado por Lino Uruñuela el 3 de enero del 2017, San Sebastián. Google no acostumbra a realizar cambios drásticos cuando llegan fechas críticas para los comercios, como por ejemplo en Navidad, donde se aumentan muchísimo las transacciones por causa de los regalos, y dónde un error podría hacerle perder mucho dinero…

¿Dosis de cafeína en Panda 4.0?
Publicado por Lino Uruñuela ( Errioxa ) el 27 de mayo del 2014 El otro día comentamos alguna cosa que percibimos con el último update de Google, Panda 4.0 , y decíamos que una de las cosas que más destacan es la reducción del número de resultados de un mismo dominio en la primera página de las serps. Ahora leo que Mat…
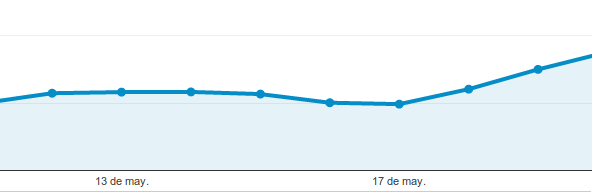
Nuevo Update de Panda, ¿qué ha cambiado?
Publicado por Lino Uruñuela ( Errioxa ) el 21 de mayo del 2014 Hoy nos hemos levantado con la confirmación por parte de Google de dos nuevas actualizaciones en su algoritmo, una Payday Loan Algorithm , que afecta búsquedas spam. Estas búsquedas suelen ser temas de porno de de "cómo ganar dinero" y cosas así y que no d…
El futuro es la búsqueda por voz
Publicado por Lino Uruñuela ( Errioxa ) el 29 de abril del 2014 Hoy he leído que Google Voice se va a extender a muchas más aplicacione de Google y no solo, como hasta ahora, a las búsquedas web (tanto en el móvil como en tablets, o el ordenador de sobremesa). En la cuestión de la búsqueda por voz, en vez de escribién…
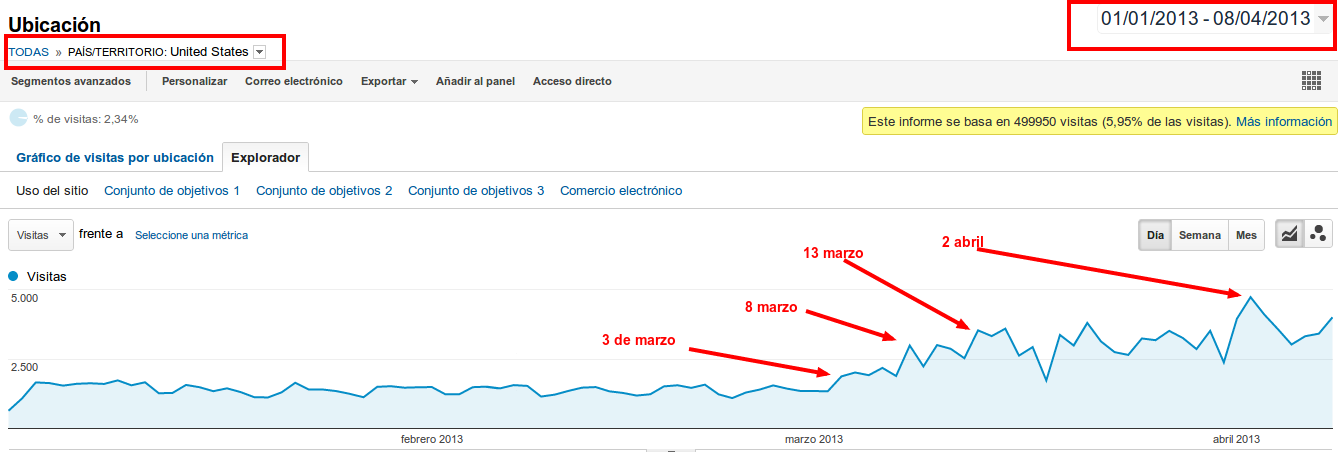
Aumento de visitas desde USA
Publicado el 10 de abril del 2013 by Lino Uruñuela Actualización: Sólo ocurre en el tráfico directo, en tráfico orgánico y tráfico de referencia no ocurre Desde comienzos de este mes de abril he notado algunos cambios en las visitas recibidas, al principio no sabía muy bien ya que coincidía con la Semana Santa y no es…
Atrapando al usuario en el nuevo Google Images
Publicado el 10 de febrero del 2013, by Lino Uruñuela ACTUALIZACIóN: El primer código del htaccess que puse al final del artículo tenía algún error. Estoy intentando hacer que funcione siempre, algo va mejorando. En estos momentos tengo así el htaccess, aunque parece que no llega a func ionar del todo . Con Firefox sí…
¿Cómo podría identificar Google las webs SEO?
Publicado el 20 de marzo del 2012 El otro día Matt Cutts comentó que en estas próximas semanas/meses habrá una actualización del algoritmo para identificar las páginas sobreoptimizadas en el aspecto SEO. Se ha comentado en varios sitios como WMT SER o SEL Los puntos que comenta la verdad que no son nada nuevo keyword…
Cómo saber si estás afectado por Google Panda
Publicado el 14 de agosto del 2011, by Lino Uruñuela, Como bien sabemos todos Google lanzó el viernes la nueva actualización Panda . En un primer momento ha habido una euforia general porque todos veíamos como nuestras visitas subían en comparación con días anteriores pero es que Google Analytics ha aprovechado para c…
Sobre Google Panda
Publicado el 9 de junio del 2011, by Errioxa Nunca un animal había causado tanto miedo entre los negocios de internet, y es que puede llegar a ser muy peligroso si caza y te confunde con bambú. He leído mucho sobre esta actualización de Google, he visto casos, he oído todo tipo de conjeturas, pero no he visto a nadie…
El otro dia Barry en la conferencia SEO de Madrid dijo que una sola sección con baja calidad puede perjudicar el entero site. Igual es por eso que te baja trafico de igual manera en secciones "malas" y secciones buenas. De todas formas estoy de acuerdo contigo, todavía el Panda no está discriminando bien entre granjas de contenidos y páginas con contenido de calidad. En algunas webs que controlo hemos notado algo pero no sé cuanto es atribuible a Google. Gran post como siempre! gracias Fabio
>>Una de dos o el tío nos dio una pista sobre que este cambio no era Panda 2.2 o es un cabrón ;) Me inclino a pensar que es lo segundo. Respecto al algoritmo ¿realmente es importante el nombre? XDD
En mi caso coincide lo que citas que no se ven afectadas palabras principales pero si mucho el long tail, auqnue tb coincide con la pérdida de un link de alto PR. A saber a que será debido pero pierdo mas del 20% del tráfico y tampoco coincide con las fechas que citan del 16 de junio mas bien ha sido poquito a poco
Hola Errioxa, Lo que comentas es perfectamente compatible con el algoritmo para medir la calidad del contenido en función de la experiencia del usuario: 1. El número de URLs que traen tráfico desde Google haya descendido Obvio, muchos long-tails están vacíos, o son de poca calidad. El usuario entra, pero sale y vuelve a realizar la misma búsqueda. Ganan "los buenos". 2. El número de keywords que traen tráfico hacia una URL también desciendan Obvio también, una misma url puede ser buena para una keyword (los usuarios se quedan), y mala para otras keywords (vuelven a buscar otra vez en google). 3. Las palabras principales para cada URL siguen bien posicionadas, las que pierden son las de Long Tail Todo ok siguiendo el mismo criterio de experiencia de usuario.
Te han enlazado esta entrada en el 14... ;-)
@pande es verdad!! jajaja, nunca lo pensé!!
Ahora como mides el número de keywords? Ya no se pude en GSC