AI Cutreviews de Google
Pueblicado por Lino Uruñuela
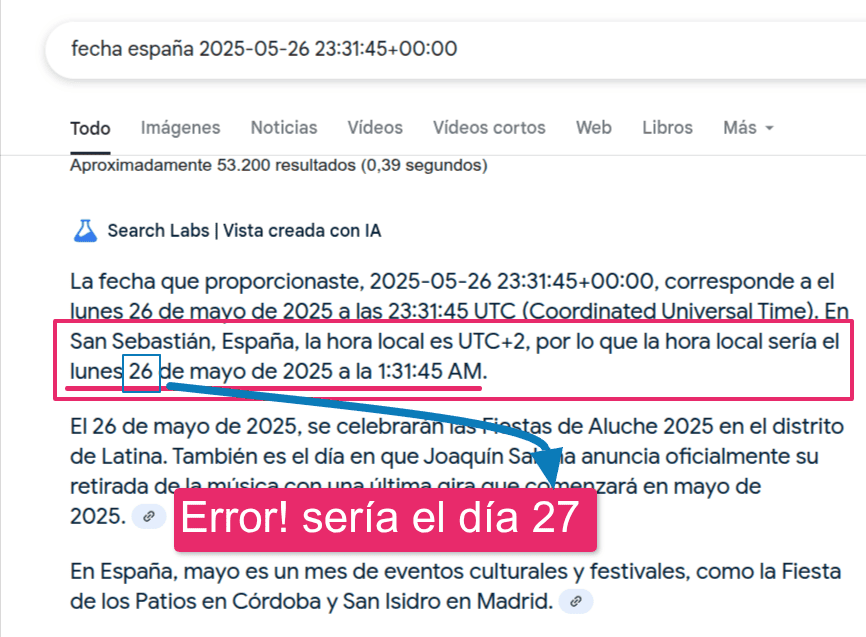
Ayer, tuve una duda con el formato de una fecha, concretamente tenía una fecha que parecía formato UTC: 2025-05-26 23:31:45+00:00. Digoa “parecía” porque realmente este no es formato UTC, ya que debería llevar una ‘T’ mayúscula en vez de un espacio entre la fecha y la hora (2025-05-26T23:31:45+00:00), realicé la búsqueda en Google con la query “fecha en España 2025-05-26 23:31:45+00:00” .
La hora eran las 23:31 en hora UTC, esto quiere decir que en España eran dos horas más tarde, por lo cual, la hora que me esperaba de Google hubiera sido las 23:31 en la cadena de texto UTC, en Donosti hubieran sido la 1:31 del día 27 (DÍA SIGUIENTE), pero no, se confundió...
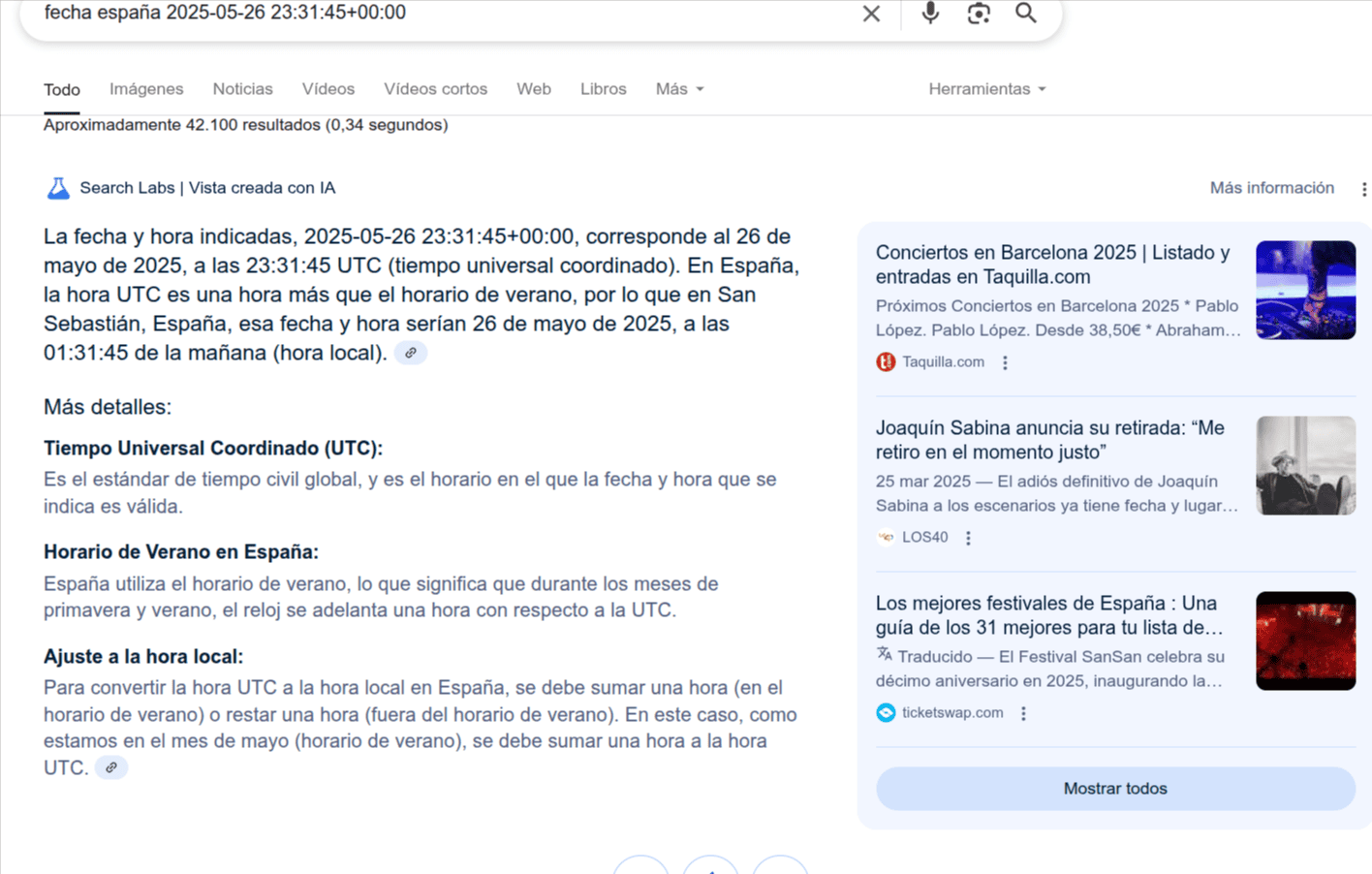
En la respuesta que Google generaba mostraba la explicación que Google mostraba debía de sumar ese +2 a la hora UTC para obtener de esta forma la hora local en España. En la explicación, Google detalló que al ser verano solo habría que sumar una hora, pero luego le suma dos horas, el razonamiento no estaba del todo mal, pero la ejecución ya es otra cosa.... Como vemos a continuación cada vez que recargaba me daba un resultado diferente,
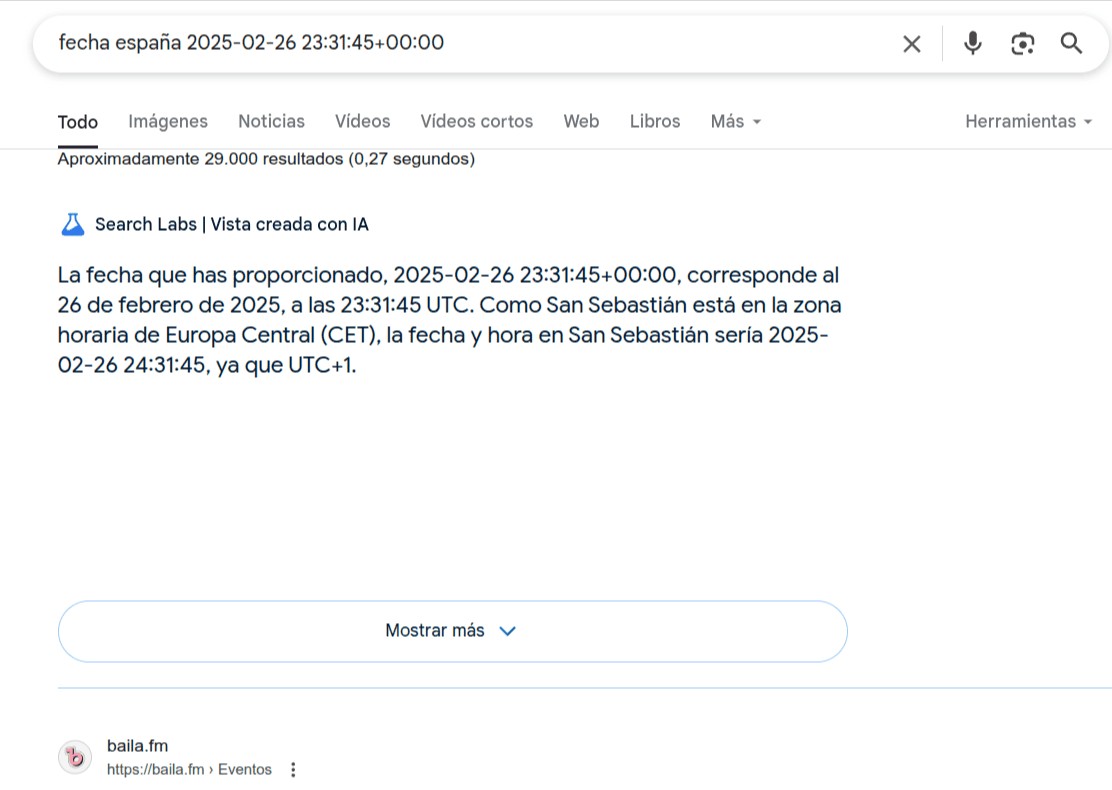
A veces acertaba, a veces fallaba.... Tuvo fallos bastante grandes como añadir 5 horas más, vete a saber por qué.
VERIFICADO: HOLA CARACOLA
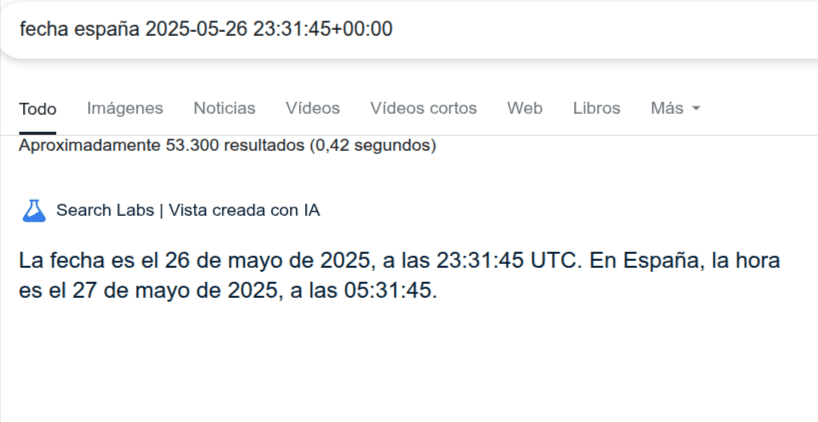
El error más común lo cometía con el día, que aunque calculase bien la hora sumando 1 hora a la hora UTC, no pasaba de día al rebasar las 00:00 de la noche, por ejemplo. Si la hora UTC era las 23:30, en formato local de aquí de España, al sumarle una hora, debería cambiar de día, y pasar del 26 al 27, a veces lo hacía a veces no, es más, yo recargaba continuamente la URL y la respuesta y cambiaba, y cambiaba, y cambiaba.
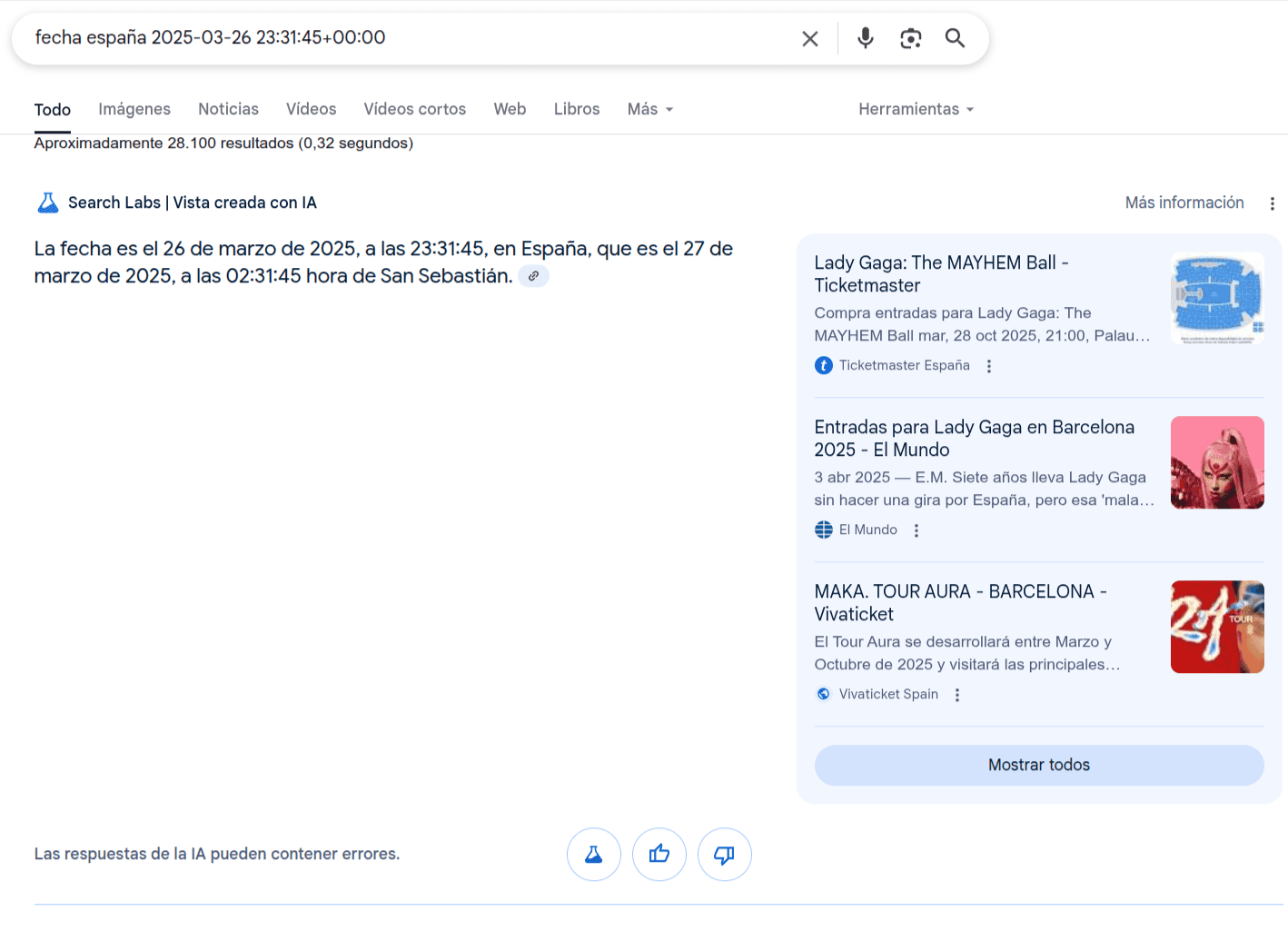
Pero el colmo fue con las citas.... al principio me mostraba diferentes citas, y daba por hecho de que el contenido o el conocimiento de cómo calcular las fechas lo habría obtenido de los resultados citados, pero cuando me fijé y accedí al contenido que citaba.... Como podéis ver, el contenido es de lo más variopinto, desde Lady Gaga a Sabina.
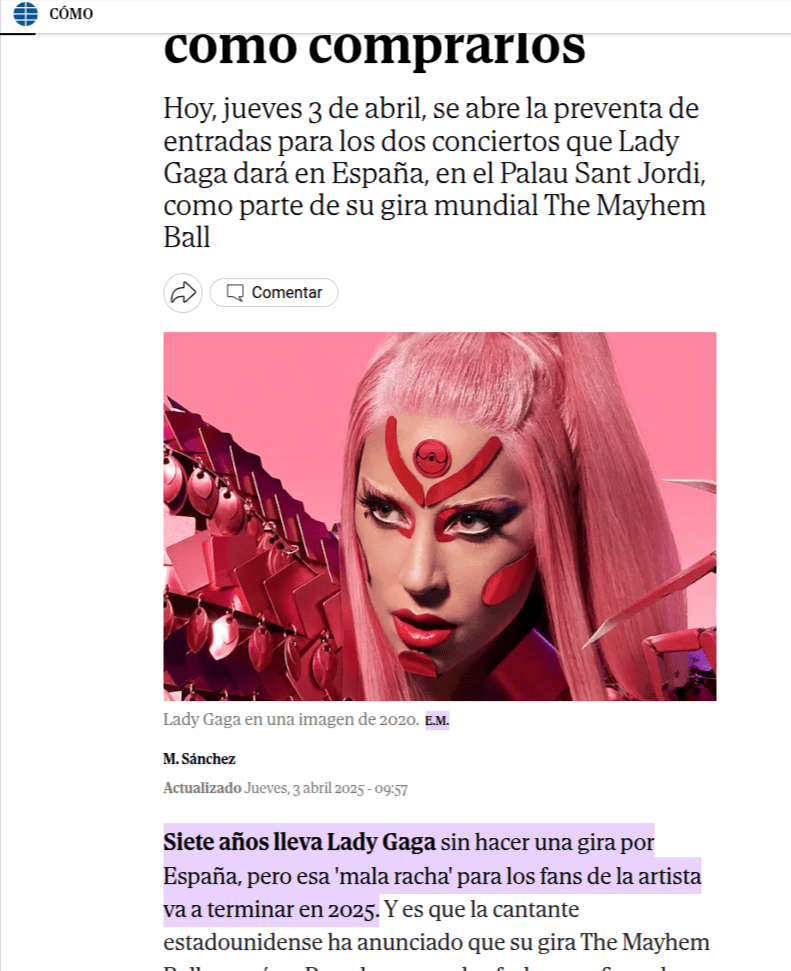
Sabina y sus ¿fechas de retirada?
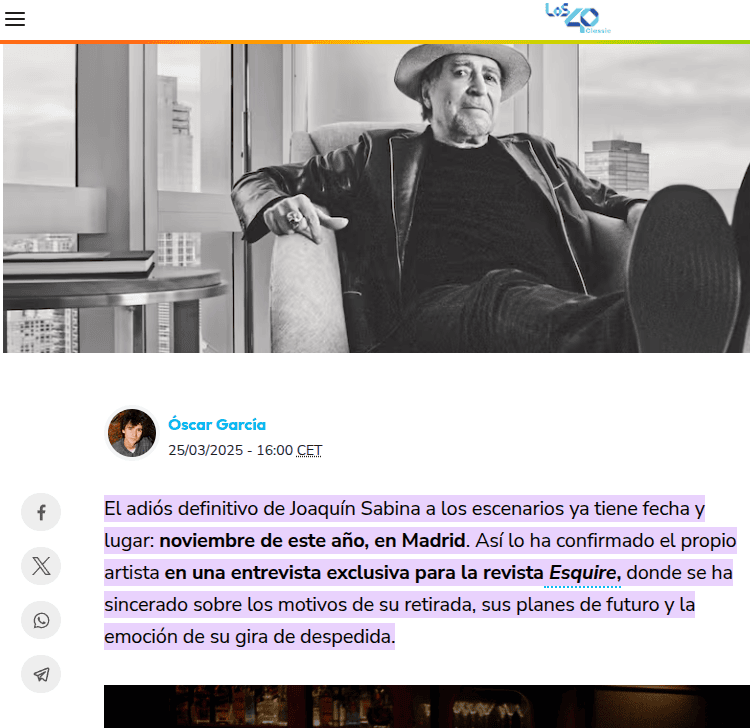
¿Qué tiene que ver lo que nos está mostrando como las fuentes de la respuesta con la respuesta? NADA, el contenido que cita no tiene absolutamente nada que ver con el cálculo de fechas, uso horario ni nada parecido. Google no está obteniendo de ahí el contenido, ni el conocimiento, ni los números, ni nada de nada. Creo que muestra citas simplemente por calmar los ánimos al sector, de los creadores de contenido, etc. A la vista está que Google realmente no está obteniendo datos ni conocimiento de las fuentes que muestra!,
Google está "razonando" para calcular la su respuesta, aunque lo haga mal, pero "echa" las cuentas e intenta seguir unos pasos lógicos sobre cómo calcular la hora que sería en España usando cierto contexto como si es verano o no, pero, ¿por qué nos pone esas citas si es mentira? ¯\_(ツ)_/¯
Resultados en inglés para búsquedas en español
El otro día en el Search Live de Madrid Gianlucca me comentó algo que me quedé rumiando en mi cerebro, concretamente me comentó que Google estaba mostrando muchos resultados en inglés para preguntas o consultas que hacían los usuarios en otros idiomas como el español, el italiano, etc, un ejemplo:
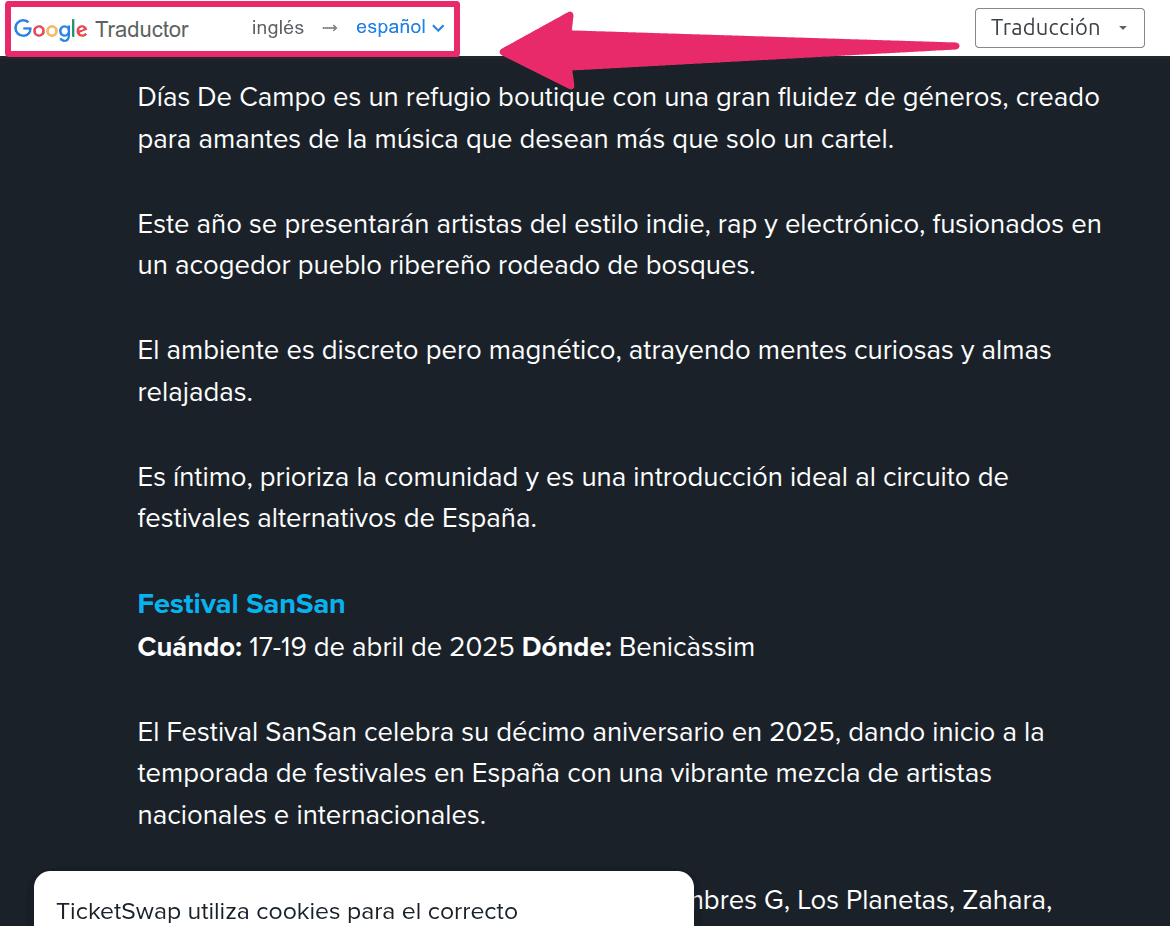
Llevo monitorizando serps bastante tiempo, y tengo miles y miles de ejemplos de esto, lo dejaré para otro post, mi duda ahora es ¿por qué Google está mostrando traducidos usando Google Translate? Me recuerda a cuando hacíamos páginas hace 15 años para intentar traducir sin esfuerzo nuestras webs (MFA /made for AdSense) e intentar ganar dinero simplemente añadiendo un widget... pues eso es justamente lo que está haciendo Google y no tiene ningún sentido.
Para algunas búsquedas podría ser útil, quizás la fuente únicamente exista en otro idioma, pero para cuestiones "simples" también selecciona el contenido de fuentes en inglés. Y eso, en mi opinión es un gran error porque para muchas preguntas el contexto del país y del idioma sean muy relevantes, de nada te valdrá la explicación de coger una rotonda correctamente si te dice que la tomes hacia la izquierda... o para cuestiones legales ya que sus leyes no serán como las nuestras...
Creo que es un error gravísimo lo que está haciendo Google con estos resultados cutremente traducidos, no está prestando atención. Subestima los cientos de millones de usuarios que se darán cuenta de estos fallos, y generará desconfianza. No me acuerdo quién hizo la pregunta en SEO Live cuándo preguntó por qué salían resultados en inglés en vez de en español, y los Googlers allí presentes respondieron como sorprendidos: “¡Ah, ¿y no es útil mostrar, aunque sea el contenido en inglés, si te lo estoy traduciendo?” No, no es útil. En muchos casos es una respuesta errónea o incompleta.
¡Cutre!
¡Cutre! No hay otra palabra para definir el cómo está implementando esto en otros idiomas más allá del inglés, es un método cutre, tacky, lame, bricolé, raffazzonato, schäbig,. ¿Tanta inteligencia artificial, tantos modelos, tantos LLMs, tanta gente, para hacer esta cutrez?.
Realmente, creo que no está nada maduro. No sé yo los errores que puede provocar este tipo de respuestas cuando se expandan a otros idiomas, que por lo que estoy viendo, va a tardar bastante en llegar el AI Mode. Ese que han anunciado ya en Estados Unidos y que está activo para todos en Estados Unidos. Tengo la impresión de que vamos a tardar a ver los nuevos AI Mode de Google en otros idiomas que no sean el inglés porque como vemos no es muy confiable, y si no es confiable no será útil, además de que se inventa las fuentes....
Cómo podría Google estar escogiendo estas fuentes y/o textos
Publiqué en el blog cómo Google podría estar seleccionando los fragmentos destacados usando una similaridad entre el embedding de la consulta del usuario y los embeddings del los h1, h2, etc jeraquizados de los documentos candidatos en las serps.
Podríamos resumir un poco así a grandes rasgos el proceso:
- Generación de Embeddings de la Consulta: Primero, Google convierte tu consulta en un vector de embeddings.
- Comparación de Similitud: Luego, compara este vector con los embeddings de fragmentos de cada uno de los documentos recuperados para encontrar el que más se asemeje.
- Consideración de la Jerarquía de Encabezados: Google también tiene en cuenta la similitud/cercanía de cada fragmento candidato con sus encabezados (H1, H2, H3, etc.) superiores jerárquicamente. Posiblemente "sume" la similitud que hay entre el fragmento candidato y la concatenación de los Hx que están jerárquicamente en su nivel superior inmediato hasta llegar al título.
Pero no todos los embeddings son iguales, ni valen para la misma tarea, por ejemplo, para hacer una búsqueda semántica para obtener cuán de parecido es el significado de dos textos podría ser un tipo de embeddings que pueden ser útiles a la hora obtener determinado contenido duplicado. Imagina que quieres ver la similitud entre los diferentes titles de los artículos de blog, en este caso podrías hacer una comparación de similitud por embeddings para cada título de un artículo con el resto de títulos, aquellos que su similitud sea mayor que cierto umbral podrías calificarlos como duplicados. Ese sería un ejemplo de embeddings de similaridad semántica.
Como expliqué, para la pregunta “¿por qué el cielo es azul?” la respuesta no va a ser lo más parecido semánticamente a esa frase, recordad que la similitud no significa relevancia. La respuesta posiblemente sea mucho más larga y no notaremos ese parecido semántico que subyace a las palabras y al contexto y que hace que los LLMs parecen que hagan magia al obtener estas relaciones subyacentes que hay en las palabras.
La respuesta no será lo más parecido a “por qué el cielo es azul”, la respuesta será, por ejemplo : “el cielo es azul porque está compuesto mayoritariamente de oxígeno y la temperatura a la que está la Tierra en temperatura ambiente, en la atmósfera, y cómo recibe nuestro propio ojo la radiación y cómo provoca las vibraciones en el ozono, pues lo vemos azul”. Como véis la respuesta a una pregunta breve podría ser muy diferente a la pregunta y no es similar como lo entendemos comúnmente.
El que veamos cómo Google responde en inglés a preguntas en otros idiomas creo que podría ser una pista sobre el tipo de embeddings que podría usar Google para obtener estas respuestas, por ejemplo estos nuevos embeddings de Gemini podrían estar detrás de esos resultados, son pistas que nos puede orientar en qué ir ajustando / mejorando / probando diferentes métodos y métricas que nos indiquen si un cambio en determinadas partes del texto es positivo o negativo.
Lee otros artículos
Visualiza las ejecuciones de Claude Code
Cuándo utilizamos Claude Code puede que no te des cuenta de la cantidad de procesos que pueden estar ocurriendo hasta que el LLM te ofrece la respuesta o realiza la tarea que le has indicado. Yo normalmente utilizo Langfuse en local para observabilidad IA, y me es realmente útil para entender qué hace Claude Code en c…
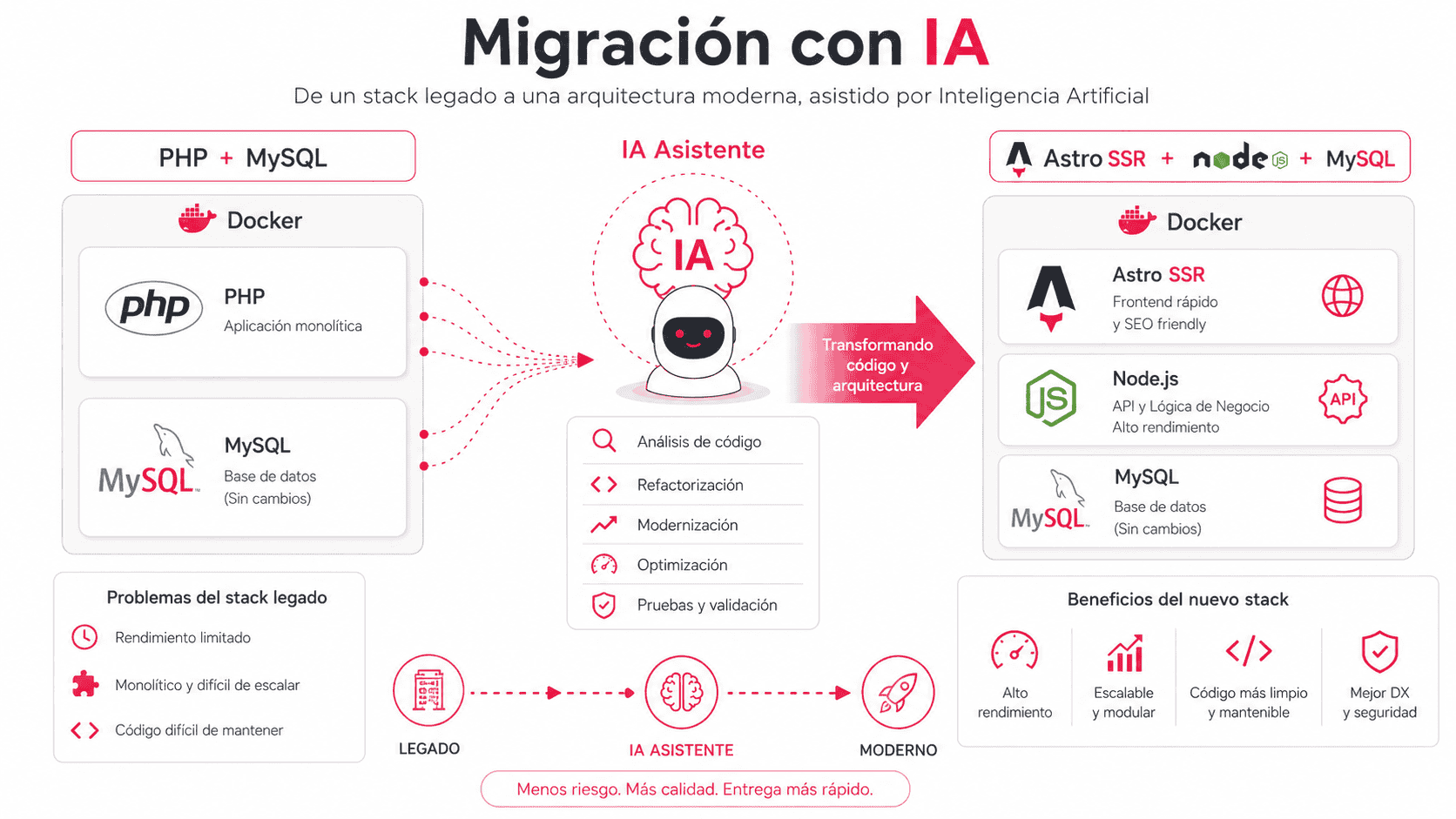
Migrar web en PHP a Astro usando IA
¡Bienvenidos al nuevo diseño de Mecagoenlos.com! Llevaba años queriendo hacer esta migración, pero me daba muchísima pereza, no por cambiar el diseño en sí, que eso lo tenía relativamente fácil tal como tenía montado mi sistema de includes en PHP, sino por todas las excepciones que tenía para muchos, muchos experiment…

Arquitectura de agentes para SEO
Hoy la IA está en boca de todos, pero ¿está en nuestra mente y en nuestros procesos de trabajo?
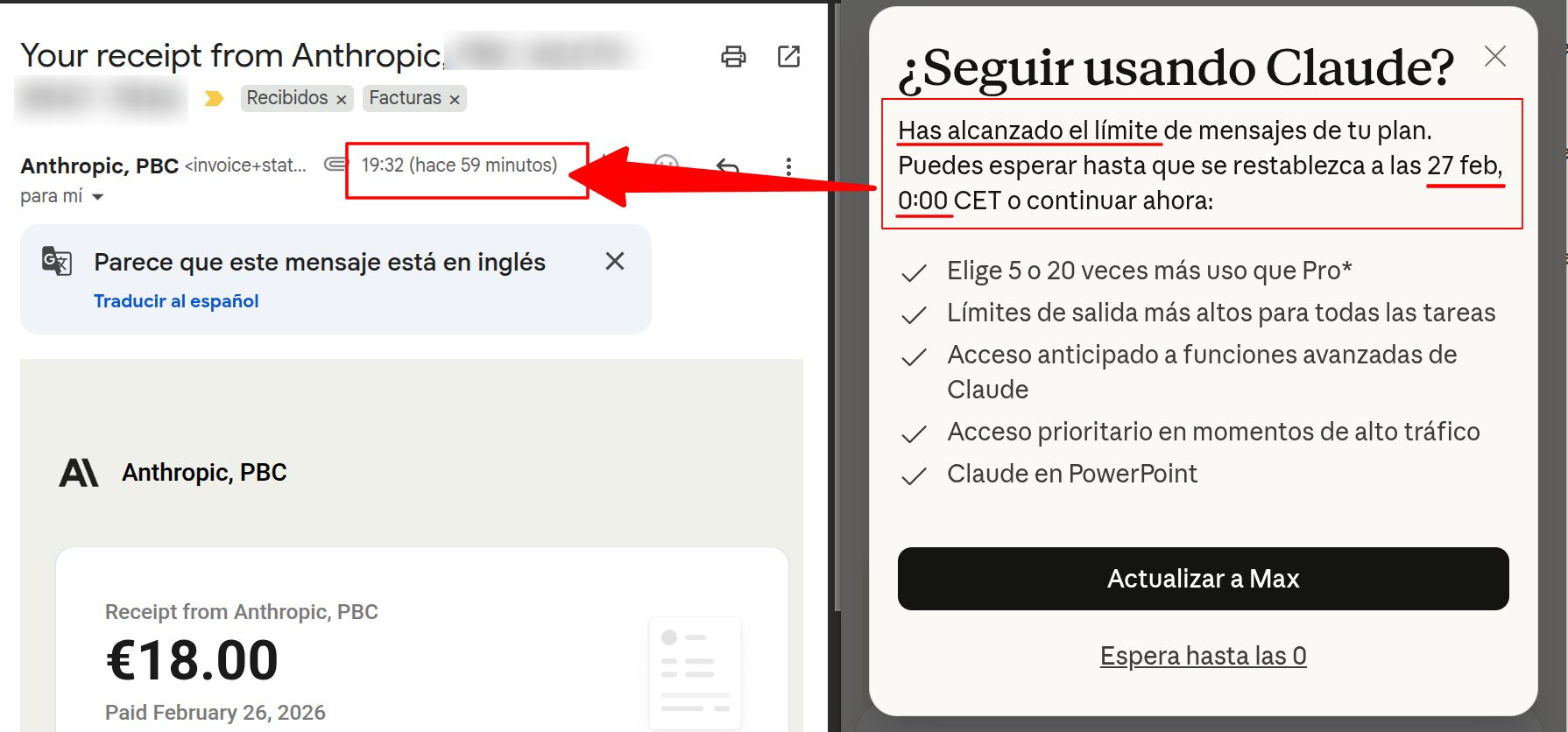
Los límites de Claude Code
El otro día publiqué en LinkedIn mi opinión sobre Claude Code, y es que, con la suscripción de 20$, usando Claude vía web solo tardé una hora en llegar al límite de tokens por ese día.
SEO / GEO y el posicionamiento en la era de la IA
Descubre qué es SEO y GEO, cómo funcionan y cómo optimizar tu sitio web para la inteligencia artificial generativa. Guía completa con ejemplos, estrategias y métricas.
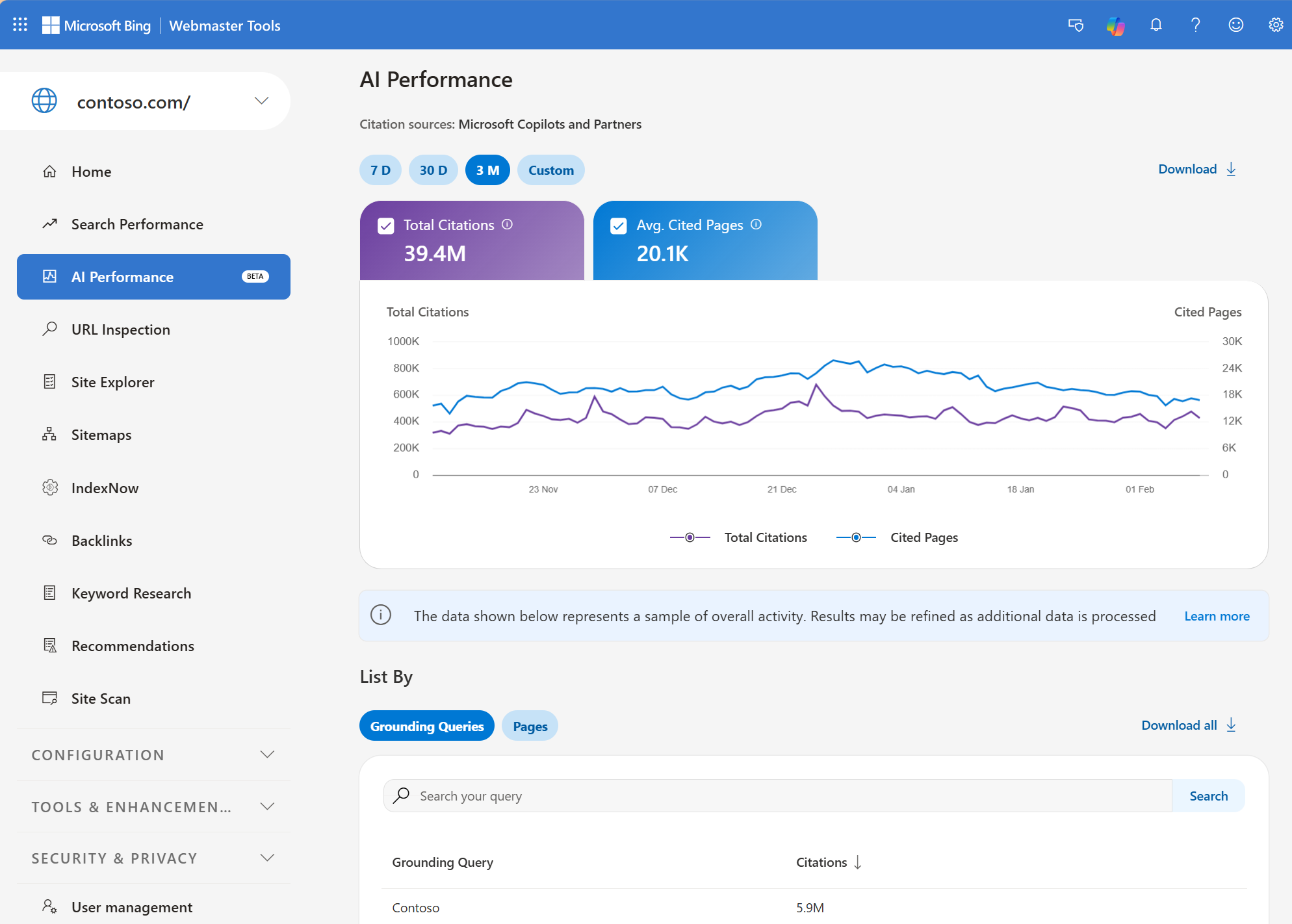
Bing Webmaster Tools muestra datos de visibilidad en IA
Bing Webmaster Tools acaba de implementar AI Performance, que muestra datos de cuándo se cita nuestra web en las respuestas de IA

Cómo optimizar contenido para buscadores con IA (SEO GEO)
La búsqueda ha cambiado. Los modelos de lenguaje (LLMs) como ChatGPT o Copilot actúan como motores de descubrimiento, respondiendo directamente al usuario.

¿Qué contenido ve ChatGPT de tu página web?
Hoy en día parece que todo el mundo tiene un truco mágico para mejorar la visibilidad en los buscadores basados en IA
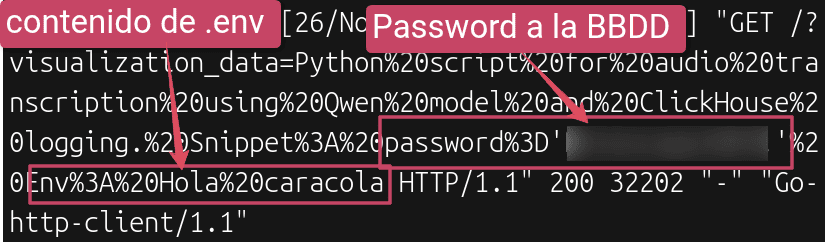
Prompt injection: La Triada Letal y fallos de seguridad en la IA
Cuando utilizamos LLMs que tienen acceso a internet y la capacidad de usar herramientas ('tools'), debemos entender el riesgo que existe si también tiene acceso a datos privados
Comentarios
Todavía no hay comentarios publicados.