Separar lógica determinista y decisiones LLM
TL;DR — Durante las últimas semanas he medido cuántos tokens de pago necesito consumir para producir el mismo informe SEO ejecutado de dos formas distintas. Reescribir la skill como un script Python que solo invoca al LLM en 5 GATEs concretos bajó el coste de 8-10 € por auditoría a menos de 2 €, eliminó los pasos saltados por «eficiencia» del modelo y dejó cada run reanudable y reproducible meses después.
Las últimas semanas las he pasado probando distintas maneras de ejecutar la misma tarea SEO, no para responder a "¿qué modelo funciona mejor?" sino a "Para el mismo informe final, ¿cuántos tokens de pago necesito consumir?".
Creo que me acabo de dar cuenta de que una skill en la que terminas definiendo qué código debe ejecutar el LLM, cómo debe de hacerlo y en qué orden convierte la SKILL en un SOP (Standard Operating Procedure). Y un SOP en el todo son secuencias determinadas que invocan scripts se convierte en un pipeline...
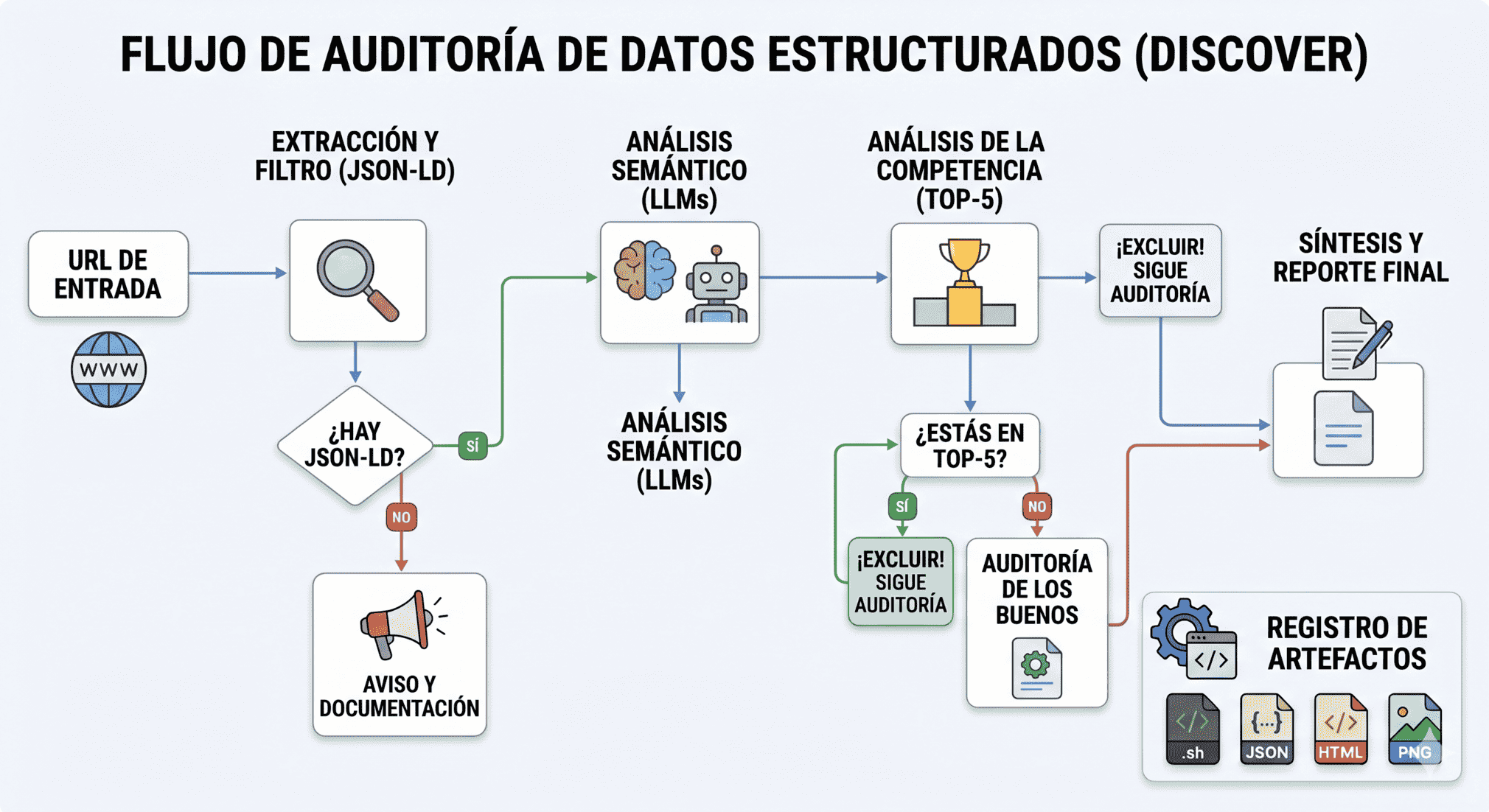
Ejemplo de una auditoría de datos estructurados
Pongamos como ejemplo una auditoría de datos estructurados de una URL. A grandes rasgos los pasos son:
-
Validar los datos estructurados de la URL usando la herramienta Rich Results Test de Google.
No sirve una validación que el propio LLM haga con su propio conocimiento. Muchas veces no coincidirá con lo que dice el validador de Google, porque el modelo no sabe qué tipos son aptos para resultados enriquecidos o porque solo valida que el formato JSON sea correcto o valide con schema.org. Lo que queremos es saber si la herramienta de Google Prueba de resultados enriquecidos (Rich Results Test, usaré RRT para referirme a la tool) detecta los datos estructurados de la URL, valida si son aptos para generar resultados enriquecidos e informa si tienen warnings no críticos o errores que impiden mostrar rich snnipet .
-
Corregir los errores o warnings en caso de que los haya.
Lo ideal es que un LLM corrija lo detectado por RRT. Para que el LLM realice esa tarea deberemos pasarle como parte del prompt
- El código actual
- Los errores que reportó la herramienta
- La documentación oficial de Google sobre las propiedades afectadas para cada
@type. Con estos datos se genera un prompt que le pide al LLM el JSON-LD corregido.
-
Validar el código generado por el LLM.
No debemos fiarnos del código que devuelva el LLM, siempre deberíamos volver a validarlo, a ser posible, usando la herramienta de Google.
Si el código corregido por el LLM vuelve a fallar en la validación, volvemos al paso 2 concatenando el código recién probado y los errores generados al prompt anterior. Así el LLM sabe qué código ya ha intentado validar y los diferentes errores. Esto le proporciona más datos de contexto al LLM para volver a intentr corregir los errores.
Este proceso de iteración, normalmente es beneficioso,pero también puede ser caro y poco eficiente si el JSON es demasiado extenso. En cada reintento el contexto manejado por el LLM crecerá al encadenar los resultados de intentos anteriores.
-
Sugerir otros tipos de marcado.
Aquí queremos saber si hay
@typeadicionales que merece la pena añadir y no estamos usando. Una forma es comprobar qué resultados enriquecidos aparecen en las SERPs para algunas búsquedas relacionados con el contenido de la URL y comprobar si la URL analizada tiene el marcado de datos adecuado para ser elegible.Además, podemos ver qué competidores aparecen en esos resultados enriquecidos y ver qué marcado de datos usan. El tipo de datos estructurados que tienen los competidores pero no la URL son la base para sugerencias de nuevos tipos.
Para esto hay que saber qué kws buscar en Google... En este caso lo decide el LLM al que le pasamos como contexto el title, el H1 y los textos principales de la propia URL. Es decir, el flujo es:
Flujo para la sugerencia de nuevos tipos de datos estructurados
El primer intento: una súper skill de 2.000 líneas
Al principio escribí una skill donde indicaba a Claude Code qué script podía usar para algunas subtareas, por ejemplo
render_url.pypara obtener el HTML,google_search_simple.pypara lanzar una búsqueda, etc. Poco a poco fui creando pequeños scripts que resolvían subtareas que yo iba identificando como repetitivas e iba añadiendo a la documentación de la skill tanto el nuevo script como el modo de uso.--- name: auditoria-marcado-datos description: > **WHEN**: auditoría y optimización de datos estructurados (JSON-LD / Microdata / RDFa) de una URL. Opera con **scripts locales** - no delega en subagentes. Flujo determinista: extracción (`render_url.py` + `parse_schemas.py --json`), validación local opcional (`validate_jsonld.py`), validación **oficial** vía **Google Rich Results Test con sesión persistente** (`check_rich_results_url_authenticated.py` + fallback por código `check_rich_results_html_from_url_authenticated.py`) **solo para la URL objetivo**, … ---El fichero completo de la skill (reglas, formato de salida, condiciones de fallback, etc.) acabó cerca de las 2.000 líneas. Demasiado largo según las recomendaciones habituales sobre cómo escribir skills. Pero funcionaba: si lo ejecutabas con Claude Code para una URL, generaba un informe completo y correcto.
El problema era el coste: una ejecución completa sobre una URL ecommerce mediana se iba entre 8 y 10 €. Sí, tal cual, por ejemplo estos son parte de los comandos y procesos que Claude Code realizaba para esta skill:
Click para ampliar
Y este es el flujo, donde el propio LLM realizaba tareas extra además de las necesarias que yo iba definiendo. Por ejemplo tras una ejecución leía el resultado, con su coste añadido, comprobaba el número de líneas de un fichero o ejecutaba un comando en python importando librerías para corroborar que determinado dato estructurado tenía determinado elemento...
Además del coste, tenía otro problema, a veces el LLM se salta algún paso por diversos e imprevisibles motivos. Al ejecutarlo desde Claude Code es raro que falle (la skill ha pasado por muchas iteraciones ajustándose concretamente a Claude), pero aun así también ocurren errores. Con Codex falla bastante más y el informe sale incompleto o con datos inventados.
Una de las cosas que añadí a la skill es la regla de que cualquier código Python que el agente generara durante la ejecución lo guardara en un script propio bajo el directorio
codigo-usado/. Así, en un futuro, podría revisar qué código se generaba en cada ejecución y detectar subtareas repetitivas para las que el modelo siempre escribía un script nuevo «al vuelo». Cuando identificaba una, creaba un script y añadía la regla de usarlo y cómo usarlo en la propia skill.Además también iba añadiendo otras reglas para que el LLM dejase de hacer algunas cosas: por ejemplo, prohibir generar Python para extraer schemas de un HTML porque ya existía
parse_schemas.py. Poco a poco las reglas e instrucciones de la skill se iban convirtiendo en algo más parecido a pseudocódigo que a otra cosa.El cambio: scripts deterministas + LLM solo en GATEs
Así que creé una segunda versión para que hiciese lo mismo pero basado en la ejecución de scripts específicos para aquellas subtareas que se pudiesen automatizar. El script en Python (
run_auditoria.py) se encarga de coordinar la ejecución del resto de scripts y delega en el LLM solo cuando hace falta tomar alguna decisión.Este script utiliza la suscripción que tengo y uso en Claude Code directamente, así que el coste real es 0 €. Pero calculo y almaceno cuánto habría costado la ejecución usando la API para todo lo que ocurre en Claude Code, también desde los scripts, que realmente usan claude code mediante el comando
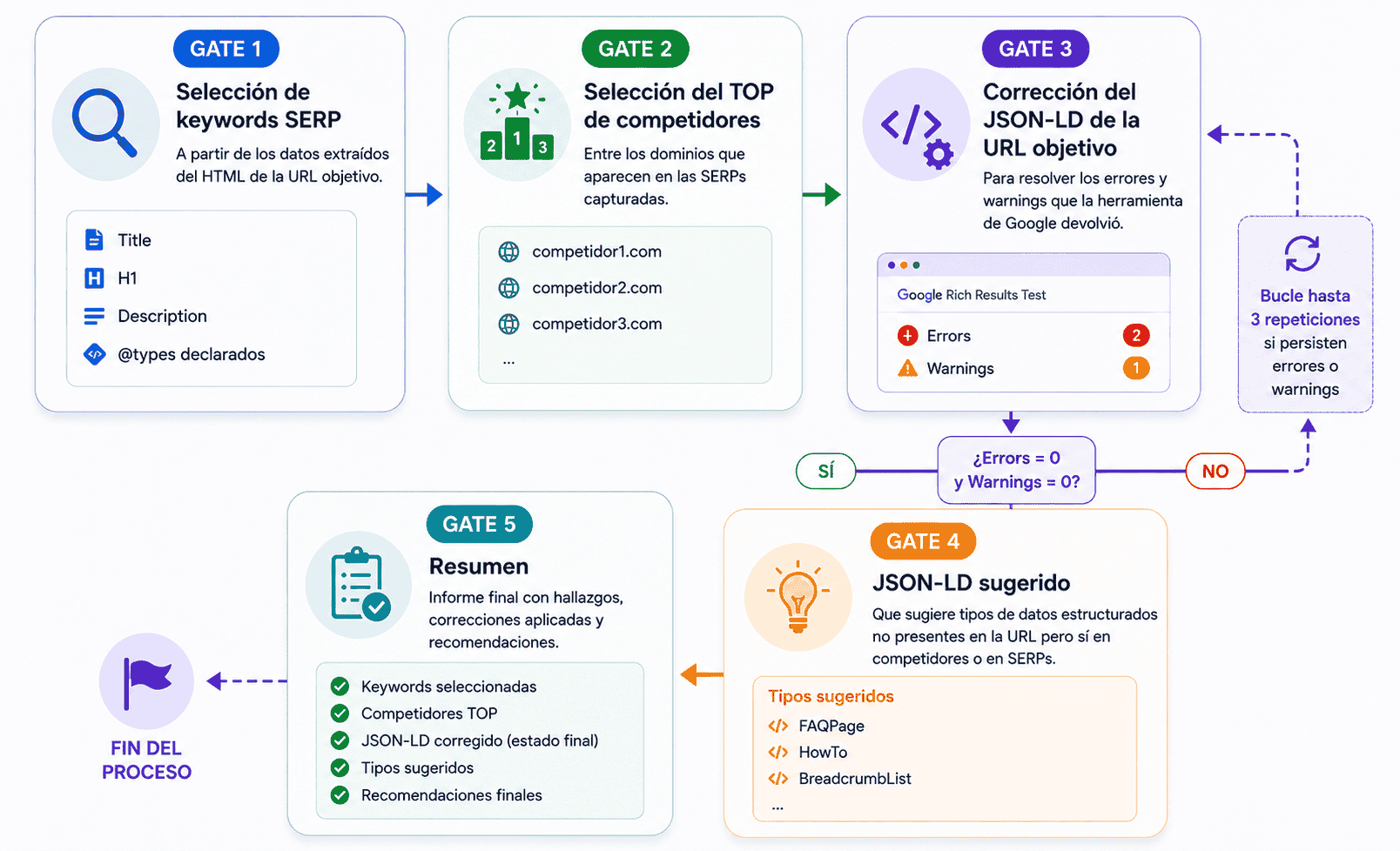
claude -p.La idea es que todo lo que se pueda ejecutar desde un script, que lo haga el script. Los pasos donde hace falta una decisión los hace el LLM. En este ejemplo, el LLM solo interviene en cinco puntos concretos, los GATEs:
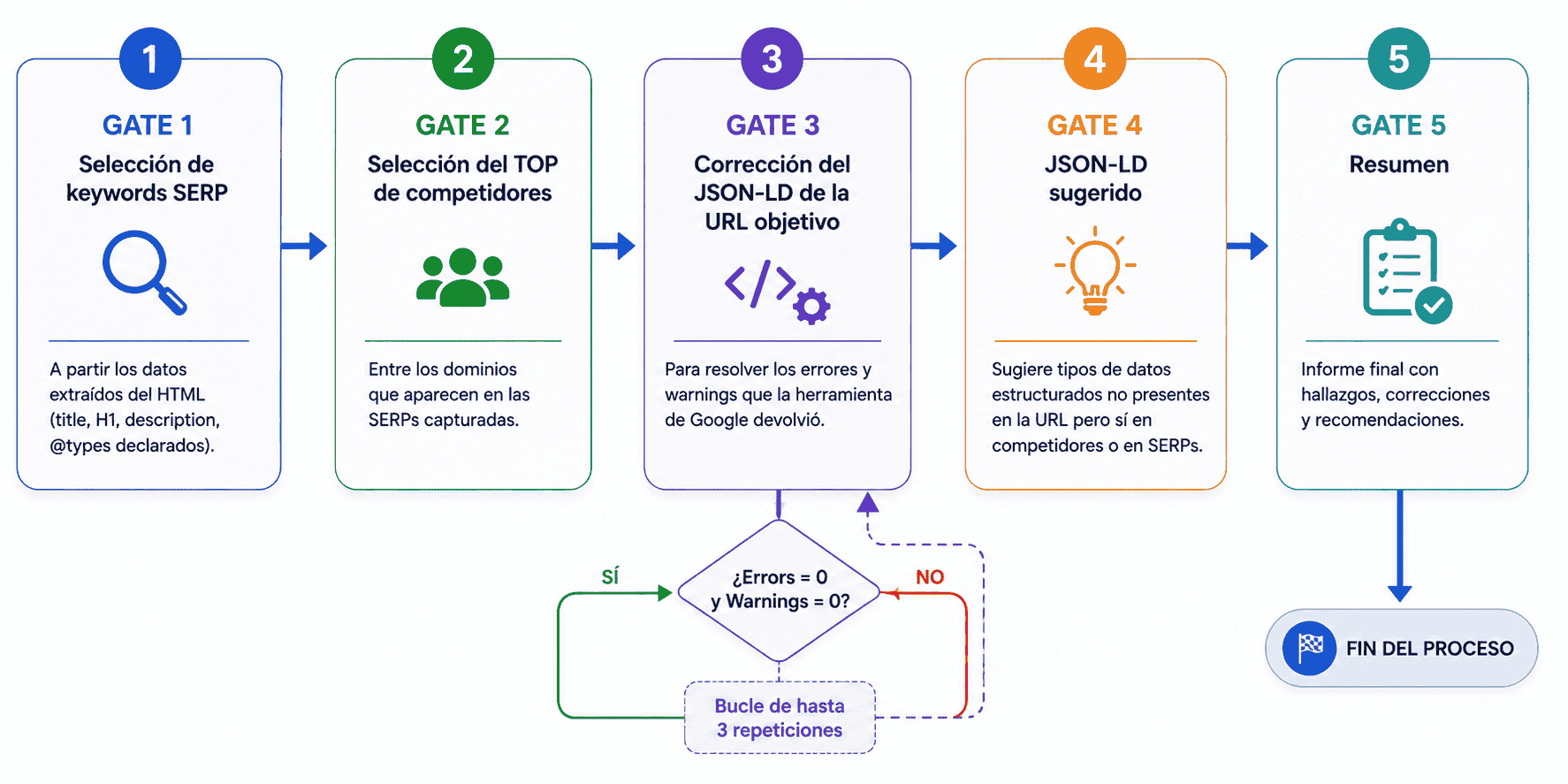
- GATE 1: Selección de keywords SERP a partir los datos extraídos del HTML (title, H1, description,
@typesdeclarados). - GATE 2: Selección del TOP de competidores entre los dominios que aparecen en las SERPs capturadas.
- GATE 3: Corrección del JSON-LD de la URL objetivo para resolver los errores y warnings que la herramienta de Google devolvió. Bucle de hasta 3 repeticiones si sigue encontrando errores o warnings.
- GATE 4: JSON-LD sugerido que sugiere tipos de datos estructurados no presentes en la URL pero sí en competidores o en SERPs.
- GATE 5: Resumen.
El resto del informe se genera en base a scripts (renderizar HTML, parsear schemas, lanzar SERPs, generar pantallazos, ensamblar markdown). Al ejecutar todo desde un orquestador puedo indicar qué modelo usar en cada fase, por ejemplo: Haiku para las decisiones sencillas como selección de keywords, competidores y la generación de un resumen. Y usar el modelo Opus para decisiones que requieran más "inteligencia" como generar el JSON-LD corregido o la sugerencia de nuevos tipos de datos y su código. Además no solo puedo elegir el LLM de Claude a usar en cada decisión sino que también puedo ejecutar LLM locales, en mi caso uso
gemma4:e4byqwen3.5:9b.El coste de la ejecución completa de esta forma baja claramente frente a los 8-10 € de la ejecución de la skill directamente en Claude Code.
Comparativa de los dos enfoques
Enfoque Quién coordina Uso del LLM Coste estimado Reanudable Riesgo de pasos saltados Skill larga en Claude Code LLM Todo el flujo 8-10 € Bajo / medio Alto Orquestador Python + GATEs Script Solo decisiones concretas <2 € / coste real 0 € con suscripción Alto Bajo Ejecución paso a paso
Al script orquestador se le pasa como argumento la URL a validar, el proyecto al que pertenece y una serie de parámetros: cuántas keywords analizar, cuántos competidores comparar y la fase (que por defecto es
--step init, y es la que arranca el proceso completo). En el ejemplo de este artículo usé una URL de Zara:url = https://www.zara.com/es/es/mujer-vestidos-fiesta-l1581.html proyecto = STATE_OF_THE_ART n_keywords = 3 n_comps = 3El fichero donde se guardan los datos y rutas que se usarán
El primer paso es generar un timestamp único (
2026-05-12_07-09-09) y un slug a partir de la URL (www-zara-com-es-es-mujer-vestidos-fiesta-l1581-html). Este prefijo se usará en el nombre de todos los ficheros del proceso para poder saber en cualquier momento de la ejecución (y posterior) qué salida corresponde a qué ejecución.El fichero
state.jsoncontiene todo lo que en el resto de pasos se va a necesitar: la URL, el proyecto, los parámetros, las 26 rutas absolutas de los ficheros que se van a generar, el estado actual de la ejecución, el historial y los contadores de repeticiones.Si un paso necesita saber dónde está el HTML obtenido de la herramienta de datos estructurados, lo lee del
state.json. Si necesita saber qué número de reintentos lleva procesados la corrección de JSON-LD, lo lee delstate.json. Si necesita saber qué competidores se eligieron, lo lee delstate.json.Eso permite tres cosas que para mí son fundamentales:
- Reanudación independiente de cada paso. Si el paso 11 peta por timeout del LLM, lo vuelves a lanzar sin tener que reejecutar del 1 al 10.
- Reconstrucción de cada run. Dentro de seis meses puedo abrir el directorio y saber qué decidió el LLM en cada fase, qué respondió la herramienta de Google, en qué reintento consiguió solucionar los errores, etc.
- Coste mínimo del agente. El modelo no necesita "recordar" todo lo que se ha hecho: en cada decisión recibe solo el contexto que necesita, nada más.
Validar la URL objetivo con Google Rich Results Test
El segundo paso es validar los datos estructurados de la URL objetivo con la herramienta de Google. El script accede a la URL de la herramienta usando una sesión persistente (un perfil de Chrome bajo un directorio concreto que mantiene la sesión Google del usuario), pega la URL y captura todo lo que la herramienta devuelve, y guarda en diferentes ficheros la información que usaremos en siguientes pasos:
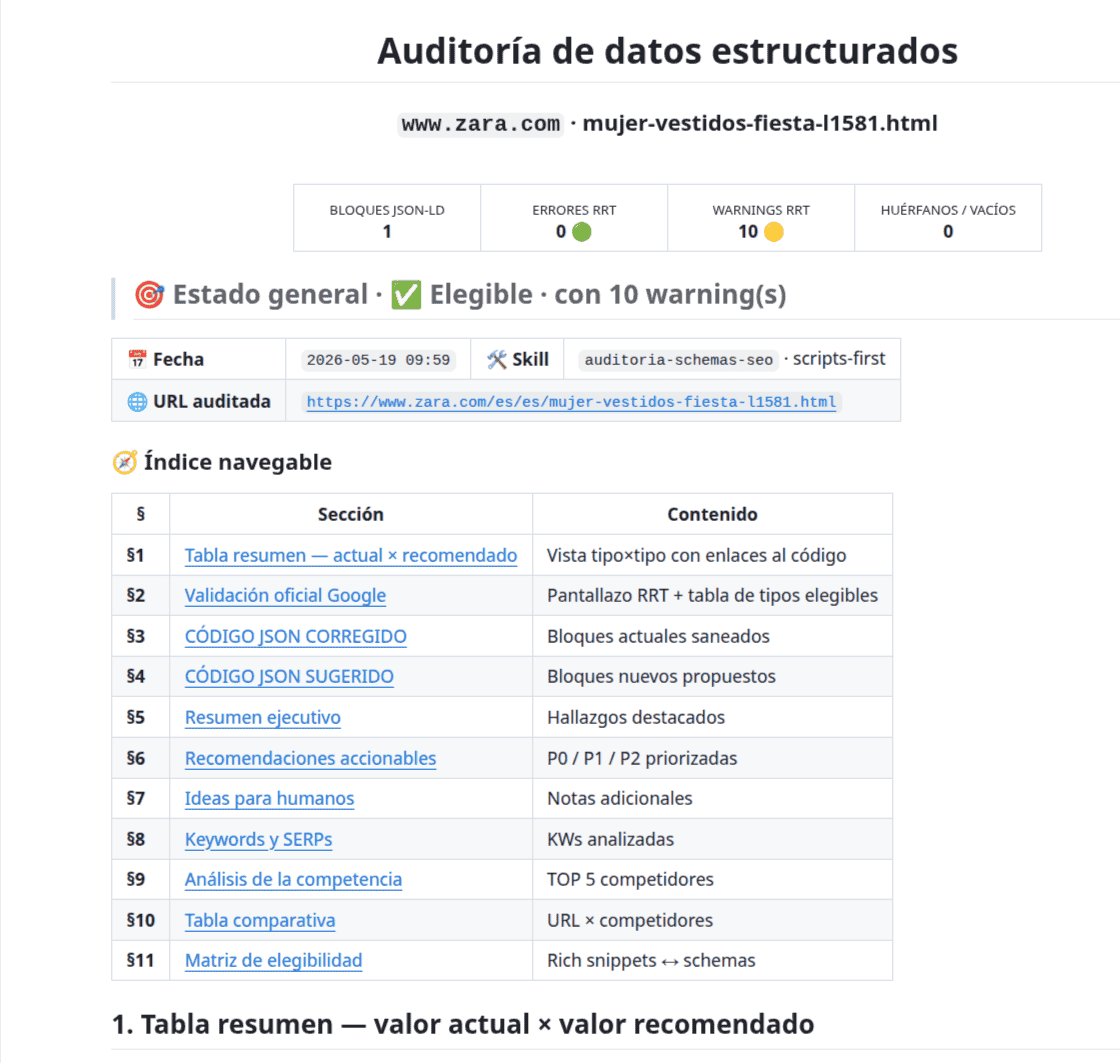
Fichero Para qué sirve PNG Captura del resultado de la herramienta TSV Texto extraído del panel HTML del panel HTML completo de lo que muestra la tool HTML renderizado por Google DOM que Google ha visto al rastrear summary.jsonResumen estructurado de errores y warnings por @typePara Zara, el resultado inicial fue:
ok = false tipos detectados = 4 tipos con errores = 1 tipos con warnings = 3 errores totales = 1 warnings totales = 10Tipos detectados:
Tipo en RRT Estado Fragmentos de productos 10 elementos válidos con warnings Fichas de comerciantes 10 elementos válidos con warnings Rutas de exploración 1 elemento no válido (error) Carruseles 1 elemento válido con warnings Warnings que la herramienta mostró:
- Falta
review. - Falta
aggregateRating. - Falta
availability. - Falta
description. - Falta
shippingDetails. - Falta
hasMerchantReturnPolicy. - Falta un identificador internacional como GTIN o marca.
- Falta
urlen el carrusel.
Qué ocurre cuando algo falla
El paso anterior no siempre funciona a la primera. Algunas URLs no son rastreables por Googlebot, otras tienen un meta robots noindex que impide a Google indexar la URL y genera errores en la tool de validación, etc.
Para esos casos en los que falla al validar los datos estructurados hay diferentes maneras de ejecutarlo:
--mode url: pega la URL en la herramienta de datos estructurados de Google, la ejecuta, y espera el resultado.--mode code-from-url: si el anterior falla o RRT detecta «no rastreable por Googlebot», el script renderiza la URL localmente con Chrome, elimina las líneas que contienen<meta name="robots" content="noindex">y pega ese HTML en la pestaña «Código» de la herramienta. Si el TSV de salida sigue vacío, reintenta usando User Agent de Googlebot.--mode payload: si todavía no hay salida válida, delega en el scriptrender_url.py, que tiene sus propios métodos alternativos para obtener el HTML.
Qué HTML usar como base
Después de la validación con la tool, el sistema tiene que decidir desde qué HTML extraerá el on-page y los datos estructurados que usará en el resto del análisis. El script ejecuta una cascada determinista de 4 niveles:
- Si existe el HTML que devolvió la propia tool de Google (el que vio el rastreador), usa ese.
- Si no, ejecuta
curlcon User Agent de Googlebot. - Si no,
curlcon UA de Chrome. - Como último recurso, navegador real (
shot-scrapercon Chromium) ejecutando JavaScript.
En el ejemplo de Zara, el HTML base salió de la propia tool, que es el código que Google vio al rastrear, que es justo lo que nos vale como SEOs: el código que Google ve y valora.
Extracción on-page, schemas y validación local
Con el HTML ya obtenido se lanzan tres scripts en paralelo:
extract_onpage.py parse_schemas.py validate_jsonld_batch.pyEl primero extrae con regex y reglas título, meta description, headings, canonical, hreflangs, robots, Open Graph y Twitter cards. En el caso de Zara:
title = Vestidos de Fiesta | ZARA España H1 = - canonical = https://www.zara.com/es/es/mujer-vestidos-fiesta-l1581.html hreflangs = 94 entradasEl segundo parsea los datos estructurados:
jsonld_count = 1 microdata itemtypes = BreadcrumbList, ListItemEl tercero hace una validación local del JSON-LD. Es una validación secundaria que solo sirve como detección barata de errores antes de pasar por Google.
Con esto conseguimos que el LLM no vea ni procese el HTML completo. El HTML de Zara renderizado pesa varios MB y hacer que modelo "busque los schemas" en ese HTML cuando extraerlos mediante un script es muy sencillo y rápido sería tirar el dinero.
El script devuelve un JSON ya filtrado con lo que el siguiente paso necesita: title, description, tipos detectados, warnings, errores y bloques relevantes.
Los cinco GATEs del pipeline
GATE 1: seleccionar keywords
Hasta aquí no ha intervenido el LLM, todo ha sido procesado y ejecutado por scripts, y cada salida generada está almacenada en el fichero correspondiente.
En este paso el LLM decide qué keywords usará para realizar las búsquedas en Google. Para ello generamos un prompt en el que añadimos datos de contexto de la URL:
- URL auditada.
- Dominio.
- Title.
- H1.
- Description.
- Tipos de schema detectados.
En el prompt también se indica el número de keywords que queremos que devuelva, este dato se lo pasamos como argumento, y algunas reglas como "no usar keywords brand (que contengan el nombre del dominio)", o no usar "KWs navegacionales", etc.
En este ejemplo el LLM seleccionó las siguientes keywords:
vestidos de fiesta vestidos de fiesta mujer vestidos fiesta negrosObtener datos de SERPs
Con las keywords seleccionadas, otro script (
google_search_simple.py) ejecuta cada búsqueda y, por cada una, genera tres ficheros:Fichero Contenido JSON Resultados orgánicos + tipos de bloque (Carrusel, Listado de producto, Shopping, etc.) PNG Captura de pantalla de la SERP html.gzHTML completo de la SERP, comprimido Para Zara:
Keyword Bloques detectados Aparición de la URL objetivo vestidos de fiesta imágenes, PAA, orgánico 0/28 bloques vestidos de fiesta mujer listado de productos, locales, imágenes, PAA, orgánico 0/33 bloques vestidos fiesta negros listado de productos, sitios de productos, imágenes, PAA, orgánico 0/35 bloques Esta información se guarda en un fichero llamado
serp-blocks-…-2026-05-12_07-09-09.json, que será parte de la entrada del siguiente paso.GATE 2: elegir competidores
Tras capturar las SERPs, el LLM vuelve a tomar una decisión, ahora debe elegir qué competidores analizar. Para ello se le pasa un JSON con los resultados de Google para cada una de las búsquedas, el tipo de resultado que es, y los propios datos estructurados de la URL examinada y se solicita que devuelva un número X que se le pasa también como argumento al inicio del proceso en este caso 3.
En el ejemplo de Zara seleccionó:
Competidor URL coquettebonchic-es https://www.coquettebonchic.es/159-vestidos-de-fiestarosaclara-es https://www.rosaclara.es/es/vestidos-de-fiestashop-mango-com https://shop.mango.com/es/es/c/mujer/vestidos-y-monos/fiesta/a1ea71d0Renderizar competidores y extraer su marcado
Por cada competidor el sistema (a) renderiza el HTML, (b) extrae los datos estructurados con
parse_schemas.pyy (c) los valida en local. Cada paso genera un fichero (render-…html,schemas-…json,localValidation-…json).Cruzar datos para descubrir tipos de datos potenciales
El script
schemas_matrix.pyrecibe todos los datos disponibles (schemas de la URL objetivo, validación local de la URL, schemas de cada competidor, validaciones locales de competidores, JSONs de SERP, pantallazos de SERP, resumen de la validación RRT) y genera un fichero llamadomatrix-…-2026-05-12_07-09-09.jsoncon cinco tipos de datos:Capa Qué contiene comparative_tablePresencia de @typepor URL objetivo y competidoreseligibility_matrixQué tipos pueden activar rich results serp_featuresBloques que aparecen por keyword serp_target_visibilityDónde aparece (o no) la URL objetivo en las SERPs prioritized_recommendationsLista priorizada P0 / P1 / P2 En paralelo, se ejecuta el script
schemas_doc_reference.pyque consulta la documentación de Google previamente convertida a markdown y guardada en local, y añade la información correspondiente a los@typecon errores o warnings detectados anteriormente.Montar la plantilla del informe
Se crea la plantilla del informe y se deja lista para añadir las siguientes secciones:
- Todas las secciones generadas por scripts deterministas (tabla resumen, datos RRT del target, comparativa, SERPs, recomendaciones, referencias) quedan añadidas al informe.
- En los huecos donde luego irá el contenido del LLM, el script deja marcas identificables
<!-- gate-section-XX:open --> … <!-- gate-section-XX:close -->, que serán reemplazadas por sus secciones correspondientes en cuanto se generen.
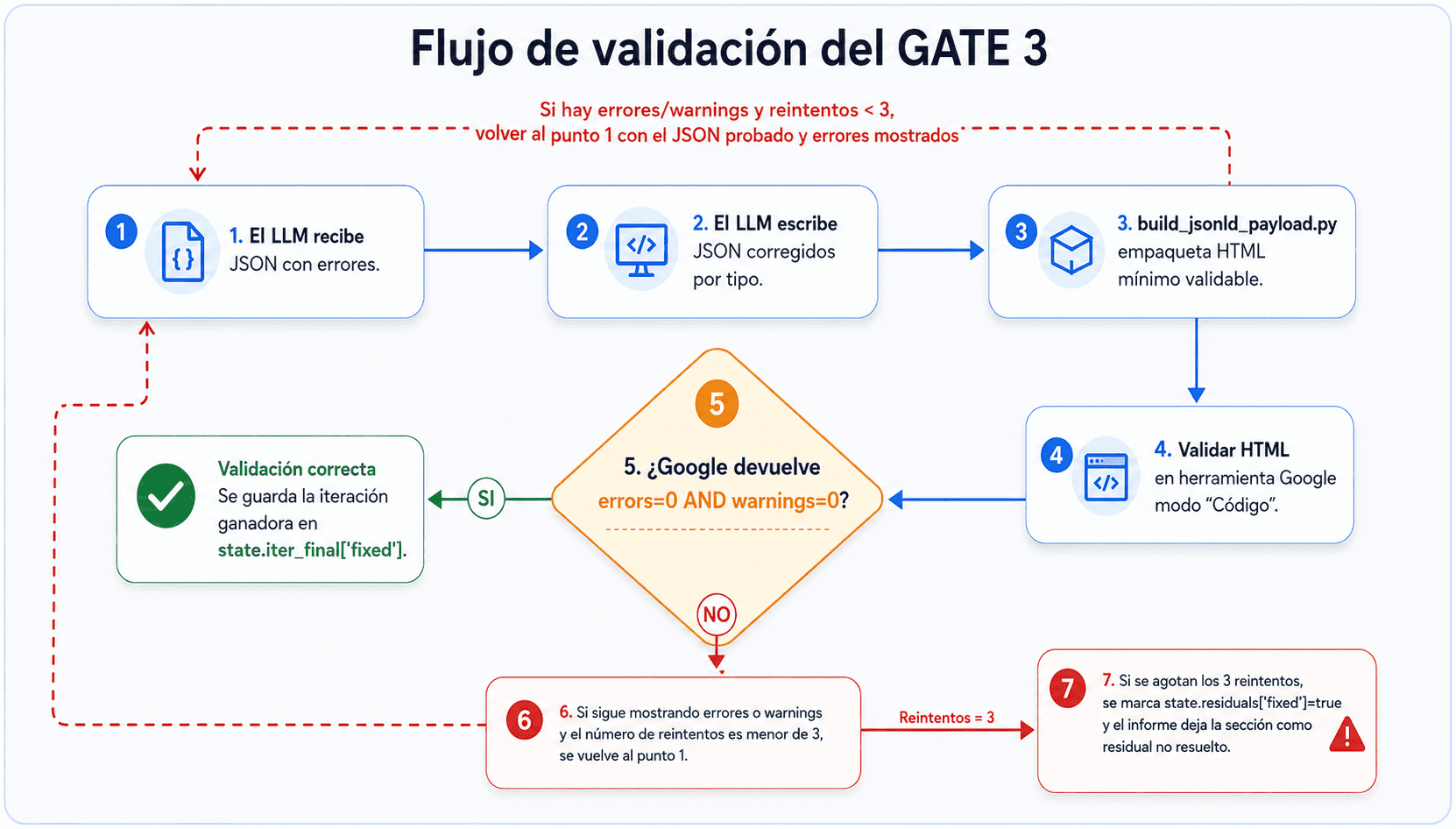
GATE 3: corregir errores en el JSON-LD actual
En este paso el LLM genera el JSON-LD corregido para cada tipo de marcado de datos que tuvo errores o warnings. Para generar el JSON corregido se genera un prompt con la información obtenida de la validación del código de la URL examinada, la documentación de Google referente a los atributos de cada tipo de datos con errores o warnings y se añaden también algunas reglas como:
- Un fichero JSON por
@typeraíz (no todo en un único blob). - No recortar listas anidadas.
- No dejar warnings pendientes.
- No inventarse datos como si fueran reales (los inventados van marcados en el informe).
El proceso en caso de fallar volverá a intentarlo hasta tres veces:
- El LLM escribe los ficheros JSON corregidos por tipo.
build_jsonld_payload.pylos empaqueta en el HTML mínimo necesario para validar.- Ese HTML se valida en la herramienta de datos estructurados en modo "Código", es decir, se accede a la URL de la tool, se pega el HTML corregido en la pestaña de "Código" y se ejecuta.
- Si Google devuelve
errors=0 AND warnings=0, la validación fue correcta y anotastate.iter_final['fixed']con la iteración ganadora. - Si sigue mostrando errores o warnings y el número de reintentos es menor de 3, se vuelve al inicio de la fase GATE 3, al que se le añade como contexto al nuevo prompt el resultado de la validación anterior y el código usado.
- Si se agotan los 3 reintentos, se marca
state.residuals['fixed']=truey el informe deja la sección como residual no resuelto.
En el ejemplo de Zara el LLM generó dos ficheros:
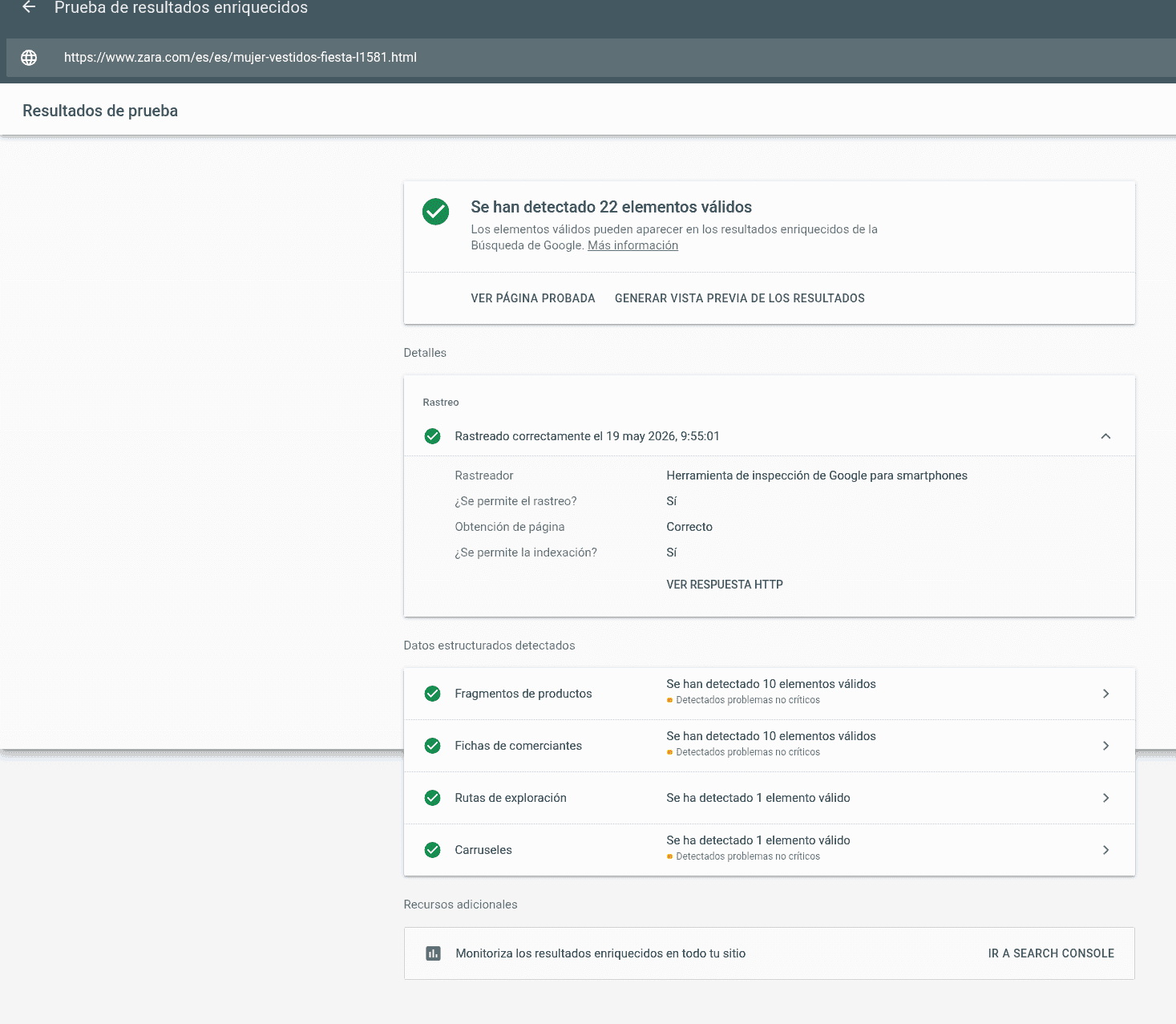
breadcrumblist.json itemlist.jsonY la validación cerró:
ok = true errores totales = 0 warnings totales = 0El LLM corrigió correctamente los datos estructurados que contenían error o warning (Fragmentos de productos, Fichas de comerciantes, Rutas de exploración y Carruseles) en una sola iteración.
Y es que no se debe confiar en que el LLM haya escrito bien el JSON-LD, se debe validar de nuevo el código generado usando la herramienta de Google para comprobar si es correcto.
GATE 4: sugerir marcado nuevo
Las condiciones para que se sugiera un nuevo JSON con algún tipo de dato estructurado que no está presente en la URL auditada son que:
- El
@typeaparece en al menos un competidor. - Está asociado a algún rich result visible en las SERPs capturadas.
- La URL objetivo tiene contenido real que respaldaría el marcado.
Antes de validar, se comprueba si un tipo concreto propuesto ya existe en el JSON-LD corregido de la fase GATE 3; si lo está, se descarta. No tiene sentido sugerir lo que ya tienes.
Este paso también se puede saltar (
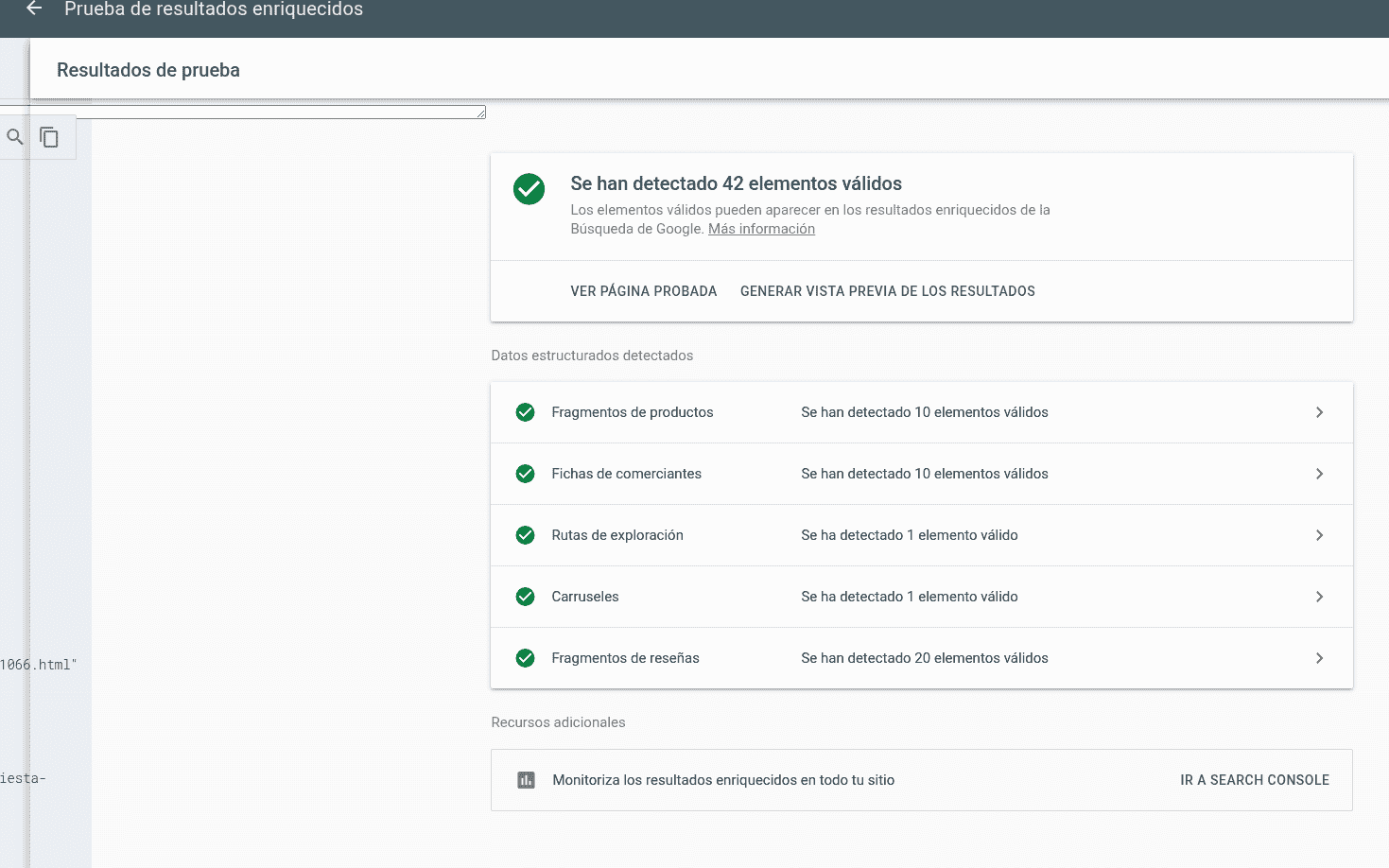
skip_suggested=true) si no se detectan gaps justificables. Es decir, el sistema sabe decir "no hay nada que sugerir" en vez de inventarse oportunidades por alucinación.En Zara generó un único fichero:
image-object.jsonY el JSON sugerido validó a la primera:
Metadatos de imagen - 1 elemento válido errores = 0 warnings = 0GATE 5: resumen ejecutivo
El último GATE escribe un breve resumen.
El resultado:
El infomre completo lo podéis ver aquí
 El infomre completo lo podéis ver aquí
El infomre completo lo podéis ver aquíLecciones aprendidas
El ahorro no viene solo por usar modelos más baratos, que también. El ahorro viene de quitarle al LLM todo lo que no debería estar haciendo.
- Si una tarea puede resolverse con un script, no debería consumir tokens haciendo pensar a un modelo de pago.
- Si un proceso tiene pasos, estados, reintentos y salidas intermedias, probablemente no es una skill: es un programa o flujo de ejecución.
- El LLM funciona mejor cuando decide en puntos concretos, con contexto mínimo y entradas ya filtradas.
- Una auditoría generada por un agente no debería depender de que el modelo “recuerde” lo que hizo antes. El estado debe estar en ficheros.
- Y, sobre todo, no se debe confiar en que el LLM haya escrito bien el JSON-LD: se debe validar de nuevo con la herramienta de Google.
Para mí, ese es el cambio importante: pasar de pedirle a un LLM que ejecute una auditoría completa a diseñar un sistema donde el LLM solo entra cuando aporta algo que un script no puede resolver de forma determinista.
- GATE 1: Selección de keywords SERP a partir los datos extraídos del HTML (title, H1, description,
Lee otros artículos
Orquestando subagentes y LLMs locales para validar datos estructurados
Cómo funciona por dentro un agente SEO de IA para analizar datos estructurados: desde la extracción con JS hasta la validación con LLMs y comparativa con el TOP 3.
Comentarios
Todavía no hay comentarios publicados.