Google podria no querer el HTML de una URL


"Y por último, y prometo que ya os dejo tranquilos, una reflexión en voz alta: a) el servidor sirve el fichero íntegramente, da igual el código de estado del mismo. Ojo con la compresión por Gzip que haga Apache en caso de que la tengas activada".
Por ejemplo podéis probar desde vuestro terminal (en Windows creo que también existe igual) a poner
- "curl -I https://www.mecagoenlos.com"
Para obtener solamente las cabeceras - "curl https://www.mecagoenlos.com"
Para obtener el código fuente (HTML)

- Petición de cabeceras a una URL correcta (200)
Peso:
:
164 bytes
Respuesta
HTTP/1.1 200 OK
Date: Tue, 10 Dec 2019 19:11:33 GMT
Server: Apache/2.4.18 (Ubuntu)
Cache-Control: max-age=0, no-cache
Content-Type: text/html; charset=utf-8
- Petición de cabeceras + HTML a una URL correcta (200)
Peso:
:
210 Kbytes
Respuesta
Todo el código HTML de la home de mi blog
- Petición de cabeceras a una URL con redirección 301
Peso:
:
258 bytes
Respuesta
HTTP/1.1 301 Moved Permanently
Date: Tue, 10 Dec 2019 19:10:29 GMT
Server: Apache/2.4.18 (Ubuntu)
Location: https://www.mecagoenlos.com/
Cache-Control: max-age=86400
Expires: Wed, 11 Dec 2019 19:10:29 GMT
Content-Type: text/html; charset=iso-8859-1
- Petición de cabeceras + HTML a una URL con redirección 301
Peso:
:
318 bytes
Respuesta
HTTP/1.1 301 Moved Permanently
Date: Tue, 10 Dec 2019 19:10:29 GMT
Server: Apache/2.4.18 (Ubuntu)
Location: https://www.mecagoenlos.com/
Cache-Control: max-age=86400
Expires: Wed, 11 Dec 2019 19:10:29 GMT
Content-Type: text/html; charset=iso-8859-1
- Petición de cabeceras a una URL de error 404
Peso:
:
140 bytes
Respuesta
HTTP/1.1 404 Not Found
Date: Tue, 10 Dec 2019 19:12:40 GMT
Server: Apache/2.4.18 (Ubuntu)
Content-Type: text/html; charset=iso-8859-1
- Petición de cabeceras + HTML a una URL de error 404
Peso:
:
282 bytes
Respuesta
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>404 Not Found</title>
</head><body>
<h1>Not Found</h1>
<p>The requested URL was not found on this server.</p>
<hr>
<address>Apache/2.4.18 (Ubuntu) Server at www.mecagoenlos.com Port 443</address>
</body></html>

Comentarios
7Lee otros artículos
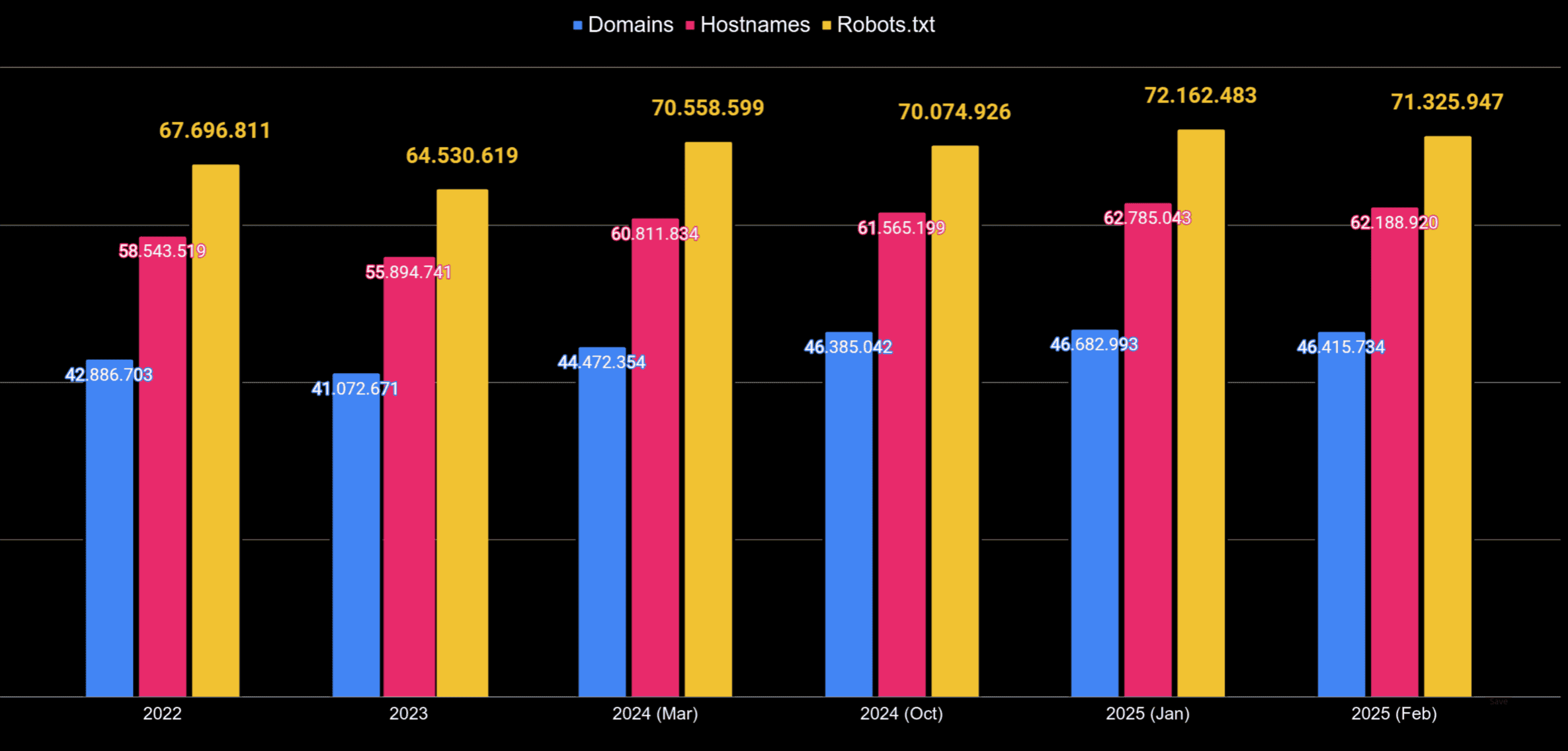
¿Se está impidiendo a los bots de Inteligencia Artificial acceder al contenido?
¿Cómo ha ido incrementando el número de robots.txt en los que aparecen rastreadores asociados a la Inteligencia Artificial?
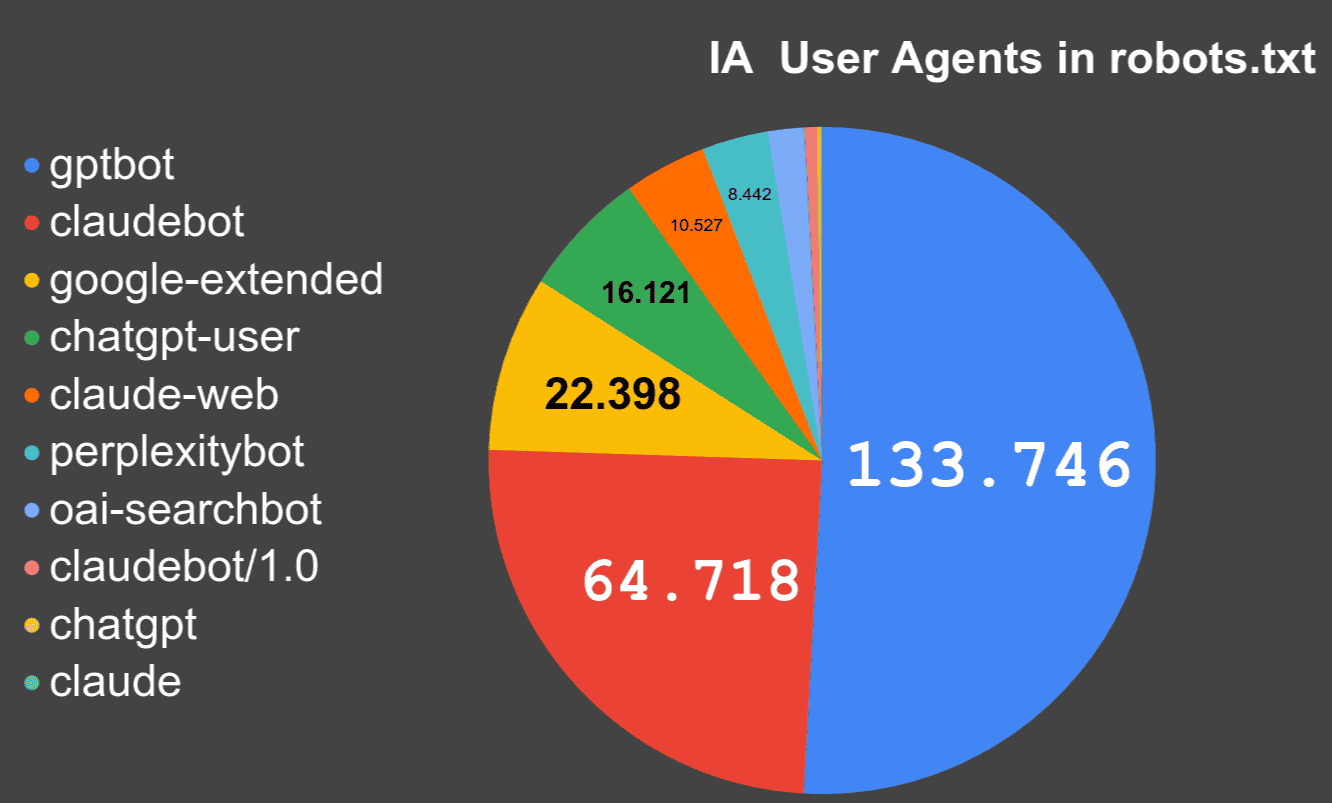
Analizando más de 72 millones de robots.txt
¿Cuántos dominios, subdominios y robots.txt estén bloqueando a los crawlers de Inteligencia Artificial?
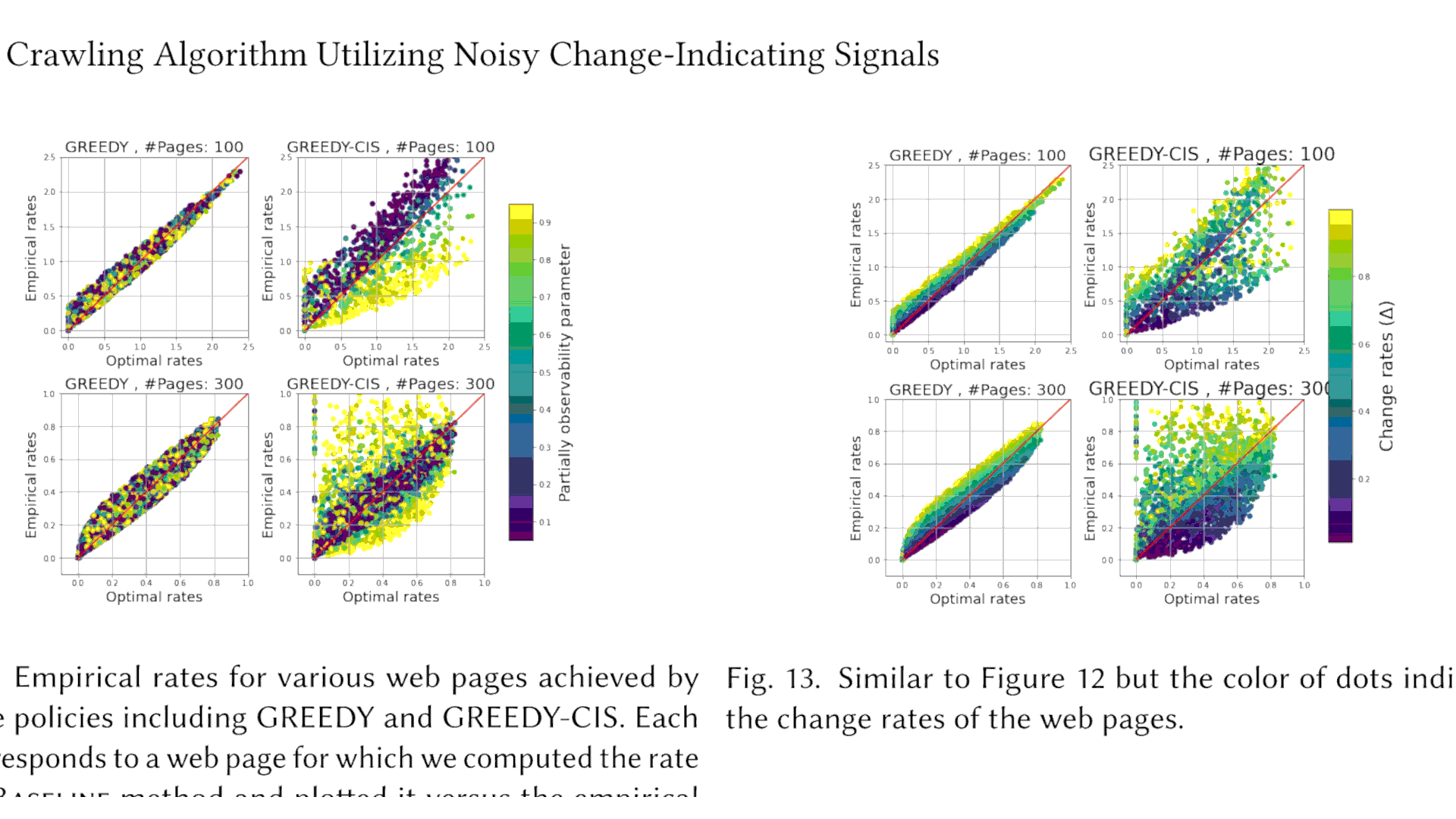
¿Cómo decide Google que URL debe rastrear?
Hoy he descubierto este paper de Google (A Scalable Crawling Algorithm Utilizing Noisy Change-Indicating Signals) dónde describe una mejora del método descrito en el artículo inicial
Búsqueda semántica de contenidos en los vídeos de Youtube
n la segunda parte mostré un caso de uso un poco más complejo para crear un buscador de contenidos dentro de los vídeos de Youtube. En este post voy a detallar la segunda parte, cómo podemos utilizar la línea de comandos + Bert + SQL para crear un buscador de contenidos dentro de los vídeos.
Intentando comprender Googlebot y los 301
Publicado por Lino Uruñuela el 22 de marzo del 2017 El otro día hubo un debate sobre qué método usará Google a la hora de interpretar, seguir y valorar las redirecciones 301. Las dudas que me surgieron fueron ¿Cómo se comportan los crawlers? Normalmente cuando lanzamos un crawler como Secreaming Frog lo que hace es Ac…
Crawl Budget, qué es y cómo afecta a tu site según Google
Publicado por Lino Uruñuela el 16 de enero del 2017 en Donostia Desde hace ya mucho tiempo llevo analizando, probando y optimizando el Crawl Budget o Presupuesto de Rastreo. Ya en los primeros análisis vi que esto era algo relevante para el SEO, que si bien no afecta directamente a los rankings de una KW determinada,…
El valor de los logs para el SEO
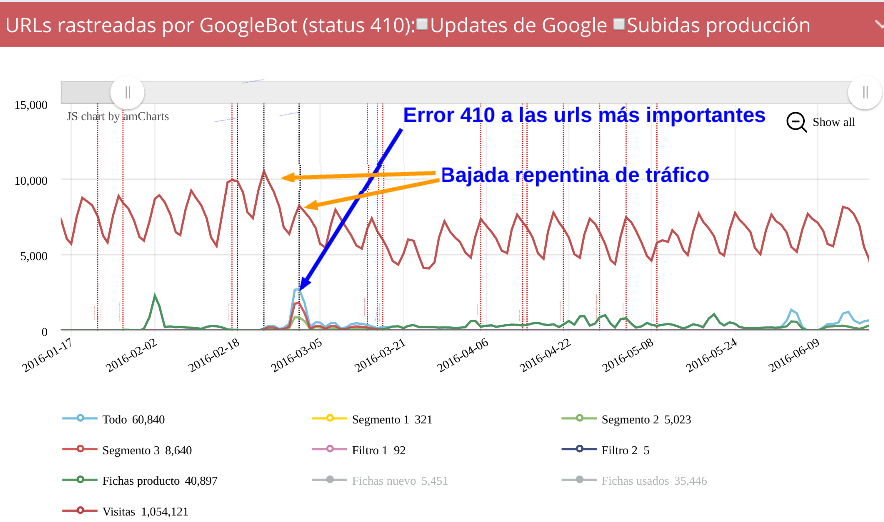
Publicado el martes 6 de septiembre del 2016 por Lino Uruñuela Hace poco escribí el primero de una serie de post sobre el uso de Logs, Big Data y gráficas, en este caso continúo el análisis de la bajada que comenzamos a ver en Seo y logs (primera parte): Monitorización de Googlebot mediante logs , una caída importante…
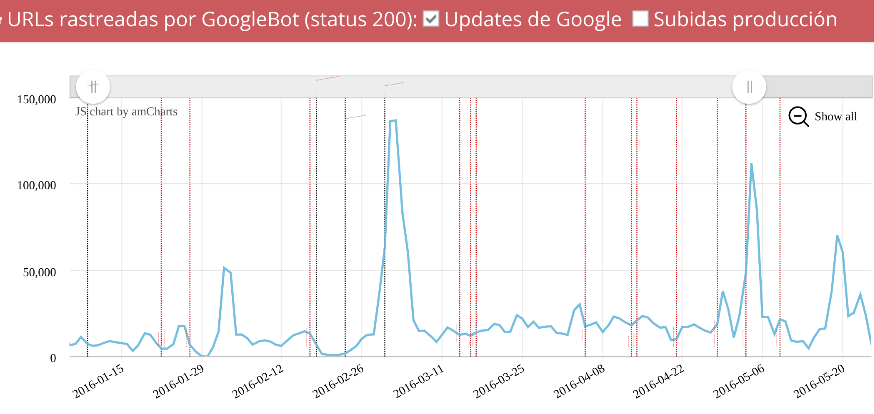
Seo y logs (primera parte): Monitorización de Googlebot mediante logs
Publicado por Lino Uruñuela el 27 de junio del 2016 Una de las ventajas de analizar los datos de los logs es que podemos hacer un seguimiento de lo que hace Google en nuestro site, pudiendo desglosar y ver independientemente el comportamiento sobre urls que dan error, o urls que hacen redirecciones, o urls que son cor…
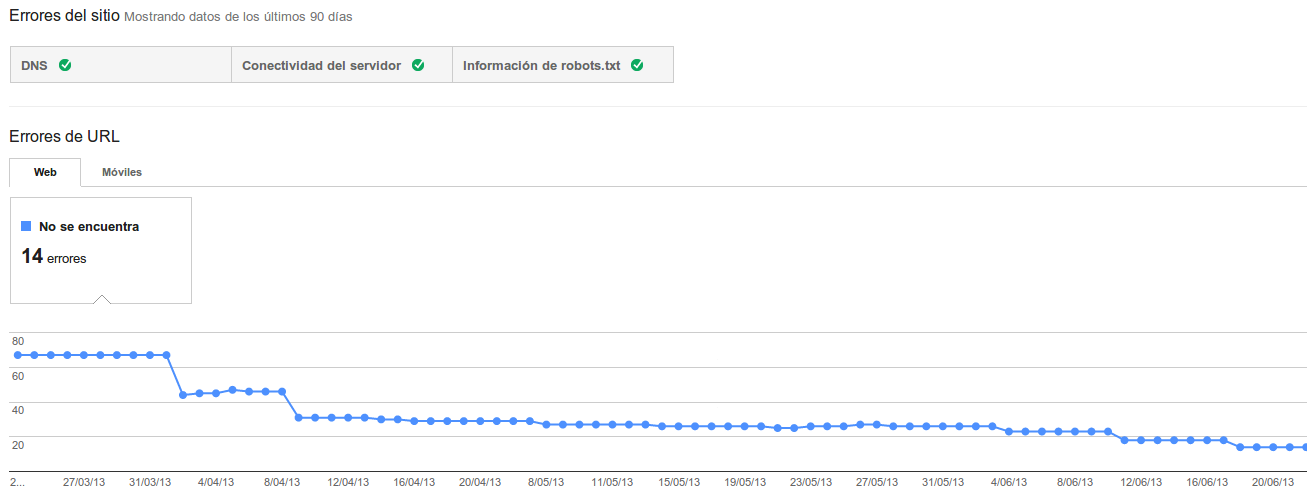
Dime que logs tienes, y te dire si Googlebot te quiere
Publicado el 23 de junio del 2013 By Lino Uruñuela Algo muy común en el día a día de un SEO es mirar las distintas herramientas que Google nos proporciona dentro de WMT para saber el estado de nuestra web en cosas como la frecuencia de rastreo, el número de páginas indexadas, errores 404, errores 503, etc... No está m…
Comprobando comportamiento de Google con meta canonical
Publicado el 10 de abril del 2012, by Lino Uruñuela Hace tiempo hice unos tests para comprobar que Google interpretaba el meta canonical y cómo lo evaluaba. No recuerdo si publiqué el experimento, pero sí recuerdo que Google contaba los links que había hacia una URL que contenía el meta canonical y traspasaba el valor…
Buenas Lino! Sólo comentar que el apellido de Gastón es RIERA (no Rivera). Saludos y gracias por compartir!
Uppsss cierto, la culpa es de tantas elecciones consecutiva... hacen remarketing en mi cerebro
En primer lugar agradecerte tus palabras, he sido alumno tuyo este año en el Máster de Webpositer en Alicante por lo que algo de culpa tendrás de que me surjan estas dudas ;-) Quiero matizar un poco el proceso que me ha llevado a mi reflexión, primero, porque como indicas, twitter no es el mejor sitio para ello, y de paso, enriquecer si se puede este post que te acabas de currar. Cuando has publicado la imagen con las diferentes medias de peso según el código de estado, al rato he caído que me faltaba más información: ¿en la agrupación que haces de códigos de respuesta 200, estás excluyendo las imágenes? He supuesto que sí, de lo contrario esa media de Kb estaría siendo alterada. Luego he pensado, igual erróneamente, que la comparación no debería ser entre la diferencia de peso de las urls 200 vs 404, si no del peso real de una url con código de error 404 (o mejor dicho, del peso del código html devuelto) y lo que está sirviendo el servidor (el peso que indica el log a esa petición). La única manera que tenía de comprobarlo era tirar de mis logs, aquí un apunte: no he usado ScreamingFrog, si no ScreamingLog. Nos enseñaste en clase a ver los logs en línea de comandos pero me has pillado en el curro y he tenido que tirar de algo más rápido ;-) La primera sorpresa que me llevo es que el peso de las urls de código 200 difiere, en mucho, al peso del código HTML que me descargo. Eso no pasa con las imágenes cuyo peso sí coincide tanto del log como del fichero. Aquí he caído que apache puede comprimir con gzip lo que envía al cliente si así lo tienes configurado en el servidor (como era mi caso). Las capturas que he puesto en twitter hacía referencia a eso: si comprimía el html con código 200 que me había descargado, el peso, ahora sí, coincidía con lo que me daba el log. ¿por qué el peso de la imagen sí coincidía entonces? Porque Gzip apenas es capaz de bajar el peso de una imagen jpg (he hecho también la prueba y no ha variado el tamaño del archivo). Por último, he cogido una url que daba código de error 404, (te aseguro que la página 404 del ecommerce en el que curro como desarrollador es bastante pesada ya que está incrustado todo el css), la he pasado por Gzip y…. tachán: el peso coincide con lo que me está mostrando el log (la captura está también subida en el hilo). De ahí mi conclusión: si el tamaño del fichero coincide, supongo que será debido a que Google pide la url completa y no solo el encabezado. Si esto es así, he pensado que igual sí influye el peso de esas páginas 404 en el rastreo. Una prueba que haré es: ¿Qué pasa si pido una url y antes de acabar de cargar en el navegador paro la petición? ¿El peso registrado en el log coincide con la carga de esa misma url completa? Si coincide sí puedo creerme que Google tenga algún mecanismo para parar la petición una vez recibida la cabecera, pero si no coincide la conclusión sería otra. Mañana haré alguna prueba con esto último que indico, prometo usar curl ;-). Otra prueba que haré es ver si en el log se ve diferenciado si se hace la petición de la cabecera o de toda la página.
Una manera súper sencilla para comprobarlo: 1- Una URL, mirar un log de Googlrbot de esa UR cuando da 200 2- Comparar con otro log de esa misma URL pero que de 404, mañana lo compruebo :) Y fuera dudas! Habrá que. @errioxa probando
Hola amigo, lo cierto es que no me he enterado pajolera idea de lo que cuentas, aunque te felicito por aparecer en el Discovery de Google. Me hubiera gustado que hubiera tenido para insertar mi web en lugar de mi email. Me hubiera valido para ganar un link externo. Puede que lo tengas en no follow. Por último hacerte una observación por si me la puedes resolver ¿Porqué de los resultados de Google, una o varias urls concretas, estas me las envía a urls distintas? Gracias por todo
muy bueno Lino, nos indica un elemento, de los tantos, en la optimización de googlebot, no trabajar en vano... ;-) ciao
Hola @acoutin te estoy usando de pruebba, esta será la última :)