Dime que logs tienes, y te dire si Googlebot te quiere
Publicado el 23 de junio del 2013 By Lino Uruñuela
Algo muy común en el día a día de un SEO es mirar las distintas herramientas que Google nos proporciona dentro de WMT para saber el estado de nuestra web en cosas como la frecuencia de rastreo, el número de páginas indexadas, errores 404, errores 503, etc...
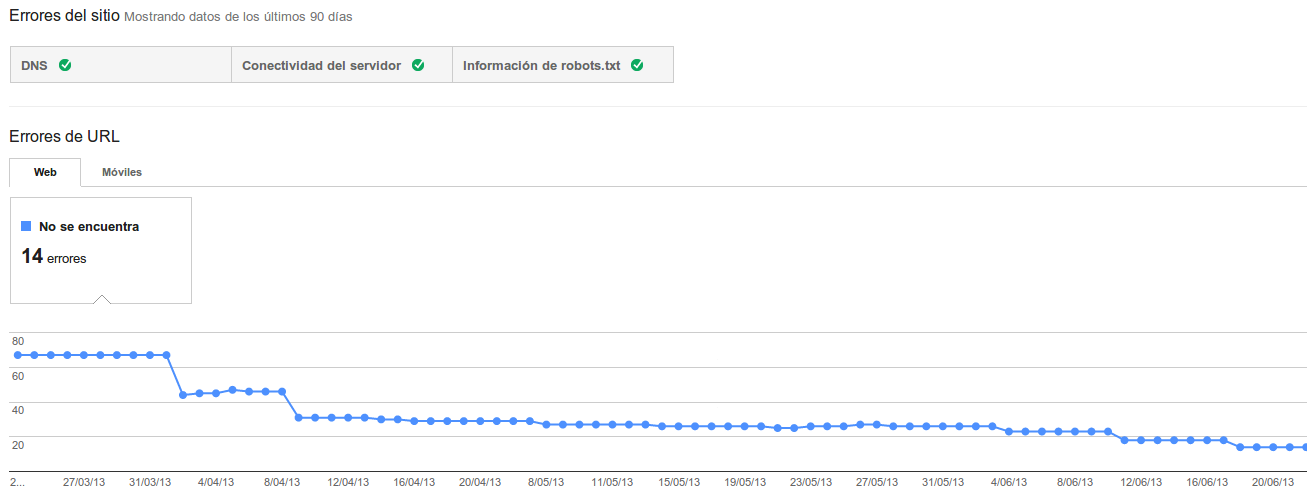
No está mal echar de vez en cuando un vistazo a estos datos, pueden darnos señales de algo que ocurra en nuestra web.
Pero creo que damos demasiada importancia a esos números e ignoramos otros datos en los que deberíamos fijarnos, por lo menos, de la misma manera aunque no nos los muestre WMT.En primer lugar, hay que inetentar comprender cómo funciona exactamente el bot de Google en nuestra página, y en segundo lugar, debemos optimizar lo que creamos que hay mejorable y/o arreglar lo que esté mal después de analizar lo que veamos.
Por ejemplo, en el caso de los errores 404, o los errores propios del servidor los 501, 503, etc, estos datos debemos mantenerlos lo más bajo posible, porque todos podríamos afirmar en consenso que tener muchos errores, bueno no es. Así que si los controlamos mucho mejor.
Hay otros datos como el número de páginas rastreadas al día, que no es que me fie o no de esa gráfica, porque realmente la mayoría de las veces coincide en las variaciones de la frecuencia de rastreo, cuando la contrastas con los logs . Pero posiblemente no sea muy importante el valor del número sino como varía y por qué!
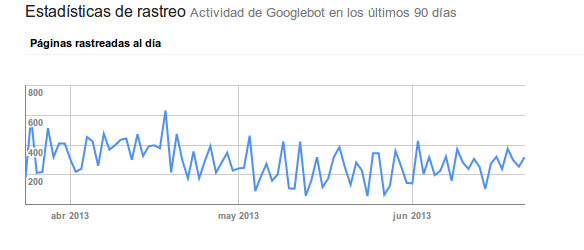
Dicho esto, creo que nos conformamos con muy poco, con estos datos realmente estamos tuertos si no analizamos nada más. El saber qué está haciendo el bot cuando llega a nuestra web, por dónde está “perdiendo” el tiempo,
-
¿cada cuanto vuelve a rastrear los distintos tipos de urls que tengamos?
-
¿Con que frecuencia rastrea nuestros sitemaps?
-
¿Cuántas redirecciones 301 tenemos en cada tipología de url?
- ¿Sigue Google rastreando redirecciones de hace 10 años? ya os lo adelanto... sí.
-
¿Cuánto tiempo dedica a los paginados?
-
¿Y a los filtros?
-
¿Cuál es el ratio entre el número total de hits de Googlebot que hay en cada tipo de urls y los usuarios recibidos a éstas?
¿A que ahora parece que no sabemos nada?
Hay que reconocer que la única información útil que nos puede mostrar Google Analytics y no nos la podrán dar los logs del servidor, son los datos de las kw de los usuarios que llegan de buscadores, y puede que dentro de pooco nos quedaremos sin referer, ya que cada vez hay más usuarios que van con esa información encriptada o directamente sin ella como en OS6.
¿Que podemos hacer de una forma rápida y fácil con los logs?
Hay cuatro o cinco comandos (linux) que podemos/debemos usar para obtener unos datos muy interesantes de la actividad del bot en nuestras páginas.
Ahí tenemos muchísima información, y si lo hacemos
bien, que es muy fácil, tendremos datos más
fiables que los de
cualquier herramienta de analítica que nos proporcionen otros, como WMT.
Vamos a ello!
Digamos que nos bajamos los logs del servidor del último mes, o de donde los tengamos guardados. Normalmente vienen en ficheros separandos, por ejemplo, pongamos que tenemos
-
ficherologs.1
-
ficherologs.2
-
ficherologs.3
-
ficherologs.4
-
etc
Lo primero que vamos a hacer es unir estos logs todos en un mismo fichero, para esto hacemos.
cat ficherologs.* > logs-Unidos.txt
Ahora que ya tenemos todos los logs juntitos, vamos analizar por ejemplo los hits que hace Googlebot en nuestro site. Para ello del fichero de logs-Unidos.txt vamos a quedarnos sólo con los accesos de Googlebot y los meteremos en otro archivo
cat logs-Unidos.txt | grep Googlebot > AccesosTotalesGooglebot.txt
Cada fila representa un acceso de Googlebot, entonces, ya tenemos el número total de veces que Googlebot ha pasado por nuestro site!, en dos órdenes... vamos a analizar un poquito más. Hay que tener en cuenta que en este fichero están todos los accesos, tanto a imágenes, js, etc. aunque Googlebot casi no entra en comparación al resto de urls
Así que vamos a centrarnos en URLs de contenido, no js, css, o imágenes.
No quedmaos sólo con la info útil de cada línea, en este caso las URLs
cat AccesosTotalesGooglebot.txt | egrep -io 'GET (.*) HTTP' > HitsTotales.txt
Ahora tenemos un fichero que está compuesto por líneas como estas
Vemos que por cada línea tenemos un GET + landing + HTTP, el GET y el HTTP los he dejado ahí porque la primera vez que hice la expresión regular me salió de esta manera, y cómo realmente me da igual que estén o no... pues ahí siguen :)
Ahora filtramos para quedarnos sólo con las urls de contenido, o sea, nos quedamos sólo con las que acaben en “.php HTTP” o en “/ HTTP”
cat AccesosTotalesGooglebot.txt | egrep -io 'GET (.*)[\.php|/] HTTP' > Hits-URLs.txt
Ahí tendremos por cada línea un acceso de Googlebot a la url de esa línea. Ahora sí, podemos saber el número de accesos que ha hecho en total el bot.
egrep -c '' Hits-URLs.txt
El resultado que devuelve es el número de hits que hace Googlebot en nuestro site.
Puede que también queramos saber por ejemplo el desglose por tipo de url, entonces le ponemos el patrón que las diferencie, por ejemplo yo quiero saber cuántas hits hay a urls de un directorio haría
egrep -c 'nombreDirectorio' Hits-URLs.txtDaros cuenta que en vez de nombreDirectorio le puedo poner el patrón que quiera, por ejemplo el patron que uso en las paginaciones, o el patrón que se usa en cada filtro. De esta manera también sabré cuánto tiempo dedica el bot a rastrear mis paginados... En todas las webs que miro se pasa casi un 80% del tiempo en paginados o haciéndose la picha un lío ordenándose a si mismo...
Si la web es muy muy grande esto puede ser un punto en tu contra, porque ese tiempo que dedica a esos paginados interminables no se lo dedica a otras urls que quizás te interesaran más...
Otro dato muy importante es saber a cuántas URls únicas accede, ¿cuántas URLs rastrea de verdad?
Tal como está ahora puede haber muchos accesos por parte de Googlebot a una misma URL .pero nosotros ahora quremos analizar por ejemplo cuántas URLs distintas nos está rastreando
Para eso vamos a ordenar y agrupar nuestro fichero de Hits-URLs.txt con la siguiente orden
sort Hits-URLs.txt | uniq -c > hits-agrupados-por-urls.txt
Si miramos cómo nos queda el fichero vemos algo así
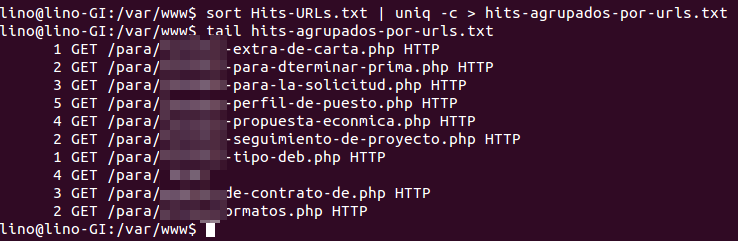
Donde el número de la primera columna es las veces que el bot de Google ha accedido a esa url. Ahora con la misma orden de antes (o contando las líneas totales del fichero) sabremos cuántas URLs distintas ha rastreado Google.
egrep -c '' hits-agrupados-por-urls.txt
De la misma manera podemos analizar cuánto tráfico orgánico nos llega desde Google por medio de los logs, y combinando con los datos que hoy hemos obtenido podemos tener una visión muy clara de que URls son rentables o cuáles no, pero esto lo dejaremos para el próximo post :)
Además se pueden pintar todos estos datos gracias a muy diversas y variadas herramientas de gráficas, y así conseguiremos gráficas como estas, donde desglosamos todos estos filtros y datos.
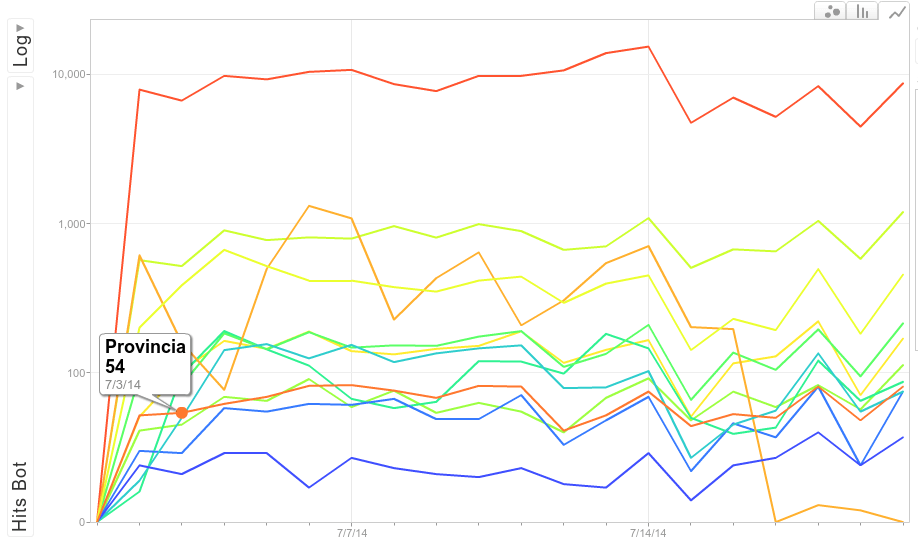
Todavía más:
Comentarios
1Lee otros artículos
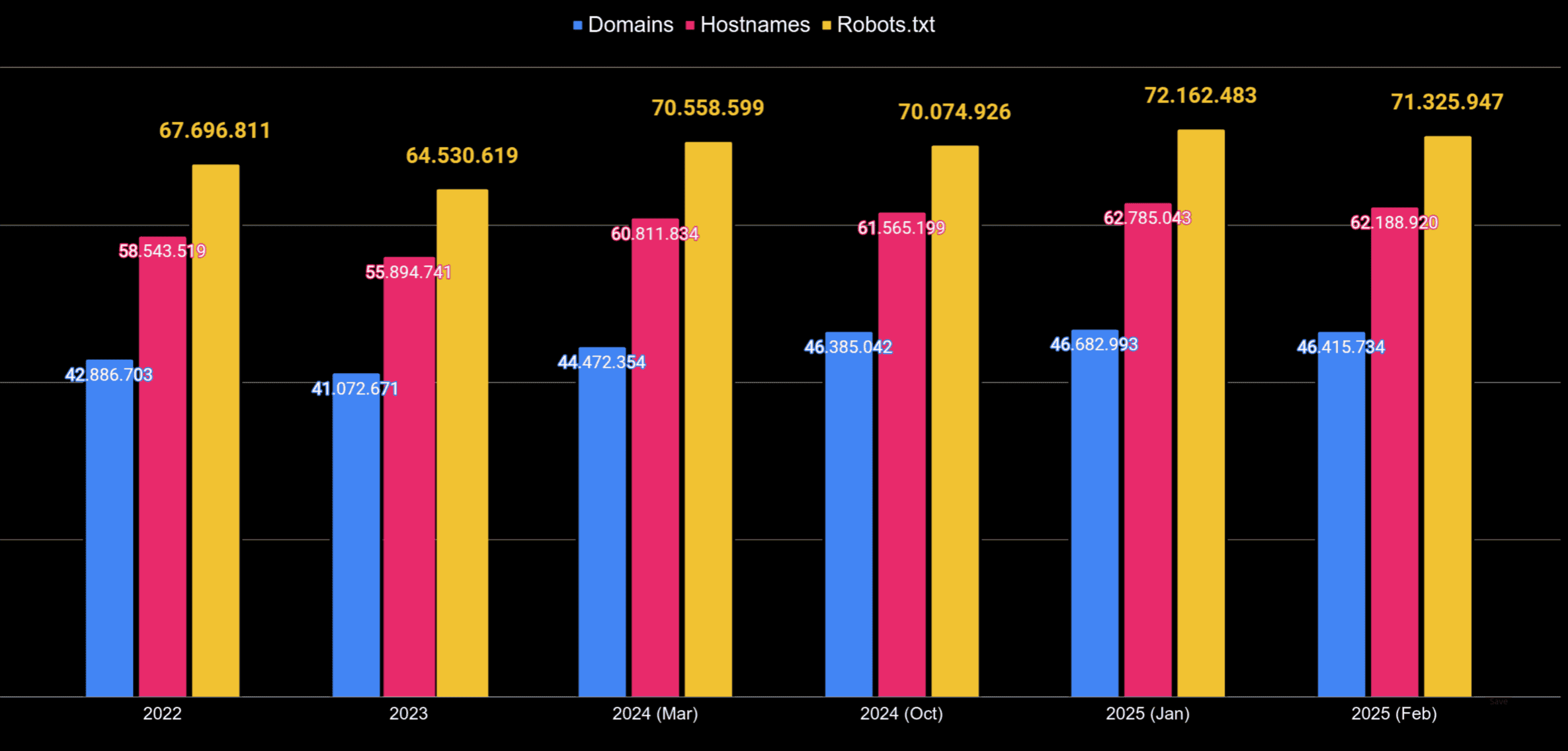
¿Se está impidiendo a los bots de Inteligencia Artificial acceder al contenido?
¿Cómo ha ido incrementando el número de robots.txt en los que aparecen rastreadores asociados a la Inteligencia Artificial?
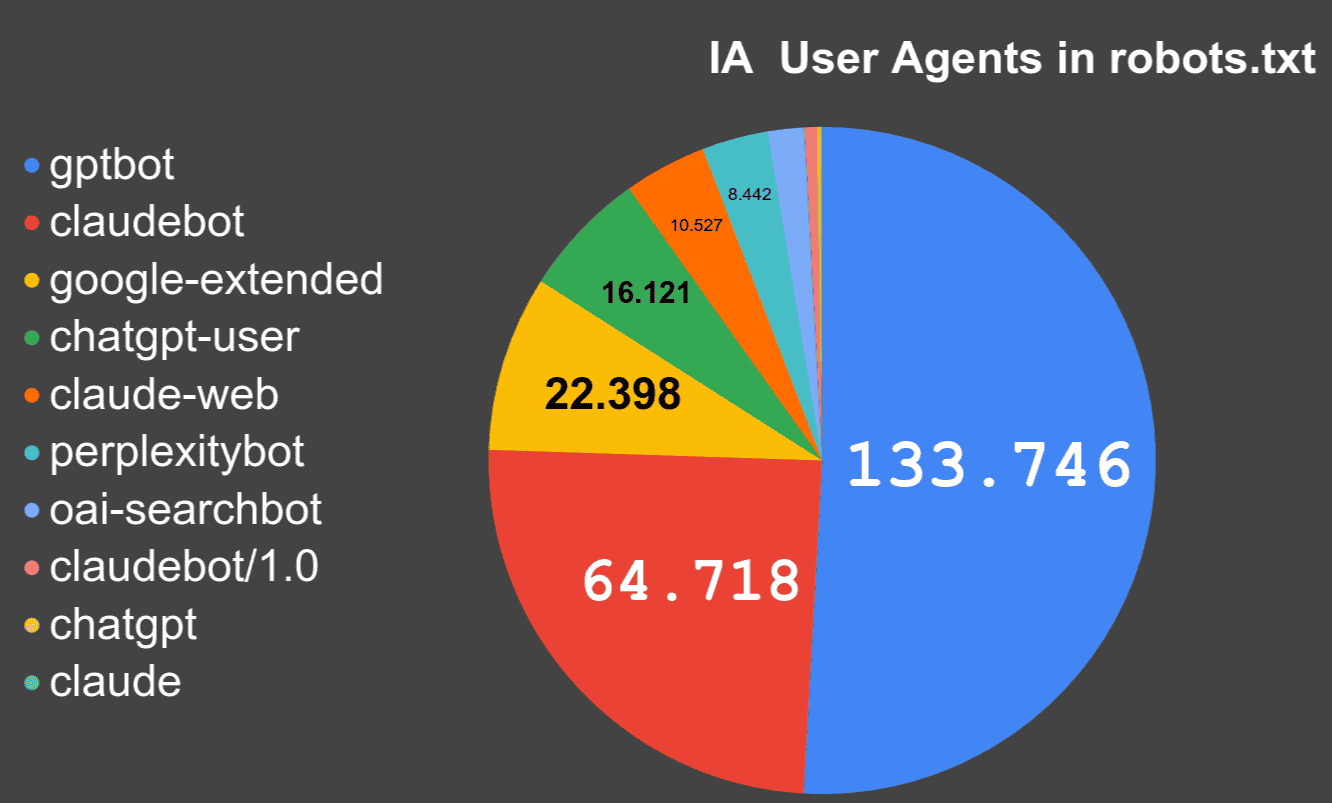
Analizando más de 72 millones de robots.txt
¿Cuántos dominios, subdominios y robots.txt estén bloqueando a los crawlers de Inteligencia Artificial?
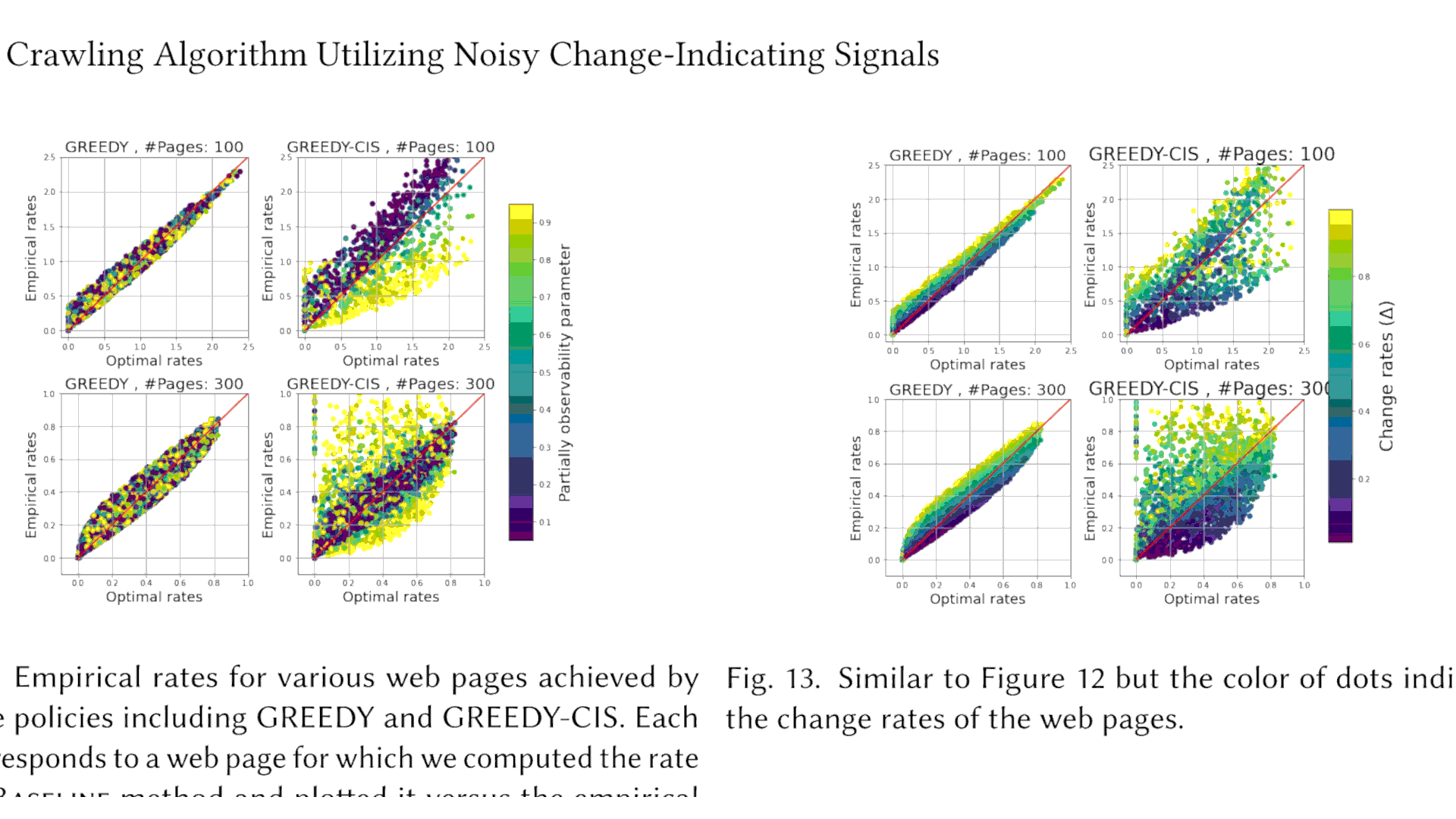
¿Cómo decide Google que URL debe rastrear?
Hoy he descubierto este paper de Google (A Scalable Crawling Algorithm Utilizing Noisy Change-Indicating Signals) dónde describe una mejora del método descrito en el artículo inicial
Búsqueda semántica de contenidos en los vídeos de Youtube
n la segunda parte mostré un caso de uso un poco más complejo para crear un buscador de contenidos dentro de los vídeos de Youtube. En este post voy a detallar la segunda parte, cómo podemos utilizar la línea de comandos + Bert + SQL para crear un buscador de contenidos dentro de los vídeos.
Google podria no querer el HTML de una URL
Publicado por Lino Uruñuela el 10 de diciembre del 2019 Llevaba tiempo preparando un post, pero me cuesta, porque quiero redactarlo bien, explicadito y al final o no lo comienzo por la pereza que me da eso de currármelo en vez de soltarlo así según viene, o directamente no lo termino jamás.... Pero hoy vuelvo a mis or…
Intentando comprender Googlebot y los 301
Publicado por Lino Uruñuela el 22 de marzo del 2017 El otro día hubo un debate sobre qué método usará Google a la hora de interpretar, seguir y valorar las redirecciones 301. Las dudas que me surgieron fueron ¿Cómo se comportan los crawlers? Normalmente cuando lanzamos un crawler como Secreaming Frog lo que hace es Ac…
Crawl Budget, qué es y cómo afecta a tu site según Google
Publicado por Lino Uruñuela el 16 de enero del 2017 en Donostia Desde hace ya mucho tiempo llevo analizando, probando y optimizando el Crawl Budget o Presupuesto de Rastreo. Ya en los primeros análisis vi que esto era algo relevante para el SEO, que si bien no afecta directamente a los rankings de una KW determinada,…
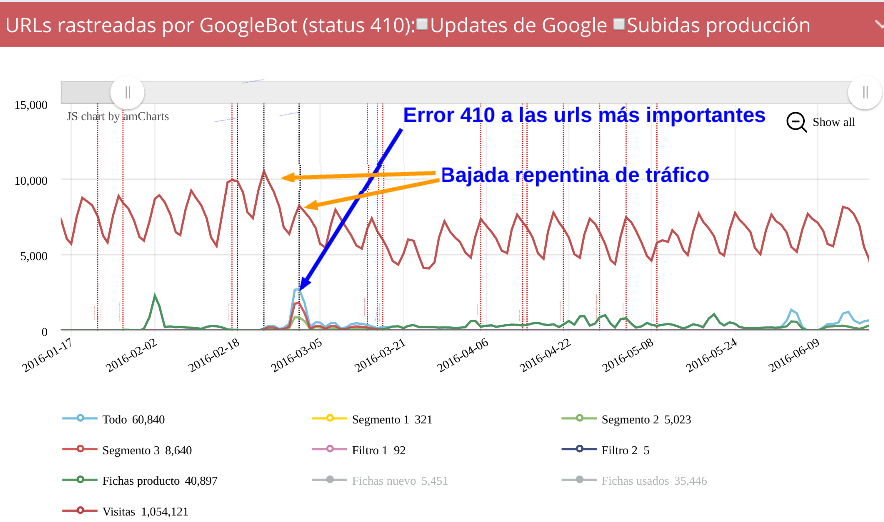
El valor de los logs para el SEO
Publicado el martes 6 de septiembre del 2016 por Lino Uruñuela Hace poco escribí el primero de una serie de post sobre el uso de Logs, Big Data y gráficas, en este caso continúo el análisis de la bajada que comenzamos a ver en Seo y logs (primera parte): Monitorización de Googlebot mediante logs , una caída importante…
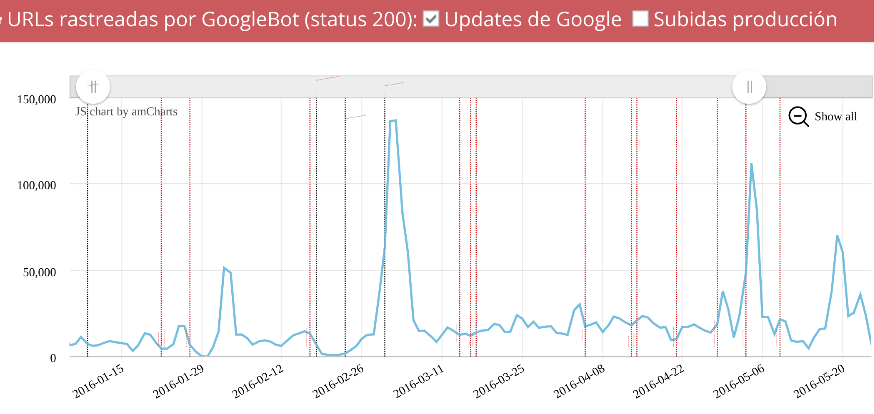
Seo y logs (primera parte): Monitorización de Googlebot mediante logs
Publicado por Lino Uruñuela el 27 de junio del 2016 Una de las ventajas de analizar los datos de los logs es que podemos hacer un seguimiento de lo que hace Google en nuestro site, pudiendo desglosar y ver independientemente el comportamiento sobre urls que dan error, o urls que hacen redirecciones, o urls que son cor…
Comprobando comportamiento de Google con meta canonical
Publicado el 10 de abril del 2012, by Lino Uruñuela Hace tiempo hice unos tests para comprobar que Google interpretaba el meta canonical y cómo lo evaluaba. No recuerdo si publiqué el experimento, pero sí recuerdo que Google contaba los links que había hacia una URL que contenía el meta canonical y traspasaba el valor…
Hola, Quiero comenzar a analizar los logs de mi blog, para iniciarme en el tema. He hablado con la gente del hosting y me preguntan que que tipo de logs quiero. Podría alguien decirme como se denomina a estos blogs o que nombre técnico tienen? Muchas gracias!