Arquitectura de agentes para SEO
Un agente de IA, en el contexto del SEO, es un sistema que puede recibir información sobre su entorno (tu web, competidores, datos analíticos), tomar decisiones y que puede realizar acciones para lograr un objetivo concreto (mejor posicionamiento en IA, aumento de tráfico, etc.). La arquitectura de agentes para SEO se basa en cómo integrar los distintos componentes que trabajan conjuntamente para lograr mejorar y optimizar la respuesta.

Hoy la IA está en boca de todos, pero ¿está en nuestra mente y en nuestros procesos de trabajo? Estoy muy lejos de ser un visionario, pero, como SEO, vislumbro un horizonte completamente diferente al actual.
No digo que el SEO haya muerto, nunca creí en eso, pero, siendo sincero con todos, y sobre todo conmigo mismo, creo que en estos últimos meses esa frase es lo más cercana a la verdad de lo que nunca antes había estado.
No creo que el SEO haya muerto, podemos llamarlo GEO si queréis; siempre que haya miles de millones de personas (o agentes) buscando información, productos o servicios en internet, el SEO aportará un valor real a las empresas y personas que ganan dinero con ese producto que busca la gente.
Dicho esto, creo que es innegable que se está produciendo un cambio, pero no es un cambio de algoritmo, ni tampoco un cambio en la empresa que domina o monopoliza la búsqueda; el cambio es mayor, más abrupto, y los desarrolladores son los primeros que lo están notando.
Aprendamos de los desarrolladores
Podemos fijarnos en cómo el entorno laboral de los desarrolladores está cambiando por completo en tan solo 4 meses. Es un hecho, ya no hay discusión sobre ello, y digo ya porque hasta hace un año muchos desarrolladores seguían pensando que la IA nunca llegaría al nivel que un developer tiene con 20 años de experiencia, pero está claro que se equivocaban.
Hoy los gurús de las grandes tecnológicas están casi totalmente de acuerdo: el código tiende a tener menos valor, el ser experto en un determinado lenguaje de programación ha disminuido de valor en varios órdenes de magnitud... Por supuesto, siempre serán necesarias un número determinado de personas desarrollando, supervisando y probando código, pero cada vez serán menos.
Algunos de los veteranos más antiguos del mundo digital quizá aprendieron a programar en ensamblador. Yo comencé mis estudios en desarrollo de sistemas en 2001 y, por suerte, ya no se enseñaba, y hoy en día pocas personas programan en este lenguaje que habla casi en unos y ceros.
Pero el código en ensamblador está presente en todos lados, es el lenguaje de más bajo nivel que habla directamente con el silicio... Aun siendo imprescindible en cualquier sistema, cada vez menos personas lo conocen y manejan. ¿Eso quiere decir que desaparecerá? No. De momento es imposible, pero pocas empresas tienen necesidad de programar en ensamblador y, por lo tanto, tiene poco valor económico.
A la programación, en general, le está comenzando a pasar lo mismo, y a la velocidad a la que avanza la IA, dentro de poco saber Python o JavaScript será como el ensamblador: irán perdiendo cuota de mercado y valor económico.
Evolución de la IA y el futuro del SEO / GEO
¿Y qué pasa con el SEO? Creo que también sufrirá un cambio rapidísimo en la forma en que trabajamos, pero con una diferencia muy importante: el valor de conseguir que los usuarios que buscan lo que tú tienes y/o vendes no dependerá de la IA... o eso creo.
Dicho esto, hace más o menos un mes abrí los ojos, o mejor dicho, me cambié de gafas y lo que veía borroso ahora, con las nuevas gafas, lo veo de colores. Ya veremos si es por el papel de celofán del que están hechas o si realmente son buenas y hasta están polarizadas...
El SEO del futuro, y muchísimos de los trabajos que están alrededor de la generación de software, será un SEO que no necesitará tener un nivel súper técnico; aportará mucho más valor un perfil que conozca el producto y que comprenda el problema que tienen sus posibles clientes, el cómo buscan ese producto y el cómo posicionarte justamente ahí. Pero no necesitaremos saber JavaScript y, si me apuras, ni CSS ni HTML; deberá ser un experto en el producto o servicio que vende y en cómo mostrarlo a los usuarios correctos.
Como he dicho antes, llevo más o menos un mes con las gafas puestas, pensando en que debo seguir haciendo el mismo trabajo que hacía, pero sin tocar una línea de código y creando un sistema o arquitectura con instrucciones para los agentes de IA, tanto en general como para cada proyecto.
Estructura y planificiación de la arquitectura
Seguro que habéis oído hablar de los arneses, de las skills o de CLAUDE.md; la ingeniería de contexto es algo que, de momento, no está resuelta. Que los agentes de IA sepan todo sobre el proyecto teniendo una "memoria" muy limitada hace que la estrategia de cómo darles ese conocimiento en cada tarea se esté volviendo muy interesante.
Niveles de adopción de IA
- Nivel 1: "Copiar y pegar desde ChatGPT"
Preguntar a un modelo y copiar fragmentos de código o recomendaciones de mejora de un chat y pegarlos en tu código, en el Excel o en el documento Word que entregas al cliente. Es un caso de uso válido, la IA te ayuda a explorar ideas y agilizar alguna tarea. Pero, comparado con los agentes, está obsoleto. - Nivel 2: Agentes en la línea de comandos, terminal o en el IDE de tu editor de código.
Usar la IA desde el terminal o el editor de código con procesos encadenados que necesitan de cierta lógica para tomar decisiones en tiempo real. Yo estoy aquí, habrá algunos que piensen "pues hay muchos SEOs que lo hacen todo con agentes, lo hacen todo, y súper bien".... De estos no me creo nada, o mienten o el nivel del trabajo que hacían era muy simple. - Nivel 3: Orquestación de agentes o multiagentes
Ejecución de agentes, bucles con retroalimentación automática y de usuarios, desarrollo basado en especificaciones, crear configuraciones multiagente. Aún no he llegado, pero sé que voy hacia allí.
Podemos pensar en la IA como configuración que se ejecuta, no es documentación con información, es un fichero que le dice a un agente de IA qué hacer, con qué herramientas y qué reglas debe cumplir: es código de control.
La línea de comandos
Como muchos sabréis, me gusta frikear con el código, comandos de terminal y ese tipo de "sudoku" que es para mí la programación. Siempre he intentado crear mis propias herramientas, mis procesos automáticos y mejorar el manejo de datos. Y eso, ahora, también será realizado por la IA sin necesidad de conocimientos profundos tras 20 años ejecutando todo tipo de comandos, de destruir tu propio ordenador con un "simple" sudo apt purge python*; sí, vi cómo el entorno gráfico iba desapareciendo hasta que solo quedaba el terminal y todo terminó.
Una de las cosas en las que más me estoy centrando es en aprovechar todos esos comandos, scripts y procesos que he ido desarrollando durante los últimos años para diferentes tareas, que van desde el scraping de las posiciones en Google y la creación de paneles de control y dashboards de métricas con datos de diferentes fuentes, hasta obtener contenido HTML de una URL para conseguir los datos necesarios para la tarea o análisis que estuviese haciendo.
Ya comenté que cuando he usado Claude a través de su interfaz web no me rentaba, los créditos me duraban poco más de media hora, pero usando Claude Code desde el terminal parece que los límites son infinitamente mayores. La causa puede ser que, cuando usas la interfaz web para desarrollar código, la IA tiene que leer las indicaciones que le des, leer los ficheros o texto que le adjuntes, guardar esta información para seguir teniendo "conocimiento" de la tarea encomendada tras realizar alguna acción, posiblemente levantar un entorno donde ejecutar código... Todo eso por cada sesión de usuario, y eso tiene un coste.
Usando el terminal me he dado cuenta del coste en tokens que tiene procesar HTML. Procesar HTML puede ser fácilmente un 75% más costoso que texto plano. Por esta razón tengo varios comandos y herramientas para extraer el texto o código concreto que necesito y pasarle solamente lo mínimo necesario al agente para realizar la tarea encomendada.
Para ello puedo usar trafilatura, que obtiene el contenido principal de una URL omitiendo headers, footers, barras de navegación, etc. O también puedo usar shot-scraper, que puede tomar desde capturas de pantalla hasta renderizar el contenido y ejecutar JavaScript sobre él como si estuvieses en la consola de desarrollador de Chrome. Este tipo de herramientas o comandos que puede usar la IA nos permite ahorrar muchos tokens.
Algunas herramientas que uso:
| Herramienta | Ruta | Para qué |
|---|---|---|
trafilatura |
/media/.../bin/trafilatura |
Texto editorial limpio de una URL (sin nav, footer ni ads) |
google_search_simple.py |
./venv/bin/python ./venv/bin/google_search_simple.py |
SERP completa: orgánicos, PAA, AI Overview, anuncios en JSON |
shot-scraper |
./venv/bin/shot-scraper |
Screenshots, HTML ligero, ejecución de JS en DOM |
llm |
./venv/bin/llm |
Modelos LLM locales vía Ollama (GPU) |
clickhouse-client |
clickhouse-client |
Consultas a ClickHouse servidor (GSC, logs) |
clickhouse-local |
clickhouse-local |
Consultas a CSV y JSON locales sin servidor |
Routing de modelos LLM por tipo de tarea
Además de estas herramientas, también ejecuto LLMs en local para tareas no muy complejas que no requieran un razonamiento de última generación. En vez de hacer que el LLM de pago ejecute, lea el resultado y tome alguna decisión que cualquier otro modelo menos capaz resuelve sin problemas, el agente ejecuta el LLM local ya sea de manera síncrona o asíncrona para tareas sencillas que, si las hiciese el LLM de Claude, serían un desperdicio de tokens.
Estos son los modelos que más frecuentemente ejecuto en local
| Tarea | Modelo |
|---|---|
| Clasificación, etiquetado, extracción de campos | qwen3.5:9b |
| Resumen, descripción corta, comparativa simple | qwen3.5:9b |
| Razonamiento multistep, diagnóstico causal, síntesis de múltiples fuentes | qwen3:30b |
| Análisis de imágenes, screenshots, capturas SERP | qwen3-vl:8b |
El objetivo es usar siempre el modelo más pequeño que cubra la tarea para no saturar la GPU ni aumentar la latencia innecesariamente.
Vista general de la estructura
Os voy a compartir lo que ya tengo organizado para mi trabajo, para automatizar aquellas tareas que tienen sentido y se pueden automatizar. No esperéis nada alucinante, como he dicho llevo un mes con esta mentalidad y poco a poco voy montando lo que creo que será el trabajo diario del SEO en unos años.
Y aquí os dejo una pequeña explicación y descripción de la arquitectura que de momento estoy generando (y que por supuesto ha generado la IA). Esto puede variar en muy poco tiempo visto el ritmo al que avanza todo, pero, de momento, creo que va por buen camino.
Informes/ Raíz del workspace
├── CLAUDE.md Identidad y reglas del agente para este proyecto
├── tareas.json Cola de trabajo pendiente/completado
├── fallos-sql-correcciones.md Errores reales encontrados + correcciones verificadas
│
├── scripts/ Herramientas reutilizables entre todos los proyectos
│ ├── render_url.py
│ ├── google_search_simple.py
│ ├── parse_schemas.py
│ ├── validate_jsonld.py
│ └── check_rich_results_test.py
│
└── Proyectos/<NombreProyecto>/
├── CLAUDE.md Identidad y reglas del agente para este proyecto
├── tareas.json Cola de trabajo pendiente/completado
├── fallos-sql-correcciones.md Errores reales encontrados + correcciones verificadas
│
├── skills/
│ ├── SKILL.md Índice maestro: qué puede hacer el agente y cómo
│ ├── conf.md Credenciales, esquema de BD, regex de segmentación
│ ├── data.md Rutas absolutas a todas las fuentes de datos
│ └── plantillas/
│ ├── analisis-seo-trafico.md ← SOP de análisis de tráfico
│ ├── analisis-seo-tecnico.md ← SOP de auditoría técnica
│ ├── comparacion-entornos.md ← SOP de QA producción vs. staging
│ ├── doc-structured-data-markup.md ← SOP de datos estructurados
│ └── Structured-Data-Google-Search-Supports/
│ └── SKILLS.md Referencia offline: tipos soportados por Google
│
├── Datos/
│ ├── data-crawler-screamingfrog/
│ │ ├── SKILLS.md Columnas del CSV + consultas clickhouse-local
│ │ └── *.csv Exportación del crawler
│ ├── google-rankings/
│ │ ├── SKILLS.md Estructura JSON + consultas clickhouse-local
│ │ └── *.json Rankings diarios por keyword
│ └── KWs-*.txt Listas de keywords para seguimiento
│
├── codigo-usado/
│ ├── README.md Propósito y reglas del directorio
│ ├── comparacion_entornos.sh ← Bitácora de comandos del SOP de QA
│ ├── revision_structured_data.sh ← Bitácora de comandos del SOP de schemas
│ ├── extract_product_jsonld.py ← Script auxiliar específico de tarea
│ └── *.html / *.json Artefactos intermedios (cachés de sesión)
│
└── informes/
└── <Tipo>-<YYYY-MM-DD>-dominio.com.md ← Salidas persistidas de cada análisis
CLAUDE.md del proyecto: identidad del agente
Fichero: Proyectos/<Proyecto>/CLAUDE.md
Es el primero que lee Claude Code al abrir el proyecto. Define quién es el agente en este contexto y con qué reglas opera. No es documentación para humanos: es el system prompt efectivo del agente.
Qué contiene:
<identity>
Eres un Agente Especialista SEO Experto con capacidades avanzadas de análisis...
</identity>
<mission>
Monitorizar el estado SEO continuo de "midominio.dev"...
</mission>
<critical_rules>
- USER_AGENT_RULE: Al acceder y obtener el contenido de URLs de midominio.dev SIEMPRE usarás UA de Googlebot.
- DATA_FIRST_RULE: Jamás asumas sin verificar conf.md primero.
- AUTONOMY_RULE: No preguntes si detectas anomalías; analízalas de inmediato.
- SEQUENTIAL_EXEC_RULE: Los scrapers para obtener resultados de Google se ejecutan individualmente, nunca en paralelo.
- CODIGO_USADO_RULE: Todo comando ejecutado se registra en codigo-usado/
</critical_rules>
<environments>
<production url="https://www.midominio.dev" />
<development url="https://dev.midominio.dev" />
</environments>
Por qué importa: sin este fichero, el agente actúa en modo genérico. Con él, sabe exactamente qué dominio está monitorizando, qué herramientas puede usar, cuándo actuar solo y cuándo parar. Es la capa que diferencia "Claude usando SEO" de "un agente SEO para midominio.dev".
skills/SKILL.md:
Tiene frontmatter YAML para que Claude Code lo indexe como skill invocable, y contiene el SOP raíz: el workflow completo de análisis de extremo a extremo.
---
name: analiza-seo-miproyecto
description: SOP completo para análisis SEO de midominio.dev. Extrae tráfico de
ClickHouse, lanza SERPs con google_search_simple.py, analiza competidores
con shot-scraper/trafilatura y genera informe en Markdown.
---
El cuerpo es XML estructurado con tres bloques:
<dependencies> — qué otros ficheros debe leer antes de empezar:
<dependency type="config" path="skills/conf.md" />
<dependency type="template" path="skills/plantillas/analisis-seo-trafico.md" />
<tools> — herramientas con comandos exactos y reglas de uso:
<tool name="google_search_simple.py">
<command>./venv/bin/python google_search_simple.py "[KW]" --hl es</command>
<rule>CRÍTICO: Ejecutar SIEMPRE de forma secuencial. No usar & ni paralelo.</rule>
</tool>
<execution_phases> — el flujo paso a paso:
<phase id="1" name="Data Extraction (ClickHouse)">
<step id="1.1">Extracción de tráfico agrupada por idioma.</step>
<step id="1.2">KWs que suman el 50% de clics en el segmento más fuerte.</step>
<step id="1.3">Semana con mayor variación usando lagInFrame sobre 90 días.</step>
</phase>
<phase id="2" name="SERP & Competitor Sourcing">
...
</phase>
Por qué es XML y no Markdown libre: el XML fuerza una estructura formal que el LLM respeta con más precisión. <phase>, <step>, <rule> no se pueden omitir silenciosamente como sí podría pasarse por alto un párrafo de texto plano.
skills/conf.md: las credenciales y el esquema de datos
El agente lee este fichero antes de escribir cualquier query. Contiene tres bloques críticos:
Conexión a la base de datos donde hay diferentes fuentes de datos
Por ejemplo, datos de Search Console, datos de GA, datos del CRM...
<command>
clickhouse-client -u Agente_lectura --password='...' --query
</command>
<rules>
<rule>NO añadas ningún otro parámetro de conexión, solo la query requerida.</rule>
<rule>Fuerza FORMAT JSONEachRow para análisis o FORMAT Markdown para tablas en .md</rule>
</rules>
Esquema de la tabla con los datos de Search Console:
<schema>
<database_name>DT</database_name>
<table_name>GSC_miproyecto</table_name>
<fields>
<field name="fecha" type="Date">Día de registro</field>
<field name="consulta" type="String">Keyword</field>
<field name="landing" type="String">URL destino del click</field>
<field name="clicks" type="UInt32">Clicks absolutos</field>
<field name="posicion" type="Float32">Posición media SERP</field>
</fields>
</schema>
Regex de segmentación de URLs:
<segment name="Tipo Blog" sql_pattern="landing LIKE '%midominio.dev/es/blog/%'" />
<segment name="Tipo Producto" sql_pattern="landing LIKE '%midominio.dev/es/prod/%'" />
Por qué aquí y no en el SKILL.md: conf.md se reutiliza en todos los SOPs. Cada plantilla lo declara como dependencia. Si cambian las credenciales o el esquema, hay un único fichero que actualizar.
skills/data.md: el mapa de fuentes de datos
Rutas a los ficheros de las diferentes fuentes de datos que el agente puede consumir; por ejemplo, datos de Screaming Frog, datos de posiciones y resultados de Google, AdWords, etc.
## Crawler técnico — Screaming Frog
| Ruta | `../Datos/data-crawler-screamingfrog/urls-crawler-miproyecto.csv` |
| Fecha | 2026-03-15 |
| URLs | ~12.000 |
| Docs | `Datos/data-crawler-screamingfrog/SKILLS.md` |
## Rankings en SERPs — google-rankings
| Ruta | `/media/.../Datos/google-rankings/*.json` |
| Frecuencia | Diaria (script cron) |
## Keywords para seguimiento
| KWs-MiProyecto.txt | Keywords principales del proyecto |
| KWs-MiProyecto-Blog.txt | Keywords de los artículos del blog |
| KWs-Competencia.txt | Keywords donde compiten dominios rivales |
Por qué importa: el LLM no puede explorar el disco libremente. Sin este fichero, necesitaría que el usuario le diga cada vez dónde están los datos. Con él, sabe exactamente qué hay disponible sin preguntar.
Datos/*/SKILLS.md con la documentación de cada fuente
Ficheros: Datos/data-crawler-screamingfrog/SKILLS.md, Datos/google-rankings/SKILLS.md
Cada fuente de datos tiene su propio fichero de documentación que responde a: ¿qué columnas tiene? ¿cómo se consulta con la herramienta CLI disponible?
Ejemplo del SKILLS.md del crawler:
## Columnas principales
| `Dirección` | URL completa |
| `Código de respuesta` | Código HTTP (200, 301, 404…) |
| `Indexabilidad` | `Indexable` / `Non-Indexable` |
| `TipoPagina 1` | `product-detail`, `category`, `blog-post`… |
| `Elemento de enlace canónico 1`| URL del canonical declarado |
## Cómo consultar con clickhouse-local
Los nombres de columna contienen espacios → citarlos con comillas dobles en SQL.
Los campos numéricos se almacenan como texto → usar toInt32OrZero() para castear.
### Ejemplo — URLs con título ausente, corto o largo
clickhouse-local --query "
SELECT \"Dirección\", \"Título 1\", toInt32OrZero(\"Longitud del título 1\") AS longitud
FROM file('urls-crawler-miproyecto.csv', CSVWithNames)
WHERE toInt32OrZero(\"Longitud del título 1\") < 30 OR > 65
FORMAT Markdown"
Por qué en SKILLS.md y no en conf.md: conf.md describe la base de datos en servidor (ClickHouse con GSC). Los SKILLS.md describen ficheros locales con esquemas distintos y herramientas distintas (clickhouse-local vs. clickhouse-client). Separar evita confusión entre fuentes.
skills/plantillas/*.md
Cada fichero es un protocolo operativo estándar (SOP) para un tipo concreto de análisis. El agente los invoca cuando el usuario pide ejecutar esa tarea, o cuando el CLAUDE.md le indica que los use de forma autónoma ante determinadas condiciones.
Estructura de plantilla de tarea
Cada plantilla es un XML con schema versionado:
<sop schema_version="2.0" id="analisis_seo_trafico" type="diagnostico">
<triggers> ← Cuándo se activa este SOP automáticamente
<trigger>Fluctuaciones inesperadas de tráfico.</trigger>
</triggers>
<prerequisites> ← Qué debe leer y verificar antes de empezar
<rule>SIEMPRE usa max(fecha) como referencia temporal. Nunca system.today().</rule>
</prerequisites>
<phases> ← Los pasos del análisis, en orden
<phase step="1" name="Contexto y Rango de Fechas">
<instruction>Ejecutar revisión de salud de tabla en ClickHouse.</instruction>
<query format="JSONEachRow">
SELECT toMonday(fecha) AS semana, count(DISTINCT fecha) AS dias_con_datos...
</query>
<reasoning>Busca huecos a cero. Notifica si la serie tiene parones.</reasoning>
</phase>
</phases>
<output_schema> ← Nombre del fichero de salida y estructura del informe
<naming_convention>Trafico-{YYYY-MM-DD}-midominio.dev.md</naming_convention>
</output_schema>
</sop>
Ejemplos de plantillas orientadas a tarea por proyecto
La idea es ir mejorando y adaptando a cada proyecto estas plantillas orientadas a tareas específicas, cuanto más, mejor. Esto es solo el comienzo; mi idea es que, por ejemplo, en vez de un análisis técnico "completo", se vaya desglosando en tareas y análisis cuanto más concretos, mejor.
Por ejemplo, tengo una única plantilla para el análisis de los datos estructurados, que no solo comprueba y valida, sino que hace búsquedas en Google para términos potenciales, extrae los datos estructurados de cada uno de los dominios de los resultados y hace una comparación para ver qué tienen los competidores. Además, comprueba cada tipo de resultado en las SERP y, para aquellos resultados con funciones de búsqueda como carruseles, listado de producto o Respuesta IA, accede a los resultados en esos bloques para comprobar si tienen algún tipo de dato estructurado o campo que la URL que le proporciono en la definición de la tarea no tenga.
Algunas plantillas que he creado inicialmente:
| Plantilla | Cuándo se usa | Tipo de salida |
|---|---|---|
analisis-seo-trafico.md |
Variaciones de tráfico, reporting mensual | Trafico-YYYY-MM-DD-dominio.md |
analisis-seo-tecnico.md |
Auditoría técnica, problemas de indexación | Tecnico-YYYY-MM-DD-dominio.md |
comparacion-entornos.md |
QA antes de despliegue a producción | QA-Entornos-YYYY-MM-DD-dominio.md |
doc-structured-data-markup.md |
Revisión de schema.org, rich results | StructuredData-YYYY-MM-DD-dominio.md |
codigo-usado/: comandos usados por el LLM validados
Muchas veces la IA tiene que ejecutar código para realizar la tarea y no hay una herramienta prevista. Esto lo hace muy a menudo, así que los comandos y códigos ejecutados que han funcionado los almaceno con la esperanza de que en un futuro pueda automatizar esas tareas y que el LLM no gaste tokens en código que ya había generado y usado satisfactoriamente en ocasiones pasadas.
Es la memoria operativa del agente entre sesiones. Cada SOP tiene su fichero .sh asociado donde se registran en tiempo real todos los comandos ejecutados durante análisis reales, con timestamp, contexto y resultado.
Formato de cada entrada:
# ==============================================================================
# [2026-04-09] URL PROD: https://www.midominio.dev/es/marca/url-tres-aros-anestesia
# URL DEV: https://dev.midominio.dev/es/marca/url-tres-aros-anestesia
# ==============================================================================
# --- PASO 1a: Render HTML producción (UA Googlebot) ---
./venv/bin/python scripts/render_url.py "https://www.midominio.dev/es/..." \
--user-agent "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" \
2>/dev/null > Proyectos/Ejemplo1/codigo-usado/prod_jeringa.html
# Resultado: 255507 bytes
Reglas del directorio:
- El fichero
.shse nombra con eliddel SOP que lo generó (comparacion_entornos.sh,revision_structured_data.sh) - Los scripts auxiliares específicos de una tarea (
.py,.js) se guardan aquí; los reutilizables entre proyectos van ascripts/en la raíz del workspace - El agente consulta este directorio al inicio de cada tarea antes de construir comandos nuevos
Estos son algunos de los ficheros que ha generado por sí mismo para resolver algún paso. En vez de que siga gastando tokens generando estos scripts cada vez que le solicito que realice una tarea específica, los convierte en nuevas herramientas evitando que el LLM de pago (Claude) tenga que gastar sus tokens en tareas que se repiten una y otra vez.
Los scripts que empiezan siendo específicos de una tarea y acaban siendo útiles en cualquier proyecto se promueven a scripts/ en la raíz del workspace:
| Script | Ubicación | Para qué |
|---|---|---|
extract_product_jsonld.py |
codigo-usado/ |
Extrae bloque JSON-LD por @type de un HTML (específico de tarea) |
extract_microdata.py |
codigo-usado/ |
Extrae valores itemprop de marcado Microdata (específico de tarea) |
parse_schemas.py |
scripts/ |
Lista todos los schemas JSON-LD y Microdata de una página |
validate_jsonld.py |
scripts/ |
Valida campos requeridos por Google sin necesidad de internet |
check_rich_results_test.py |
scripts/ |
Comprueba el marcado en Google Rich Results Test y validator.schema.org vía Playwright |
tareas.json
Sistema ligero de gestión de tareas que permite coordinar trabajo entre sesiones y con herramientas externas (dashboards, scripts de automatización).
{
"pendientes": [
{
"id": "TSK-BIJXFZ",
"texto": "Desarrollar App",
"asignado": "agente",
"id_padre": null,
"fecha": "2026-04-08T15:14:15.136Z"
}
],
"completadas": [...],
"cambios": [...]
}
El agente puede leer este fichero al inicio de una sesión para saber qué tiene pendiente, marcar tareas como completadas y añadir subtareas generadas durante el análisis.
fallos-sql-correcciones.md:
Los LLMs repiten los mismos errores en queries SQL cuando no hay feedback explícito. Este fichero registra los errores reales que ocurrieron durante el análisis, con el comando fallido, el mensaje de error exacto, la causa raíz y la corrección verificada que funciona.
Ejemplo real:
## FALLO 1 — Alias que sombrea nombre de columna en CTR calculado
**Comando fallido:**
SELECT sum(clicks) AS clicks, round(sum(clicks) * 100.0 / sum(impresiones), 2) AS ctr...
**Error:**
Code: 184. DB::Exception: Aggregate function sum(clicks) AS clicks is found inside
another aggregate function in query.
**Causa:** ClickHouse 26.x interpreta el alias `clicks` como referencia circular
cuando sombrea la columna del mismo nombre dentro de la misma cláusula SELECT.
**Corrección:** calcular los agregados en una subquery y hacer la aritmética en
el SELECT exterior.
Por qué es imprescindible: sin este registro, el agente cometería el mismo error en cada sesión nueva. ClickHouse tiene comportamientos específicos de versión que no están en el conocimiento de entrenamiento del modelo. Este fichero es la memoria de los errores que no deben repetirse.
informes/: las salidas persistidas
Todo análisis concluido se guarda aquí con nombre canónico. El agente no arroja las salidas al chat: las persiste en ficheros Markdown con estructura fija.
Convención de nombres:
<Tipo>-<YYYY-MM-DD>-<dominio>.md
Trafico-2026-04-08-midominio.dev.md
Tecnico-2026-04-08-midominio.dev.md
QA-Entornos-2026-04-09-midominio.dev.md
StructuredData-2026-04-09-midominio.dev.md
Esto permite:
- Búsqueda rápida por fecha o tipo (
ls informes/QA-*) - Comparar evolución entre fechas (
diff informes/Trafico-2026-03.md informes/Trafico-2026-04.md) - Referencia en análisis posteriores sin regenerar
Artículos en Arquitectura de agentes para SEO
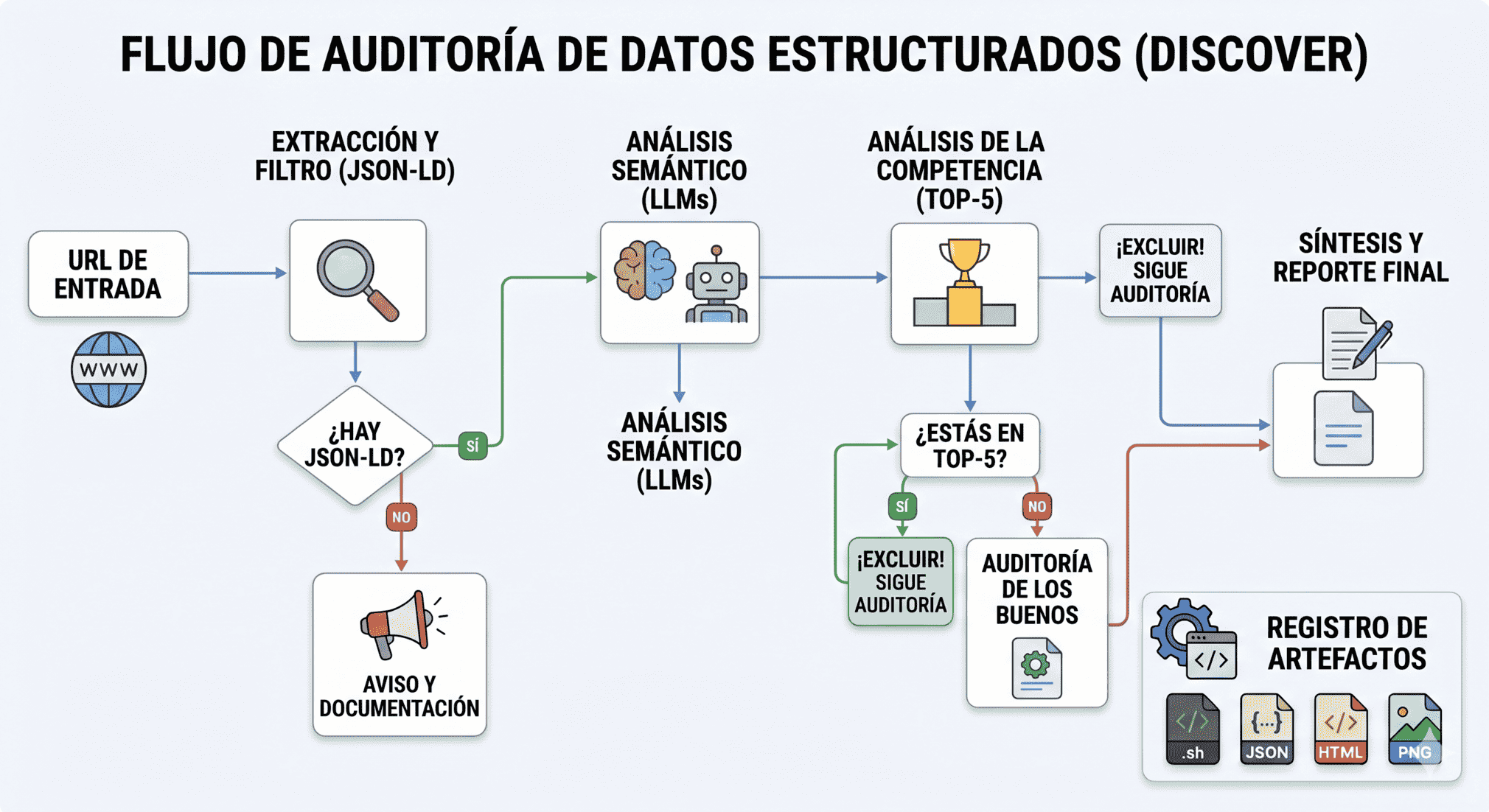
2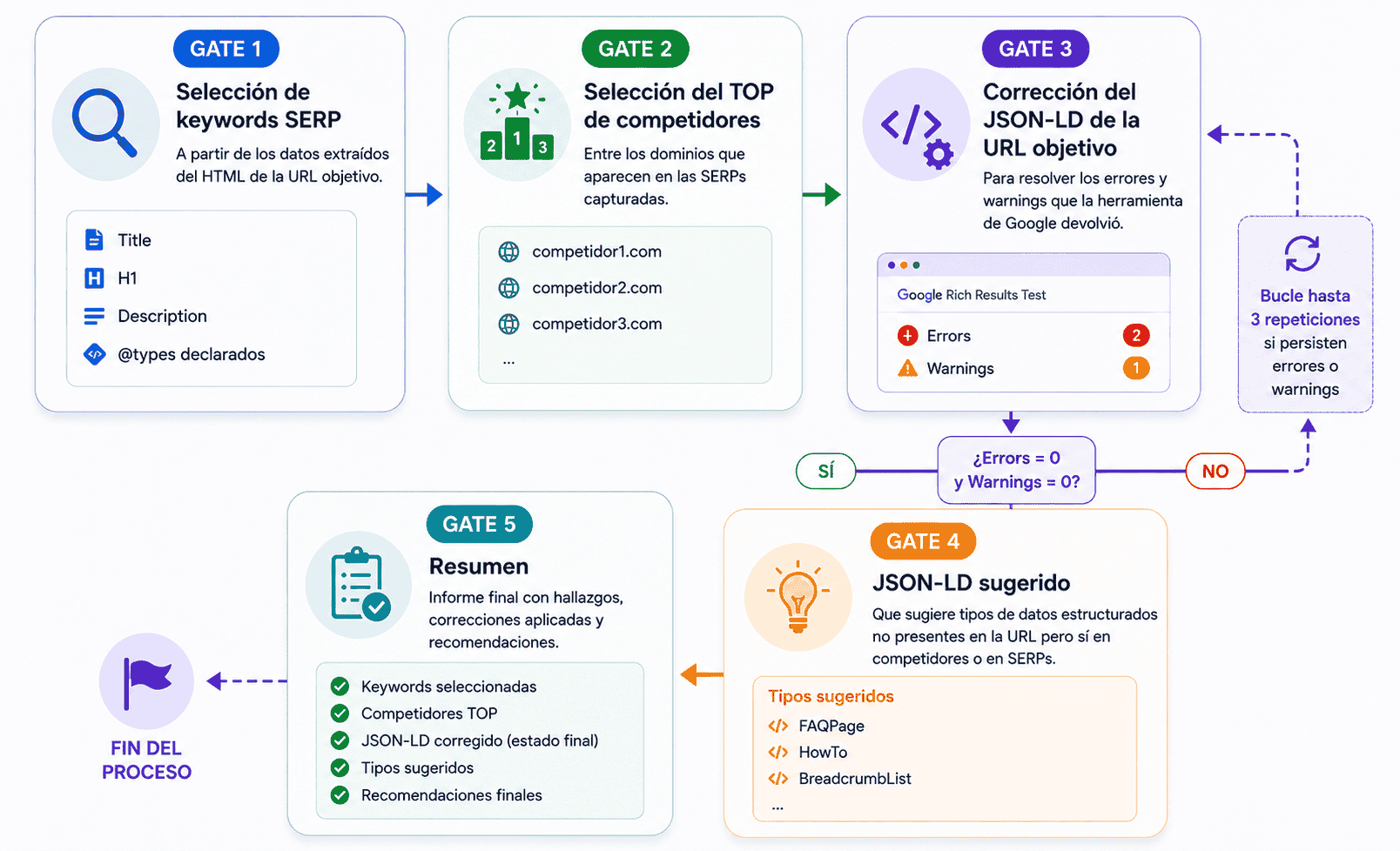
Separar lógica determinista y decisiones LLM
Cómo pasé de una skill de Claude Code de 2.000 líneas a un pipeline reproducible para auditorías SEO con LLMs, reduciendo el coste de 8-10 € a menos de 2 € por ejecución.
Orquestando subagentes y LLMs locales para validar datos estructurados
Cómo funciona por dentro un agente SEO de IA para analizar datos estructurados: desde la extracción con JS hasta la validación con LLMs y comparativa con el TOP 3.
Comentarios
Todavía no hay comentarios publicados.