Meta etiqueta noindex
¿Qué es el noindex?
El meta noindex sirve para indicar a los buscadores que la URL rastreada no debe ser indexada. Se configura utilizando una etiqueta <meta> entre '<head>' y '</head>' o en las cabeceras HTTP de la URL.
Ejemplo de uso del meta robots noindex
<meta name="googlebot" content="noindex" />
Posibles valores para el meta robots
La metaetiqueta "robots" es una directiva, por lo que Google la cumplirá siempre (igual que hace con el robots.txt). Pero esto no impide que Google acceda y rastree esta URL, aunque no la muestre en los resultados.
Analizando los logs del servidor podemos comprobar que Google sigue accediendo a estas URLs si sigue recibiendo enlaces, ya sean externos o internos, o si sigue añadida al sitemaps.
En la siguiente tabla verás todas las directivas que Google reconoce para el meta robots.
| Valores |
Significado |
| all | No hay restricciones de indexación ni de presentación de contenido. Nota: Esta directiva es el valor predeterminado y no tiene ningún efecto si se muestra de forma explícita. |
| noindex | No se muestra ni esta página ni un enlace "en caché" en los resultados de búsqueda. |
| nofollow | No se siguen los enlaces de esta página. |
| none | Equivalente a noindex, nofollow. |
| noarchive | No se muestra ningún enlace "en caché" en los resultados de búsqueda. |
| nosnippet | No se muestra ningún fragmento en los resultados de búsqueda de esta página. |
| noodp | No se utilizan metadatos del proyecto de Open Directory para los títulos o los fragmentos que se muestran en esta página. |
| notranslate | No se ofrece una traducción de esta página en los resultados de búsqueda. |
| noimageindex | No se indexan las imágenes de esta página. |
| unavailable_after | No se muestra esta página en los resultados de búsqueda después de la fecha y la hora especificadas. La fecha y la hora deben especificarse en el formato RFC 850. |
¿A que buscadores afecta el noindex?
El meta noindex se puede configurar para todos los bots o rastreadores, por ejemplo;
<meta name="robots" content="noindex" />
Este meta indica a todos los bots de buscadores y otros rastreadores que está url no debe ser mostrada en los resultados de búsqueda.
Configurar meta noindex solo para Google
También se puede definir para un bot en concreto, poniendo en el atributo "name" el nombre de ese bot o rastreador
Por ejemplo la siguiente línea le dirá a Google (pero no a otros buscadores) que está url no debe ser mostrada en los resultados de búsqueda de Google.
<meta name="googlebot" content="noindex" />
Meta robots Noindex Follow
El meta robots con valor "noindex, follow" es uno de los metas más usados por los SEOs. El valor "noindex" le indica a Google que no puede mostrarlo en los resultados de búsqueda, y el valor "follow" indica a Google que siga los enlaces que hay en el contenido de esa url.
Se suele usar en estos casos:
- Cuándo tenemos contenido de poco valor (Thin content)
Por ejemplo es habitual verlo en filtros de poco valor, que no generan apenas diferenciación, o en urls con contenido generado por los usuarios y que se cree que es de baja calidad
- Cuándo ese contenido es duplicado
Aunque en este segundo caso se suele usar meta canonical, hay casos en los que no se sabe la url homóloga donde apuntaría ese canonical y para evitar una posible baja valoración del contenido de esa urls por parte de Google se usa el meta robots noindex.
¿Para qué sirve y para qué NO sirve el meta noindex?
Una de las crencias más difundidas sobre el meta noindex es que al ponerlo Google accederá menos o no accederá a urls que contengan el meta robots noindex, y que por ello mejorará el crawl budget o frecuencia de rastreo, pero cómo vamos a ver a continuación no ocurre esto.
Hace poco tiempo, desupués de una subida a producción de un site,
se subió sin querer la home del site con un meta noindex, vamos a tratar
de analizar este caso e intentar sacar algunas conclusiones.
- El meta robots noindex sí impide que la url se muestre en los resultados de búsqueda
El tener este meta impedirá que salga en las serps de Google, lo que es lo mismo impedirá que tenga tráfico orgánico desde resultados normales, es decir, sin contar resultados de imágenes por ejemplo.
Cómo vemos en la siguiente gráfica el tráfico orgánico proveniente de Google descendió casi a cero.
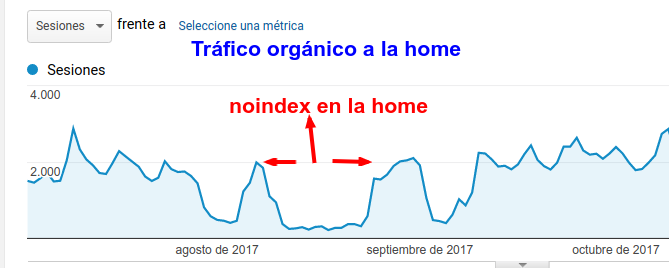
El tráfico que aun llegaba podría ser por búsquedad de imágenes, ya que el meta noindex no indica que las imágenes que haya en esa url no sean indexadas.
Posiblemente las otras dos crestas, anterior y posterior al periodo indicado por las flechas, también hubiese ocurrido el subir a producción la home con el meta noindex, pero no puedo asegurarlo.
- El meta robots noindex NO impide el acceso de Google a estasurls
La siguiente gráfica son los accesos diarios de Googlebot a la url de la home, cómo vemos, durante ese perioro de tiempo Google siguió accediendo a esa url, y con una frecuancia similar a cuándo no lo tenía.

Por lo que podríamos decir (al menos en este caso) que el meta noindex no impide el acceso de Google a estas urls, y tampoco se aprecia que reduzca su frecuencia de acceso, por lo que no nos vale para mejorar nuestro crawl budget.
Casos de uso del meta robot="noindex"
Viendo cómo actua Google, ¿dónde y cuándo debemos usar el meta noindex?. Siempre digo que los metas como el noindex o el meta canonical son parches que usamos para solucionar algún problema detectado o un posible problema, pero realmente en una web ideal no deberíamos tener que usarlos.
Dicho esto, muchas veces no nos queda más remedio que usar estos parches metas para minimizar un error de arquitectura de la información o arquitectura web, y debemos enviar señales a Google para indicarle determinadas cosas como que un contenido es igual a otro.
¿Cuándo usar el meta noindex?
En el caso del meta noindex los casos para los que yo lo usaría serían los siguientes;- No quiero que una url sea mostrada en Google.
Podría ser por cuestiones de derechos de autor, o por privacidad de usuarios o por otras cuestiones.
Para esto es esencialmente este meta, para indicar a Google y otros buscadores que no muestren esta url y su contenido en los resultados del buscador.
- Contenido de baja calidad que no queremos que Google indexe y valore.
Hemos visto antes que realmente Google accederá, y posiblementer evalue el contenido que en la url encuentre, por lo que no es una solución optima ya que no sabemos si Google lo evaluará o no, y en el caso de evaluarlo no sabemos si tener el meta noindex en contenido que sea thin content evitará o no el contagio al resto del dominio. Pero a veces no tenemos más alternativas que realizar esto.
Por ejemplo si tenenmos un site en el que determinado contenido es creado por los usuarios, y hay algún contenido de usuarios que sí proporciona valor (por ejemplo si contiene más de 100 palabras) y otro que no (por ejemplo si NO contiene más de 100 palabras) .
Si tenemos este escenario posiblemente no podremos crear una regla por robots.txt para impedir el acceso a estas urls, ya queremos que acceda o no según determinadas variables entorno al contenido introducido por el usuario y no en base a un patrón de urls.
En este caso el poner noindex en contenido calificado de baja calidad, que conenga menos de 100 palabras, en muchas urls podría salvarnos de que Googe nos valore nuestro site como de baja calidad al tener muchas urls de baja calidad, pero de esto no estamos seguros, aunque por si acaso, ¿por qué no ponerlo?.
¿Cuándo NO usar el meta noindex?
Hay casos en los que no creo que se deba usar este meta pero que veo a menudo utilizar a muchos SEOs.
- Contenido parcial o duplicado de otra url
Para este caso tendríamos el meta canonical o una redirección 301. Si la causa es la duplicidad del contenido el noindex no será la solución idónea ya que lo único que parece hacer es impedir salir en los resultados orgánicos del buscador, y no tenemos certeza que valga para evitar que Google califique como thin content estas urls.
- URLsde baja calidad que no queremos indexar
Pongamos por ejemplo que tenemos diferentes filtros para un listado, unos filtros son potenciales y diferenciales y los quermos indexar pero otros no lo son y no queremos indexarlos.
Si los filtros que no queremos indexar tienen un patrón en la url creo que es mucho mejor impedir el acceso a los buscadores mediante el robots.txt que usar el meta noindex por las siguientes razones
- Nos aseguramos que Google no accede al contenido, por lo que
mejora la frecuencia de rastreo del resto de urls que sí creemos
potenciales y sí queremos que Google las rastree.
- Nos aseguramos que Google no valora el contenido de esa url, y así
evitar que Google califique esas urls, y puede que otras también por
contagio, como de thin content.
- Nos aseguramos que Google no accede al contenido, por lo que
mejora la frecuencia de rastreo del resto de urls que sí creemos
potenciales y sí queremos que Google las rastree.
- Si queremos evitar que no se indexen las imágenes que hay en estas urls
El meta robots name="noindex" no impide que Google acceda, indexe y muestre las imágenes en sus resultados. El meta noindex impide que se muestre la url donde aparece el meta noindex, pero no sus imágenes.
Conclusiones
Hemos visto algunos aspectos que yo creo importantes sobre el meta noindex, y de los cuales saco estas conclusiones
- El meta noindex impide que la url salga en los resultados de los buscadores.
Es su cometido, para esto se creó esta directiva, y como directiva los buscadores (o la mayoría de ellos) lo cumplen.
- El meta noindex no impide el acceso a esa url por parte de Google ni otros buscadores.
Google y otros buscadores, accederán a urls que contengan el noindex.
- El meta noindex no varia la frecuencia de rastreo para las urls que lo llevan.
Como hemos visto, en este caso, Google no varia su frecuencia de rastreo hacia esta url.
Se podría pensar que quizás con esta url (la url de la home) no varie la frecuencia de rastreo porque esta url es la home y recibe una gran cantidad de enalces tanto internos como externnos.
Podria ser, pero eso querría decir que la frecuencia con que Google visita una url no depende del meta noindex, o al menos no depende solo del meta noindex, sino de otros factores.
Yo me atrevería a decir que depende del número de enlaces entrantes tanto internos como externos y la autoridad de estos.
- El meta noindex no impide que se muestren las imágenes en los resultados
Posiblemente haya más casos creais que se debería usar el noindex, y también haya más casos para los que no usariais el meta noindex, comantar cuáles son para vosotros esos otros casos e iremos actualizando a lista sobre cuándo usar y cuándo no usar el meta noindex.
Comentarios
8Artículos en Meta etiqueta noindex
6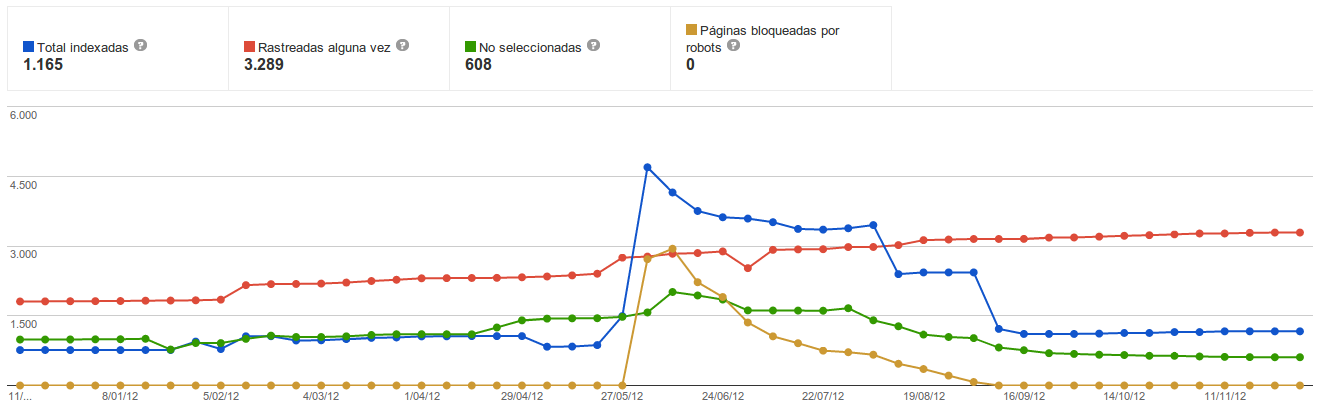
Diferencias entre url indexada y url accesible
Publicado el 18 de marzo del 2019 por Lino Uruñuela Siempre ha habido debates sobre cómo indexar urls en Google, ¿cuántas urls tiene Google indexadas de mi web ? ¿cuántas urls crawleadas tiene mi site? ¿es mejor usar el robots.txt o es mejor usar el meta noindex para no indexar determinadas urls?.... el debate continu…
Resultados del experimento con meta noindex
Publicado el 24 de marzo del 2013 El otro día hicimos un experimento para ver cómo se compartaba Google ante una url con el meta noindex . Los objetivos eran dos: Saber si Google accede a esa URL Saber si Google indexa y almacena el contenido de esa URL Saber si Google rastrea los enlacecs que hay en ella (este test y…

¿Cómo trata Google el meta noindex? -- Round 3
Publicado el 16 de marzo del 2013 by Lino Uruñuela Hoy voy a tratar de enterder cómo funciona Google con el meta noindex. Según Google este meta noindex es tratado de la siguiente manera Si Google detecta una metaetiqueta "noindex" en una página, elimina la página por completo de los resultados de búsqueda , incluso e…
¿Cómo valora google una url con meta noindex y canonical?
Publicado el 27 de julio del 2012 Ya era hora! después de no sé cuánto tiempo vuelvo a escribir un post! Espero poder cumplir mi promesa de principios de año de escribir dos por semana, creo que ya me he cargado las pilas otra vez. Esta vez voy a hacer un test un poco irrelevante pero que últimamente me han preguntado…

¿Contará Google el texto de los enlaces en páginas con noindex/follow?
Publicao el 22 de agosto del 2010 El otro día discutíamos en twitter José B. Moreno , Carlos Redondo , Javier Ortiz , Aina Lluna y yo sobre cuando usar la meta canonical y si sería mejor usar el meta noindex/follow para contenidos que a Google le pudiese parecer duplicados, como por ejemplo distintos tipos de listados…
Google se salta el noindex nofollow
Publicado el 28 de noviembre del 2008 Google está haciendo caso omiso a la etiqueta < meta name = "robots" content = "noindex,nofollow" / > Tengo páginas que tienen esa etiqueta pero sí las está mostrando en caché, o sea, que sí las está indexando. Esto en mi caso particular me podría traer muchos problemas ya q…
Kaixo Lino! Habría que ver si baja la frecuencia de rastreo en otras urls que no fuesen la home, muy difícil de medir por cierto. Por otro lado sobre si valora el contenido o no, diría que no, pero quien sabe.
@javier Lorente Aupa Javi, en algún proyecto en el que he aplicado el noindex y que podía analizar los accesos del bot (tenina cierto patrón en a url) la verdad que no vi cambios, pero podría ser que si Google tuviese pocas señales sobre una url y encima la pones noindex quizás rastrea con menos frecuencia. Pero sinceramente, creo que el meta no lo tiene en cuenta para acceder más o menos, y que la frecuencia con la que accede a una url depende sobretodo de dos cosas; 1) La cantidad de enlaces entrantes que tenga esa url. 2) La frecuencia con la que la url actualiza su contenido. Si tienes algún proyecto en el que se pudiese analizar porque tiene patrón de url y tienes acceso a los logs lo miramos si quieres :)
Hola Lino! Te leo desde hace algún tiempo (genial el cambio de look) y casualmente he venido aquí con una duda sobre indexación. Lo que comentas es muy interesante, y lo cierto es que el tema de crawl budget es digno de estudio y gracias a tus artículos creo que queda ayuda a la comunidad a conocerlo más, sobre todo como trabajar bien a nivel técnico. Mi pregunta es la siguiente... Dentro de un mismo artículo o entrada podemos hacer que no se indexe parte del artículo? Por ejemplo al primer párrafo Google puede acceder a los dos siguientes no y al último si. No se si me explico bien pero creo que viendo el nivel técnico que manejas seguro que sabrás como resolverlo jeje. Como el tema de enmascarar enlaces ;) que ayuda mucho. Un saludo y muchas gracias de antemano
Buenas Lino Mecagoenlos! (vaya apellido tienes...) Tu artículo me ha dado mucho que pensar... acaban de hacerme una web en una agencia y basicamente lo han hecho todo con javascript. De esta manera, si miro la web en cache (sólo texto) la página aparece totalmente en blanco... ¿significa eso que google no está viendo el contenido en texto y no lo posicionará? si eso fuera así, cosa que obviamente no quiero...pienso... ¿podría ponerse texto con javascript en páginas con contenido parcialmente duplicado para no poner canonicals ni nada de eso y evitar penalizaciones? Saludos y gracias de anteamno! Soy un reciente suscriptor de tu blog desde que te vi en el video de ofuscación de enlaces de Luís :)
@Alex R , lo primero graciias por a ti por participar :) Sobre tu prebunta ¿Dentro de un mismo artículo o entrada podemos hacer que no se indexe parte del artículo? creo que no existe ningún protocolo o señal para indicar al buscador que no indexe o que no muestre un fragmento o parte del contenido. Solo conozco el la opción de no traducir un fragmento del contenido, usando class="notranslate" por ejemplo así <span class="notranslate">Este es el texto que no se deberá traducir cuándo usemos el traductor de Google para ver este site en otro idioma</span>, <a href="https://webmasters.googleblog.com/2008/10/helping-you-break-language-barrier.html">aquí tienes más documentación sobre esta clase.</a> Alternatiivas, como bien intuyes, existen, pero a menos que sea por alguna casusa muy concreta y crítica no sé si merecería la pena hacerla.... A botepronto decirte que no es algo fácil, la única manera que se puede conseguir es que Google no lo vea, y para ello solo se me ocurre la opción de hacerlo con JavaScript, pero recuerda que según el experimento que hicimos, <a href="http://www.mecagoenlos.com/Posicionamiento/interpreta-google-el-javascript.php">Google sí verá el conenido cargado mediante javascript si se realiza esa carga en el onReady o en el onLoad</a> por muy ouscado que esté. Es decir, debemos cargar ese contenido con alguna interacción del usuario como por ejemplo hacer scroll, mover el ratón, o hacer click, es decir, al detectar un evento mediante javascript, porque si no Google sí lo verá y lo valorarará cómo parte del contenido del site. Si en tu web se carga el texto mediante javascript, pero esto ocurre "automáticamente" por llamarlo así, Google lo verá. Puedes hacer una prueba buscando entrecomillas ese texto que cargas con javascript para ver si sale en las serps de Google, y avisa con lo que ocurra ;)
Hola @Javier repondiendo a tu pregunta "¿significa eso que google no está viendo el contenido en texto y no lo posicionará?" con el mismo argumento que a Alex te digo que si en tu web se carga el texto mediante javascript, pero esto ocurre "automáticamente" por llamarlo así, Google sí lo verá, y lo valorará cómo contenido de esa url. Puedes hacer una prueba buscando entrecomillas ese texto que cargas con javascript para ver si sale en las serps de Google, y avisa con lo que ocurra ;) "si eso fuera así, cosa que obviamente no quiero...pienso... ¿podría ponerse texto con javascript en páginas con contenido parcialmente duplicado para no poner canonicals ni nada de eso y evitar penalizaciones? " No creo que sea válido ya que no veo la manera en la que haciendo eso, suponiendo que Google no lo viese, se podría corregir el que una url tenga el mismo contenido que otra. ¿No? o quizás no te haya entiendido bien :s
Bueenas Lino! Gracias por tu respuesta! Efectivamente, cogiendo texto de una página hecha con javascript y poniéndolo en Google entre comillas me sale la url que lo contiene. No así en Bing, he leído que Bing no es capaz aún de leer texto en javascripts, no sé si ese post estaba desactualizado y esto se debe a otro motivo... porque poniendo en bing "site:mipagina.com" no me sale más que la home... Con mi segunda pregunta me refería a que en un ecommerce por ejemplo. El apartado "telas disponibles" es igual para todos los productos (un texto de 300 palabras repetido en todas las fichas) pero el resto de la ficha de producto es un texto único. según lo que mencionas en tu respuesta a Alex entiendo que se podría poner ese contenido duplicado con javascript y cargarlo cuando el usuario hace scroll para evitar que Google lo vea. Muchas gracias por la ayuda!
Siempre sospeché de https://www.seroundtable.com/amp/google-long-term-noindex-follow-24990.html tiene toda la lógica. En alguno de tus experimentos Lino mantuviste el noindex períodos de más de 6 meses?