Extracción y comparación de pasajes con IA en Google Chrome
El otro día os comentaba cómo estaba usando la IA para mi día a día como SEO, hoy os quiero compartir otro ejemplo de cómo podemos obtener valor al realizar cosas que hace dos años las habría descartado por ser demasiado laboriosas en cuanto a programación.
IA integrada en el navegador (de momento de Google Chrome)
Creo que no se le está dando la suficiente importancia a la integración de LLMs en el propio navegador, me refiero concretamente a la integración que Google está haciendo de las versiones más pequeñas de sus modelos Gemini y que ya podemos ejecutar desde el navegador como otras APIs.
En el artículo que escribí el otro día sobre la extensión aNotame, que usa IA en varias funcionalidades como traducir y resumir el contenido de una página web expliqué cómo estaba practicando / probando / aprendiendo qué se puede hacer con estas integraciones de Gemini en el navegador web.
Podéis instalar y probar la extensión a la que he añadido algunas mejoras como poder usar un prompt personalizado o añadir el contenido que quieras usar como contexto, pero no quiero enredarme ahora con las distintas opciones de la extensión, podéis instalarla y probarla instalándola en Chrome.
Como venía diciendo, hoy quería enseñaros otra extensión que estoy creando, en la que uso Prompt API, que permite usar IA directamente en el navegador gracias a algún modelo Gemini preparado especialmente para Google Chrome.
Prompt API está habilitado para versiones de Chrome 138 o superiores y tiene la limitación de que solo se puede usar, de momento, desde extensiones. No se puede usar como se usa actualmente otras APIs que se invocan desde el código JavaScript devuelto por una página web al cliente, por ejemplo Storage API para guardar datos o chrome.notifications para mostrar notificaciones,
Supongo que solo se permite a través de las extensiones por motivos de seguridad, porque los posibles usos que le podamos dar a IA que se ejecuta directamente en el navegador son inescrutables, tanto para bien como para mal.
Respuestas generadas por IA mediante diferentes "pasajes"
Los pasajes suelen ser fragmentos de texto que tienen un significado por sí mismos sin necesidad de otro contexto.
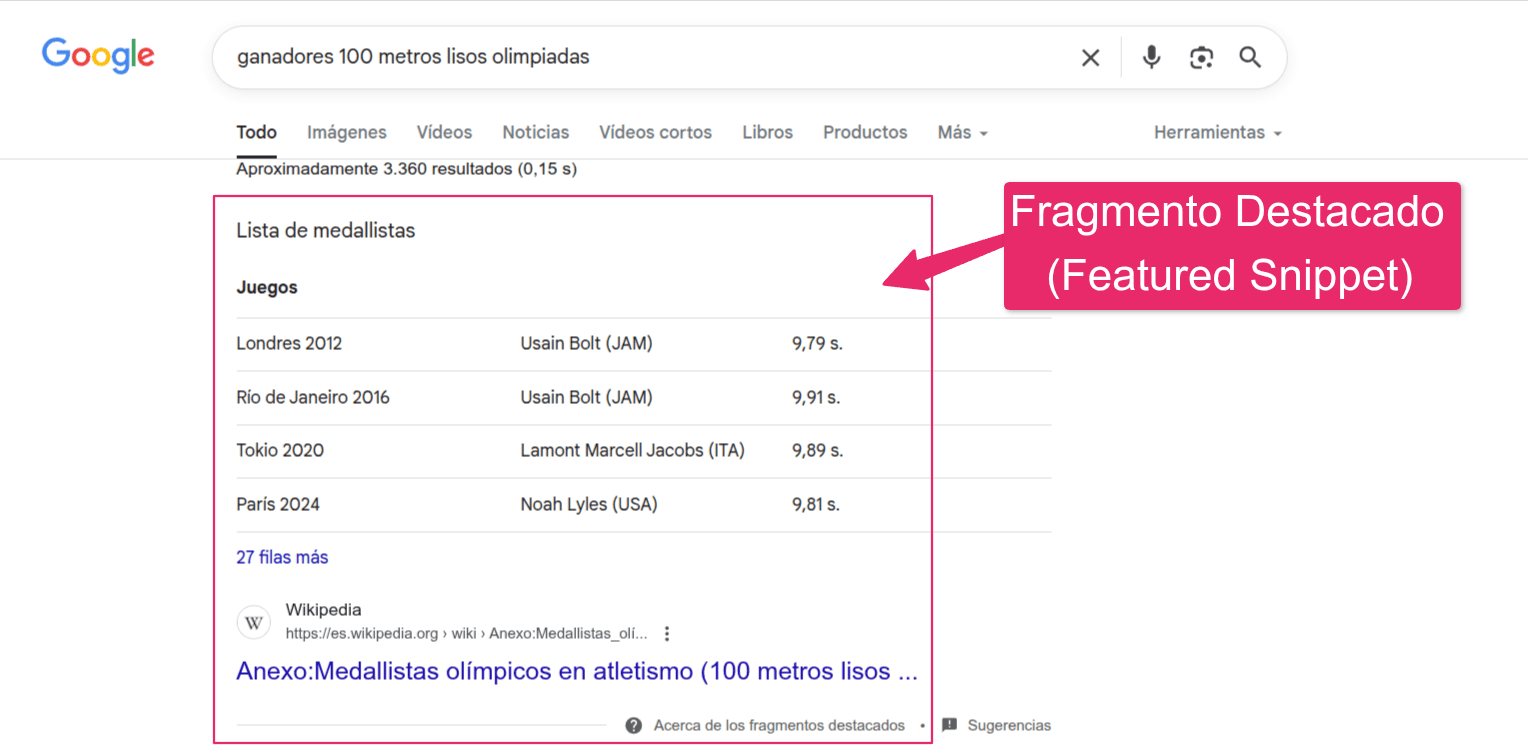
En el ámbito SEO tenemos desde hace tiempo "resultados enriquecidos" o "rich snippets" y pueden ser de muchos tipos, uno de ellos son los "fragmentos destacados" o "featured snippets" que habitualmente responden directamente a la consulta del usuario, no solo con una frase sino que hay de varios tipos, como en el siguiente ejemplo donde se muestra una tabla para mostrar la información.
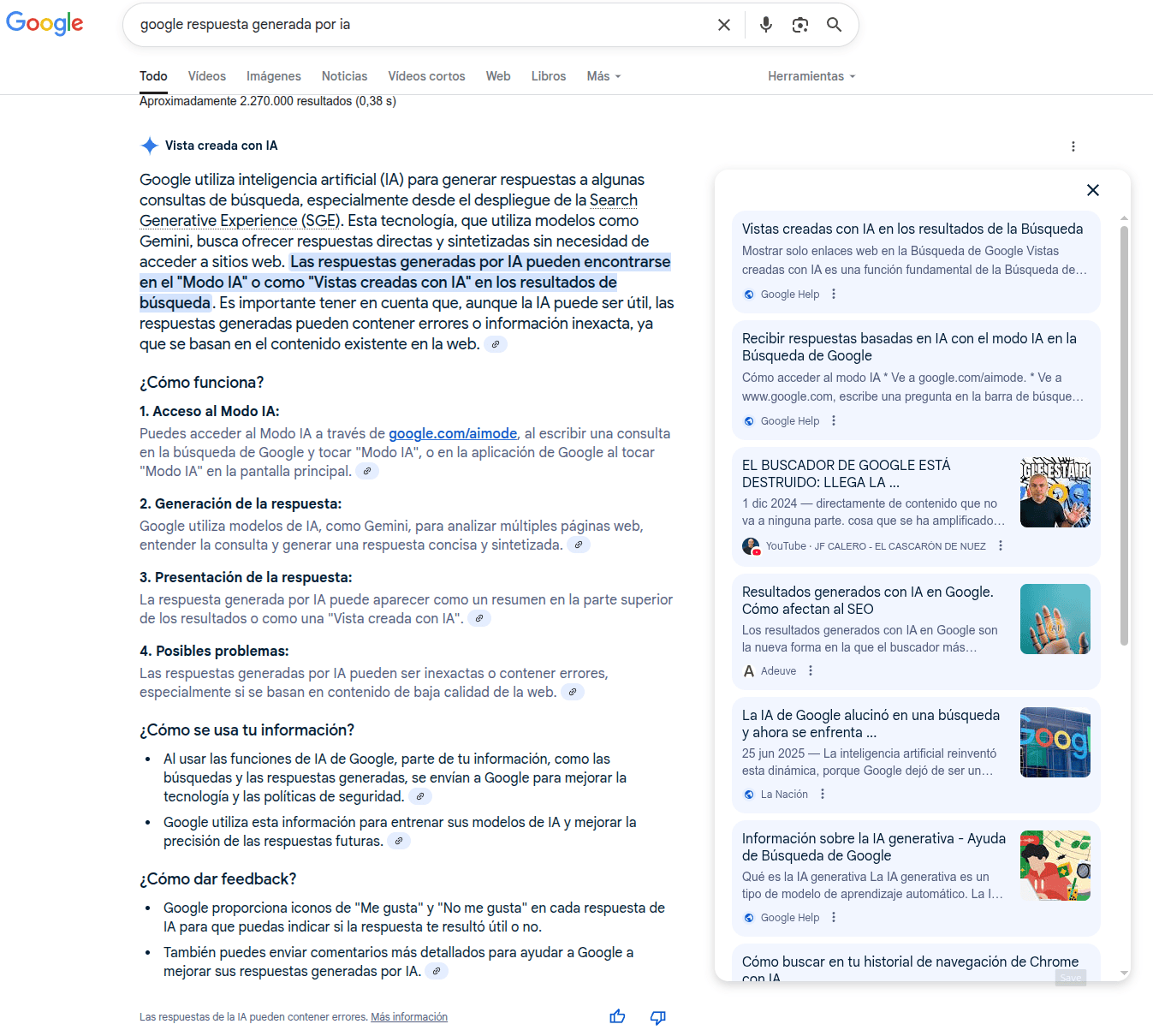
Desde hace unos meses Google también muestra otro tipo de resultado las "AI Overviews" o "Vista creada con IA" que se componen básicamente de diferentes fragmentos de texto obtenidos, normalmente, de los resultados principales de una búsqueda para generar una respuesta completa.
Como SEOs nuestro objetivo es mejorar la visibilidad de nuestra web para lograr aparecer en estas vistas creadas con IA
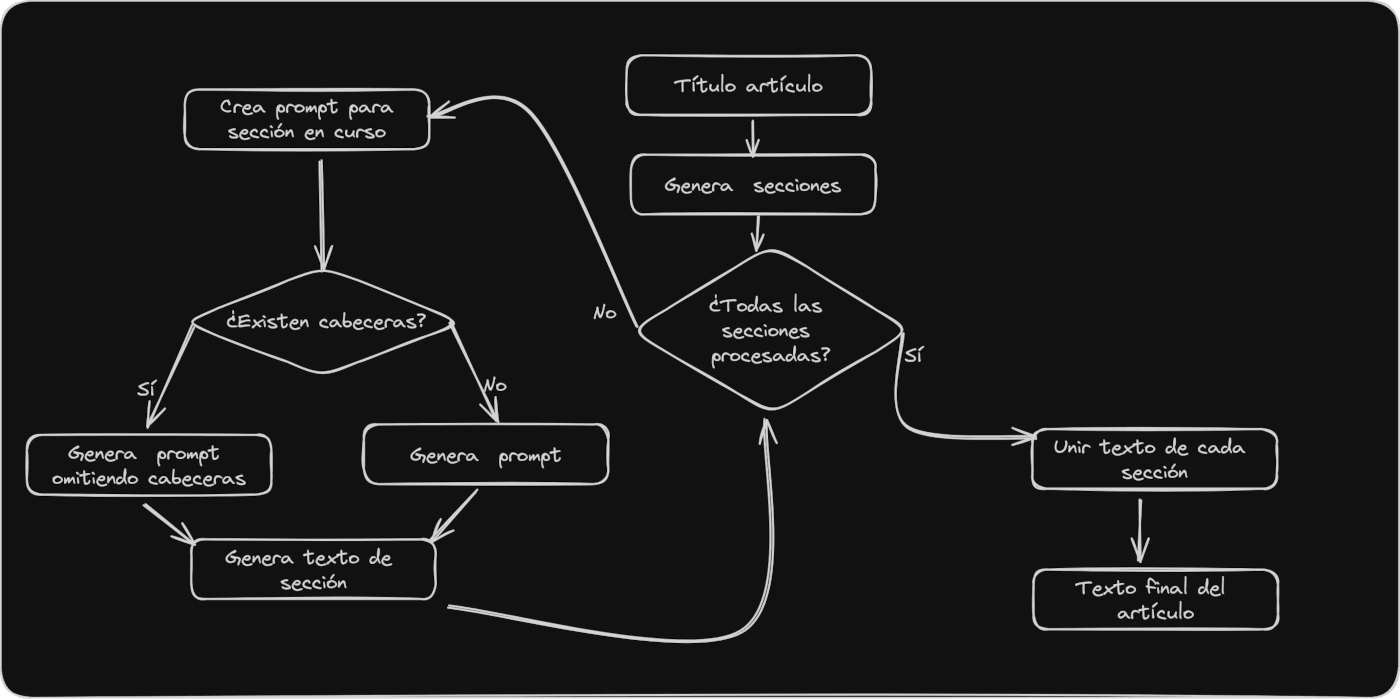
Cómo obtener pasajes relevantes usando IA
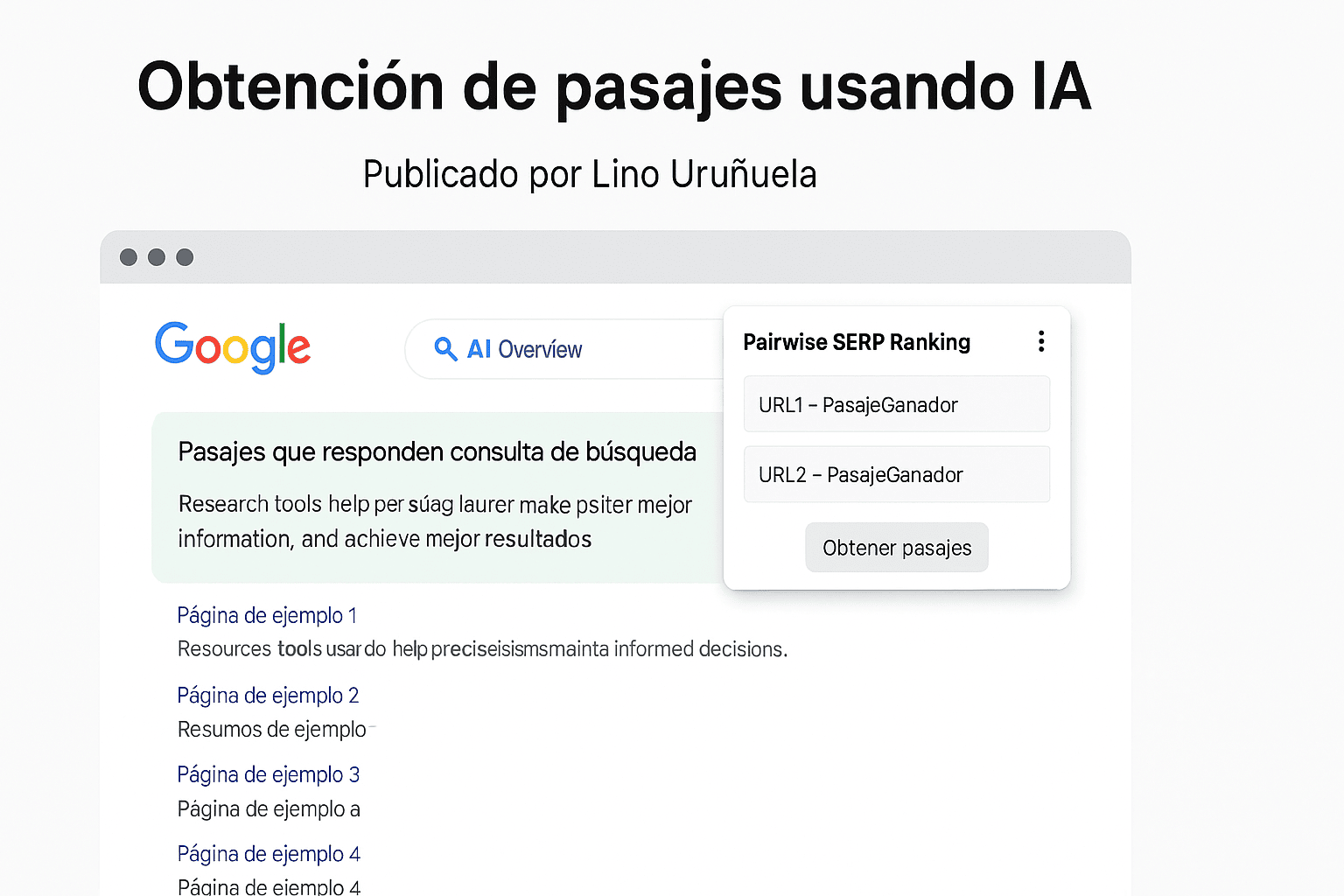
Con la nueva extensión que estoy creando y que he llamado 'Pairwise Passage Ranking' y extraigo fragmentos de texto del contenido de las URLs mostradas en los resultados de Google.
Para obtener los pasajes y no morir en el intento lo ideal es obtener el texto del contenido de la URL, digo texto y no código HTML porque el código HTML completo de una URL normalmente es tan extenso que supera el límite máximo de entrada del LLM usado en Chrome, 8.000 caracteres a día de hoy,
Se pueden idear estrategias, como las que uso en la extensión de aNotame, donde divido el texto cuando tiene más de 8.000 caracteres y voy solicitando "cacho" a "cacho" al LLM que ejecute el prompt que corresponda pero la forma ideal de hacerlo es procesar únicamente el texto del contenido principal de la página.
Extracción del contenido principal de un documento HTML
Para extraer el contenido principal de un documento HTML realizo algunas técnicas básicas como intentar eliminar elementos HTML que no suelen ser el contenido del artículo en sí mismo, por ejemplo la barra de navegación, breadcrumbs, enlaces del footer, scripts y otros elementos HTML que, a priori, suelen ser significativamente menos importantes.
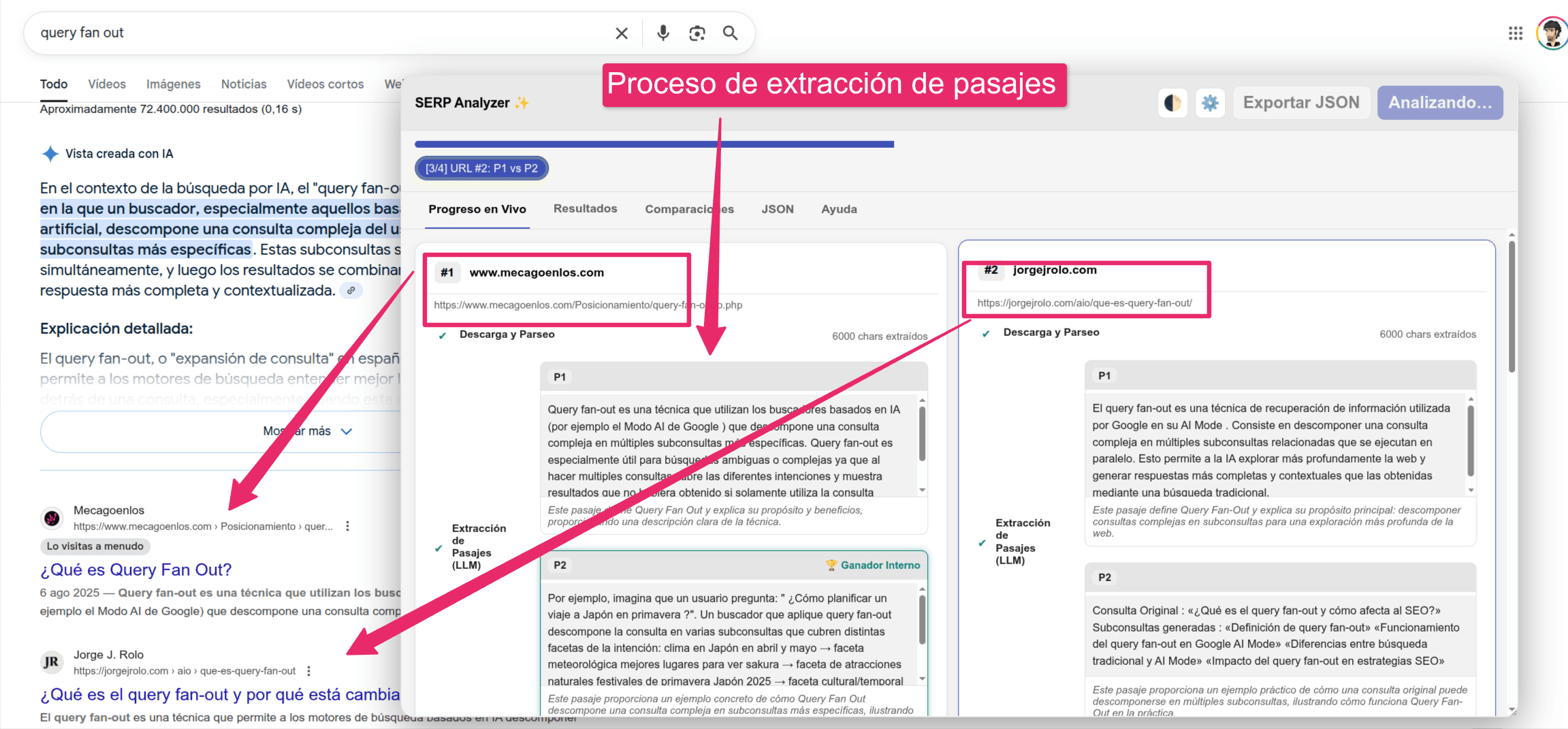
Una vez tenemos el contenido principal de cada resultado vamos a usar la IA integrada en el navegador Chrome para extraer un número n de pasajes de cada resultado, por defecto lo he configurado en 2 pasajes,
Pasajes que responden consulta de búsqueda, AI Overviews
Queremos extraer el pasaje que mejor responda a la búsqueda que hayamos hecho en Google, ya que dependiendo de la búsqueda que hagamos serán unos y otros pasajes los que mejor responden a la intención de esa búsqueda concreta. Por lo tanto, para cada resultado en las SERPs de Google:
- Accedemos a cada resultado
- Obtenemos el contenido principal de esa URL
- Pedimos al LLM embebido en Chrome que extraiga los n pasajes que mejor responden a la pregunta.
Pairwise Passage Ranking
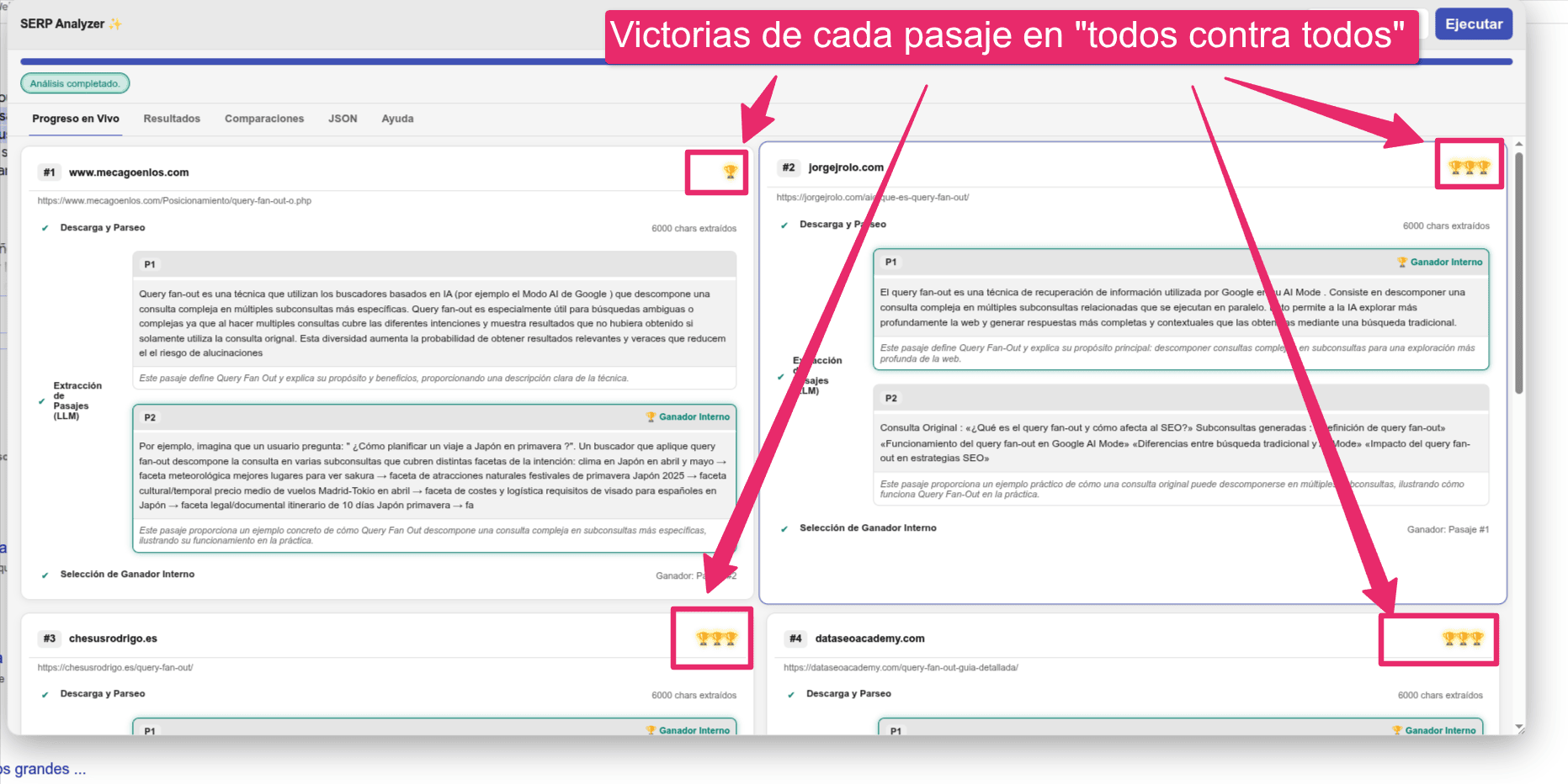
Una vez tenemos los pasajes de cada resultado, vamos a hacerlos competir entre ellos para intentar averiguar cuál es el mejor de todos respondiendo a la búsqueda del usuario. Actualmente, CREO, que a la hora de ordenar un listado usando un LLM como juez, la comparación por pares (pairwise) es uno de los métodos que mejor funcionan.
En la comparación por pares se le pide al LLM (el juez) que evalúe dos pasajes, preguntando cuál responde mejor a la consulta de búsqueda. Podríamos tener la tentación de pasarle todos los pasajes y que nos devuelva una lista de pasajes ordenada de mayor a menor relevancia.
Pero los LLMs no son buenos ordenando listas de resultados, en cambio, a la IA se le da mucho mejor comparar y decir cuál es mejor que otro, así que vamos a comparar todos los pasajes unos con otros e ir creando una lista ordenada en base a "victorias" entre las diferentes comparaciones.
Antes de comparar los pasajes de cada resultado vamos a seleccionar el ganador de entre los pasajes extraídos de una misma URL. Preguntamos cuál responde mejor la consulta del usuario y al ganador le sumamos un punto de victoria, por ejemplo, de la URL1 hemos obtenido URL1- Pasaje1 y URL1- Pasaje2 y le preguntamos al LLM ¿Cuál de estos dos pasajes responde mejor a la {query}? (la kw que has realizado en Google).
Comparación por pares
Ahora ya tenemos un pasaje ganador por cada resultado en las serps, y lo que vamos a hacer es comparar unos con otros (por pares) para saber cuál es el mejor. Para ello comparamos
- URL1- PasajeGanador Vs URL2- PasajeGanador
- URL1- PasajeGanador Vs URL3- PasajeGanador
- URL1- PasajeGanador Vs URL4- PasajeGanador
- ....
- ...
- URL2- PasajeGanador Vs URL3- PasajeGanador
- URL2- PasajeGanador Vs URL4- PasajeGanador
- URL2- PasajeGanador Vs URL5- PasajeGanador
- ...
- etc
Cómo elegir el pasaje más relevante
Cada vez que uno gane le sumamos un punto, y cuando hayamos comparado todos con todos podremos determinar el ganador. Además, podemos pedirle al LLM que explique el por qué, o que nos indique mejoras para que nuestro pasaje sea mejor que el ganador....
Espero mejorar y añadir más métodos para extraer y puntuar los pasajes, con la intención de ir acercándome a los criterios que Google podría usar, siempre dentro de la humildad del que sabe que no sabe nada (comparado con los doctorados en matemáticas de Google). Porque todo esto son matemáticas muy chungas, que sinceramente creo que nadie de los que lean esto llegan a entender, por supuesto yo tampoco, pero debemos entender que hay cosas que se nos escapan y que los métodos que usa Google son métodos muy muy matemáticos.
Pero eso no quita para que de manera más terrenal aprendamos cómo funciona de manera superficial, pero seguramente suficiente para poder mejorar nuestro contenido de manera que sea más probable de ser seleccionado para aparecer en los resultados de AI Mode y en los resultados de otros LLMs
Vídeo de cómo usar la IA en el navegador
Esta semana o como muy tarde la siguiente os compartiré la extensión para que la podáis instalar y también el código fuente para que veáis cómo la he desarrollado, bueno yo no, Gemini + chatGPT... en esto soy promiscuo.
Os dejo un pequeño vídeo que quizás aclare alguna duda,
Acepto sugerencias... y críticas si empiezan a oír la letra 'R'.. si no :p
Lee otros artículos
Las personalidades de Gemini
Gemini presenta cuatro personalidades principales, o "prompts internos", que se activan cuando el usuario le otorga acceso a sus documentos o datos privados
Generar contenido con abundante texto usando Google Gemini
Hoy quiero profundizar en la redacción de textos utilizando Gemini, y cómo resolver algunos de los problemas comunes que suelen ocurrir cuando generamos textos con este tipo de tecnología

Cómo utilizar la API de Google Gemini
Hoy quiero mostrar cómo crear aplicaciones / desarrollos para poder probar integrar Gemini en tu web o aplicación
Comentarios
Todavía no hay comentarios publicados.