Validando masivamente términos potenciales para muchas KWs
Cuando manejamos un site muy grande en el que tenemos cientos o miles de categorías para clasificar el contenido, como podría ser un e-commerce, puede que haya categorías muy distintas entre si.
Por ejemplo una web podría vender desde clavos hasta tractores pasando por grúas o balones... lo que llamamos un popurrí de categorías, no todas las categorías comparten las mismas keywords potenciales para cada una.
Seguramente clavos al por mayor, o balones al por mayor son términos potenciales, que son buscados por determinado público y este público son clientes potenciales para nuestro negocio, pero podrían carecer de sentido aplicados a otra categoría como el caso de tractores, nadie busca tractores al por mayor....
¿O quizás sí se busque tractores al por mayor?
En muchos sites vemos cosas incoherentes como es el caso de tractores al por mayor ya que aplican los mismos términos a todas sus categorías o palabras clave y queda bastante mal ante el usuario a parte de que no generará ventas.
Para estos casos en el que tenemos cientos o miles de KWs que podrían tener sentido con unos términos, pero no con otros tenemos dos maneras de optimizarlo correctamente
- Repasando una a una estas categorías o KWs.
- Automatizando este proceso para filtrar los casos que no tienen sentido.
Aquí voy a exponer una manera automatizada de cómo podríamos hacerlo, tengo más, pero este es uno de los que mejores resultados me da casi siempre, y es usando el XML de Google suggest.
Cuando abrimos esta url vemos como Google nos devuelve unas sugerencias de términos que contienen esos términos.

Para ser más exactos creo nos devuelve los términos más cercanos entre sí dentro de su matriz de términos relacionados (es mi opinión) y son los resultados que observamos para algunas búsquedas en la parte inferior de las serps, no debmos confundir estos términos con los que salen en el suggest de la caja de búsqueda cuando vamos introduciendo texto, esto será otro post.
Vemos como para el ejemplo de balones al por mayor nos devuelve un xml con frases de búsqueda relacionadas, y vemos como el término que nosotros hemos buscado está presente.
Con esto ya tenemos una primera manera de conseguir saber si un término como "al por mayor" es coherente con la categoría de "balones" y podemos crear un simple script que dadas unas KWs comprobara si tienen sentido con la KW "al por mayor" y hacer que nos reescriba los metas de nuestro site de manera mucho más eficaz que hacerlo a mano. Podemos comprobar como con "tractores al por mayor", el resultado devuelto está vacío, no existe, por lo tanto podríamos decir que no es común por lo que no lo incluiríamos en nuestra sección de tractores.

Antes en el resultado también te daba un número basado en el volumen de búsqueda, en un campo que se llamaba num_queries pero parece ser que lo han quitado. Si añadimos el parámetro &client=chrome podemos ver que descarga también datos númericos, pero siempre son los mismos para todas las KW así que no es relevante.
Estoy convencido que con algún otro parámetro podríamos conseguir otra vez este dato y así poder comparar dos KWs y saber por cuál de los dos es más buscado. Sigamos con el ejemplo de antes, ¿qué será más buscado "Comprar balones", "Venta de balones", o "balones online"? con el dato que ahora ha desaparecido podríamos haber realizado la comparación, pero ahora no nos lo dan y no podremos comparar el volumen de búsqueda entre ambos términos, de momento hasta que demos con el parámetro que nos ofrezca este número podremos validar si un término es coherente o potencialmente buscado para no tener cosas sin sentido en nuestro site.
También podemos optimizar más profundamente si tenemos varios términos posiblemente potenciales, por ejemplo, Venta de balones, Comprar balones, Comprar balones online, etc con este xml y si existe resultado para "venta de balones" y también para "Comprar balones" y para "Comprar balones online" podríamos alternarlos en las paginaciones como ya comentamos en su día.
Por supuesto estos datos que nos devuelve en base a una keyword nos pueden valer para muchas otras cosas, otra de ellas, de la que hablaré dentro de poco es como usarla para un KW research cuando ya se te hayan acabo las ideas.
Lee otros artículos
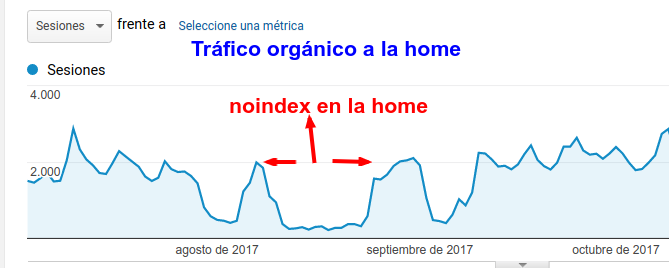
Meta etiqueta noindex
índice de contenido ¿Qué es el meta noindex? ¿A que buscadores afecta? Meta noindex solo para Google Posibles valores Meta robots Noindex Follow ¿Para qué sirve? Casos de uso ¿Cuándo usar el meta noindex? ¿Cuándo NO usar el meta noindex? Conclusiones ¿Qué es el noindex? El meta noindex sirve para indicar a los buscado…
Instalar HTTPS gratis y facilmente
Publicado el 26 de enero del 2016, por Lino Uruñuela Desde hace tiempo Google va evangelizando sobre el uso de https en internet, para ello lo hace de la manera más efectiva que conoce, EL MIEDO!. Un gran porcentaje de negocios online a día de hoy son Googledependientes, si pierden visibilidad en las serps de Google e…
Tratamiento de urls que tienen un tiempo de vida muy corto
Publicado por Lino Uruñuela ( Errioxa ) el 16 de abril del 2014 Ha habido grandes debates en el mundo SEO sobre cómo trata Google los errores 404 y 410 del servidor. Puede parecer que "da un poco igual" el cómo trate Google los errores 404 y 410 y de si hay diferencias entre ellos, pero puede ser crucial para algunas…
Velocidad de carga de una página web, ¿factor relevante para Google?
Publicado el 14 de febrero del 2014 por Lino Uruñuela ( Errioxa ) Hoy leo en SEOby the Sea que Google incluye en una de sus patentes la velocidad de una página web como factor de relevancia en sus resultados. Esto no es nuevo , desde hace mucho se viene diciendo, casi casi lo mismo que lo de " El SEO ha muerto ".... y…

Google aconseja no usar canonical en las paginaciones
Publicado el 10 de abril del 2013 , by Lino Uruñuela Ayer Google publicó los 5 errores más comunes al usar el meta rel=canonical , de ellos el que más me llama la atención es "canonical en la primera página de una serie paginada" donde nos dicen Especificar un rel = canonical de la página 2 (o cualquier otra página po…
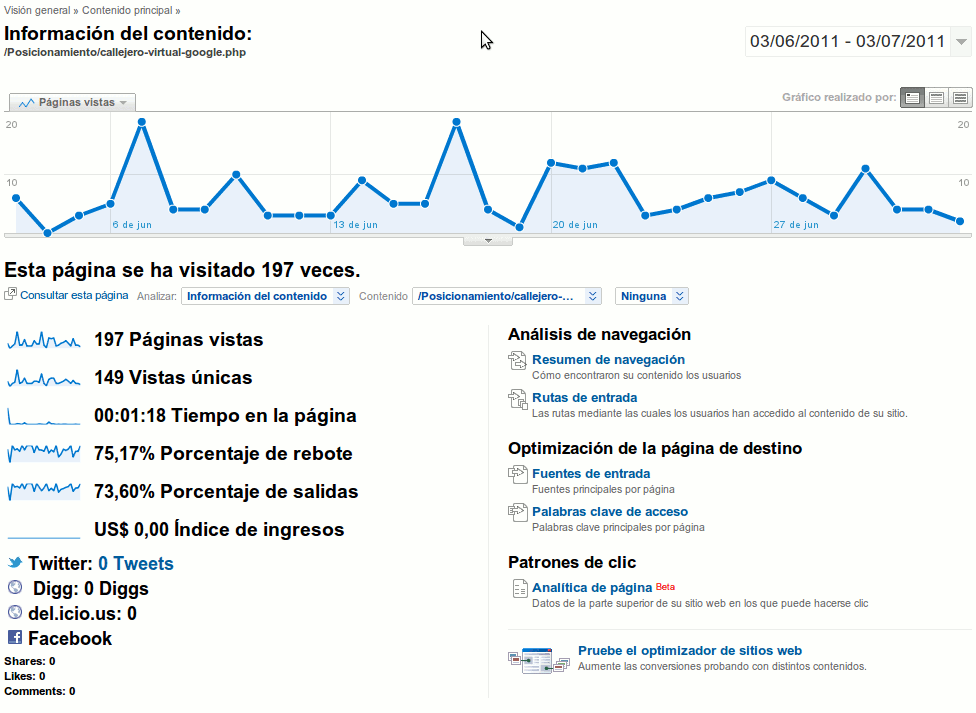
Evaluará Googel la tasa de rebote para los rankings
Publicado el 4 de julio del 2011 Desde la salida del oso de Google cada vez hay más gente que cree que Google ahora le da valor a determinadas experiencias de usuarios en una página web, como puede ser la tasa de rebote o la estancia del usuario en la web. Igual podemos demostrar que es cierto, pero nunca podremos dem…
Como evitar contenido duplicado
Publicado el 5 de febrero del 2010 Hoy quería explicar mi opinión sobre distintas formas de cómo podemos evitar el contenido duplicado, en algunos casos. Pongo un cuadro con algunos métodos que podemos utilizar para solucionar nuestros problemas. Meta/propiedad Es rastreado Es mostrado en las serps Pasa Page Rank Evit…
El fichero Robots.txt para SEO
Escrito el miércoles 25 de Julio de 2007 Aquí mostramos los últimos artículos que tratan aspectos técnicos acerca del SEO y el robots.txt
Comentarios
Todavía no hay comentarios publicados.