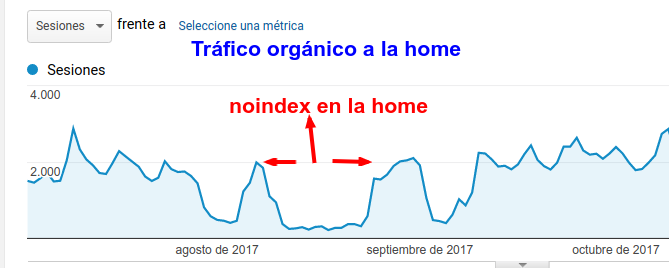
Google aconseja no usar canonical en las paginaciones
Ayer Google publicó los 5 errores más comunes al usar el meta rel=canonical, de ellos el que más me llama la atención es "canonical en la primera página de una serie paginada" donde nos dicen
Especificar un rel = canonical de la página 2 (o cualquier otra página
posterior) a la página 1 no es correcto uso de rel = canonical, ya que
no son páginas duplicadas. El uso del rel = canonical aquí causaría que
el contenido de las páginas 2 y más adelante no se indexen en absoluto.
|

Yo siempre he dicho que no me gusta poner ese meta y que me gusta dejar las paginaciones rastreables e indexables (en muchos casos, que no en todos). En este artículo expongo una práctica para obtener distintos términos usando las paginaciones, aunque actualmente el ejemplo se ha quedado obsolote ya que no toco esa web desde hace más de 4 años....
Aquí dejo unos experimentos que he ido realizando para saber cómo trata Google el meta canonical
- Comprobando comportamiento de Google con meta canonical
- ¿Ha cambiado Google la forma en que trataba el meta canonical?
- Otra prueba para el meta canonical
- ¿Cómo afecatará poner meta canonical a si misma?
- ¿Cómo valora google una url con meta noindex y canonical?
Google ahora nos comenta lo que deberíamos hacer y supuestamente cómo lo trata. Está claro que una cosa es lo que dice y otra lo que hace, pero en este caso con este punto que comentan creo que es así y que hacerlo no será beneficioso para tu site.
Y es que hay muchísimas webs que usan este meta de esta manera. Se opina que el valor que tengan esas páginas con un meta canonical estará reforzando a la URL a la que apuntan, sumando así ésta el valor o parte del valor de todas las que la apunten con un canonical. Según los tests que menciono arriba el valor del los links que apuntaran a las paginaciones sí se otorgarían a la URL donde apuntan los canonicals, así que algo de valor parece que sí pasa.
Yo seguiré dejando las paginaciones indexables y rastreables, y si alguna no quiero que la rastree entonces la restringiré por medio del robots.txt porque además puede beneficiarte al dejar sitio a otras URLs.
Comentarios
1Lee otros artículos
Meta etiqueta noindex
índice de contenido ¿Qué es el meta noindex? ¿A que buscadores afecta? Meta noindex solo para Google Posibles valores Meta robots Noindex Follow ¿Para qué sirve? Casos de uso ¿Cuándo usar el meta noindex? ¿Cuándo NO usar el meta noindex? Conclusiones ¿Qué es el noindex? El meta noindex sirve para indicar a los buscado…
Instalar HTTPS gratis y facilmente
Publicado el 26 de enero del 2016, por Lino Uruñuela Desde hace tiempo Google va evangelizando sobre el uso de https en internet, para ello lo hace de la manera más efectiva que conoce, EL MIEDO!. Un gran porcentaje de negocios online a día de hoy son Googledependientes, si pierden visibilidad en las serps de Google e…
Tratamiento de urls que tienen un tiempo de vida muy corto
Publicado por Lino Uruñuela ( Errioxa ) el 16 de abril del 2014 Ha habido grandes debates en el mundo SEO sobre cómo trata Google los errores 404 y 410 del servidor. Puede parecer que "da un poco igual" el cómo trate Google los errores 404 y 410 y de si hay diferencias entre ellos, pero puede ser crucial para algunas…

Validando masivamente términos potenciales para muchas KWs
Publicado el 19 de marzo del 2014 por Lino Uruñuela ( Errioxa ) Cuando manejamos un site muy grande en el que tenemos cientos o miles de categorías para clasificar el contenido, como podría ser un e-commerce, puede que haya categorías muy distintas entre si. Por ejemplo una web podría vender desde clavos hasta tractor…
Velocidad de carga de una página web, ¿factor relevante para Google?
Publicado el 14 de febrero del 2014 por Lino Uruñuela ( Errioxa ) Hoy leo en SEOby the Sea que Google incluye en una de sus patentes la velocidad de una página web como factor de relevancia en sus resultados. Esto no es nuevo , desde hace mucho se viene diciendo, casi casi lo mismo que lo de " El SEO ha muerto ".... y…
Evaluará Googel la tasa de rebote para los rankings
Publicado el 4 de julio del 2011 Desde la salida del oso de Google cada vez hay más gente que cree que Google ahora le da valor a determinadas experiencias de usuarios en una página web, como puede ser la tasa de rebote o la estancia del usuario en la web. Igual podemos demostrar que es cierto, pero nunca podremos dem…
Como evitar contenido duplicado
Publicado el 5 de febrero del 2010 Hoy quería explicar mi opinión sobre distintas formas de cómo podemos evitar el contenido duplicado, en algunos casos. Pongo un cuadro con algunos métodos que podemos utilizar para solucionar nuestros problemas. Meta/propiedad Es rastreado Es mostrado en las serps Pasa Page Rank Evit…
El fichero Robots.txt para SEO
Escrito el miércoles 25 de Julio de 2007 Aquí mostramos los últimos artículos que tratan aspectos técnicos acerca del SEO y el robots.txt
Totalmente de acuerdo