Cómo añadir el valor del meta Robots a Google Analytics via Google Tag Manager
Muchas veces los SEOs usamos determinados protocolos y/o directivas para dar determinadas señales a los Bots de los buscadores y otros servicios.
Así por ejemplo, podemos usar un meta para indicarles en qué fecha se publicó determinada noticia o a qué hora fue modificada por última vez.
<meta property="article:published_time" content="2017-05-24T17:48:33+0200" />
<meta property="article:modified_time" content="2017-05-24T17:48:34+0200" />
También tenemos otros protocolos/directivas para indicar a los robots que una url no es accesible para ellos, y que les prohibimos acceder a esa url, normalmente cuando sabemos que siempre querremos impedir el acceso a Google a determinadas urls usamos el robots.txt.
Meta NoIndex
Uno de los metas más usados es el meta robots, el cual indica a los buscadores que esa url no debe indexarse ni mostrarse en los resultados del buscador.<meta name="robots" content="noindex,follow">
Este meta, al contrario que la directiva Disallow del robots.txt, no impide el acceso por parte del Bot al cotnenido de esa url, solo indica al buscador que ni el el contenido de esa url, ni la propia url debe ser mostrada en los resultados del buscador.
El meta robots se suele usar en urls que tienen contenido el cual podría ser considerado por Google como duplicado, o como thin content (contenido de baja calidad), de esta manera le damos una señal a Google para que no lo tenga en cuenta a la hora de evaluar el site porque sabemos que es contenido de baja calidad, ya sea por escaso, ya sea por duplicado, o ya sea porque realmente es de baja calidad, como ocurre a veces con los contenidos generados por los usuarios.
La mayoría de las veces usamos el meta noindex de una forma dinámica, es decir, dependiendo de diversos factores se le añadirá el meta noindex o no. Pongamos un ejemplo, tenemos un site donde los usuarios generan contenido, unos lo hacen muy bien, y otros en cambio lo hacen fatal, por ejemplo creando miles de contenidos con solo unas pocas palabras.
Queremos aprovechar el cotenido que creen los usuarios que cumpla ciertos requerimientos de calidad, por ejemplo, que el texto redactado contenga más de 200 palabras y una imagen. Todos los artículos que no cumplan al menos esta regla no queremos que Google lo valore como parte de nuestro site/contenido, una manera sencilla de realizarlo es introducir el meta con el valor noindex en aquellos contenidos que no satisfagan nuestras condiciones, y solo permitir su indexación (poniendo el meta robots con valor index) en aquellos contenidos con cierta calidad.
En muchas ocasiones, cuando el site tiene cierto histórico, el número de contenidos con el meta noindex puede ser muy superior al cotenido indexable, y eso no es bueno. Cada vez hay más urls de este tipo, que hacen perder el tiempo a Google, ya que aunque no lo indexa sí accede y la rastrea. Esto conlleva un gasto del presupuesto de rastreo que Google asigna al site, y lo gastará en urls que no van a darnos visitas al no ser indexanles.
Una de las mayores dificultades a las que me suelo enfrentar en sites grandes (como webs de anuncios clasificados , o sites con un altísimo volumen de urls en su histórico) es saber cuántas y qué urls están, en ese u otro momento, con un meta noindex.
Cómo monitorizar el valor del meta Robots
Para saber el número de urls con meta noindex (o index) que tenemos en nuestro site podemos usar un crawler que rastree nuesrto site y nos lo indique. En webs grandes no hay crawler capaz de rastrear todas y cada una de las urls tal como hace Google. Normalmente estos crawlers o terminan con la memoria Ram de tu pc, como le ocurre a Screaming Frog, o terminan con tu cuenta bancaria como en el caso de Botify...Hoy vamos a ver cómo ver y analizar el contenido de este meta en una dimensión personalizada de nuestro Google Analytics, y así poder segmentar y listar fácilmente las urls que tienen uno u otro valor, y lo mejor de todo, sin necesidad de implementación técnica en el código de nuestro site.
Para ello vamos a seguir estos pasos:
-
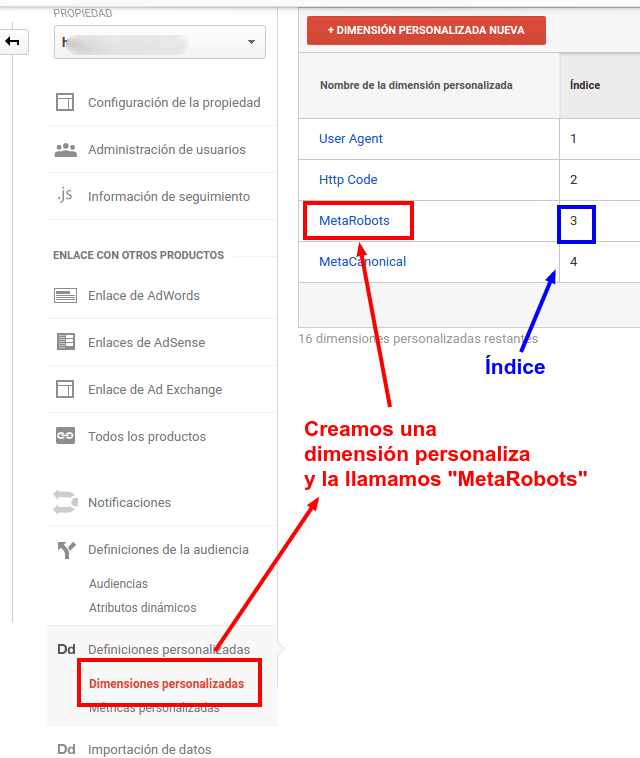
Crear Dimensión personalizada en GA
Llamaremos a esta nueva dimensión personalizada "MetaRobots", y nos fijaremos en el número del índice, en este caso el 3
-
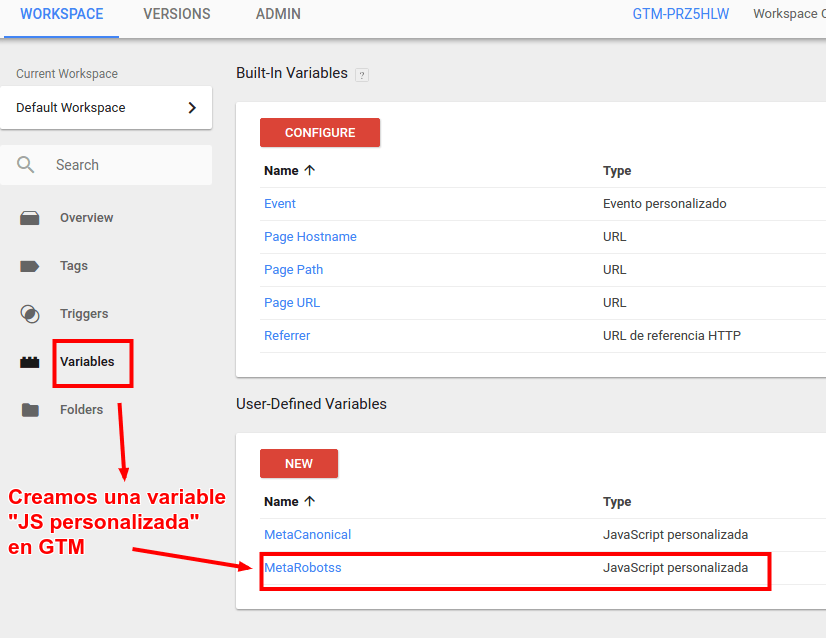
Creamos una variable en Tag Manager
Dentro del Workspace de GTM creamos una variable del tipo JavaScript personalizada
-
Añadimos el siguiente código JavaScript en la variable que acabamos de crear
-
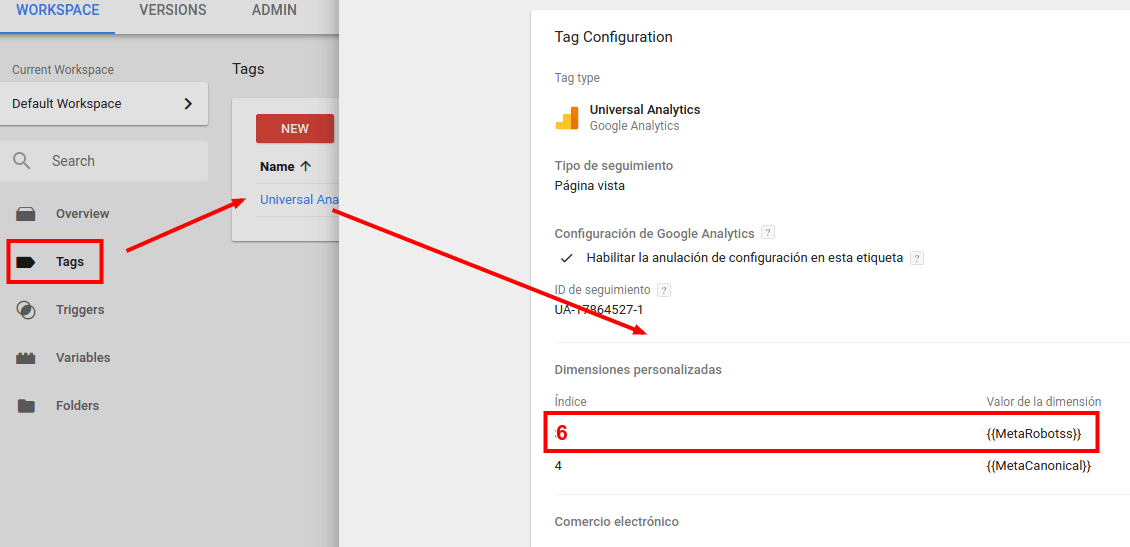
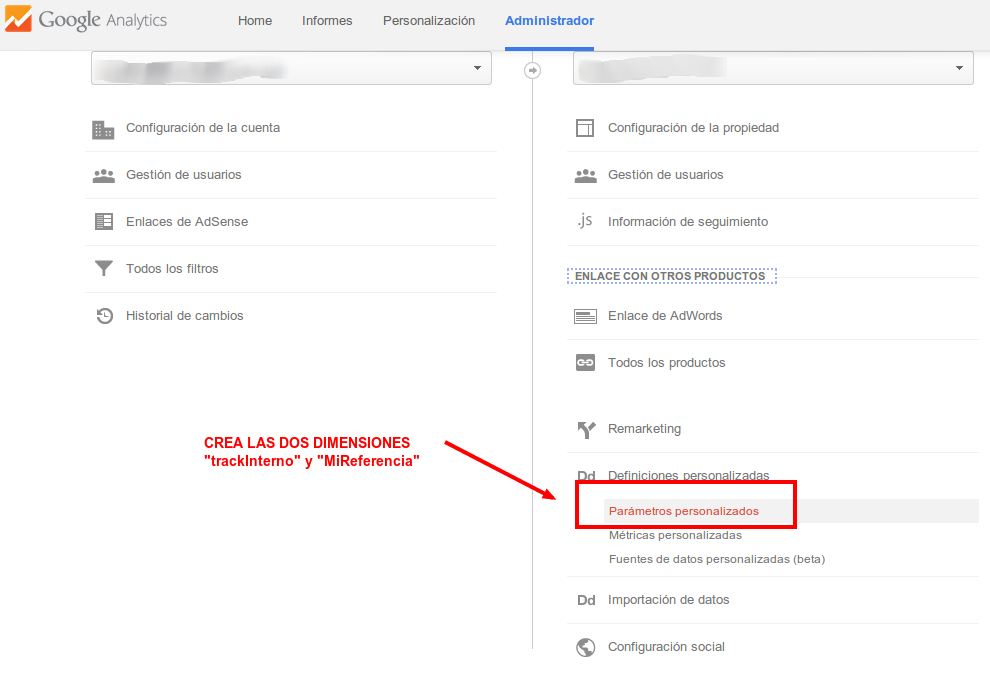
Crear dimensión personalizada en GTM
En la configuración del tag de Universal Analytics en GTM creamos una dimensión personalizada
El índice, en nuestro caso sería el 6 y el valor sería "{{MetaRobots}}"
-
Pulbicamos el nuevo tag.
function metas() { encontrada=0; var metas = document.getElementsByTagName('meta'); for (i=0; i<metas.length; i++) if (metas[i].getAttribute("name") == "robots") { encontrada=1; return metas[i].getAttribute("content"); } if (encontrada==0) return "index,follow"; } |
A partir de ahora ya podremos comprobar, mirando el tráfico de hoy por horas, que se está ejecutando de manera correcta. Yo he craedo dos segmentos avanzados, uno que contiene "noindex" en la dimensión secundaria MetaRobots y otro que no lo contiene
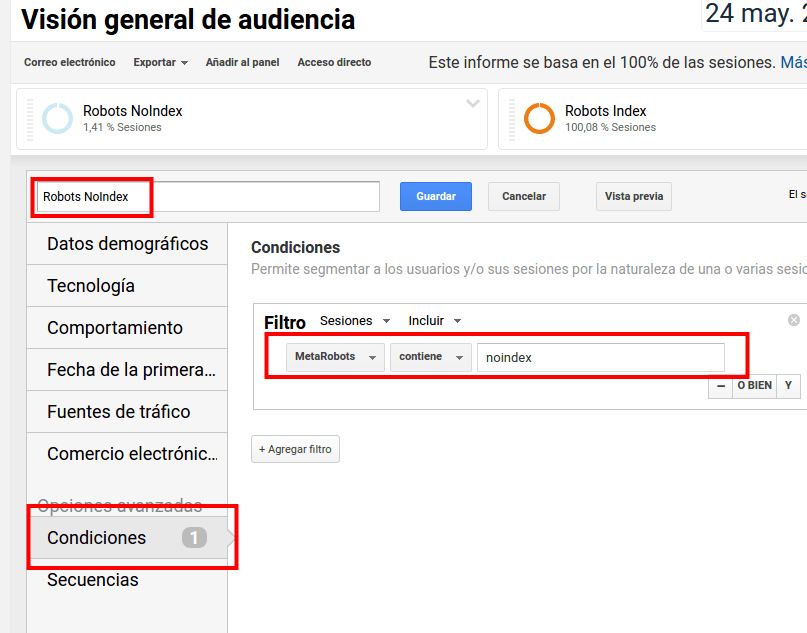
Para luego poder segmentar por el valor del meta y verlo así en los informes, este lo acabo de crear a la vez que este post, por eso hoy solo puedo visualizar los datos de las últimas hora.
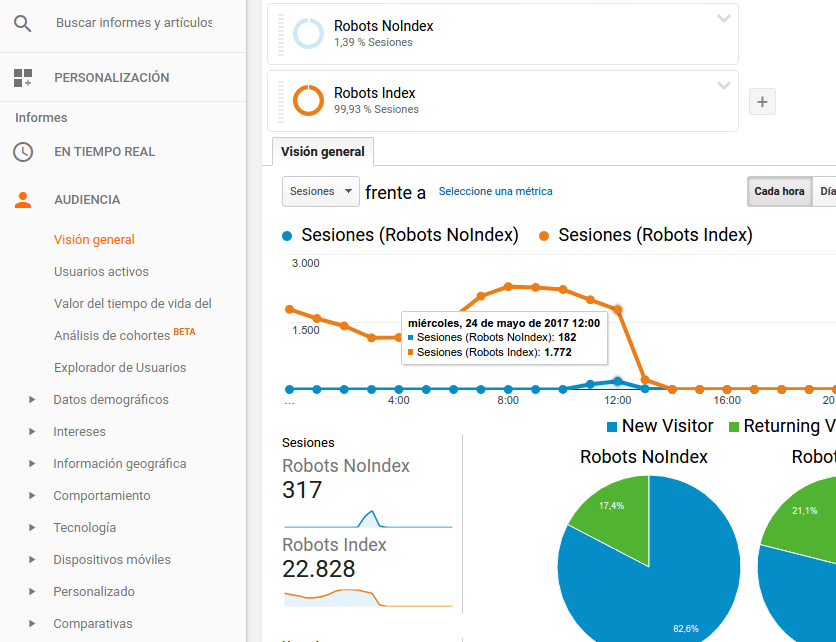
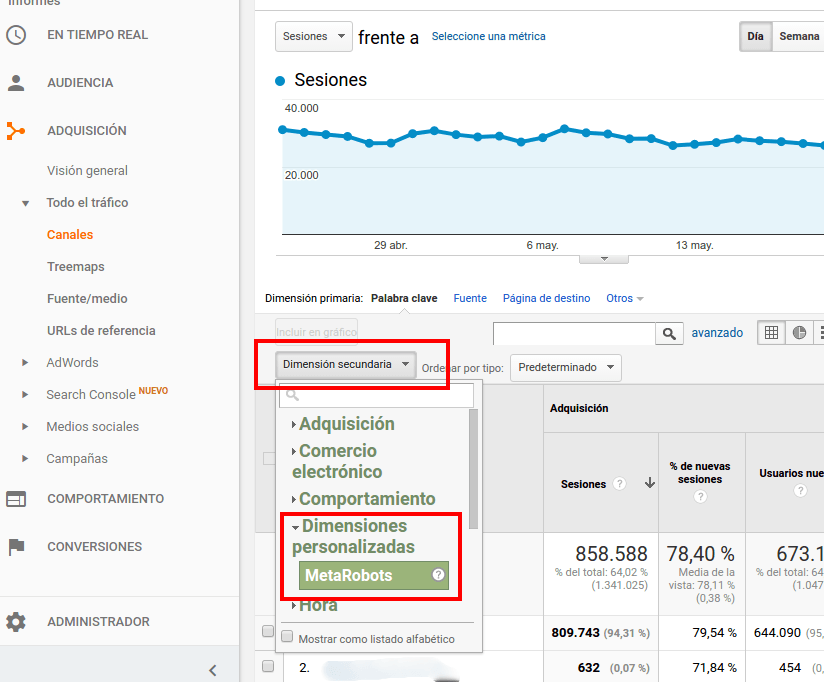
Y podremos usar la nueva dimensión secundaria MetaRobots en nuestros informes de Google Analytics como cualquier otra
Comentarios
3Lee otros artículos
Medir cuántos usuarios hacen click para ampliar la imagen en Google Imágenes, aunque no entren en nuestra web
Publicado por Lino Uruñuela el 20 de febrero del 2018 El otro da Google hizo un cambio importante del inteface en su buscador de imágenes, eliminando el botón de ver imagen y respondiendo así a la demanda antimonopolio que Getty Images realizó ante la Unión Europea. Cómo era antes Y actualmente ha desaparecido la opci…
Monitorizar GoogleBot con Google Analytics
Vamos a facilitar un poco esta monotorización mostrando cómo trackear GoogleBot, BingBot (y los que quieras) con Google Analytics, concretamente con Universal Analytics y su protocolo de medición.
Benchmarking en Google Analytics y divagaciones sobre el marketing a cañonazos
Publicado el jueves 11 de septiembre por Lino Uruñuela Hoy voy a cambiar un poco de tema para variar, pero no me desviaré mucho. Si hay algo que me ha quedado claro en más de 10 años que llevo trabajando entorno a los negocios online , y que se viene cumpliendo como una máxima desde entonces, ya fuese a comienzos de s…
Cómo obtener la fuente en Universal Analytics sin cookie utmz
Publicado el 19 de agosto del, 2014 Hace ya "bastante" que salió a la luz Universal Analytics y ya nos ha dado tiempo a descubrir sus pros y sus contras con respecto a la anterior versión de Google Analytics. Y sí, también tiene contras, bastantes además, y es sobre uno de estos puntos sobre el que vamos a hablar hoy.…
El tráfico de Internet Explorer vuelve a ser orgánico
Publicado por Lino Uruñuela ( Errioxa ) el 30 de junio del 2014 Hoy me he llevado una sorpresa cuando me he puesto a analizar el tráfico directo a raíz de que Rodrigo Hernandez me comentase su preocupación con el tráfico de un site , y es que normalmente suelo tener un segmento personalizado para medir el tráfico dire…
Volcado de Google Analytics a tu Base de Datos
Publicado por Lino Uruñuela ( Errioxa ) el 23 de abril del 2014 Como dijimos el otro día, vamos a crear una serie de post sobre cómo utilizar determinadas APIs que Google nos ofrece, ya que en ocasiones la documentación es escasa en español, e incluso para algunas novedades es escasa hasta en inglés. Hoy vamos a comen…
Not Provided un mensaje de optimismo
Publicado el lunes 7 de octubre del 2013 , by Lino Uruñuela Hoy me siento optimista, no sé si será porque ya estoy casi recuperado de la operación de rodilla a la que me sometí hace un mes, pero estoy optimista. Hace poco Google anunció que iba a encriptar y ocultar las palabras de búsqueda por las que llegan los usua…

Keywords para hoy not provided para mañana
Pu blicado el 4 de abril del 2013 by Lino Uruñuela Como todos sabemos desde hace más de un año el Not Provided cada vez aglutina más keywords en nuestras estadísticas y aunque aun podemos trabajar casi igual que hace dos años, no creo que podamos hacerlo dentro de otros dos... El crecimiento del término Not Provided e…
Cómo cruzar los datos de Analytics, WMT, rankings, etc
Publicado el 26 de enero del 2012 by Errioxa En el anterior post comenté cómo se podría sacar más provecho si cruzamos los datos que tenemos desde la distintas herramientas como Analytics, WMT, monotorización de posiciones. Así obtendríamos un excel como este Os dije lo que hacía pero no el cómo, y lo prometido es deu…
Cruzando datos Analytics, WMT, AdWords y posicion
Publicado el 27 de diciembre del 2011 El otro día desde el blog para webmasters de Google nos anunciaban que habían creado un script para poder descargar los datos de impresiones, clicks, CTR, etc desde WMT . La verdad lo acogí con gran ilusión pero de momento no le veo más utilidad que la de poder filtrar por fechas…
Gracias Lino!
Muy útil...gracias!
Antes de Nada muchas gracias por la aportación. Estoy probando de poner en marcha este procedimiento y me surgen un par de dudas. En el punto 1 : Crear Dimensión personalizada en GA Se informa que el id = 3, pero luego más adelante en el punto 4 : Crear dimensión personalizada en GTM se usa el id=6 Sobre el script, puede ser que falte cerrar una llave al código javascript? En este código se define la función, pero cuando se ejecuta esta función si no se llama desde ningún sitio. Y por último, ¿sería posible mediante este mismo procedimiento guardar la respuesta del servidor (404/200/500), el bot y la última fecha de visita? Muchas gracias de antemano.