Monitorizar GoogleBot con Google Analytics
Publicado el 13 de abril del 2015 por Lino Uruñuela
Hace tiempo ya comentamos que podemos saber cómo y cuándo acceden los robots de los buscadores a cada url de nuestro site por medio de los logs.
Es muy importante tener visibilidad sobre qué y cómo crawlean GoogleBot, BingBot nuestro site.
Cosas que nos pueden ser muy útiles y a veces salvarnos la vida
- URLs más frecuentadas por cada Bot
- Saber cuánto tiempo pierden los bots en URLs de paginaciones
- Saber cuánto tiempo pierden los bots en URLs con canonical
- Saber cuánto tiempo pierden los bots en URLs con noindex
- Saber cuánto tiempo pierden los bots en URLs con parámetros
- ¿Cuantos accesos a páginas con error 404 hace cada Bot?
- ¿Desde que país está rastreando?
- ¿Con que User Agent concretamente?
- ¿A cuántas URLs únicas acceden los distintos Bots?
- ¿Cuántas de las URLs que acceden los bots no tienen accesos por parte de usuarios desde hace mas de 1 año?
Cómo véis, estos datos nos pueden dar mucha luz sobre que podemos mejorar de nuestro site, y lo mejor, intentar averiguar por que los Bots actuan como actuan en nuestra web y si su rastreo está siendo eficiente.
Ya vimos en un post anterior, que es posible obtener todos estos datos con los logs del servidor, aplicando unas simples órdenes en linux. Pero también es verdad que si no sabes mucho de logs puede no ser fácil aislar bien los datos que quieres obtener (hecho en falta alguna herramienta de logs completamente orientada a SEO), sería de gran ayuda.
Vamos a facilitar un poco esta monotorización mostrando cómo trackear GoogleBot, BingBot (y los que quieras) con Google Analytics, concretamente con Universal Analytics y su protocolo de medición.
Si algo bueno tiene este protocolo de Universal Analytics es que lo puedes usar cómo tú quieras, y monotorizar desde los usuarios de tu site, hasta el inventario de libros de tu casa, claro está, si sabes cómo funciona y te has peleado unas cuantas horas conél.
En este caso vamos a usar el protocolo para obtener los accesos de GoogleBot y BingBot a nuestro site
Monotorizamos los siguientes datos
- Nombre del Bot
- URL a la que accede
- Fecha completa a la que accede
- País desde donde llega
- Si da un estado http 200, o da error 404
- User Agent que usa
Muchos creeréis que será complicado... NO! solo hay que seguir estos 7 pasos ;)
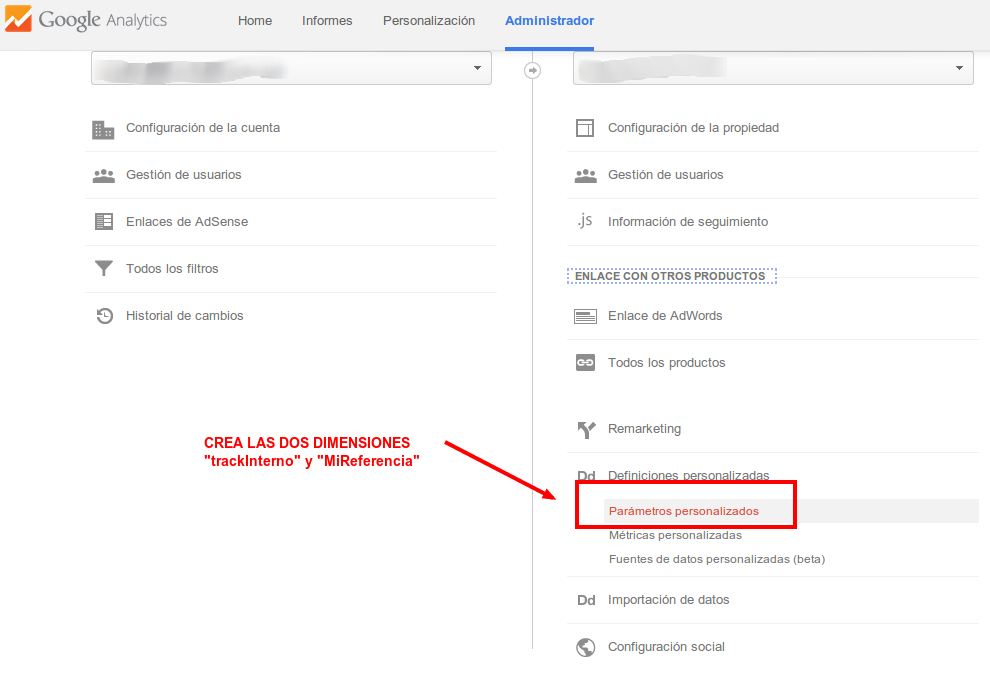
- Créate una nueva propiedad en Google Analytics
Vamos a hacerlo en una distinta para no contaminar los datos de visitas, aunque como veremos no influye para nada... pero por si acaso - Ve al administrador de Google Analytics y crea una nueva propiedad

- Rellenamos los campos

- Vamos a crear dos dimensiones personalizadas, para desde el administrador.

- Yo las he llamado así, podéis nombrarlas como queráis. La creamos a nivel de "Hit"

- Copia y pega el código al final de todo
Ya tenemos Analytics configurado y preparado, ahora el código php que debes pegar al final de tu site, después del </html> y de cualquier otro comando que ejecute en php, que sea lo último así no interfiere en nada.
Lo único que debes personalizar, tu identificador de Analytics, y si es página de error código 404 y si es correcta 200
UA-XXXXX-XX -> tu identificador de Google Analytics
$titulo_Pagina -> title de la página
"200" -> si la página no es la de error, si es la de erro un "404"
<? class BotTracker { static function track($s, $params) { if (preg_match("/googlebot|bingbot/i", $s['HTTP_USER_AGENT'], $matches)) { $bot = $matches[0]; $data = array('v' => 1, 'tid' => 'UA-XXXXX-XX', 'cid' => self::generate_uuid(), 't' => 'pageview', 'dh' => $s['HTTP_HOST'], 'dl' => $s['REQUEST_URI'], 'dr' => $s['HTTP_REFERER'], 'dp' => $s['REQUEST_URI'], 'dt' => $params['page_title'], 'cs' => $bot, 'cm' => 'direct', 'cn' => '', 'ck' => $s['HTTP_USER_AGENT'], 'cc' => '', 'uip' => $s['REMOTE_ADDR'], 'cd1' => $s['HTTP_USER_AGENT'], 'cd2' => $params['http_code'],); $url = 'http://www.google-analytics.com/collect'; $content = http_build_query($data); $ch = curl_init(); curl_setopt($ch, CURLOPT_USERAGENT, $s['HTTP_USER_AGENT']); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 0); curl_setopt($ch, CURLOPT_CONNECTTIMEOUT_MS, 0); curl_setopt($ch, CURLOPT_TIMEOUT_MS, 0); curl_setopt($ch, CURLOPT_HTTPHEADER, array('Content-type: application/x-www-form-urlencoded')); curl_setopt($ch, CURLOPT_HTTP_VERSION, CURL_HTTP_VERSION_1_1); curl_setopt($ch, CURLOPT_POST, 1); curl_setopt($ch, CURLOPT_ENCODING, "gzip"); curl_setopt($ch, CURLOPT_POSTFIELDS, $content); $result = curl_exec($ch); $info = curl_getinfo($ch); curl_close($ch); } } static private function generate_uuid() { return sprintf('%04x%04x-%04x-%04x-%04x-%04x%04x%04x', mt_rand(0, 0xffff), mt_rand(0, 0xffff), mt_rand(0, 0xffff), mt_rand(0, 0x0fff) | 0x4000, mt_rand(0, 0x3fff) | 0x8000, mt_rand(0, 0xffff), mt_rand(0, 0xffff), mt_rand(0, 0xffff)); } } BotTracker::track($_SERVER, array("page_title" => $titulo_Pagina, "http_code" => "200")); ?>
*Este código solo recoge datos de GoogleBot y BingBot por no liar a los lectores con una expresión regular para obtenerlos de todos los bots como pueden ser aHrefs, Screaming Frog, Sistrix, etc. Actualizaré en breve el post añadiendo esta regex. - Comprobar en Informes de tiempo real que está funcionando correctamente
Puedes probarlo usando un Use-Agent que emule a GoogleBot o a BingBot.

Y ya podemos ver los informes como si cada bot que trackeemos fuese una fuente de tráfico distinta

Otra vista útil son las URLs que nos dan error 404, como veis se puede segmentar todo (por urls, por carpetas, etc), crear tus propios dashboards, alertas, etc.
OjO debemos cambiar el "200" por el 404 en este código en la url que trate nuestro servidor los errores 404, en mi caso defino el fichero que trata los 404 desde apache y CREO que también se podría hacer con las redirecciones, pero no he comprobado esto.. lo haré ;)

En próximos posts, esta información, cruzada con la de los usuarios nos pueden hacer ver por qué ciertas secciones no obtienen visibilidad en las serps de Google, o que urls podemos dejar de linkar porque consumen mucho tiempo de crawleo y muy pocas visitas de usuarios, a las que llamo "urls poco eficientes" y creo que son una de las mayores pistas de cómo matar al Oso Panda ;)
Cualquier mejora, cualquier sugerencia, o cualquier duda ya sabéis... comentarlo y compartirlo!!!
Si te ha gustado este postVótame en la web de Seonthebeach, para ver poder ver una ponencia completa y más detallada en el @seonthebeach |
PD: Gracias a Fran Horrillo (excelente Product Manager de Motofan.com) por resumir mi caos de código en una simple clase de PHP!!!
Comentarios
14Lee otros artículos
Medir cuántos usuarios hacen click para ampliar la imagen en Google Imágenes, aunque no entren en nuestra web
Publicado por Lino Uruñuela el 20 de febrero del 2018 El otro da Google hizo un cambio importante del inteface en su buscador de imágenes, eliminando el botón de ver imagen y respondiendo así a la demanda antimonopolio que Getty Images realizó ante la Unión Europea. Cómo era antes Y actualmente ha desaparecido la opci…
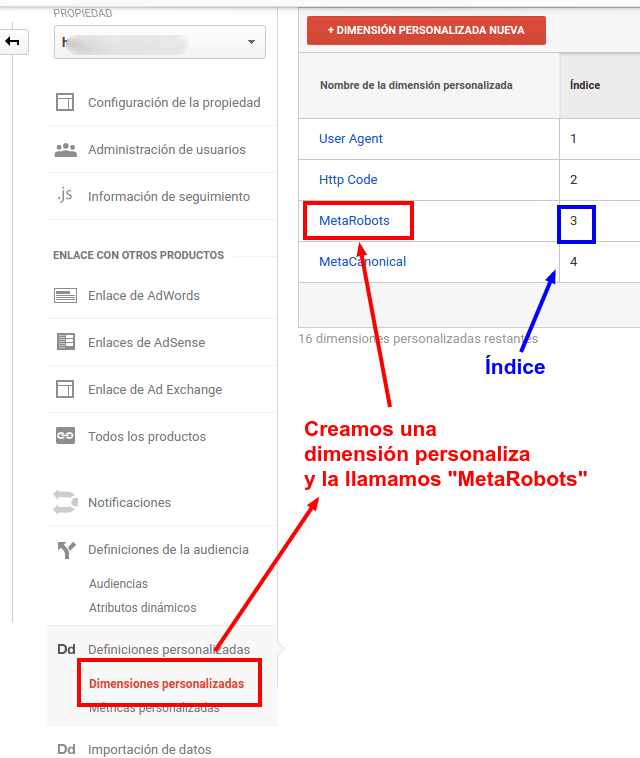
Cómo añadir el valor del meta Robots a Google Analytics via Google Tag Manager
Publicado el 24 de mayo del 2017, by Lino Uruñuela Muchas veces los SEOs usamos determinados protocolos y/o directivas para dar determinadas señales a los Bots de los buscadores y otros servicios. Así por ejemplo, podemos usar un meta para indicarles en qué fecha se publicó determinada noticia o a qué hora fue modific…
Benchmarking en Google Analytics y divagaciones sobre el marketing a cañonazos
Publicado el jueves 11 de septiembre por Lino Uruñuela Hoy voy a cambiar un poco de tema para variar, pero no me desviaré mucho. Si hay algo que me ha quedado claro en más de 10 años que llevo trabajando entorno a los negocios online , y que se viene cumpliendo como una máxima desde entonces, ya fuese a comienzos de s…
Cómo obtener la fuente en Universal Analytics sin cookie utmz
Publicado el 19 de agosto del, 2014 Hace ya "bastante" que salió a la luz Universal Analytics y ya nos ha dado tiempo a descubrir sus pros y sus contras con respecto a la anterior versión de Google Analytics. Y sí, también tiene contras, bastantes además, y es sobre uno de estos puntos sobre el que vamos a hablar hoy.…
El tráfico de Internet Explorer vuelve a ser orgánico
Publicado por Lino Uruñuela ( Errioxa ) el 30 de junio del 2014 Hoy me he llevado una sorpresa cuando me he puesto a analizar el tráfico directo a raíz de que Rodrigo Hernandez me comentase su preocupación con el tráfico de un site , y es que normalmente suelo tener un segmento personalizado para medir el tráfico dire…
Volcado de Google Analytics a tu Base de Datos
Publicado por Lino Uruñuela ( Errioxa ) el 23 de abril del 2014 Como dijimos el otro día, vamos a crear una serie de post sobre cómo utilizar determinadas APIs que Google nos ofrece, ya que en ocasiones la documentación es escasa en español, e incluso para algunas novedades es escasa hasta en inglés. Hoy vamos a comen…
Not Provided un mensaje de optimismo
Publicado el lunes 7 de octubre del 2013 , by Lino Uruñuela Hoy me siento optimista, no sé si será porque ya estoy casi recuperado de la operación de rodilla a la que me sometí hace un mes, pero estoy optimista. Hace poco Google anunció que iba a encriptar y ocultar las palabras de búsqueda por las que llegan los usua…

Keywords para hoy not provided para mañana
Pu blicado el 4 de abril del 2013 by Lino Uruñuela Como todos sabemos desde hace más de un año el Not Provided cada vez aglutina más keywords en nuestras estadísticas y aunque aun podemos trabajar casi igual que hace dos años, no creo que podamos hacerlo dentro de otros dos... El crecimiento del término Not Provided e…
Cómo cruzar los datos de Analytics, WMT, rankings, etc
Publicado el 26 de enero del 2012 by Errioxa En el anterior post comenté cómo se podría sacar más provecho si cruzamos los datos que tenemos desde la distintas herramientas como Analytics, WMT, monotorización de posiciones. Así obtendríamos un excel como este Os dije lo que hacía pero no el cómo, y lo prometido es deu…
Cruzando datos Analytics, WMT, AdWords y posicion
Publicado el 27 de diciembre del 2011 El otro día desde el blog para webmasters de Google nos anunciaban que habían creado un script para poder descargar los datos de impresiones, clicks, CTR, etc desde WMT . La verdad lo acogí con gran ilusión pero de momento no le veo más utilidad que la de poder filtrar por fechas…
Grande Lino! Especialmente para tí, se acerca la herramienta de los logs :) en breve espero tener más noticias!
tengo que testear pq tengo una duda. ¿tiene sentido usar el "generate_uuid" solo a nivel de session?
Hola, tengo una duda. En mi caso, cuando pongo el promedio de tiempo del bot en la página, sale 0:00:00. ¿Esto es debido a que están menos de un segundo en la página o es otra métrica? Porque he probado con duración media de la sesión y otras métricas relacionadas con el tiempo, pero sigue siendo 0. Gracias de antemano.
@jordi, la verdad que da un poco igual... no almacenará nunca la cookie @Manuel Es normal, piensa que el GoogleBot no es un usuario ni nada, simplemente hace una petición a una url. Vete a saber si realmente obtiene ahí la info, o si solo mira el status... lo relevante es cuánto pasa y por dónde :)
Lino disculpa la molestia, he implementado el código como explicas pero no veo resultados. Modifique el codigo de seguimiento, y deje el status code en 200. Lo que no cambie es $titulo_Pagina ya que no se bien si debo poner solo el nombre de mi web o que. El código lo implemente en el footer de la plantilla después de la etiqueta de cierre
Muy bueno el post Lino, ya lo estoy probando... ...me gusta especialmente la categoria del sector que le pones a la nueva propiedad ;)
Hola Lino! Excelente post! Muy interesante todo lo relacionado al analisis de logs. Podrías por favor decirme como sería la regex para trackear todos los bots? Saludos desde Argentina.
Con varnish o CDN esto es inviable claro..
@Javier Lorente supongo que sí, la verdad nunca me enfrenté a ese monstruo
Hola Lino, Sabes si añadiendo como robot Googlebot ya incluye tanto al robot de desktop como de mobile? O se tendria que añadir Googlebot-Mobile a rastrear? Muchas gracias!!!
Hola Lino como podemos añadir a este código la identificación de la ip del bot, como sabes hay falsos bots y una forma de saber si son lo que son es con la ip gracias
Excelento post Lino! Has podido trackear los 301 y 302?
@Joan marc sí!, pero has de configurar el server para que cualquier URL que de 301 sea tratada por una única url del site (como la url de error personalizada) que se encarga de redirigir, en esa url añades el código. No es un método válido para muchos sites, que no pueden o no deben realizar toda la lógica de redirecciones desde un archivo..
Muchísimas gracias @Lino!! Para acabar, sabes si con Varnish tendríamos problemas? Entiendo que al no hacerse siempre consultas al servidor por estar en cache nos podría dar problemas, es así?