Como evitar contenido duplicado
Hoy quería explicar mi opinión sobre distintas formas de cómo podemos evitar el contenido duplicado, en algunos casos.
Pongo un cuadro con algunos métodos que podemos utilizar para solucionar nuestros problemas.
| Meta/propiedad | Es rastreado |
Es mostrado en las serps | Pasa Page Rank |
Evita duplicados |
| NoIndex |
Sí | No | Sí | Sí |
| El problema de usar este es que estás traspasando link jiuce (valor del link). Si no quieres que una página sea mostrada en los resultados de Google pero que sí cuenten los links que hay dentro de ella, esta podría ser una buena solución. Habrá que hacer una prueba para comprobar si cuenta los links dentro de una página con el meta puesto. Yo no la usaría para páginas como contacto, aviso legal y otras páginas que para nosotros son inútiles porque no nos interesa posicionar. Para hacer esto yo creo que hay mejores soluciones (con javascript) y así no desperdiciar nada de Link juice. |
||||
| NoFollow | Sí | Sí | No, no sigue los links |
No |
| Este es un meta al que se le puede sacar provecho de distintas maneras. Lo puedes usar para incambiar links con gente inerpexta. Google, en teoría, no seguirá ni valorará esos link, con lo cual, tu recibes uno a cambio de nada. También puedes hacer de esta página un gran acumulador de PR, ya que recibirá links pero no dará ninguno (como ocurre con la wikipedia). Luego no sé si quizás se podría usar ese poder acumulado por ejemplo quitar la meta, cambiar contenido y poner cuatro links contados a donde tú quieras. O simplemente posicionar esta url, aunque será más difíl que si tuviese un mínimo de contenido. Aunque no creo que ninguna buena estrategia se base en esto. Sólo es por probar, por intentar comprender un poco más el por qué salen unos u otros... |
||||
| Canonical | Sí, pero no sé hasta que punto |
A veces salen... |
?? | Sí, Google la creó para ello. |
| Esta nos puede valer si tenemos mucho contenido duplicado porque la navegación permite múltiples vías de entrada a un mismo producto. Suele ocurrir a menudo en las webs de clasificados, o las páginsa de tiendas online. A menudo no podemos controlar la cantidad de URLs que se pueden duplicar. Creo que lo mejor es definir las urls principales y las demśa URLs variables de esa ponerla la cannonical. En este caso no queremos redireccionar, ya que es por usabilidad el que tenga tantas rutas. Y mejor usar esto ya que no sé hasta que punto le dirá a Google cual es la buena, pero seguro que se lo dice mejor que si lo bloqueamos con el robots.txt aunque hay casos en los que no hay más remedio. Debermos hacer algún experimento con esto, a ver si valora los links que hay dentro. Si tomamos hacemos esto también deberíamos darle un sitemaps a Google sólo con las URL válidas. |
||||
| Link nofollow |
Si la apunta otra sin nofollow sí | Sí. La página a la que apunta si tiene más links desde otras. | No | No |
| Estos links creo que puden ser lo peor. Google hace con ellos lo que quiere, valorar no los valora, pero a saber lo que hace mañana. Yo los pongo por si acaso, pero no confío nada en ellos. |
||||
| Enlaces JavaScript |
No, si no se le enlaza desde orto sitio, cosa que suele pasar |
Igual que los links con nofollow, | No |
No |
En estos momentos son mis favoritos para evitar una fuga en el link juice hacia donde no quiero. Hay que camuflarlos un poco ya que los haces, no vale con poner <a href="javscriptwindow.location.href"> lo primero no debemos ponerlo con una etiqueta <a porque posiblemente por eso pueda contarlo también, mucho mejor con un <span Con este método nos podemos asegurar donde no queremos traspar nada de posicionamiento a esas páginas que no tienes interés en que salgan y así puedes distribuir el LinkJuice a otros links que sí te interesan. Como claro ejemplo están la página de contacto, la página de aviso legal, el comenta este artículo, y muchas más que se te irán ocurriendo que no quieres traspasarlas nada, y si esas páginas en vez de cuatro haces 1 con todo el contenido, mejor. |
||||
| Robots.txt | No | Sí, si recibe los links suficientes | No, se lo queda todo para ella |
Sí |
| Hay veces que trabajas con aplicaciones que no pueden identificar esa duplicidad de contenidos para insertar o no insertar el meta, entonces podemos usar el robots.txt .Lo malo, que estamos desperdiciando links que apuntan a esas páginas restringidas, y con ello malgastamos votos que hubieramos podido distribuir
a los demás links. Cuando la cantidad de contenido duplicado es muy grande, un buen método es acabar de raíz con el problema, y aunque estemos despilfarrando algo de link juice y de tráfico puede ser mucho mejor que ser penalizados por ello. Pero bueno, casi siempre hay soluciones menos drásticas. |
||||
Si antes de hacer la estructura de una web lo pensamos bien, no deberíamos usar casi nunca estos métodos. Seguro que se os ocurren más, supongo que cada uno habrá tenido que lidiar con su propio problema e igual ha encontrado una solución distinta. Cada web es cada web y hay que conocerla bien para poder tomar la mejor decisión.
¿Que más añadiríais?
Artículos en Como evitar contenido duplicado
4Cómo agrupar URLs para evitar contenido duplicado
El otro dia pariticipé en el evento SEO mas familiar organizado por Sico de Andres, el Seonthebeach
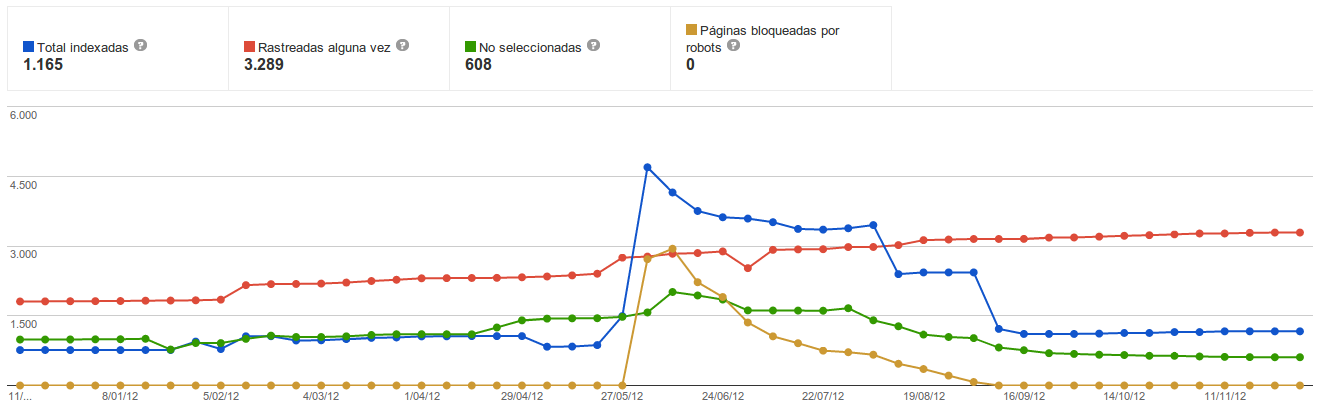
¿Cuál es la mejor manera de desindexar URLs?
Publicado el lunes 10de junio del 2013, By Lino Uruñuela Hoy debatiendo en una lista de correo me ha hecho pensar en cuál es el mejor método para desindexar una url, y claro todo depende de en cómo definamos lo que es desindexar una página y para que lo estamos usando.... Empezemos por definir que entendemos por desin…
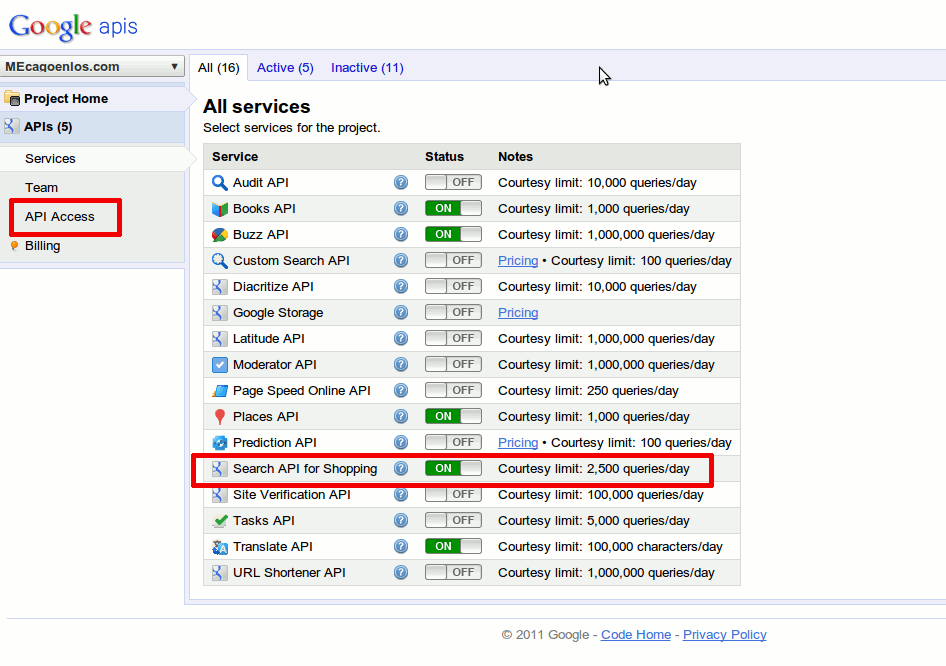
Como obtener datos de Google Shopping
Publicado el día 1 de junio del 2011, by Lino Uruñuela Ultimamente vivo obsesionado con diferenciar mi contenido del resto, algunas veces se me ocurren cosas ingeniosas y otras tengo que tirar por el medio como los burros, como en este caso... Con la nueva salida de Google Shopping Google también ha lanzado la API par…
Por qué Google no identifica la fuente original
Publicado el 14 de junio del 2010 Muchas veces Google ha comentado que lucha contra el contenido duplicado y que cada vez identifica mejor la fuente original, pero ¿que de cierto hay en esto? Yo comienzo a dudar que Google haga un esfuerzo claro por identificar cuál es la fuente original de un contenido (texto, imagen…
Comentarios
Todavía no hay comentarios publicados.