Por qué Google no identifica la fuente original
Muchas veces Google ha comentado que lucha contra el contenido duplicado y que cada vez identifica mejor la fuente original, pero ¿que de cierto hay en esto?
Yo comienzo a dudar que Google haga un esfuerzo claro por identificar cuál es la fuente original de un contenido (texto, imagen, vídeo, etc) , y es que puede que eso le de igual.
Google quiere satisfacer a su usuario (que no se nos olvide), a ese usuario que ha entrado a buscar algo y al cual Google intentará ofrecer los resultados que crea mejores para satisfacerle, no es su objetio mostrarle la fuente original sino la información más útil y puede que una página plagiadora tenga, además de ese contenido (copiado), otro contenido relacionado (también copiado) en otra sección que pueda complementar la información que busca el usuario. Si lo hace, Google habrá cumplido su función, dar al usuario lo que buscaba.
Vale que intente identificar páginas que copian webs enteritas de arriba abajo ya que esas páginas realmente no aportan nada, son meras copias. Pero no hace nada contra las páginas que van copiando de poco en pcoo, de aquí, de allá y que tienen más autoridad, más contenido y unos cuantos links más.
Si lo pensamos no sería muy difícil saber por parte de Google saber cuál es el contenido original, por ejemplo viendo la fecha que descubrió ese contenido. Vale que se equivoque alguna vez porque haya rastreado antes la página plagiadora que la fuente original pero serían la minoría de veces.
Otro método que podrían usar sería mirando los pings, ahí no habría ninguna duda, la página que antes envie el ping es la original sí o sí. Es cierto que para usar este método tendría que comenzar anunciándolo antes de ponerlo en práctica y evangelizando a los webmasters para que actualizasen sus sistemas y envien ping cada vez que se publica algo. No creo que los webmsaters tardasen mucho tiempo en hacerlo cuando se juegan el salir o no en los buscadores, al cabo de poco tiempo todas las páginas webs lo harían, de hecho la mayoría de gestores ya lo hacen como Worpress por ejemplo.
Entonces ¿por qué no hacen todo lo posible por identificar la fuente original? pues porque no es necesario para Google, aunque sea una putada para los creadores de contenido original.
Comentarios
4Lee otros artículos
Cómo agrupar URLs para evitar contenido duplicado
El otro dia pariticipé en el evento SEO mas familiar organizado por Sico de Andres, el Seonthebeach
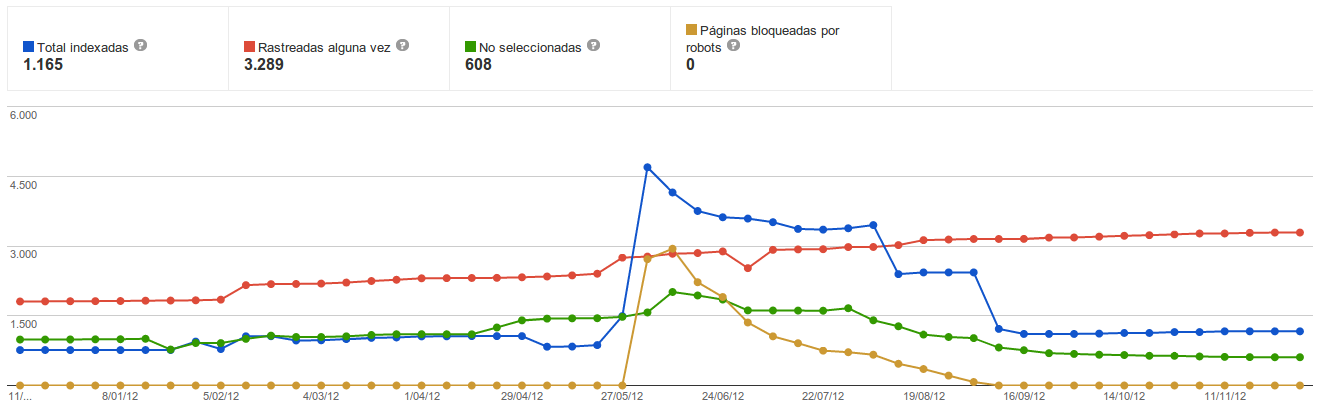
¿Cuál es la mejor manera de desindexar URLs?
Publicado el lunes 10de junio del 2013, By Lino Uruñuela Hoy debatiendo en una lista de correo me ha hecho pensar en cuál es el mejor método para desindexar una url, y claro todo depende de en cómo definamos lo que es desindexar una página y para que lo estamos usando.... Empezemos por definir que entendemos por desin…
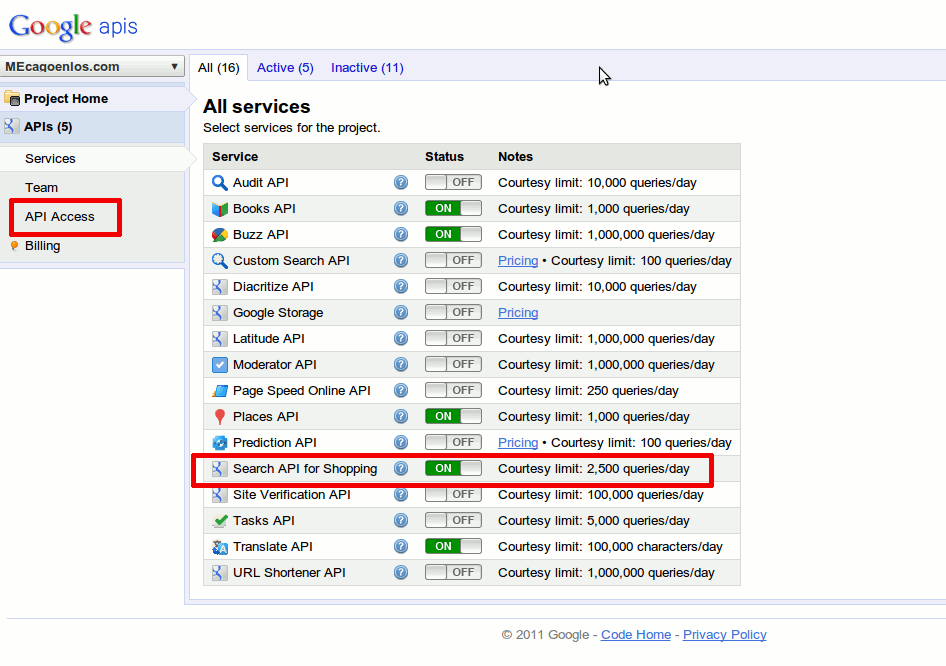
Como obtener datos de Google Shopping
Publicado el día 1 de junio del 2011, by Lino Uruñuela Ultimamente vivo obsesionado con diferenciar mi contenido del resto, algunas veces se me ocurren cosas ingeniosas y otras tengo que tirar por el medio como los burros, como en este caso... Con la nueva salida de Google Shopping Google también ha lanzado la API par…
El ping no hace falta que lo hagan los webmaster a google, ya google trabaja dia a dia, para hacer el ping al primero que publica jeje
@perico, el ping hay qwue enviarlo desde tu site, es un xml que se envía a una URL específica de Google. Saludos!
Yo tengo varias experiencias en este sentido. Y tampoco lo entiendo... tan sencillo como identificar la fecha de indexación por ejemplo... Yo me he limitado en algunos casos a remitir a google mi queja hacia ciertas webs que me plagian el contenido... y sin éxito.
Hola, a mi me clonaron una buena parte de un portal local, dando a los clientes el servicio a mitad de precio, con lo que más o menos voy siguiendo este tipo de temas porqué me perjudicó en diversos sentidos... a cual más molesto, y no tengo intención de que se repita. Siguiendo las recomendaciones de un amigo SEO, me limité a intentar contactar, y al no tener respuesta y dejé un mensaje al elemento en cuestión, con lo que no tuve ningún resultado. De todos modos si hay algo que hacer, puesto que se puede contactar con su proveedor de hosting, y éste (por lo menos si está en España) tiene que retirar los contenidos plagiados, lo mismo que si se trata de una sola imagen (que también me ha pasado). Lo que yo he experimentado, es que los contenidos duplicados perjudican tanto al plagiador como al plagiado. el primero apenas saca provecho (la programación de la página estaba bastante bien y era accesible, y a día de hoy apenas supera un Alexa 3.000.000). En cuanto a mi página, perdió entre un 30% y un 40% de las visitas (bastantes más de las que pueda tener en total la otra), por lo que supongo que debía copiar contenido de otros sitios. Este es un factor que el Pagerank tiene en cuenta, diría que si Google identifica contenidos duplicados lo que hace (ni corto ni perezoso) es castigar a todos los que los tengan sin entrar en más consideraciones. Por cierto, buena página, llevo un buen rato mirando qué podía aportar y me ha costadoo!!!