Google Sitemaps permite probar robots.txt virtuales
Según Google los robots rastrean una página según estos factores:
- Porque ya conoce la página.
- Porque otras páginas enlazan con ella.
- Porque la página está en el sitemaps.
También nos comenta que los robots no acceden a las páginas sino a URLs, porque la misma página puede ser accesible por medio de distintas URLs, un ejemplo:
- http://www.example.com/
- http://www.example.com/index.html
- http://example.com
- http://example.com/index.html
Y que en este caso, Google sumara 4 páginas en su índice, otro ejemplo en el que ocurre esto es cuando hacemos distintos links dentro de una misma página, por ejemeplo:
- http://www.example.com/mypage.html#heading1
- http://www.example.com/mypage.html#heading2
- http://www.example.com/mypage.html#heading3
O por medio de URLs dinámicas
- http://www.example.com/furniture?type=chair&brand=123
- http://www.example.com/hotbuys?type=chair&brand=123
Por estos motivos pude tener un mayor número de páginas indexadas en un sitio de las que realmente son. Cuando Google tiene 4 URLs distintas que realmente son la misma página, sólo mostrará una y nos dice cómo podemos elegir cuál queremos que sea esa página que nos muestre, como siempre con redirecciones 301 y tratando el archivo robots.txt .
Haciendo una redireccion 301 a la versión que nosotros prefiramos
Por ejemplo redireccionando los index de nuestros directorios a la raíz del directorio ej. de www.mecagoenlos.com/index.php a www.mecagoenlos.com/
Usando el robots.txt
Podemos bloquear el acceso a los robots a determinadas páginas, o páginas con parametros en la URL
ej. de robots.txt para bloquear páginas con parametros en la URL y así Google sólo coja la página principal
User-agent: * Disallow: /*?*
Y la gran novedad es que ahora escribimos nuestro robots.txt virtual y podemos ver el resultado que tendría sobre una página determinada de nuestra web ese robots.txt virtual que creamos en la herramienta de Google Sitemaps, así podrás comprobar que ese archivo hace lo que tú pretendías.
En el caso de que el robots.txt esté bloqueando esa URL que estamos comprobando te dice exactamente qué línea de tu robots.txt es la que no permite al robot de Google acceder. Parece ser que Google se ha dado cuenta del número desmesurado de URLs que tiene para algunos sitios, ya que este número se ve muy incrementado cuando usas parametros en la URL para por ejemplo ordenar resultados. Así intentará que los webmasters como siempre le facilitemos las cosas, por el bien de los dos.
Comentarios
1Lee otros artículos
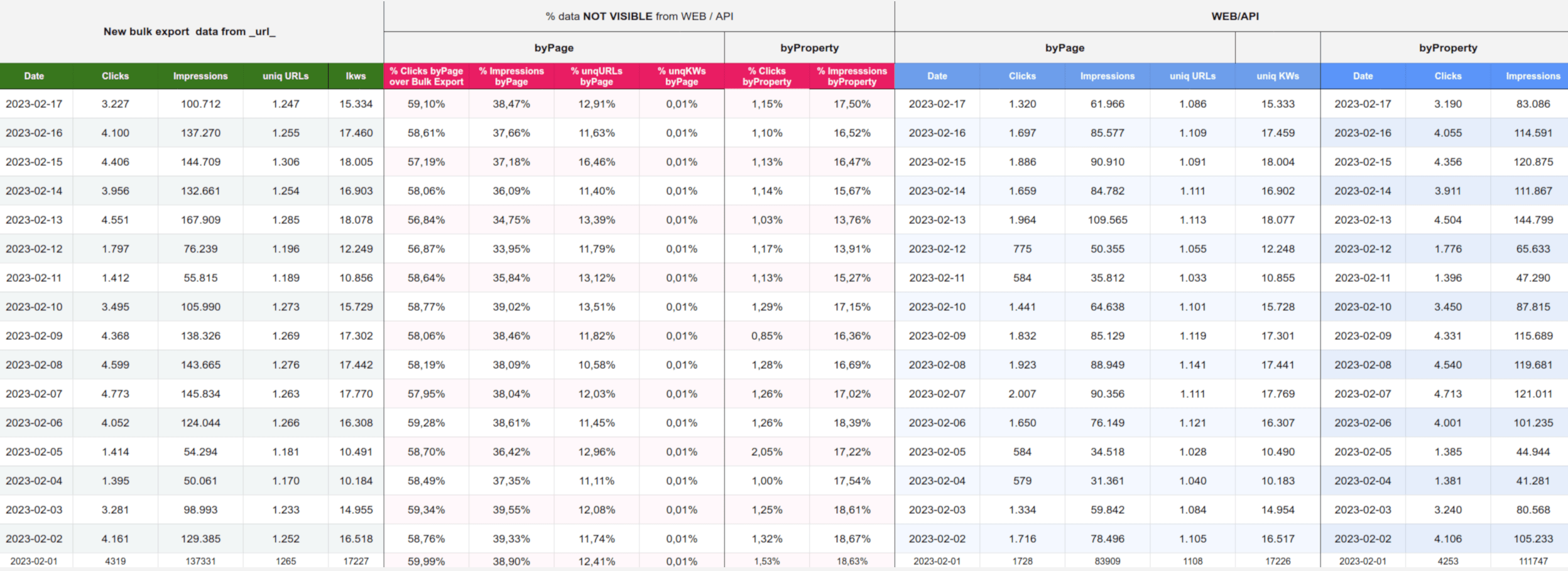
Diferencia de datos en Search Console para webs pequeñas dependiendo del método que usemos
Comparativa de los datos en la nueva exportación que Search Console a través de Big Query en sites PEQUEñOS
Diferencias entre la exportación de datos de Search Console usando BigQuery o usando la API
Características de la exportación de Search Console a BigQuery
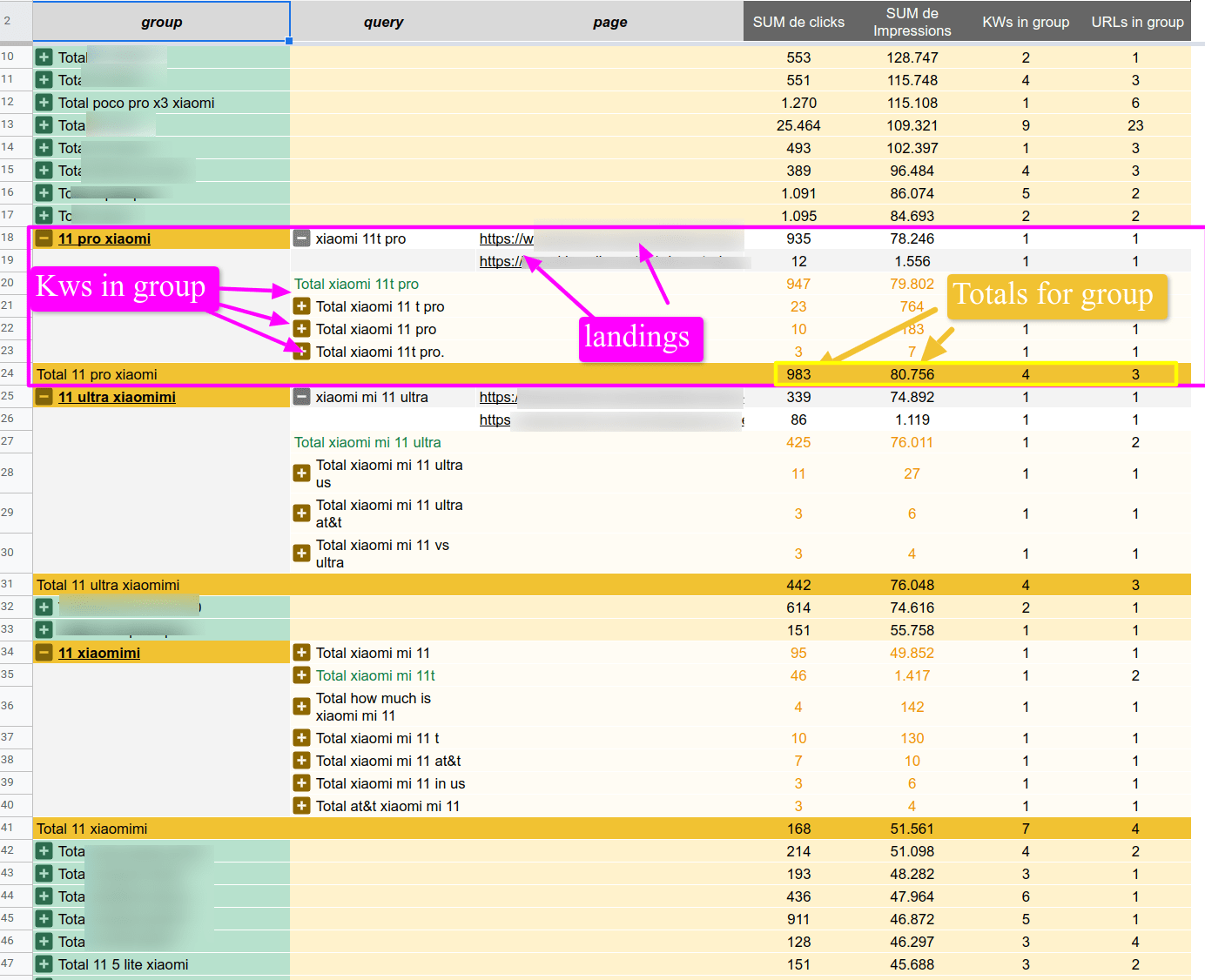
Keywords grouping using Google Search Console data
Publish at October, 25 of 2021 by Lino Uruñuela Table of Contents Classifying keywords vs. grouping search terms Classifying keywords based on a previously defined list Grouping search terms Usually, the simpler, the better it works. Looking at the code Create a dictionary for specific words Accept that there are thin…
Agrupación - Clustering de keywords SEO en Google Search Console
Publicado el día 30 de agosto del 2021 por Lino Uruñuela índice de contenido Agrupación de Keyword SEO Objetivos Tokenización Normalización Lematizació Vs Stemming Código Machine Learning para SEO Quiero dejar algo claro, no soy experto en Machine Learning, pero sí de sus tecnologías o hacia dónde va la cosa, que es m…
Expresiones regulares para SEO (Google Search Console)
Publicado el 8 de julio del 2021 por Lino Uruñuela Hace poco Google Search Console a nunciaba una de sus opciones más deseadas, poder filtrar usando expresiones regulares. No voy a ponerme a explicar qué son las expresiones regulares y para qué se pueden usar, ya hay información muchísimo mejor que la que yo pueda ofr…
Informe de experiencia en la página - Google Search Console
Por Lino Uruñuela Desde hace tiempo Google avisa e informa de determinados cambios en cómo trata, evalúa o muestra determinados resultados. En mi opinión, cuando Google avisa de algo con cierto margen de tiempo para que nos vayamos preparando es que no tendrá apenas repercusión, por ejemplo, tal y como ha hecho anteri…
Comprender los datos Google Search Console
Publicado el 14 de enero del 2021 Índice de contenido Límite de filas usando la API de Google Search Console Consultas por Propiedad o por Página Cuantas más dimensione, menos URLs únicas Algo que normalmente la gente que no se ha pegado mucho con los datos de Google Search Console no conoce es cómo funciona el l ímit…
Informes y gráficas usando la API de Google Search Console
Mediante la API de Google Search Console creamos informes que no podrás obtener mediante el interface web
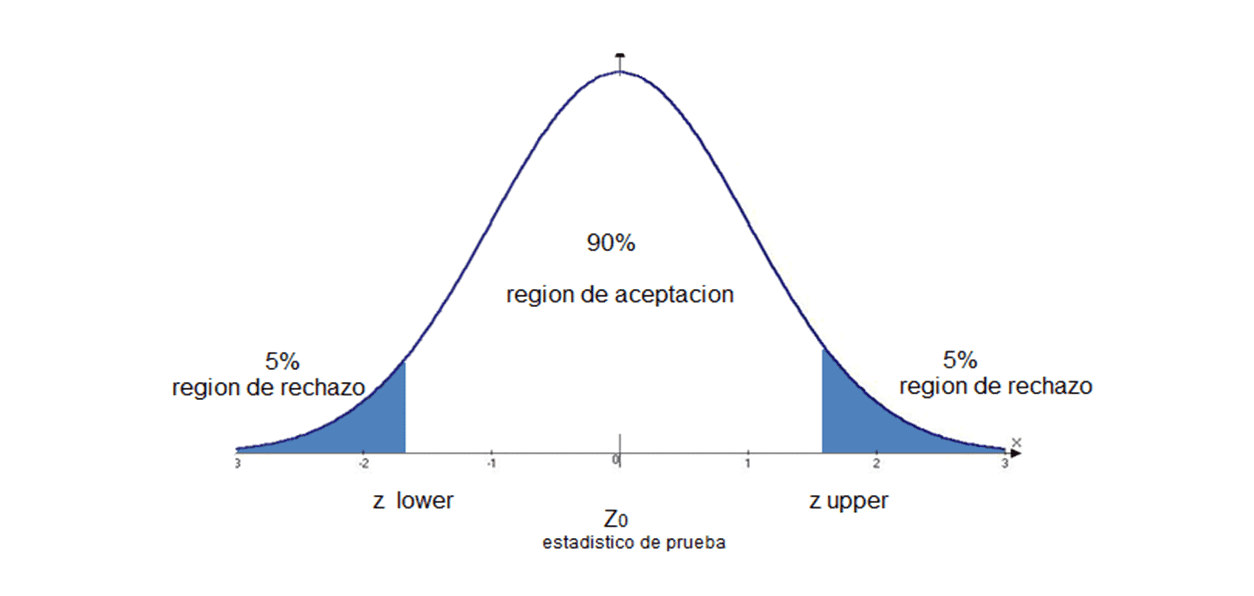
Datos incoherentes y cálculo de la posición media en Search Console
Publicado el lunes 29 de julio del 2019 por Lino Uruñuela Métricas Posición Cálculo de la posición media Impresiones Clicks Dimensiones Informe de Rendimiento vía Web Limitaciones del interface web Consolidación de datos Hace muchos años que Google lanzó Search Console , aunque su nombre inicialmente fue Google Sitema…
Consolidación de urls canónicas en Google Search Console
Publicado el 27 de febrero del 2019 por Lino Uruñuela En el año 2018 Google parece haber apretado el acelerador en el desarrollo y mejora de Google Search Console con nuevos diseños y nuevas funcionalidades, pero también desaparecen, al menos de momento, otras funcionalidades. No voy a entrar en cada novedad o cada fu…
Pero no sólo habla de las URL canónicas, con www o sin www, sino de todas en general y con las URLs dinámicas que sí pueden dar problemas.