Atacados por los .cn .cz .pl
Se venía viendo desde hace un mes como dominios .cn (también otros como .pl .cz) iban ascendiendo en los resultados de Google para términos no muy competidos. No sólo es que usaran técnicas ilícitas como copia de contenido automáticamente, red de páginas con enlaces a sitios .edu y sitios de referencia para enmascarar los suyos propios, además de todo esto te meten malware en el ordenador, sobre todo si usas IE7.
Por ejemplo en la búsquedas que llevan "pokemon ruby gamesharks" and "blue book." comillas. ATENCIÓN tener cuidado si entrais en los resultados de esas búsquedas, no sé si las limpiaron ya pero me da que alguna es de las que decimos que lleva malware. Si veis caracteres chinas ni se os curra. Si no, cuidado.
Ahora Matt Cutts hasta lo afirma, diciendo que ya tienen cambios preparados para arreglar el problema. No ha dicho cómo, claro está, pero se supone que será reducir sus sitios de confianza, siendo sólo unos pocos los que den autoridad en los links como. Si hiciese esto un link en un sitio de autoridad como pueden ser los .Edu (aunque a saber, porque también hay mucho spam en ellos), sitios como el New York Times, .gov, etc, eran de muchísimo más valor que ahora. Pero habrá que esperar a ver qué medidas toma.
Mucha más información en este hilo de WMW
Comentarios
1Lee otros artículos
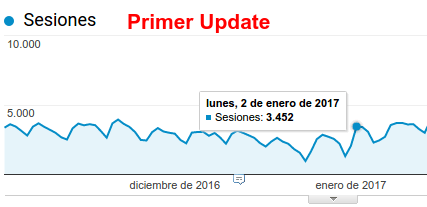
Google comienza el año con dos updates
Publicado por Lino Uruñuela el 23 de febrero del 2017 Este año 2017 ha empezado con movimientos comvulsivos en las gráficas de tráfico orgánico en muchas webs. Yo he notado varios updates de Google y con bastante impacto, vamos a resumirlos un poco. ¿Primer Update del año, 2 de enero? Comenzamos el día 2 de enero con…
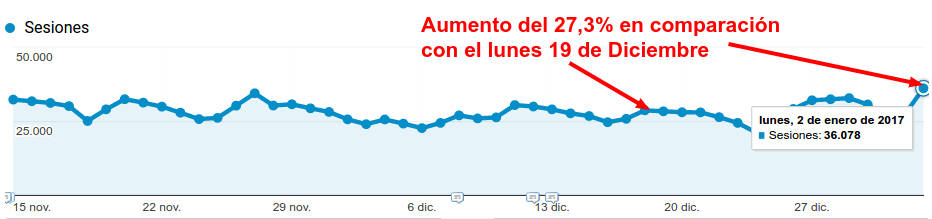
¿Christmas Update?
Publicado por Lino Uruñuela el 3 de enero del 2017, San Sebastián. Google no acostumbra a realizar cambios drásticos cuando llegan fechas críticas para los comercios, como por ejemplo en Navidad, donde se aumentan muchísimo las transacciones por causa de los regalos, y dónde un error podría hacerle perder mucho dinero…

¿Dosis de cafeína en Panda 4.0?
Publicado por Lino Uruñuela ( Errioxa ) el 27 de mayo del 2014 El otro día comentamos alguna cosa que percibimos con el último update de Google, Panda 4.0 , y decíamos que una de las cosas que más destacan es la reducción del número de resultados de un mismo dominio en la primera página de las serps. Ahora leo que Mat…
Nuevo Update de Panda, ¿qué ha cambiado?
Publicado por Lino Uruñuela ( Errioxa ) el 21 de mayo del 2014 Hoy nos hemos levantado con la confirmación por parte de Google de dos nuevas actualizaciones en su algoritmo, una Payday Loan Algorithm , que afecta búsquedas spam. Estas búsquedas suelen ser temas de porno de de "cómo ganar dinero" y cosas así y que no d…
El futuro es la búsqueda por voz
Publicado por Lino Uruñuela ( Errioxa ) el 29 de abril del 2014 Hoy he leído que Google Voice se va a extender a muchas más aplicacione de Google y no solo, como hasta ahora, a las búsquedas web (tanto en el móvil como en tablets, o el ordenador de sobremesa). En la cuestión de la búsqueda por voz, en vez de escribién…
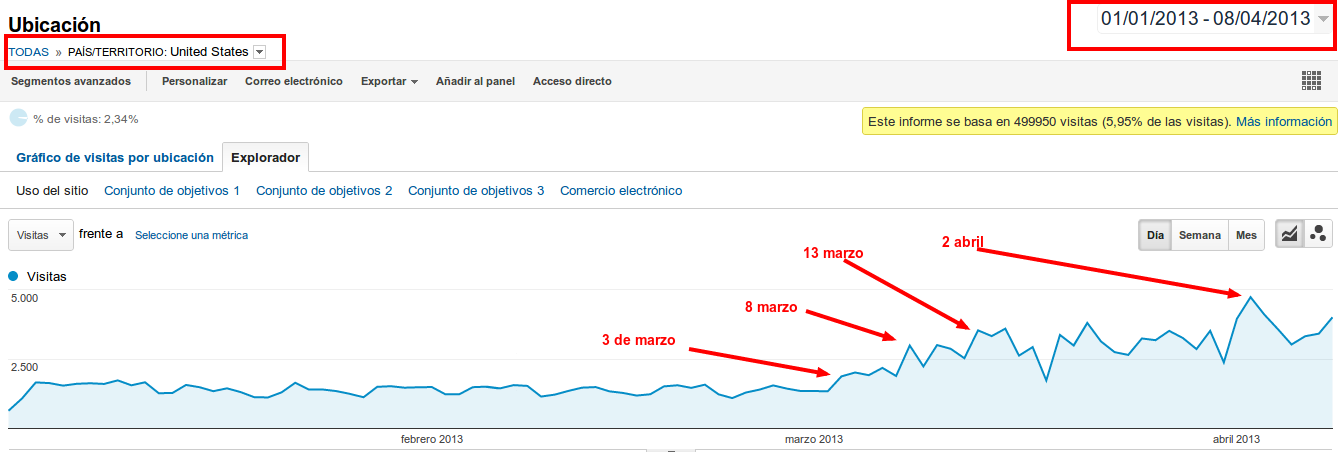
Aumento de visitas desde USA
Publicado el 10 de abril del 2013 by Lino Uruñuela Actualización: Sólo ocurre en el tráfico directo, en tráfico orgánico y tráfico de referencia no ocurre Desde comienzos de este mes de abril he notado algunos cambios en las visitas recibidas, al principio no sabía muy bien ya que coincidía con la Semana Santa y no es…
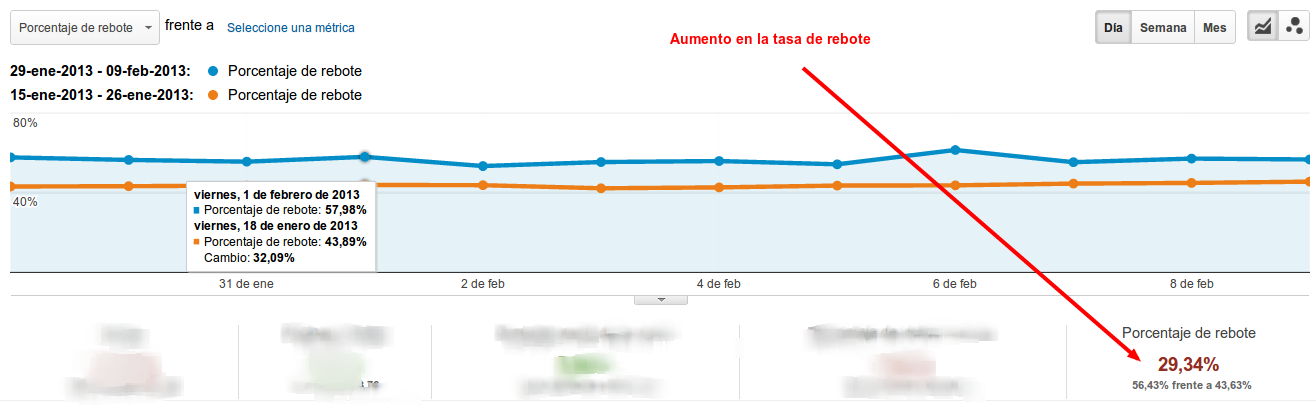
Atrapando al usuario en el nuevo Google Images
Publicado el 10 de febrero del 2013, by Lino Uruñuela ACTUALIZACIóN: El primer código del htaccess que puse al final del artículo tenía algún error. Estoy intentando hacer que funcione siempre, algo va mejorando. En estos momentos tengo así el htaccess, aunque parece que no llega a func ionar del todo . Con Firefox sí…
¿Cómo podría identificar Google las webs SEO?
Publicado el 20 de marzo del 2012 El otro día Matt Cutts comentó que en estas próximas semanas/meses habrá una actualización del algoritmo para identificar las páginas sobreoptimizadas en el aspecto SEO. Se ha comentado en varios sitios como WMT SER o SEL Los puntos que comenta la verdad que no son nada nuevo keyword…
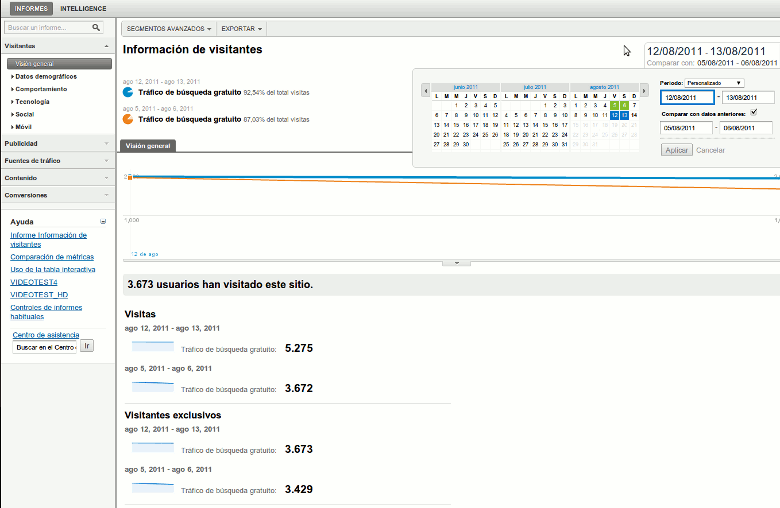
Cómo saber si estás afectado por Google Panda
Publicado el 14 de agosto del 2011, by Lino Uruñuela, Como bien sabemos todos Google lanzó el viernes la nueva actualización Panda . En un primer momento ha habido una euforia general porque todos veíamos como nuestras visitas subían en comparación con días anteriores pero es que Google Analytics ha aprovechado para c…
¿Pre-panda, Google caffeine o un poquito d ambas?
Pulbicado el 19 de junio del 2011 Ya se están viendo cambios en las estadísticas de muchos sites , ¿será Panda 2.2? Y es que el otro día Matt Cuts comentó que la actualización a Panda 2.2 llegará en breve, la verdad es que dijo que no era cosa de semanas sino de meses. Y justo unas semanas después comienza a ocurri es…
Gracias por la informacion!! Este tipo de blogs me parecen muy importantes, esto lo estudio en la universidad. gracias por la informacion. https://uautonoma.cl