Seo y logs (primera parte): Monitorización de Googlebot mediante logs
Una de las ventajas de analizar los datos de los logs es que podemos hacer un seguimiento de lo que hace Google en nuestro site, pudiendo desglosar y ver independientemente el comportamiento sobre urls que dan error, o urls que hacen redirecciones, o urls que son correctamente rastreadas.
Esta información nos es útil para poder ver rápidamente si está ocurriendo algo fuera de lo normal en tu site, o si por el contrario todo va según lo previsto. Muchas veces los SEOs definimos que urls deben dar un estado 200, o cuando deben hacer un tipo de redirecciones o si deben responder un código de error u otro.
Hay ocasiones en el que al hacer la implementación técnica se comete algún error de programación o un error en la definición que les pasamos, y que como consecuencia estemos dando algo erróneo a Google sin darnos cuenta,.
Hoy vamos a ver unos ejemplos de cómo con los logs obtendremos información útil sobre que está haciendo Google en tu site, de lo fácil que es darse cuenta de que algo ha ocurrido y de identificar dónde está ocurriendo.
Estos ejemplos son sacados de una tool propia que usamos en FunnelPunk con nuestros clientes, así cada día podemos comprobar de un vistazo si todo va bien.
En este ejemplo vamos a filtrar los logs de la siguiente manera
- Fecha: Desde comienzo de año
- User Agent: que contiene "Googlebot"
- Código de estado: = 200
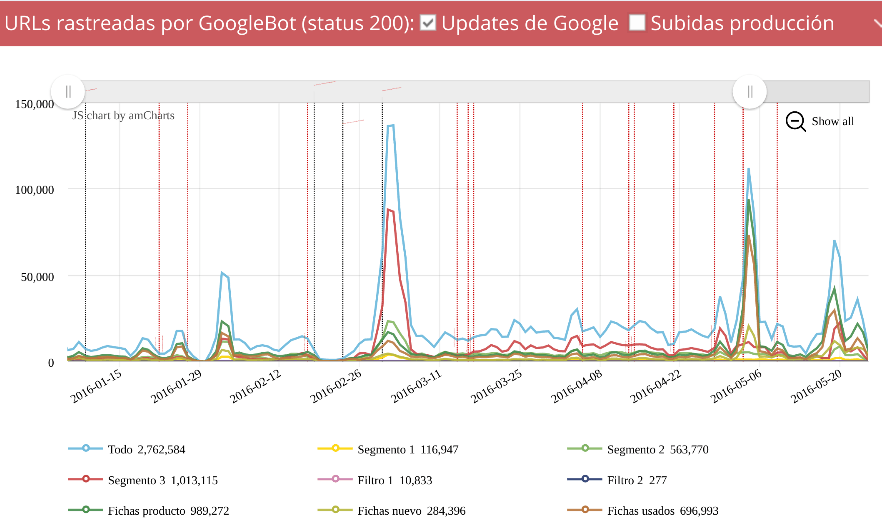
Y mostramos una gráfica como esta, la cual nos dice cuántas urls con estado 200 rastrea Google en nuestro site cada día
*Las líeneas verticales son guías que indican una implementación en el site para poder relacionar los cambios en el site con el comportamiento de Google.
Vemos como de repente en un día Google se puso a rastrear más de 100.000 urls mientras que anteriormente su frecuencia no era tan alta, algo había pasado. Y es que se cometió un error de programación que nos duplicó todo el site unas cuantas veces y creó miles de enlaces a páginas tanto correctas como inexistentes.
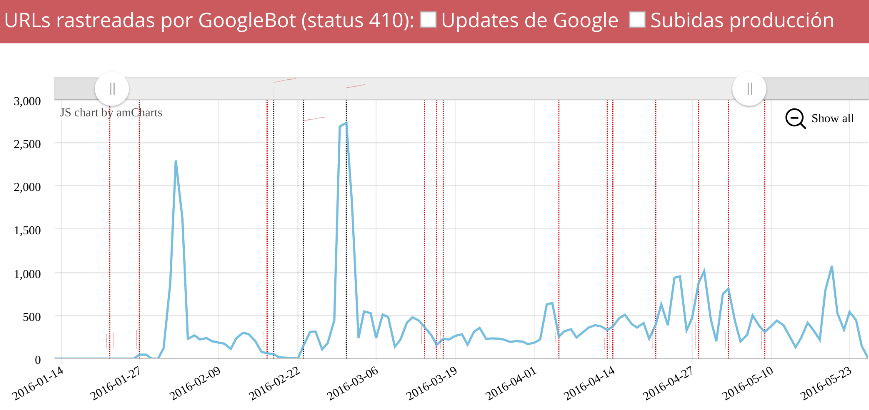
Filtrando
igual que antes pero en vez de código de estado = 200 lo hacemos por
los 410, vemos los distintos incrementos en este tipo de errores..
- Fecha: Desde comienzo del año
- User Agent: que contiene "Googlebot"
- Código de estado: = 410
No solo se crearon miles de urls correctas, también muchas dieron 410, pero ¿que fue lo que las causó? Para ello debemos segmentar el site por secciones, para saber en que secciones ocurrió y si fueron urls que antes daban 200 o han sido nuevas.
Podemos ver rápidamente como las fichas crearon el primer pico de 410, algo que era correcto ya que eran fichas caducadas que no daban tráfico y queríamos eliminar, pero vemos que el segundo pico se genera en los segmentos 3 y 2, las dos secciones que más tráfico orgánico aportaban al site.
Para facilitarnos la investigación podemos supoponer las visitas, obtenidas desde la API, esto nos dará una información vital para entender cómo afecto al site aquel error cometido.
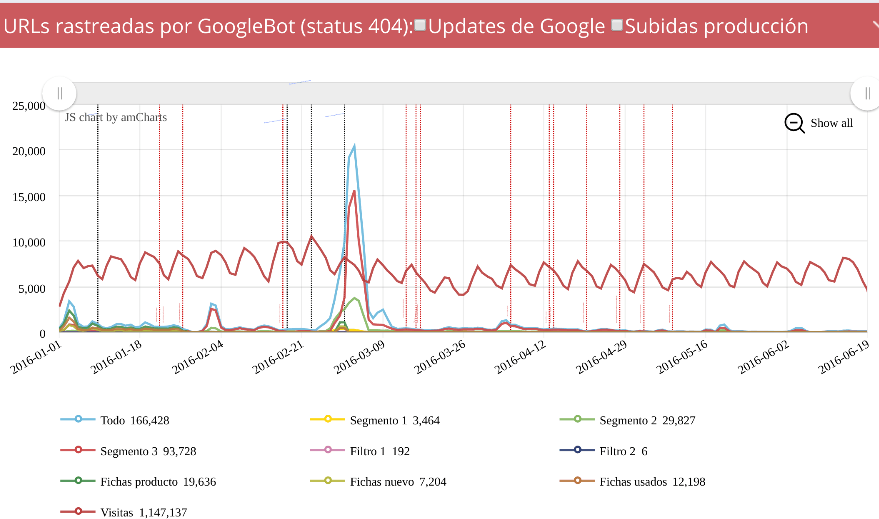
Como se ve, poco a poco se va recuperando el tráfico una vez resuelto los errores, pero claro, después de marear a Google con esos errores en miles y miles de urls, está siendo costoso, pero poco a poco parece que recupera :)
En el siguiente post veremos información igual o más útil que esta pero que no se puede representar en gráficos ;)

henry (@henry_muschett)hace Hace más de 7 años y 58 días
hola dar la gracias por el port bastante interesante.
les tengo una preguanta cuando uno tiene un server dedicado como puedo adquirir los log
Errioxa (@Errioxa)hace Hace más de 7 años y 57 días
@henry si tu sistema es linux suelen estar en /var/log/apache/access.log