Obtener KWs de varias fuentes usando la línea de comandos
Publicado el jueves 12 de febrero del 2024 por Lino Uruñuela
Hoy voy a mostrar lo útil que pueden ser los comandos de linux, yo los uso a diario, para una variedad de tareas como por ejemplo, ver datos de un fichero que tiene millones de filas, realizar transformación de datos y un sin fin de tareas!
Comando 'curl'
Veremos cuatro comandos, que unidos nos darán kws obtenidas de dos fuentes diferentes. Comenzaremos con el comando 'curl' que sirve para realizar conexiones http, ftp, etc, en el post de hoy nos centraremos en lo simple, descargar su contenido HTML y/o Json- Lo mejor es verlo en funcionamiento así que vamos con un ejemplo que descargará el contenido del un sitemap de un dominio determinado.
curl -s https://www.ejemplode.com/sitemap.xml
El resultado que nos devolverá este comando es el sitemap de este dominio:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>http://www.ejemplode.com/58-administracion/2735-ejemplo_de_acta_constitutiva.html</loc>
<lastmod>2023-02-17T18:56:02+00:00</lastmod>
<changefreq>daily</changefreq>
<priority>0.7</priority>
</url>
<url>
<loc>http://www.ejemplode.com/58-administracion/3032-ejemplo_de_acta_de_acuerdo.html</loc>
<lastmod>2023-02-17T19:14:23+00:00</lastmod>
<changefreq>daily</changefreq>
<priority>0.7</priority>
</url>
<url>
<loc>
http://www.ejemplode.com/58-administracion/3983-ejemplo_de_acta_de_entrega_de_activo_fijo.html</loc>
<lastmod>2023-02-17T19:23:59+00:00</lastmod>
<changefreq>daily</changefreq>
<priority>0.7</priority>
</url>
Es decir, con 'curl' descargamos el contenido del sitemap, pero también descarga el HTML o el XML, etc...
Tuberías, concatenando la salida de comandos
Algo muy importante es que la salida de un comando puede ser la entrada de otro cuando ponemos una barra '|', vamos a ver cómo funciona y aprovechamos para aprender otro comando otro comando muy común es el comando 'grep'.
El comando 'grep' filtra las líneas que contengan el texto que ponemos entre comillas, grep 'http' filtrará y mostrará únicamente las líneas que contienen el texto 'http'.
Comando 'grep' (filtra las líneas que contienen un texto)
Siguiendo nuestro ejemplo anterior, pongamos que queremos obtener únicamente las URLs, para ello, a la salida anterior que nos daba el comando 'curl' le aplicamos un filtro para filtrar las filas que contengan 'http'
curl -s https://www.ejemplode.com/sitemap.xml|grep 'http'
El resultado es
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<loc>http://www.ejemplode.com/58-administracion/2735-ejemplo_de_acta_constitutiva.html</loc>
<loc>http://www.ejemplode.com/58-administracion/3032-ejemplo_de_acta_de_acuerdo.html</loc>
<loc>http://www.ejemplode.com/58-administracion/3983-ejemplo_de_acta_de_entrega_de_activo_fijo.html</loc>
<loc>http://www.ejemplode.com/58-administracion/2864-ejemplo_de_acta_de_inventario_fisico.html</loc>
<loc>http://www.ejemplode.com/58-administracion/1470-ejemplo_de_administracion.html</loc>
<loc>http://www.ejemplode.com/58-administracion/1474-ejemplo_de_auditoria_administrativa.html</loc>
<loc>http://www.ejemplode.com/58-administracion/4632-ejemplo_de_bienes.html</loc>
Como podemos ver, se nos ha "colado" alguna línea que no nos interesa, concretamente '<urlset ....', porque también contiene 'http'. Podemos probar con otro patrón de texto por el que filtrar cada línea, por ejemplo '<loc>'
curl -s https://www.ejemplode.com/sitemap.xml|grep '<loc>'
Que nos da como resultado:
<loc>http://www.ejemplode.com/58-administracion/2735-ejemplo_de_acta_constitutiva.html</loc>
<loc>http://www.ejemplode.com/58-administracion/3032-ejemplo_de_acta_de_acuerdo.html</loc>
<loc>http://www.ejemplode.com/58-administracion/3983-ejemplo_de_acta_de_entrega_de_activo_fijo.html</loc>
<loc>http://www.ejemplode.com/58-administracion/2864-ejemplo_de_acta_de_inventario_fisico.html</loc>
<loc>http://www.ejemplode.com/58-administracion/1470-ejemplo_de_administracion.html</loc>
<loc>http://www.ejemplode.com/58-administracion/1474-ejemplo_de_auditoria_administrativa.html</loc>
<loc>http://www.ejemplode.com/58-administracion/4632-ejemplo_de_bienes.html</loc>
Algo hemos progresado, ya tenemos únicamente las filas que contienen URLs que nos interesan :)
Comando 'sed' (reemplaza un texto por otro)
Como tercer comando vamos a ver el comando 'sed' que en su manera simple lo que hace es remplazar un texto por otro, su formato es sed 's/original/sustituido/g'.
En este ejemplo sustituimos '<loc>' por nada
curl -s https://www.ejemplode.com/sitemap.xml|grep '<loc>'|sed 's/<loc>//g'
El resutlado es
http://www.ejemplode.com/58-administracion/2735-ejemplo_de_acta_constitutiva.html</loc>
http://www.ejemplode.com/58-administracion/3032-ejemplo_de_acta_de_acuerdo.html</loc>
http://www.ejemplode.com/58-administracion/3983-ejemplo_de_acta_de_entrega_de_activo_fijo.html</loc>
http://www.ejemplode.com/58-administracion/2864-ejemplo_de_acta_de_inventario_fisico.html</loc>
http://www.ejemplode.com/58-administracion/1470-ejemplo_de_administracion.html</loc>
Ha funcionado, pero si os dais cuenta, ha sustituido <loc> por nada, es decir, lo ha eliminado, pero nos queda al final '</lcc>', podemos aplicar otra sustitución con 'sed' como acabamos de hacer con este otro texto a eliminar '</loc>'
curl -s https://www.ejemplode.com/sitemap.xml|grep '<loc>' | sed 's/<loc>//g' | sed 's/<\/loc>//g'
Ahora ya tenemos las URLs que hay en el sitemaps
http://www.ejemplode.com/58-administracion/2735-ejemplo_de_acta_constitutiva.html
http://www.ejemplode.com/58-administracion/3032-ejemplo_de_acta_de_acuerdo.html
http://www.ejemplode.com/58-administracion/3983-ejemplo_de_acta_de_entrega_de_activo_fijo.html
http://www.ejemplode.com/58-administracion/2864-ejemplo_de_acta_de_inventario_fisico.html
http://www.ejemplode.com/58-administracion/1470-ejemplo_de_administracion.html
Limpiando y formatendo datos
Imaginemos que nos interesa obtener el texto de la URL que nos puede dar ideas para realizar un KW Research, nos gustaría quedarnos con las palabras 'ejemplo de acta constitutiva '.'ejemplo de acta de acuerdo '.'ejemplo de acta de entrega de activo fijo '.'ejemplo de acta de inventario físico '.'ejemplo de administración', como hemos visto antes podemos usar el comando sed para eliminar los patrones de estas URLs que no nos interesan, sed acepta expresiones regulares por lo que podemos usar una regex sencilla para lograrlo, por ejemplo.
Con el parámetro 'E' de sed indicamos que el 'texto_original' es una regex, y el '\1' indica que texto_sustituido será el valor capturado por los paréntesis de nuestra regex.
curl -s https://www.ejemplode.com/sitemap.xml|grep '<loc>'|sed 's/<loc>//g'|sed 's/<\/loc>//g' |sed -E 's/.*\.com\/.*\/[0-9]+-(.*)\.html$/\1/g'
Lo que nos devuelve:
ejemplo_de_acta_constitutiva
ejemplo_de_acta_de_acuerdo
ejemplo_de_acta_de_entrega_de_activo_fijo
ejemplo_de_acta_de_inventario_fisico
ejemplo_de_administracion
Solo nos falta sustituir el guión bajo por un espacio en blanco para tener unas KWs "limpias"
curl -s https://www.ejemplode.com/sitemap.xml | grep '<loc>'|sed 's/<loc>//g' | sed 's/<\/loc>//g' | sed -E 's/.*\.com\/.*\/[0-9]+-(.*)\.html$/\1/g' | sed 's/\_/ /g'
El resultado es:
ejemplo de acta constitutiva
ejemplo de acta de acuerdo
ejemplo de acta de entrega de activo fijo
ejemplo de acta de inventario fisico
ejemplo de administracion
Ya tenemos algunas ideas para nuestra web!! Si quisiéramos guardar estas URLs en un fichero simplemente tenemos que añadir al final '>>nombreFicheroSalida.txt', ya que '>>' indica que lo que iba a salir por pantalla lo guarde en un fichero.
Obteniendo sugerencias de Bing Suggests
Vamos a darle un poco de chicha.... Queremos emular la petición que el buscador de Bing realiza cuando introducimos texto en la caja de búsqueda que nos va sugiriendo términos de búsqueda más comunes dado el texto anterior, vamos el típico Suggests.
La URL a la que llamaremos la he obtenido desde mi navegador, si ves las llamadas (pestataña de 'red' en Chrome) cuando tecleas algo en la caja de búsqueda verás que se hacen llamadas a una URL con determinados parámetros / cabeceras. Este ejemplo es como si hubiésemos tecleado 'ejemplo de acta constitutiva' y nss ofrece otras KWs que contienen 'ejemplo de acta constitutiva'.
curl -s "https://www.bingapis.com/api/v7/suggestions?appid=B1513F135D0D1D1FC36E8C31C30A31BB25E804D0&setmkt=es-ES&q=ejemplo+de+acta+constitutiva" \
-H 'authority: www.bingapis.com' \
-H 'accept: */*' \
-H 'accept-language: es,es-ES;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6' \
-H 'origin: https://www.bing.com' \
-H 'referer: https://www.bing.com/' \
-H 'sec-ch-ua: "Chromium";v="116", "Not)A;Brand";v="24", "Microsoft Edge";v="116"' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'sec-ch-ua-platform: "Linux"' \
-H 'sec-fetch-dest: empty' \
-H 'sec-fetch-mode: cors' \
-H 'sec-fetch-site: cross-site' \
-H 'user-agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69' \
--compressed | jq ".suggestionGroups" | jq ".[].searchSuggestions" | jq ".[].query"
Las kws sugeridas para la palabra inicial 'ejemplo de acta constitutiva' son:
"ejemplo de acta constitutiva"
"ejemplo de acta constitutiva pdf"
"ejemplo de acta constitutiva de una empresa"
"ejemplo de acta constitutiva de una sociedad"
"ejemplo de acta constitutiva en mexico"
"ejemplo de acta constitutiva de un comité"
"ejemplo de acta constitutiva sociedad anónima"
"ejemplo de acta constitutiva word"
Ahora tenemos una lista de KWs sugeridas, que son las mismas que obtendríamos al ir tecleando la palabra inicial, en este caso era "ejemplo de acta constitutiva" y que nos vendrán muy bien:).
Encadenando comandos
¿Se os ocurre alguna idea con estas órdenes? Podemos encadenar la salida del sitemaps con el suggest de Bing de manera que por cada WK obtenida en el sitemaps nos devuelva las kws sugeridas!!
Para ello solamente vamos a modificar el último paso del comando dónde obtenemos las KWs del sitemaps, Si os fijáis, el comando anterior
curl -s https://www.ejemplode.com/sitemap.xml|grep '<loc>'|sed 's/<loc>//g'|sed 's/<\/loc>//g' |sed -E 's/.*\.com\/.*\/[0-9]+-(.*)\.html$/\1/g'
Esto nos devolvía;
ejemplo_de_acta_constitutiva
ejemplo_de_acta_de_acuerdo
ejemplo_de_acta_de_entrega_de_activo_fijo
ejemplo_de_acta_de_inventario_fisico
ejemplo_de_administracion
Pero la URL de Bing cuando tiene más de una palabra no acepta espacios en blanco, en vez de espacio en blanco debemos sustituirlos por el carácter '+'. Así que para conseguirlo añadimos este último comando encadenado '| sed 's/\_/+ /g'' obtendremos nuestras KWs con el formato adecuado
curl -s https://www.ejemplode.com/sitemap.xml|grep '<loc>'|sed 's/<loc>//g'|sed 's/<\/loc>//g' |sed -E 's/.*\.com\/.*\/[0-9]+-(.*)\.html$/\1/g' | sed 's/\_/+/g'Esto nos da
ejemplo+de+acta+constitutiva
ejemplo+de+acta+de+acuerdo
ejemplo+de+acta+de+entrega+de+activo+fijo
ejemplo+de+acta+de+inventario+fisico
ejemplo+de+administracion
ejemplo+de+auditoria+administrativa
ejemplo+de+bienes
caracateristicas+de+la+organizacon
caracteristicas+de+la+administracion
Bucle while
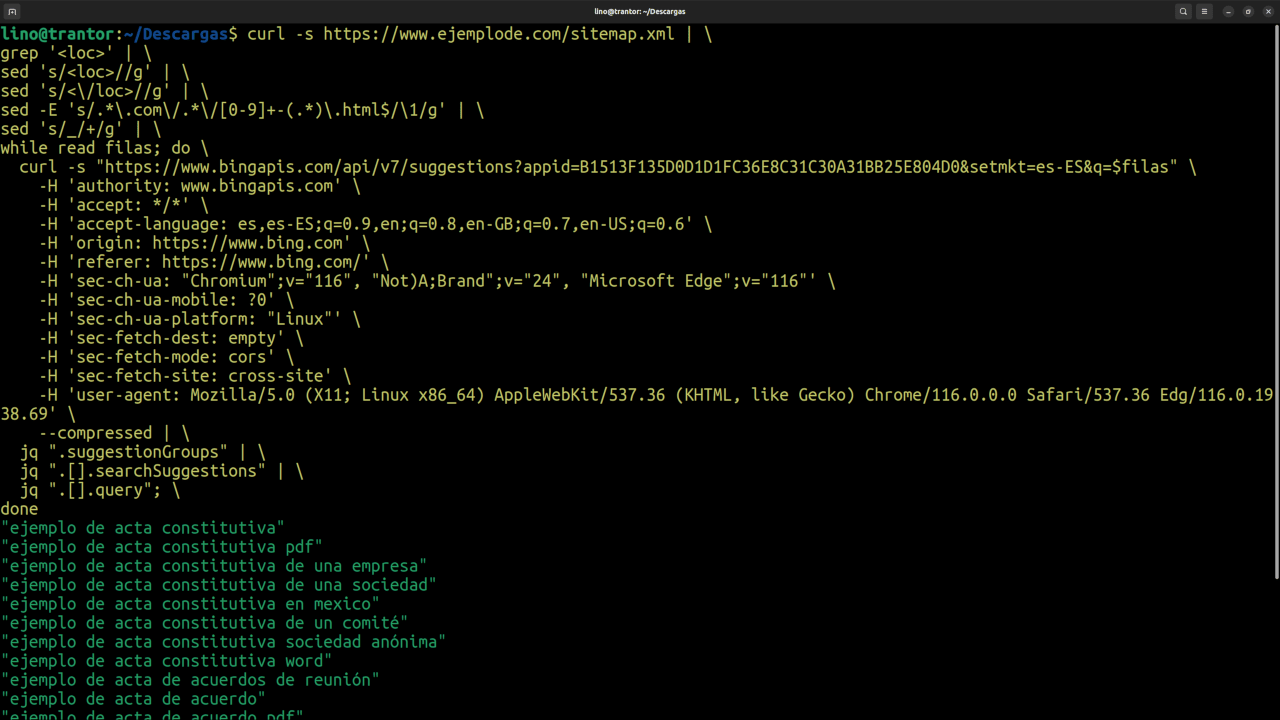
Hoy no voy a entrar a fondo con los bucles, lo dejaré para otro día, pero simplemente saber que podemos realizar diferentes comandos por cada línea que obtenemos de la salida de algún comando anterior. Por ejemplo en este caso lo que intentamos es que por cada KW que hemos obtenido del sitemap nos ofrezca las KWs sugeridas por Bing. Para esto usaremos 'while' que lee cada línea y ejecuta las órdenes que hay entre el 'do' y el 'done' del while :)
curl -s https://www.ejemplode.com/sitemap.xml | \
grep '<loc>' | \
sed 's/<loc>//g' | \
sed 's/<\/loc>//g' | \
sed -E 's/.*\.com\/.*\/[0-9]+-(.*)\.html$/\1/g' | \
sed 's/_/+/g' | \
while read filas; do \
curl -s "https://www.bingapis.com/api/v7/suggestions?appid=B1513F135D0D1D1FC36E8C31C30A31BB25E804D0&setmkt=es-ES&q=$filas" \
-H 'authority: www.bingapis.com' \
-H 'accept: */*' \
-H 'accept-language: es,es-ES;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6' \
-H 'origin: https://www.bing.com' \
-H 'referer: https://www.bing.com/' \
-H 'sec-ch-ua: "Chromium";v="116", "Not)A;Brand";v="24", "Microsoft Edge";v="116"' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'sec-ch-ua-platform: "Linux"' \
-H 'sec-fetch-dest: empty' \
-H 'sec-fetch-mode: cors' \
-H 'sec-fetch-site: cross-site' \
-H 'user-agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69' \
--compressed | \
jq ".suggestionGroups" | \
jq ".[].searchSuggestions" | \
jq ".[].query"; \
done
Y voila! por cada KW extraída del sitemaps, obtenemos una lista de kws sugeridas :)
Comentarios
1
Ya me has dado la necesidad de crear un comaando en bash para hacer estas cosas. Gracias Lino por estos tips