Errores críticos originados por el robots.txt
- ¿Qué es el robots.txt?
- ¿Para qué sirve el robots.txt?
- ¿Comprueba Google el robots.txt para cada URL que rastrea?
- Errores críticos ocasionados por el robots.txt
- ¿Cómo solucionar problemas causados porque nuestro robots.txt esté
inaccesible?
Hay cosas muy importantes sobre el robots.txt que mucha gente no sabía hasta hace poco y que a día de hoy no todo el mundo conoce.
Por ejemplo ¿sabías que si el robots.txt no está disponible los rastreadores asumirán que pueden rastrear todas las urls de la web? ¿o que si el robots.txt está inacesible los rastreadores no volverán a rastrear ninguna URL de tu web hasta que pueda acceder al fichero robots.txt?.
Pero antes de ver lo desconocido vamos a hacer un pequeño resumen de qué es el robots.txt y para qué sirve:
¿Qué es el robots.txt?
¿Para qué sirve el robots.txt?
¿Comprueba Google el robots.txt para cada URL que rastrea?
- Frescura del contenido
La probabilidad de que el contenido de una URL haya variado significativamente desde la última vez que realizó la comprobación. Esto nos dice que cuánto más se actualice el contenido de una URL, con más frecuencia accederá a esa URL.
- Relevancia de la url (PageRank)
El PageRank o popularidad de una URL también influye en su frecuencia de rastreo, cuánto más PageRank mayor frecuencia de rastreo.
- Políticas de rastreo
Existen ciertos límites que se deben cumplir, pueden ser límites generales a todos los sites como los recursos máximos de Google destinados al crawling, o pueden ser límites de host, que sería el presupuesto de rastreo de cada host (cuántos recursos destina Google a cada host).
También puede influir los límites dados por el propio site como podría ser la capacidad del servidor, es decir, cuántas urls por segundo es capaz de procesar el servidor sin perjudicar su velocidad de respuesta. Google irá modificando la frecuencia de rastreo para adaptarla a la capacidad de respuesta que tiene el servidor y así evitar que se sature.
- Obtiene una lista de urls a rastrear
Esta lista será un grupo con las siguientes URLs que toca rastrear, mejor que te lo cuente quién lo diseñó, lo explica aquí.
- Google comprueba las reglas definidas en el robots.txt para saber si puede o no acceder a cada
URL
Esta comprobación la realiza usando las reglas que obtuvo de la versión más reciente que tiene guardada del robots.txt, tal y como hemos comentado antes.
La frecuencia con la que Google actualiza el contenido del robots.txt se calcula en base a cuánto cambia su contenido, en la frecuencia de rastreo general para el host y en la popularidad o relevancia del dominio.
Es decir, Google no accede al robots.txt de todos los dominios con la misma frecuencia, sino que accede en relación a la probabilidad de que su contenido haya variado y en cuán popular sea el site, o mejor dicho, cuán populares son las URLs de ese host, cuanto más popular mayor frecuencia de rastreo para ese host y mayor frecuencia de accesos al robots.txt
De esta manera por ejemplo en un site de noticias que sea conocido y muy popular accederá con mayor frecuencia al robots.txt que en un site con su misma popularidad pero que apenas varía el contenido.
También accederá con mayor frecuencia al robots.txt de este periódico online que al robots.txt de un site que no es muy popular aunque se modifique el contenido con la misma frecuencia. - Actualiza el contenido y valores de cada URL después de acceder o intentar acceder a
ellas
- Para URLs que no están restringidas por el robots.txt
- Si no existe alguna versión previa de esa URL en su sistema, la creará con el
contenido actual de la URL.
- Si existiera una versión previa, comprobará si hay variaciones
significativas en comparación con la última versión que
tenía
guardada, y si las hay, actualizará el contenido de esa url en su sistema.
- Si no existe alguna versión previa de esa URL en su sistema, la creará con el
contenido actual de la URL.
- Para las URL restringidas por robots.txt
Actualizará la versión que tiene de esa url con los nuevos valores.
Dado que no le hemos permitido acceder a la url, para Google podríamos decir que el contenido de esa URL es nulo, y así lo valorará y tendrá en cuenta a la hora de rankear esa URL.
Esto hará mucho más improbable que se muestre como resultado de alguna búsqueda, pero no imposible.Podríamos decir que esas URLs tienen una enorme desventaja para posicionarse porque Google no puede evaluar su contenido, pero que aun así podrían estar indexadas y rankeando, independientemente de si son o no accesibles.
Si no tienes clara la diferencia echa un vistazo a este otro artículo dónde explico la diferencia entre URLs indexadas y URLs accesibles.
Tan verídico es que Google no accede a URLs restrijidas que muestra en sus resultados urls que dan un error 404 pero que al estar bloqueadas por robots.txt no puede acceder a ellas y no puede darse cuenta que esa url ya no existe... desde hace más de 10 años.
Aquí un ejemplo:

Si quieres comprobarlo tú mismo, aquí dejo los enlaces para ello:
- Realizar
la siguiente búsqueda en Google, y buscad el resultado que muestro en la
imagen de arriba.
- URL
de destino de ese resultado de Google, hacer click en el resultado para comprobar
cómo la url da error 404.
- Comprobar cómo esa url está bloqueada por el robots.txt de Google.com, concretamente lo bloquea la línea "Disallow: /search"
Otra vez comprobamos que aunque Google no pueda acceder a esa URL no impide que esté indexada y que podría rankear en los resultados de Google para determinados términos. - Realizar
la siguiente búsqueda en Google, y buscad el resultado que muestro en la
imagen de arriba.
- Para URLs que no están restringidas por el robots.txt
Errores críticos ocasionados por el robots.txt
Errores por definir reglas erróneas
Por ejemplo se podría impedir el acceso de Google a más URLs de las que pretendíamos y que no
nos hayamos dado cuenta de ello. Si estas URLs aportan mucho tráfico a nuestro site veremos las consecuencias
rápidamente de diferentes maneras:
- Descenso en el tráfico orgánico de Google Analytics para las urls restringidas.
- Bajada en el número de clicks en el informe de rendimiento de Search Console.
- Aumento del número de URLs bloqueadas por robots.txt en el informe de cobertura de Search Console.
El robots.txt no está disponible "archivo robots.txt no econtrado (404)"
|
"If a server status code indicates that the robots.txt
file is unavailable to the client, then crawlers MAY access any
resources on the server or MAY use a cached version of a robots.txt
file for up to 24 hours." |

Y esto podría ser un gran problema, porque que Google acceda a todas las urls de tu servidor, en determinadas webs puede ser algo muy negativo ya que Google podría rastrear muchísimas URLs innecesarias.
Por ejemplo si un site genera millones de urls para sus búsquedas internas (búsquedas que realizan los usuarios en el buscador interno de la web) Google podría rastrear e indexar todas esas urls.
Otro ejemplo podrían ser págins de clasificados, que suelen tener un gran número de posibles filtros y sus combinaciones y que podrían generar millones de URLs de muy baja calidad.
El robots.txt está inaccesible "Error al obtener el archivo robots.txt"
Se define como "inaccesible" cuándo la url da un código de estado con valor entre 500 y 599, simplificando, cuándo existe un error de servidor.
Google nos describe en esta tabla posibles errores que podrían causar el mensaje "url inaccesible".
|
"If the robots.txt is unreachable due to server or network
errors,this means the robots.txt is undefined and the crawler MUST assume
complete disallow." |


Aumento en el número de URLs con algún tipo de error
Además del problemón que es que no rastreé ninguna URL del site, debemos añadirle el ruido que nos meterá en el resto de URLs.
Y es que también provoca un aumento en el número de URLs que presentan problemas de
rastreo debido que cuándo intenta acceder a alguna URL del site, volverá a comprobar el robots.txt para saber si puede o no acceder lo que generará un error de rastreo para esa URL y la añadirá en alguno de los siguientes grupos.
-
Error - robots.txt ha bloqueado la URL enviada

Google marca como Error algunas urls que no ha podido rastrear debido a que el robots.txt es inaccesible.
-
Warning - Se ha indexado aunque un archivo robots.txt la ha bloqueado

Para otras URLs, que presentan el mismo problema, Google las marca como Advertencia, y dice que la URL se ha indexado a pesar que ha sido bloqueada por el robots.txt.
¿Querrá decir que las URLs añadidas a este mensaje son más valiosas paara Google?. Podríamos pensar que si aun estando restringidas por robots.txt (ya sea por fallo o adrede) aun así las indexa podría indicarnos que por alguna razón Google las considera importantes. Posiblemente sea por la cantidad de enlaces que reciben.
-
Excluida - Bloqueada por robots.txt

Este grupo de URLs tienen el mismo problema que las anteriores, pero Google las marca como excluidas.
Si seguimos el mismo razonamiento que en el caso anterior, ¿será un indicio de que estas URLs tienen poco valor, o menor valor, que las urls que sí ha indexado a paser de que el robots.txt las bloqueaba?
Me parece un punto interesante a observar, para intentar comprender por qué URLs con el mismo tipo de problema, con el mismo origen pero sin embargo Google las cataloga de diferentes maneras....
Todo esto se genera porqué el robots.txt no es accesible! añadiendo ruido a los datos de Google Search Console.
En vez de indicar un único error, al no poder acceder al robots.txt, Gogole va acumulando errores para cada URL que le teocaba rastrear....
Así que vamos a ver cómo comprobar si el robots.txt tiene problemas de rastreo
¿Cómo saber si Google no puede acceder a nuestro robots.txt?
Identificar cuándo Google no puede acceder al robots.txt no es algo que se vea a simple vista, y si no te has topado con ello antes puede que lo pases por alto.
Mediante el Probador de robots.txt





Mediante el Inspector de URLs de Google Search Console


¿Cómo solucionar problemas causados porque nuestro robots.txt esté inaccesible?
- Configuración del servidor, firewall, CDN u otras causas que impiden el acceso de Google al
robots.txt (o a todo el servidor)
- El servidor está o estuvo caído, las causas podrían ser demasiadas peticiones en poco tiempo, error de programación, error de red, y otras posibles causas que "tumban" el servidor y son ajenas a la configuración.
- Desde el probador de robots.txt
Este método no garantiza que lo actualice en ese mismo momento, al menos si lo haces más de una vez, la primera vez lo seguramente lo actualice, pero la segunda vez, si no ha transcurrido cierto tiempo no lo hará aunque te indique lo contrario.

- Desde el Inspector de URLs:
Solicita que inspeccione cualquier url del site, esto hará que compruebe en ese momento el robots.txt, CREO, y que actualice la versión que tiene del robots.txt.
Si muestra el error "robots.txt ha bloqueado la url enviada" pero realmente no lo está, es que Google no puede acceder al robots.txt y deberías investigar el por qué.
Si por el contrario, ha accedido correctamente y el robots.txt es, al menos, accesible (por ejemplo da un 404) no te mostrará ese mensaje sino que mostrará algún otro, por ejemplo diciendo que Google no reconoce esa URL, pero no que el robots.txt se lo ha impedido:

O que indique que esa url está en indexada en Google:

Comentarios
9Lee otros artículos

¿Es necesario comenzar con slash la directiva Disallow?
Publicado el viernes 26 de febrero del 2016 por Lino Uruñuela El otro día, mi socio Natzir me pasó el tweet de John Muller donde indicaba que la directiva Disallow del robots.txt debía comenzar siempre con un slash "/". Esto ha provocado cierto revuelo entre los SEOs, muchos de nosotros no hemos tenido nunca esta prem…
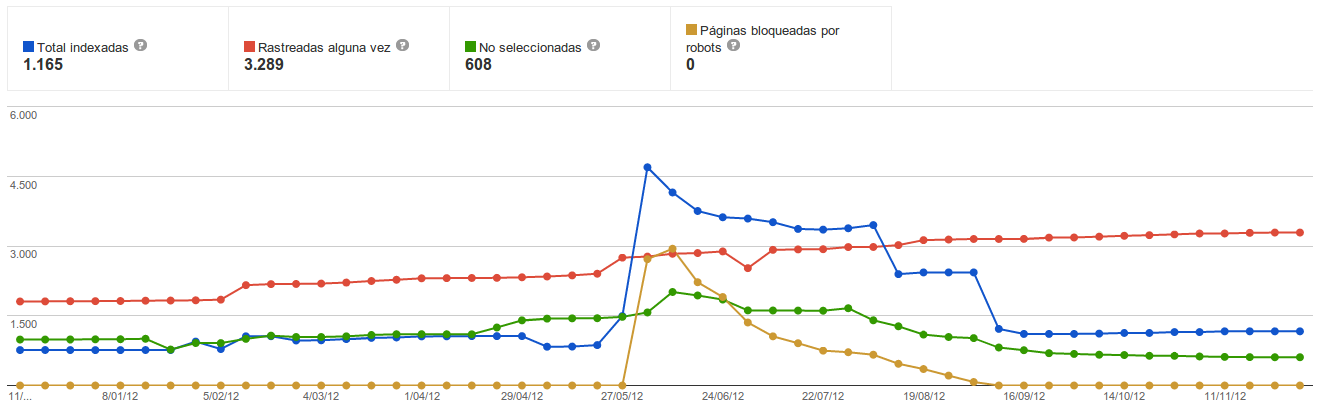
Cuando restringes por robots.txt puedes aumentar el número de URLs indexadas
Publicado el 3 de diciembre del 2012, by Lino Uruñuela Llevo unos cuantos meses observando un comportamiento algo contradictorio al restringir URLs desde el robots.txt. Supuestamente en el robots.txt puedes restringir el acceso a los buscadores como Google, para así no indexar y que no se muestre en las búsquedas resu…
PR sculpting con JavaScript y Robots.txt
Publicado el 28 de febrero del 2010 Ya vimos como hacer PR sculpting usando JavaScript , así, independientemente de cómo Google quiera valorar los enlaces nofollow ( a veces nos dice que valen para pr sculpting y otras nos dice que no ) nos aseguramos que el peso de una url lo traspasemos exactamente entre los links q…
Otra forma de hacer PageRank sculpting
Publicado el 4 de junio del 2009 Se está montando un pequeño revuelo en el mundo SEO a costa de unas declaraciones de Matt Cutts en el SMX advance (no, el de Madrid no) acerca de la nueva manera en que Google trata los enlaces con nofollow. Antes Hasta ahora si tenías 10 enlaces en una página web, la fuerza que traspa…
Lino estoy haciendo un experimento y tengo una duda, si en una web donde puedes crearte un perfil de usuario capan mediante Robots.txt, pero haciendo site: ha indexado unas pocas Urls de perfiles. Mi pregunta es ... Puedo hacer que google indexe mi perfil forzando con enlaces? Que ha tenido en consideración Google a la hora de indexar esas URLs de perfiles y no otras? Tal vez no me he explicado bien o he dicho una tontería. Espero curioso tu respuesta.
@Xavier que Google no pueda acceder no significa que no pueda indexarla. Lo que no hará es entrar, y por lo tanto, no podrá ver el contenido. Así que se puede posicionar pero para KWs muy poco frecuentes si la enlazas con ese texto. Arriba he puesto un ejemplo dónde sale una url que da 404 pero está restringida por robots.txt por lo que la sigue mostrando en las serps ya que no puede saber (al no poder acceder) que esa url da 404
@Lino probando mi script del futuro
Buenas Lino, No sé si me podrás echar una mano, estoy intentando comprobar porque Google no puede acceder a mi robots.txt, incluso he eliminado el fichero robots.txt de mi sitio web y cuando sigo intentando acceder a través de robots.txt testing tool obtengo el mismo mensaje de "Tienes un archivo robots.txt que en estos momentos no podemos obtener." aunque este ya no exista, la verdad que google no está indexando mi sitio web desde unos días y no sé como solucionar este problema. Me han comentado que puede ser debido a no tener binding https ?? Un saludo.
Hola Miriam, crea un robots.txt vacío para probar, también podrías añadir uno básico con las dos siguientes líneas User-agent: * Allow: /* Una vez creado y comprobado que puedes acceder a él desde cualquier navegador, sigue estos pasos: <ul> <li>Ve al <a href="https://www.google.com/webmasters/tools/robots-testing-tool?hl=es&siteUrl=">viejo probador de robots.txt</a> y solicita a Google que actualice la versión del robots.txt <img src="https://www.mecagoenlos.com/fotos/probador-robots-txt-error-1.png" alt="Solicita a Google que actualice la versión del robots.txt" class="img-responsive"> Y luego <img src="https://www.mecagoenlos.com/fotos/probador-robots-txt-error2.png" alt="versión del robots.txt" class="img-responsive"> </li> <li>Si no te da problemas, ya debería estar solucionado!</li> <li>Si te muestra algún mensaje de error, vuelve al blog y seguimos indagando :)</li> <li>Desde el probador de robots.txt puedes ver si Google ha tenido algún error al acceder al robots.txt para ello debes darle a la flechita que señalo en verde. <img src="https://www.mecagoenlos.com/fotos/probador-robots-txt-error.png" alt="URL Bloqueada por robots.txt" class="img-responsive"> </ul> Saludos
Complementando la respuesta (y aprovechando para comprobar mi "avisador" por Twitter), por si Google no pudiese acceder al robots.txt y no supieras por qué, os dejo aquí este enlace dónde enumero algunas posibles causas. Saludos, @errioxa
Hola Lino, tengo el mismo problema. El probador de robots de google me indica: "Error al obtener el archivo robots.txt Tienes un archivo robots.txt que en estos momentos no podemos obtener. En estos casos, dejamos de rastrear tu sitio web hasta que conseguimos un archivo robots.txt o usamos el último archivo conocido en buen estado" y en google search al inspeccionar alguna de las URL indexadas me aparece el siguiente mensaje: "Se han detectado problemas de indexación en la URL durante la prueba de versión publicada" "Solicitud de indexación rechazada". He eliminado el archivo robots y he creado uno nuevo, intento actualizarlo en el probador de google pero me indica "No se ha podido realizar. Vuelve a intentarlo más tarde". No sé que más puedo hacer... llevo varios días con este problema y no sé cómo solucionarlo. Agradezco mucho tu ayuda. Gracias!!
@María un placer verte por aquí :) Lo primero, a veces, con el robots.txt no se puede "forzar" a que lo rastree, si tu site no es muy popular y no cambia con frecuencia el contenido Google determina que necesita acceder solamente de vez en cuando por así decirlo. Entonces, lo importante es saber y asegurar que ahora Google sí podría acceder al robots.txt correctamente - ¿has probado a acceder al robots.txt como si fueses Google (cambiando el User Agent del navegador)? - ¿En qué fecha el robots.txt fue la última vez que tuvo estado 200? Puedes mirar la imagen del anterior dónde explico cómo puedes comprobarlo Saludos!
Sí, he buscado el archivo robots.txt y todo está correcto. La última versión vista con error fue el 08/11/2021 y la última vez que el proceso fue correcto (200) fue el 13/10/2021.