Test 2 sobre indexacion de Google usando JavaScript , y resultado del Test 1
El pimer experimento sobre si es capaz de rastrear contenidos cargados mediante Ajax tras la acción del usuario y hoy podemos comprobar que sí, Google es capaz de rastrear e interpretar los contenidos cargados mediante Ajax, ya sea con o sin jQuery.
Podemos comprobar como al buscar la kw, google muestra resultados, concretamente devuelve la url desde la que se carga el contenido y no la url desde donde se le llama, yo creo que sería lo ideal...
Podríamos pensar que simplemente Google ha visto las urls en el código fuente, en la función de javascript y que ha probado a ver si descubria algo, ya que muchas veces lo hace con cualquier trozo de código que se pueda parecer a una url, cosa que a veces puede dar más de un dolor de cabeza a los webmasters ya que estos errores de URLs que intenta intuir pero que realmente se "inventa" Google nos salen mostradas en WMT como un error...
Pero si nos fijamos en el título del resultado en las serps hay un detalle clave.

Vemos como Google muestra como título del resultado el mismo texto que usamos para que el usuario generara el evento que hacía cargar el contenido mediante Ajax.
Me resulta extraño que si es capaz de ejecutar el evento, no muestre como url del resultado la página desde donde se llama a este contenido, ya que el mostrar esta otra url puede no tener mucho sentido en la mayoría de los casos, ya que normalmente será contenido fuera de contexto y que es muy posible que no genere al usuario la información que necesitaba,
La impresión de que Google es capaz de asignar el texto que provoca la carga de contenido, que en este caso está en un y con un evento onClick, a la url desde donde lo carga. Podría significar que sabe que ese texto con la interacción del usuario provoca esta carga del contenido.
Ahora vamos a ir un paso más allá, y vamos a comprobar si Google es realmente capaz de ejecutar JavaScript. Para ello usaremos dos técnicas.
Objetivo de este experimento
El objetivo del test es comprobar si realmente Google es capaz de ejecutar este código para cargar contenido mediante Ajax, o si bien el resultado del experimento anterior es debido a que siempre que ve en el código fuente algo parecido a una URL intenta indexarla
- Usando base64 para codificar la url del enlace desde el servidor
En vez de pasar en el evento onClick como parámetro de la función una URL, vamos a intentar camuflar esta url para que no lo parezca, e intentar averiguar si Google indexó el contenido cargado por Ajax porque vió algo parecido a una URL o si es que realmente ejecutó el código.
Esta vez solo ejecutando el código se pueda decodificar la URL.
En el código fuente podéis ver cómo el texto que hace la llamada Ajax no contiene una url, está codificada, y veremos si Google es capaz de descubrirla e indexarla.
Si Google ejecutara JavaScript, debería resolver fácilmente la url y actuar como en el anterior experimento, y cargar el contenido mediante ajax con este otro enlace, que si miráis el código funete no veréis en el nada parecido a una URL - Segundo test, usando una función JavaScript y un window.location.href
La url del fichero Ajax que nos devolverá contenido será creado al juntar distintas partes de una cadena que a priori no tiene el patrón de una URL.
Con esto intentaremos comprobar si ejecuta las órdenes que unen las cadenas para crear la url final, y ejecutar el window.location con un eval.
Para entenderlo tenemos debajo el código fuente de este test, y este es el enlace que ejecuta la función al hacer onCLick y llevará al navegador a la url de prueba, a ver si la indexa.
El código que realiza el segundo test usa la función eval que pasa la url por "trocitos" y reemplaza @ por slash "/", dolar "$" por guión medio, y guion bajo "_" por punto "."
Si ejecuta el código JavaScript la función de abajo formará la URL y ejecutara el window.location.href.
<span onclick='DesglosaEnlace("www_mecagoenlos_com@archivoAjax_php?otroContenido=coneval");'
style="color:#FF0000;cursor:hand;cursor:pointer;">enlace</span>
function DesglosaEnlace(enlace){
trozoUrl = "'http://";
}
trozoOrden ="window.";
trozoOrden2 ="location.";
trozoOrden3 = "href=";
enlace_bueno = enlace.split("@").join("/");
enlace_bueno2 = enlace_bueno.split("$").join("-");
enlace_bueno3 = enlace_bueno2.split("_").join(".");
split(trozoOrden+trozoOrden2+trozoOrden3+trozoUrl+enlace_bueno3+"'");
Este texto va a ser sustituido por el contenido en Ajax
Este es el código javaScript que ejecuta este "enlace camuflado", como se puede observar, a primera vista no hay nada parecido a una url
Primer test, usando codificación en Base 64
function b64_to_utf82(str) {
return decodeURIComponent(escape(window.atob(str)));}
function cargarDivCodificado(div,url) {
$(div).load(decodeURIComponent(b64_to_utf82(url)));}
<span onclick='cargarDivCodificado("#contenido","Li4lMkZhcmNoaXZvQWpheENvZGlmaWNhZG8ucGhw")'
style="color:#FF0000;cursor:hand;cursor:pointer;">con este otro enlace</span>
Comentarios
3Lee otros artículos
Cómo se adapta Googlebot al tamaño del contenido
Publicado por Lino uruñuela el 9 de febrero del 2021 índice Un poco de historia sobre Google y JavaScript en este blog Datos del último experimento Código JavaScript para capturar el evento resize Código JavaScript Código en .htaccess Fichero ResizeRenderizadoJS.php (PHP) Datos del último experimento Observaciones sob…
Cómo saber qué errores JavaScript genera Google cuando ejecuta JavaScript
Publicado por Lino Uruñuela el 1 de febrero del 2021 Ya hemos visto cómo podemos comprobar y monitorizar qué URLs renderiza Google, pero si queremos ir un poco más allá también podemos capturar y guardar en Google Analytics qué errores JavaScript se producen cuándo Google ejecuta el código JavaScript para renderizar e…
Cómo ver las URLs renderizadas por Google en Google Analytics
Publicado por Lino Uruñuela el 1 de febrero del 2021 Desde hace unos cuántos años Google está produciendo grandes avances en su capacidad rastrear y obtener el contenido cargado por JavaScript, tal como lo haría un usuario navegando desde un dispositivo móvil. Para ello deduzco que ha debido hacer grandes cambios en s…

Diferentes métodos para indexar contenido JavaScript - Ajax
Webs en JavaScript, metodos para la carga de contenido rastreable por Googlebot esta. basado en Chrome 41 sí soporta determinadas funcionalidades posteriores al número de su versión, pero no sabemos cuáles.
Carga de imagenes usando lazy load - Resultado del experimento
Publicado el 15 de febrero del 2019 por Lino Uruñuela índice de contenido Métodos probados en el experimento Carga normal, sin lazy load Imagen usando thubmnail de posición Cargar imagen desde desde data-src Imagen usando thubmnail de posición y noscript Sin usar thubmnail pero sí noscript Sin usar thubmnail ni tampoc…

Indexar imágenes en Google usando Lazy Load
Publicado el 23 de diciembre del 2018 por Lino Uruñuela índice de contenido ¿Qué es lazy load? Diferntes maneras de cargar imágenes medidante lazy load Miniatura de posición Usar < noscript > y miniatura de posición Añadir estilos para eliminar <noscript> Cómo aegurarnos que las imágenes serán indexables&l…
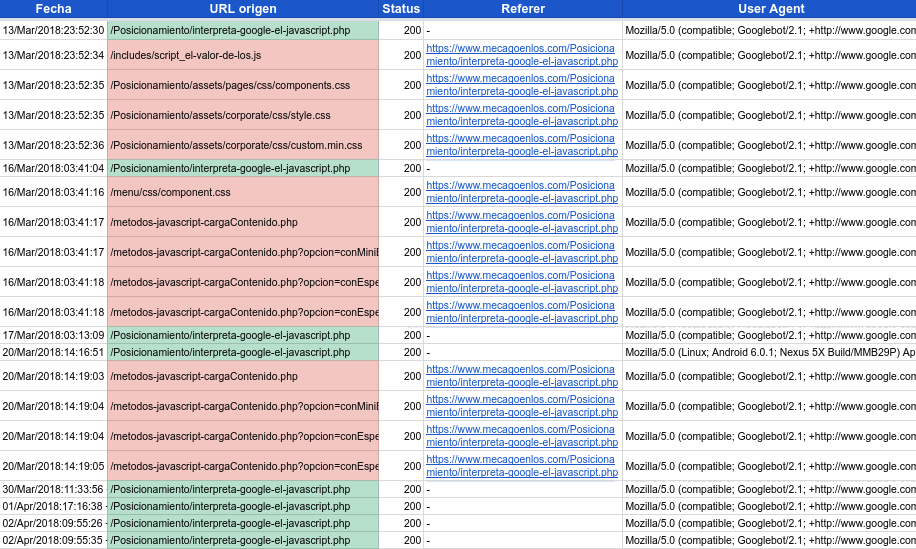
La segunda ola de indexación y cómo saber qué renderiza Google
Publicado por Lino Uruñuela el 23 de julio del 2018 Desde hace ya unos años venimos viendo cómo Google es capaz de cargar e indexar ciertos contenidos via javascript, en este blog hemos hecho muchos experimentos sobre cómo Google rastrea e indexa el contenido cargado mediante JavaScript. Los últimos experimentos sobre…
Cómo cargar css y js y no bloquear la carga de contenido | Experimento con canonical
Publicado el 5 de enero del 2018 por Lino Uruñuela Experimento con canonical, en el próximo post mostraré resultados, mirar el final de este para intentar entender algo Como muchos habréis notado he rediseñado el blog, que ya era hora después de 11 años con el mismo diseño. Los motivos han sido varios Mobile First El…
Cómo cargar css y js y no bloquear la carga de contenido
Publicado el 11 de Octubre del 2017 por Lino Uruñuela Como muchos habréis notado he rediseñado el blog, que ya era hora después de 11 años con el mismo diseño. Los motivos han sido varios Mobile First El híper anunciado índice móvil parece ser que está llegando este mes, cosa que ya anunció Google hace bastante tiempo…
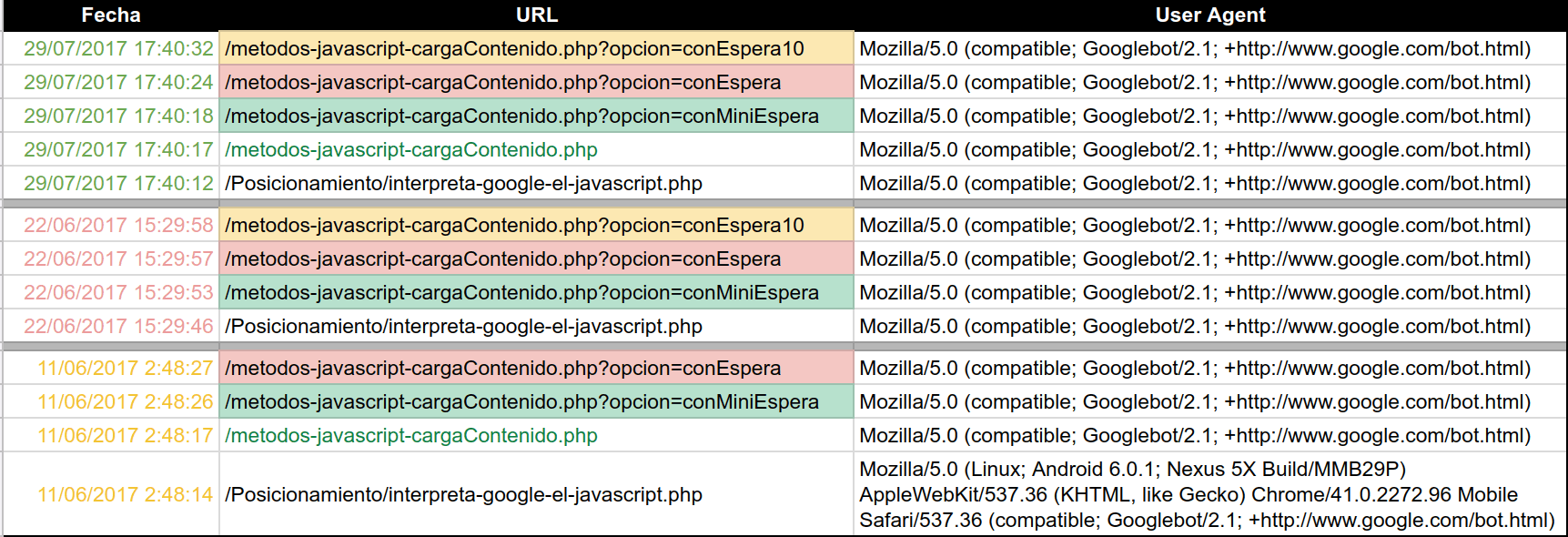
¿Cómo ejecuta, interpreta e indexa Google el contenido cargado mediante javascript?
Publicado el 14 de agosto del 2017 by Lino Uruñuela, SEO El otro día realizamos un test de lo más interesante, ¿Interpreta Google cualquier JavaScript que esté en el onready? , para intentar entender cómo Google rastrea, renderiza e indexa el contenido cargado mediante JavaScript. Ya habíamos hecho muchos experimentos…
Hola, buen trabajo... mi Ho es que estos chic@s lo leen todo.. jaja saludos !! Adrián
Para terminar de asegurar esto quizás podrías revisar los logs del servidor para ver si Googlebot ha accedido a esa nueva url. Quizás pase, que acceda y decida no indexarla (raro...). Buen post! Un saludo!
@Alvaro suelo comprobarlo cuando la url ha sido indexada, por si hubiese sido enlazada desde otro site, o por algún otro bot. Pero en los casos en los que no la indexa, me da igual qué entre ahí, si no indexa, no existe para Google... Eso sí, como bien dices sería, cuanto menos, desconcertante, que llegará a ella y no la indexara Saluds!