Diferentes métodos para indexar contenido JavaScript - Ajax
A priori debería indexar el contenido con ambos métodos, ya que si no fuese así sería de conocimiento público y se habría comentado ampliamente dada la cantidad de sites que usan estos métodos de una u otra manera.
Diciendo esto puede parecer que este experimento no tiene mucha trascendencia, pero sí la tiene, y mucha, ya que Googlebot se está actualizando, y no sabemos qué novedades habrá en cuanto a cómo Google es capaz de rastrear páginas webs altamente basadas en JavaScript (ya sea puro JavaScript como jQuery como el usado por frameworks como Angular, React o Vue.js).

Googlebot usando nuevas versiones de Chrome
En la siguiente imagen podemos ver las funcionalidades que soporta Googlebot en las diferentes versiones, a la izquierda las funciones que Googlebot aceptaba y acepta cuando rastrea el site usando la antigua versión y a la derecha las funcionalidades soportadas con la reciente actualización.

Debemos dejar claro, que el bot actual por defecto que usa Google es el antiguo, el que usa la versión 41 de Chrome, son muy pocos los accesos que Google realiza con el nuevo Googlebot y no sabremos cuánto tardará en usarlo como predeterminado.
Métodos para la carga de contenido mediante Ajax
- XMLHttpRequest
XMLHttpRequest es un objeto JavaScript que fue diseñado por Microsoft y adoptado por Mozilla, Apple y Google. Actualmente es un estándar de la W3C. Proporciona una forma fácil de obtener información de una URL sin tener que recargar la página completa
Este método era el usado típicamente hace tiempo, pero con la llegada de librerías como jQuery y posteriormente con FrameWorks como Angular, React o Vue (aunque estas dos últimas son librerías si nos ponemos estrictos) se quedó en desuso.
Aquí documentación y ejemplos de uso
- Fetch
El API fetch es un nuevo estándar que viene a dar una alternativa para interactuar por HTTP, con un diseño moderno, basado en promesas, con mayor flexibilidad y capacidad de control a la hora de realizar llamadas al servidor, y que funciona tanto desde window como desde worker
Este otro método tiene varias ventajas sobre el método XMLHttpRequest pero no vamos a entrar en esto, solo queremos comprobar si Google es capaz de ejecutar ambas y si es capaz de indexar el contenido obtenido por ambos métodos.
Tenéis documentación y ejemplos en este enlace.
Experimento SEO: indexando contenido obtenido por XMLHttpRequest y Fetch
Usando XMLHttpRequest
Usando Fetch
¿Cómo comprobar los resultados?
Para saber si Google es capaz de indexar (y por lo tanto poder posicionar) páginas que carguen contenido usando alguno de estos métodos JavaScript, podremos hacer una búsqueda por las palabras entrecomilladas en el encabezado de cada método.
Esta manera de comprobar si Google accede e indexa estos contenidos no es del todo fiable, podría ser "forzado" para su indexación, ya sea por sitemaps, por enlaces desde este site como otros sites que copien / fusilen este código, y otras mucha maneras.
La forma más fiable será analizando los logs y comprobando que Google accede a los archivos que contienen el HTML solicitado, y también si Google accede a las imágenes que hay en ese HTML.
Analizando los logs podremos obtener una respuesta más fiable que simplemente comprobando si aparece esta url en los resultados de Google al buscar alguna de las dos palabras que hay entre paréntesis
Así que ya sabéis, atentos a cuando publique los resultados, espero que en una semana podamos ver algo
¿Alguna idea / sugerencia / corrección sobre este experimento?
Lee otros artículos
Cómo se adapta Googlebot al tamaño del contenido
Publicado por Lino uruñuela el 9 de febrero del 2021 índice Un poco de historia sobre Google y JavaScript en este blog Datos del último experimento Código JavaScript para capturar el evento resize Código JavaScript Código en .htaccess Fichero ResizeRenderizadoJS.php (PHP) Datos del último experimento Observaciones sob…
Cómo saber qué errores JavaScript genera Google cuando ejecuta JavaScript
Publicado por Lino Uruñuela el 1 de febrero del 2021 Ya hemos visto cómo podemos comprobar y monitorizar qué URLs renderiza Google, pero si queremos ir un poco más allá también podemos capturar y guardar en Google Analytics qué errores JavaScript se producen cuándo Google ejecuta el código JavaScript para renderizar e…
Cómo ver las URLs renderizadas por Google en Google Analytics
Publicado por Lino Uruñuela el 1 de febrero del 2021 Desde hace unos cuántos años Google está produciendo grandes avances en su capacidad rastrear y obtener el contenido cargado por JavaScript, tal como lo haría un usuario navegando desde un dispositivo móvil. Para ello deduzco que ha debido hacer grandes cambios en s…
Carga de imagenes usando lazy load - Resultado del experimento
Publicado el 15 de febrero del 2019 por Lino Uruñuela índice de contenido Métodos probados en el experimento Carga normal, sin lazy load Imagen usando thubmnail de posición Cargar imagen desde desde data-src Imagen usando thubmnail de posición y noscript Sin usar thubmnail pero sí noscript Sin usar thubmnail ni tampoc…

Indexar imágenes en Google usando Lazy Load
Publicado el 23 de diciembre del 2018 por Lino Uruñuela índice de contenido ¿Qué es lazy load? Diferntes maneras de cargar imágenes medidante lazy load Miniatura de posición Usar < noscript > y miniatura de posición Añadir estilos para eliminar <noscript> Cómo aegurarnos que las imágenes serán indexables&l…
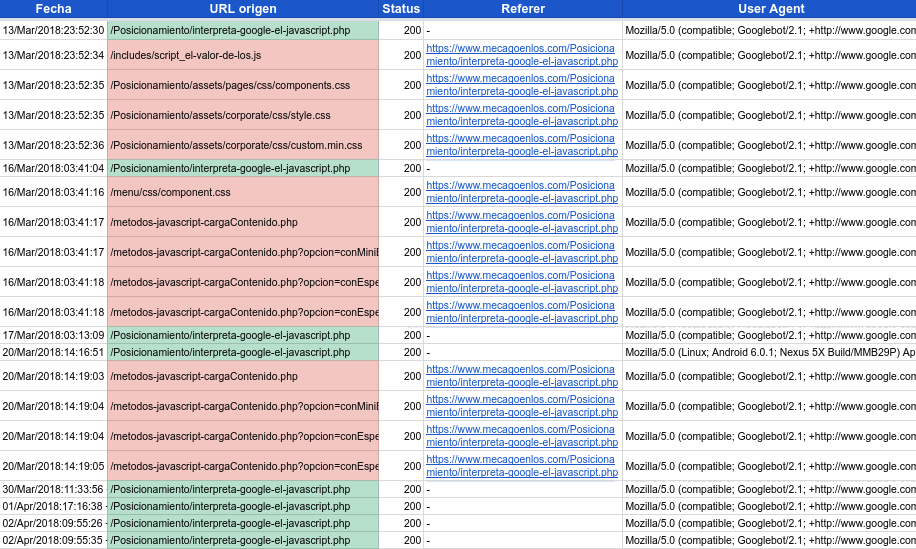
La segunda ola de indexación y cómo saber qué renderiza Google
Publicado por Lino Uruñuela el 23 de julio del 2018 Desde hace ya unos años venimos viendo cómo Google es capaz de cargar e indexar ciertos contenidos via javascript, en este blog hemos hecho muchos experimentos sobre cómo Google rastrea e indexa el contenido cargado mediante JavaScript. Los últimos experimentos sobre…
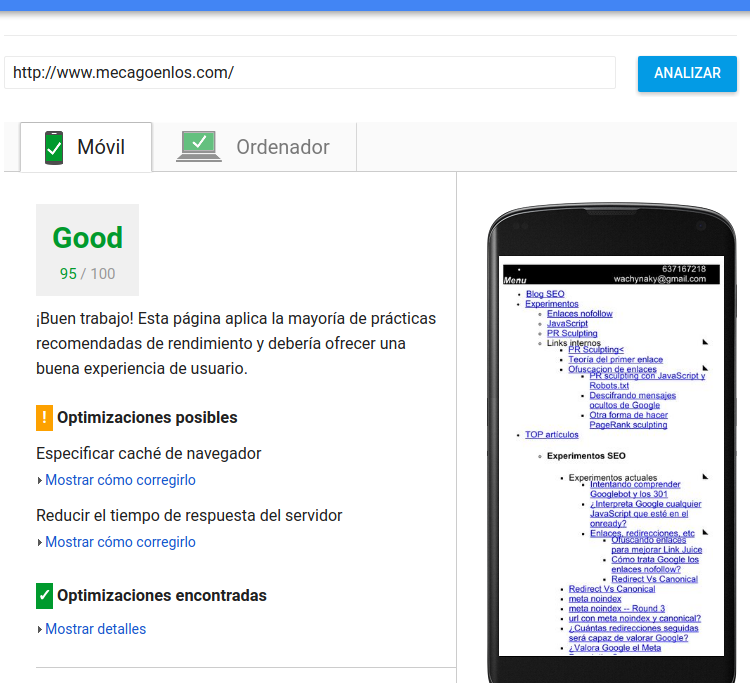
Cómo cargar css y js y no bloquear la carga de contenido | Experimento con canonical
Publicado el 5 de enero del 2018 por Lino Uruñuela Experimento con canonical, en el próximo post mostraré resultados, mirar el final de este para intentar entender algo Como muchos habréis notado he rediseñado el blog, que ya era hora después de 11 años con el mismo diseño. Los motivos han sido varios Mobile First El…
Cómo cargar css y js y no bloquear la carga de contenido
Publicado el 11 de Octubre del 2017 por Lino Uruñuela Como muchos habréis notado he rediseñado el blog, que ya era hora después de 11 años con el mismo diseño. Los motivos han sido varios Mobile First El híper anunciado índice móvil parece ser que está llegando este mes, cosa que ya anunció Google hace bastante tiempo…
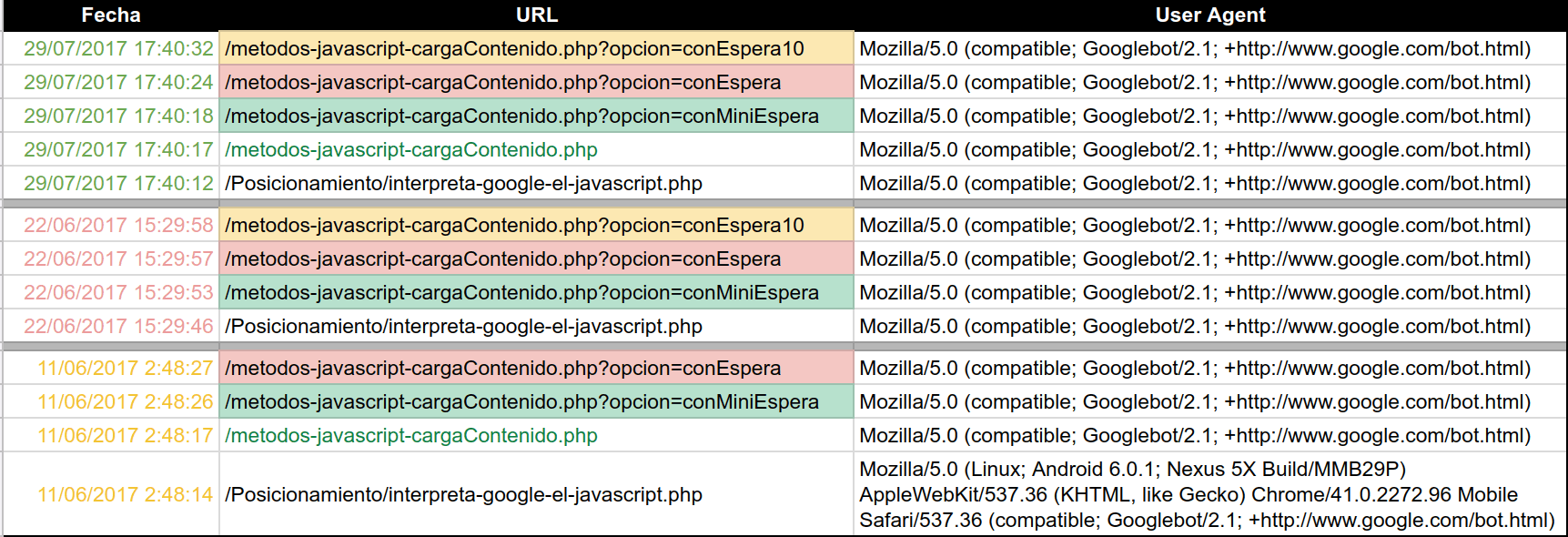
¿Cómo ejecuta, interpreta e indexa Google el contenido cargado mediante javascript?
Publicado el 14 de agosto del 2017 by Lino Uruñuela, SEO El otro día realizamos un test de lo más interesante, ¿Interpreta Google cualquier JavaScript que esté en el onready? , para intentar entender cómo Google rastrea, renderiza e indexa el contenido cargado mediante JavaScript. Ya habíamos hecho muchos experimentos…
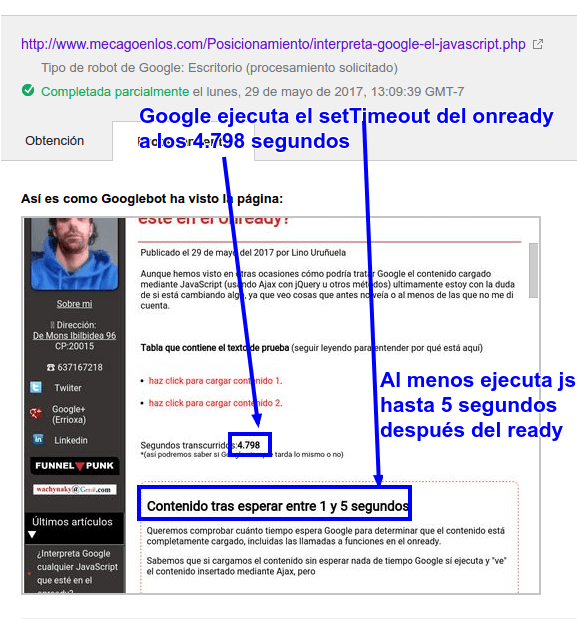
¿Interpreta Google cualquier JavaScript que esté en el onready?
Publicado el 29 de mayo del 2017 por Lino Uruñuela Aunque hemos visto en otras ocasiones cómo podría tratar Google el contenido cargado mediante JavaScript (usando Ajax con jQuery u otros métodos) ultimamente estoy con la duda de si está cambiando algo, ya que veo cosas que antes no veía o al menos de las que no me di…
Comentarios
Todavía no hay comentarios publicados.