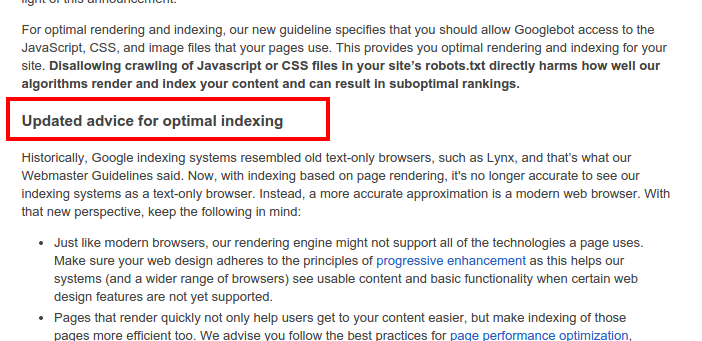
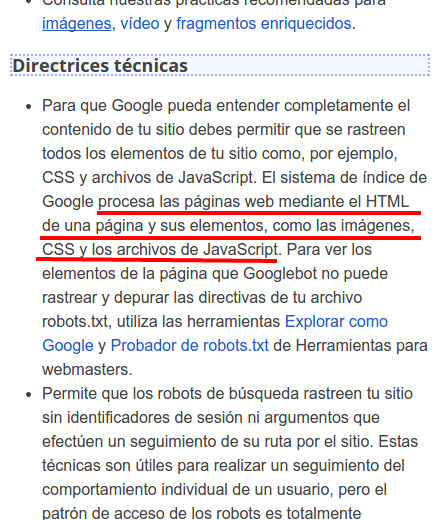
Google dice que no restrinjas ficheros css o javascript mediante robots.txt
| ANTES |
AHORA |
 |
 |
Pero si nos fijamos bien vemos que no lo hace por mejorar su algoritmo de ordenación, es un esfuerzo más para ser capaz de distinguir los sites que más probablemente satisfagan a sus usuarios, y esto pasa por tener en cuenta el dispositivo desde donde el usuario de Google realiza la búsqueda.
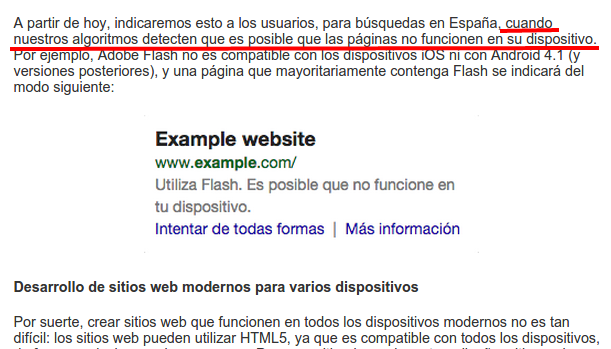
En el anterior post que publicaron, donde dan a entender que si detectan elementos flash o algo que no podrá ser reproducido por los usuarios desde dispositivos móviles, les avisarán desde las serps de que el contenido no es compatible con su dispositivo para que no pierda el tiempo y se frustre.
¿Por qué no quiere que restrinjamos esos ficheros?
Yo siempre he sido de la opinión de que cuanto menos sepa Google lo que hago para adecuar las necesidades SEO a los distintos escenarios, y es que muchas veces la usabilidad y funcionalidades visuales que introducimos en algunos elementos del site no son conmpatibles con el SEO, o mejor dicho, no son los idóneos pero seguro que le buscaremos las vueltas para que satisfaga nuestras necesidades.Pongamos por ejemplo el último artículo escrito en este blog, donde mostraba una manera de optimizar determinados listados con un diseño en contra de los requisitos SEO, recordemos;
- El problema venía de que el texto de los enlaces hacia las fichas de producto eran inútiles para SEO, ya que el texto de enlace no es nada relevante para búsquedas que hagan los clientes potenciales en Google. Las opciones que teníamos eran o bien le pegábamos una patada a la usabilidad y satisfacción de nuestro usuario si pusiéramos enlaces con un texto que fuese mediánamente útil para SEO (un link de texto "gana" al alt de la imagen aunque ésta esté enlazada, si hay enlace de texto a esa misma URL y otro enlace de imagen, el alt de la imagen lo ignorará para ese link).
- Para solucionarlo nos inventamos un método donde "camuflamos" los enlaces de texto al crawler para que tenga en cuenta el alt de las imágenes como texto del enlace, de esta forma sí podemos poner nuestras keywords potenciales en los enlaces sin pegarle una patada al manual de primer curso de usabilidad y que además, los enlaces, sean con el texto que nosotros como SEOs queremos, es decir, KW potenciales.
- Una de las cosas que dijimos es que era bueno camuflar las URLS para que Google no se ponga a rastrear por si mismo y valore eso como un enlace, sino que fuésemos nosotros quienes lo "guiaramos".
- El otro punto que comentamos fue el restringir ell fichero que ejecutaba la función de encriptación de url para que Googe no tuviese acceso y no comience a rastrear cosas que no queremos, o mal optimizadas, a parte de que puede volverse loco en mis funciones.
Pero parece ser que a Google no le gusta esto, y como vemos, ha modificado sus directrices para persuadirnos a que no restinjamos este tipo de ficheros. La verdad es que tiene sentido y no creo que sea un movimiento contra los SEOs. Creo que simplemente está renderizando cada url para ver cómo se vería por los usuarios.
Google no dice que dejará de mostrar esos resultados, tampoco se podría arriesgar a que aunque haya un elemento en flash no haya información muy relevante para el uysuario y es mejor , simplemente, avisarle antes de no mostrarle ese resultado.
Entonces, ¿que hacemos con los ficheros de javascript o css que tenemos restringidos por robots.txt? ¿abrimos su indexación? ¿lo dejamos como lo tenemos?
Mi recomendación es que mientras no sepamos más información y no estemos seguros de si va a repercutir, cuánto y de que manera, hagamos lo que nuestro DiosGoogle nos comenta no vaya a ser que el impacto sea mayor del previsto.
Ahora es tiempo de estrujarse un poco el coco y pensar en maneras de analizar cuánto impacto tiene este tipo de acciones, y con que tipo de contenido. Habrá que darle una vueltita más de tuerca a nuestro código para volver a "camuflar" esos links de una una u otra manera. Creo que en muchos casos realmente hay que hacerlo (poniendo el ejemplo del anterior post) y se ha de conseguir que las fichas de producto (en este caso camsetas) estén enlazadas con un texto potencial, a los diseñadores no les va a hacer ninguna gracia, y es que detallitos como este que hemos comentado para listados con imágenes te pueden hacer subir posiciones por muchas KW, medium tail y long tail. Si una buena parte de los ingresos de un site basado el cual está basado en listados mandará a tomar por saco la usabilidad y hará lo necesario para optmizar su site
¿Hay algo que joda más a un SEO saber cómo optimizar bien el linking interno y ver que no puede hacer sin cargarse la usabilidad, conversión e ingresos del negocio por una noticia así?
Ya tenemos reto, y nos toca pensar en otras alternativas, seguro que pronto nos vienen a la cabeza y comenzamos a testar.
Comentarios
1Lee otros artículos
Cómo se adapta Googlebot al tamaño del contenido
Publicado por Lino uruñuela el 9 de febrero del 2021 índice Un poco de historia sobre Google y JavaScript en este blog Datos del último experimento Código JavaScript para capturar el evento resize Código JavaScript Código en .htaccess Fichero ResizeRenderizadoJS.php (PHP) Datos del último experimento Observaciones sob…
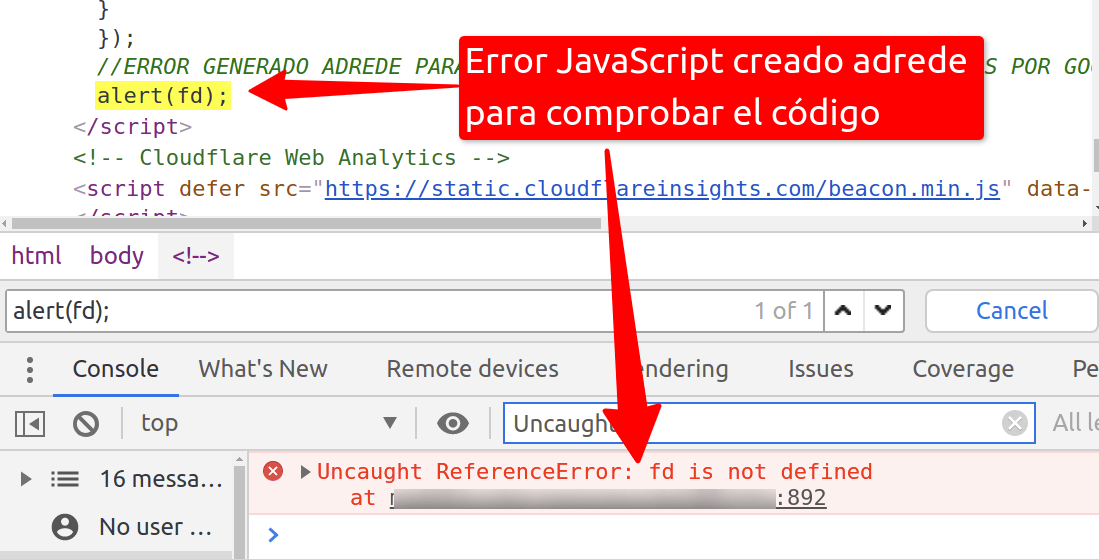
Cómo saber qué errores JavaScript genera Google cuando ejecuta JavaScript
Publicado por Lino Uruñuela el 1 de febrero del 2021 Ya hemos visto cómo podemos comprobar y monitorizar qué URLs renderiza Google, pero si queremos ir un poco más allá también podemos capturar y guardar en Google Analytics qué errores JavaScript se producen cuándo Google ejecuta el código JavaScript para renderizar e…
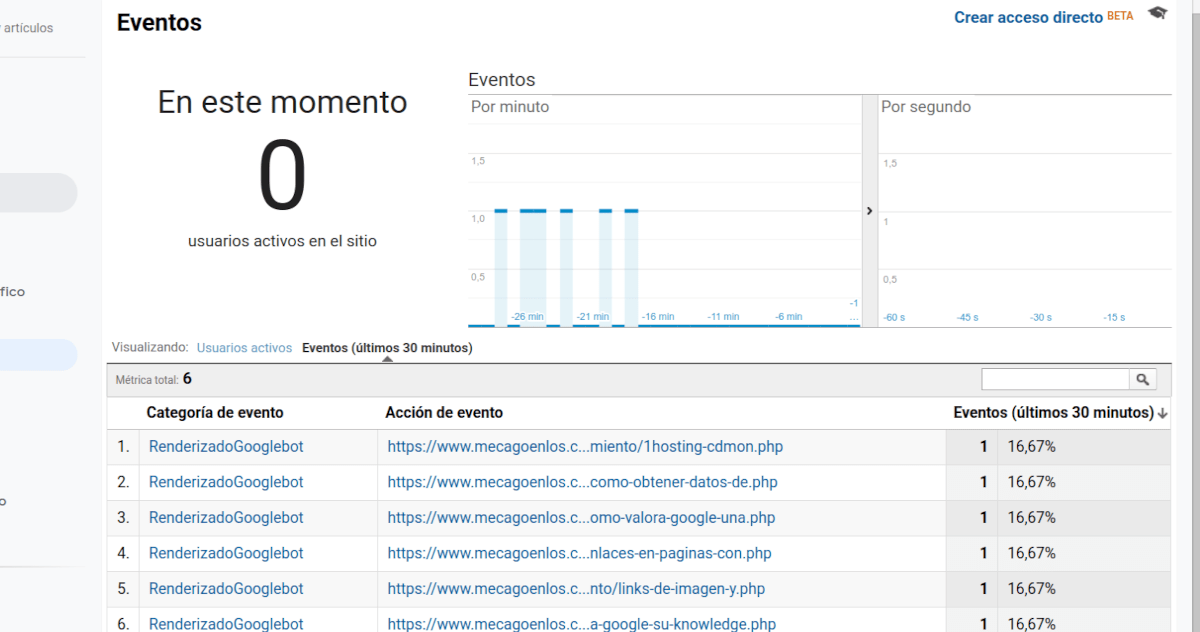
Cómo ver las URLs renderizadas por Google en Google Analytics
Publicado por Lino Uruñuela el 1 de febrero del 2021 Desde hace unos cuántos años Google está produciendo grandes avances en su capacidad rastrear y obtener el contenido cargado por JavaScript, tal como lo haría un usuario navegando desde un dispositivo móvil. Para ello deduzco que ha debido hacer grandes cambios en s…

Diferentes métodos para indexar contenido JavaScript - Ajax
Webs en JavaScript, metodos para la carga de contenido rastreable por Googlebot esta. basado en Chrome 41 sí soporta determinadas funcionalidades posteriores al número de su versión, pero no sabemos cuáles.
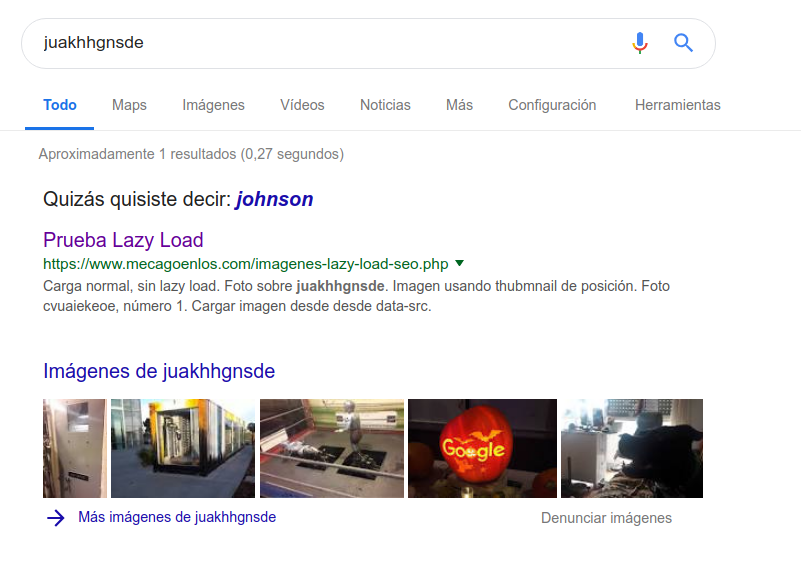
Carga de imagenes usando lazy load - Resultado del experimento
Publicado el 15 de febrero del 2019 por Lino Uruñuela índice de contenido Métodos probados en el experimento Carga normal, sin lazy load Imagen usando thubmnail de posición Cargar imagen desde desde data-src Imagen usando thubmnail de posición y noscript Sin usar thubmnail pero sí noscript Sin usar thubmnail ni tampoc…

Indexar imágenes en Google usando Lazy Load
Publicado el 23 de diciembre del 2018 por Lino Uruñuela índice de contenido ¿Qué es lazy load? Diferntes maneras de cargar imágenes medidante lazy load Miniatura de posición Usar < noscript > y miniatura de posición Añadir estilos para eliminar <noscript> Cómo aegurarnos que las imágenes serán indexables&l…
La segunda ola de indexación y cómo saber qué renderiza Google
Publicado por Lino Uruñuela el 23 de julio del 2018 Desde hace ya unos años venimos viendo cómo Google es capaz de cargar e indexar ciertos contenidos via javascript, en este blog hemos hecho muchos experimentos sobre cómo Google rastrea e indexa el contenido cargado mediante JavaScript. Los últimos experimentos sobre…
Cómo cargar css y js y no bloquear la carga de contenido | Experimento con canonical
Publicado el 5 de enero del 2018 por Lino Uruñuela Experimento con canonical, en el próximo post mostraré resultados, mirar el final de este para intentar entender algo Como muchos habréis notado he rediseñado el blog, que ya era hora después de 11 años con el mismo diseño. Los motivos han sido varios Mobile First El…
Cómo cargar css y js y no bloquear la carga de contenido
Publicado el 11 de Octubre del 2017 por Lino Uruñuela Como muchos habréis notado he rediseñado el blog, que ya era hora después de 11 años con el mismo diseño. Los motivos han sido varios Mobile First El híper anunciado índice móvil parece ser que está llegando este mes, cosa que ya anunció Google hace bastante tiempo…
¿Cómo ejecuta, interpreta e indexa Google el contenido cargado mediante javascript?
Publicado el 14 de agosto del 2017 by Lino Uruñuela, SEO El otro día realizamos un test de lo más interesante, ¿Interpreta Google cualquier JavaScript que esté en el onready? , para intentar entender cómo Google rastrea, renderiza e indexa el contenido cargado mediante JavaScript. Ya habíamos hecho muchos experimentos…
Un mes después, creo que la peor consecuencia son los errores. Las páginas con plugins o funciones más o menos sencillas que cambiaban la información de la pantalla con javascript y Ajax se han convertido en errores de rastreo cuando Google ha intentado interpretarlos. Es cierto que depende de cómo esté programado, pero no dejará de afectar a una gran cantidad de páginas. Por no hablar de la cantidad de páginas cuyo primer contenido visible ha pasado a ser el mensaje de Cookies jeje