La segunda ola de indexación y cómo saber qué renderiza Google
Analizando cuándo y qué urls renderiza Google
No me había dado cuenta de la importancia de esto hasta que escuché la famosa presentación que Tom Greenaway y John Mueller dieron en el Google I/O de este 2018, dónde explicó cómo Google procesa los contenidos cargados mediante javascript.
Resumiendo podemos decir que Google procesa el contenido de una url en dos procesos / fases / olas. En una primera ola Google funciona cómo siempre lo hemos entendido.
Primera ola de indexación
- Accede a la url que tiene en su lista de urls a rastrear.
- Obtiene el HTML de esa url, sin ejecutar JavaScript. Es lo que vemos cuándo le damos al botón dercho del ratón y seleccionamos "Ver código fuente de la página").
- Evalua en base a multitud de variables ese HTML obtenido y decide si la indexa y qué imporancia da al contenido de esa url.
Segunda ola de indexación
- Accede a la url que tiene en su "lista de espera" por renderizar
- Obtiene el HTML de esa url.
- Evalua en base a multitud de variables el HTML de la url de origen renderizado, es decir evaluará el contenido y recursos cargados en la rederización
- Carga de contenido tras pasar entre uno y cinco segundos
- Carga de otro contenido tras pasar entre 5 y 10 segundos
- Carga de otro contenido diferente al trasnscurrir al menos 10 segundos).
¿Cómo podemos saber que urls esta renderizando?
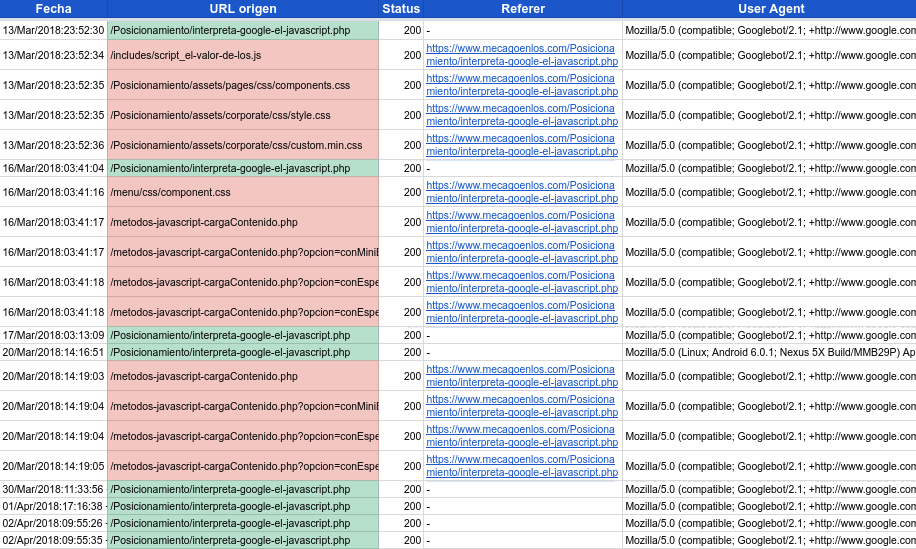
- Cuando Google accede a la url de origen, lo hace con el campo referer vacío.

- Los recursos cargados desde esa url de origen por parte del navegador, ya sean urls de contenido ajax, hojas de estilo o ficheros js llevan todas en el campo referer la url de origen.

- Los accesos a la url de origen y a las urls o recusos cargados en el renderizado se dan en un pequeño periodo de tiempo, podemos decir casi al 100% que en un periodo de tiempo menor a un minuto.
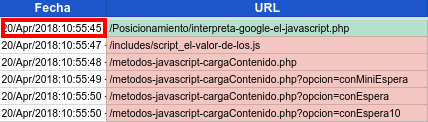
- El User Agent con el que accede contiene "Googlebot", tanto para la url de origen como para las urls javascript o recursos cargados. Aquí la lista completa de las distintas versiones de Googlebot según su User Agent para hacer las comprobaciones del tipo de Bot
- Google a veces espera el tiempo definido en el setTimeout de JavaScript, pero a veces se salta ese tiempo de espera y ejecuta el javascript casi inmediantemanete.
- No siempre que accede a una url de origen la renderiza, la mayoría de las veces accede a la url pero no hay un renderizado posterior.
- No siempre carga todos los recursos o urls de contenido, a veces carga solo un css, a veces carga todos los recursos, a veces solo una url de contenido... deberemos investigar mejor este comportamiento y saber que no siempre carga todo ni siempre lo mismo.
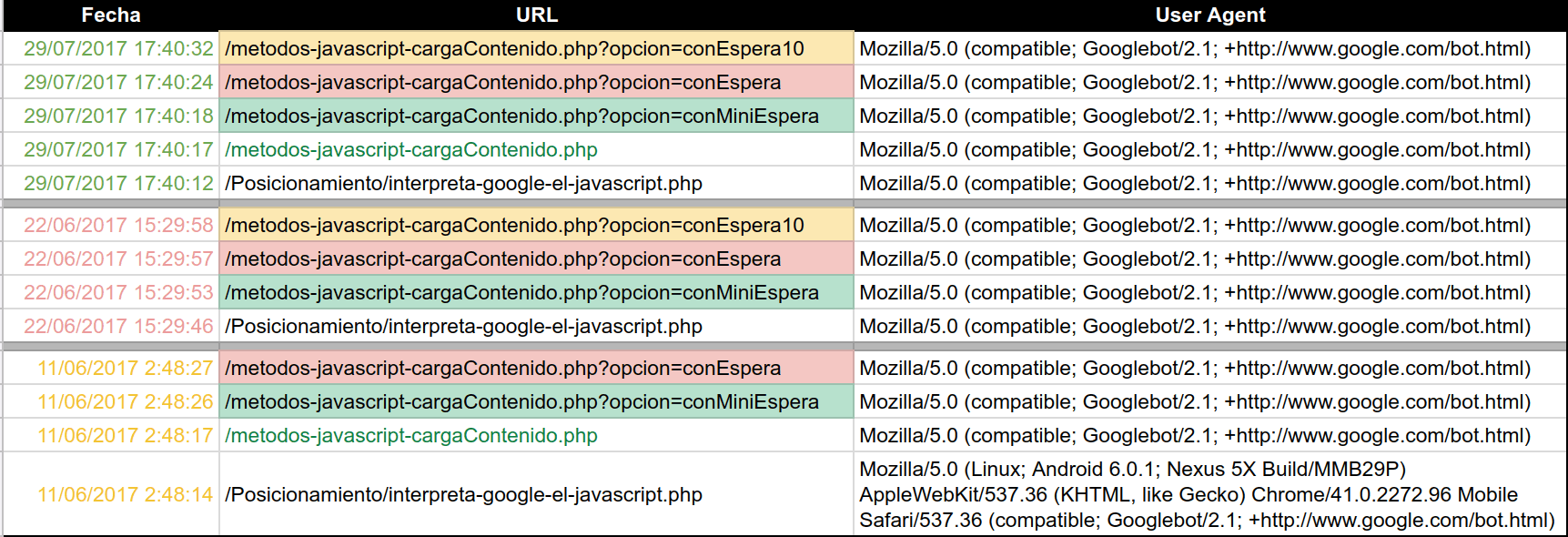
Ejemplo SQL para saber las urls que Google renderiza
- El User Agent contiene "Googlebot", por supuesto debemos comprobar que realmente sea Google, esto se puede hacer con un reverse DNS.
- El campo referer no está vacío, esto querrá decir que la url de este log ha sido cargada desde la url que aparece en e campo referer. En nuesto caso el valor de este campo es https://www.mecagoenlos.com/Posicionamiento/interpreta-google-el-javascript.php
SELECT fecha, referer FROM Logs WHERE (UA LIKE '%Googlebot%') AND ((fecha >= '2018-03-01') AND (fecha <= '2018-07-01')) AND (referer != '-') GROUP BY fecha, referer
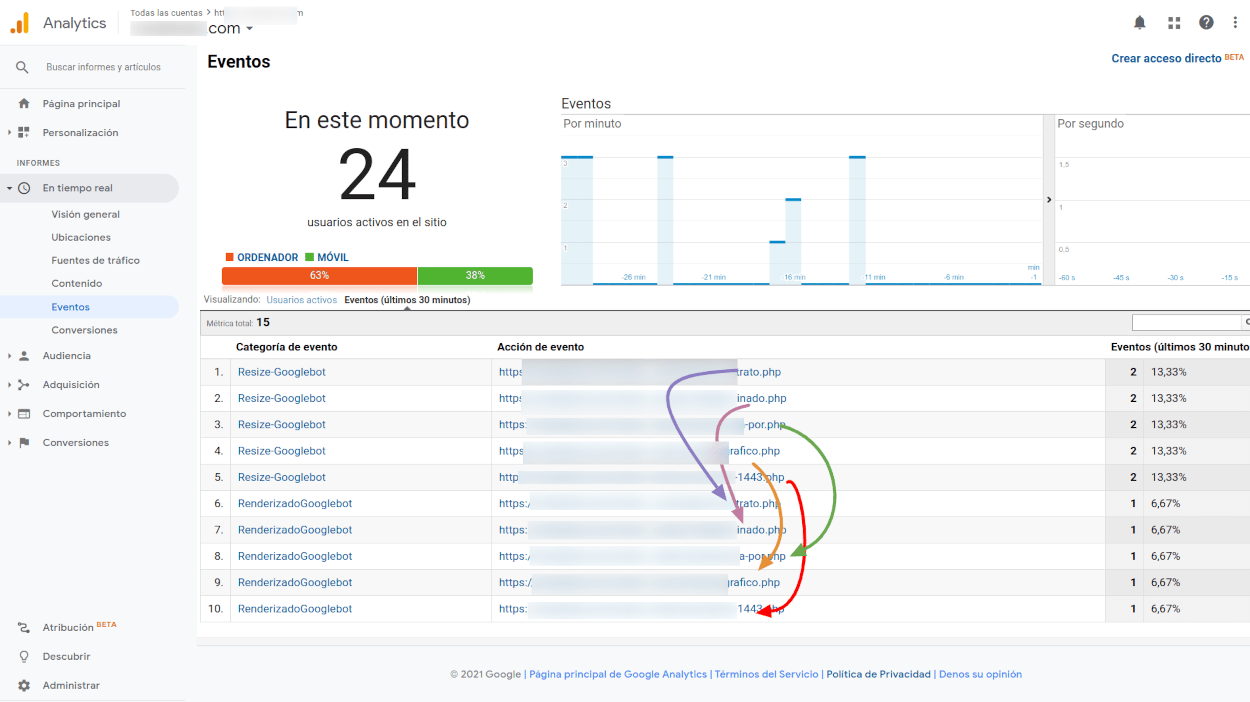
Además podremos saber qué recursos están dando error 404, que tamaño tienen los recursos descargados y cuánto tiempo tarda Google en descargarlo. Sin duda se puede rascar mucho para merjorar la velocidad de carga y saber cuáles son los recursos que debemos revisar.
Comentarios
3Lee otros artículos
Cómo se adapta Googlebot al tamaño del contenido
Publicado por Lino uruñuela el 9 de febrero del 2021 índice Un poco de historia sobre Google y JavaScript en este blog Datos del último experimento Código JavaScript para capturar el evento resize Código JavaScript Código en .htaccess Fichero ResizeRenderizadoJS.php (PHP) Datos del último experimento Observaciones sob…
Cómo saber qué errores JavaScript genera Google cuando ejecuta JavaScript
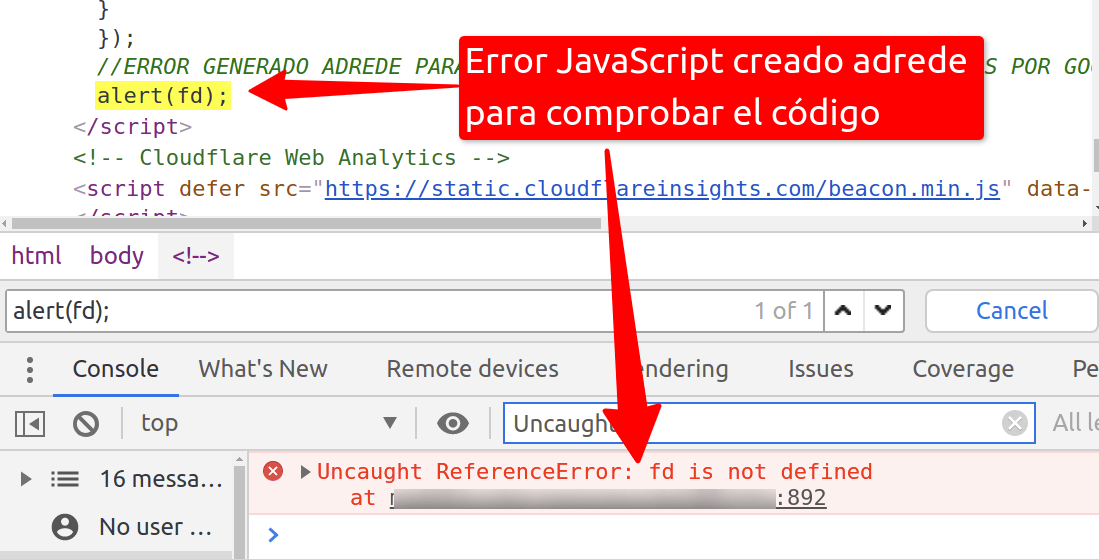
Publicado por Lino Uruñuela el 1 de febrero del 2021 Ya hemos visto cómo podemos comprobar y monitorizar qué URLs renderiza Google, pero si queremos ir un poco más allá también podemos capturar y guardar en Google Analytics qué errores JavaScript se producen cuándo Google ejecuta el código JavaScript para renderizar e…
Cómo ver las URLs renderizadas por Google en Google Analytics
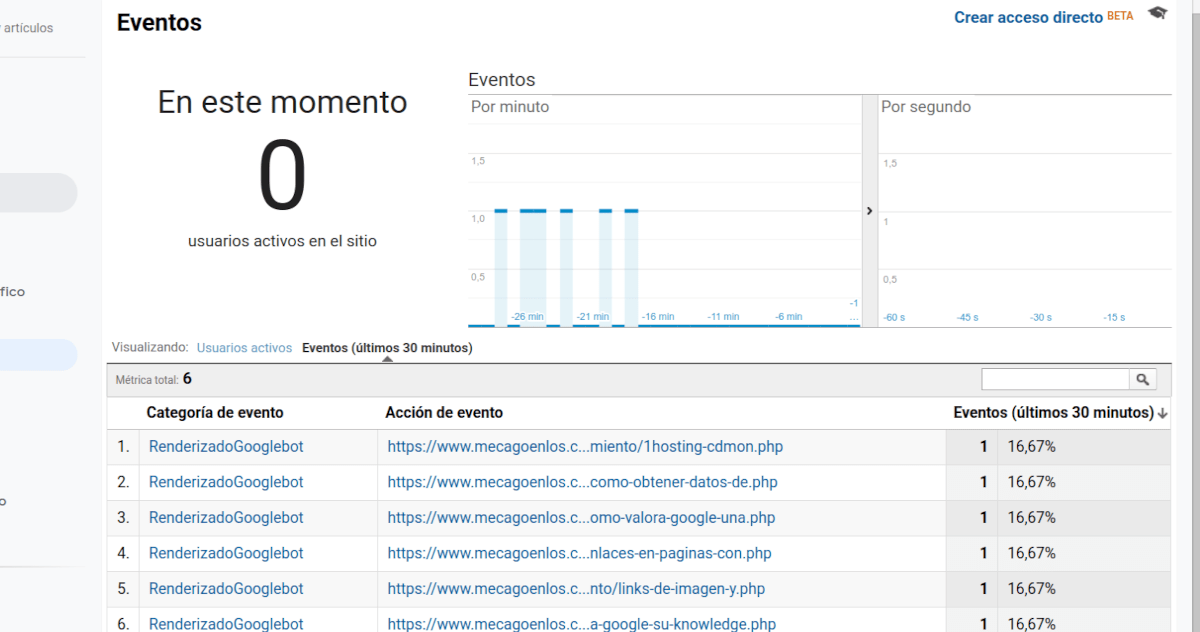
Publicado por Lino Uruñuela el 1 de febrero del 2021 Desde hace unos cuántos años Google está produciendo grandes avances en su capacidad rastrear y obtener el contenido cargado por JavaScript, tal como lo haría un usuario navegando desde un dispositivo móvil. Para ello deduzco que ha debido hacer grandes cambios en s…

Diferentes métodos para indexar contenido JavaScript - Ajax
Webs en JavaScript, metodos para la carga de contenido rastreable por Googlebot esta. basado en Chrome 41 sí soporta determinadas funcionalidades posteriores al número de su versión, pero no sabemos cuáles.
Carga de imagenes usando lazy load - Resultado del experimento
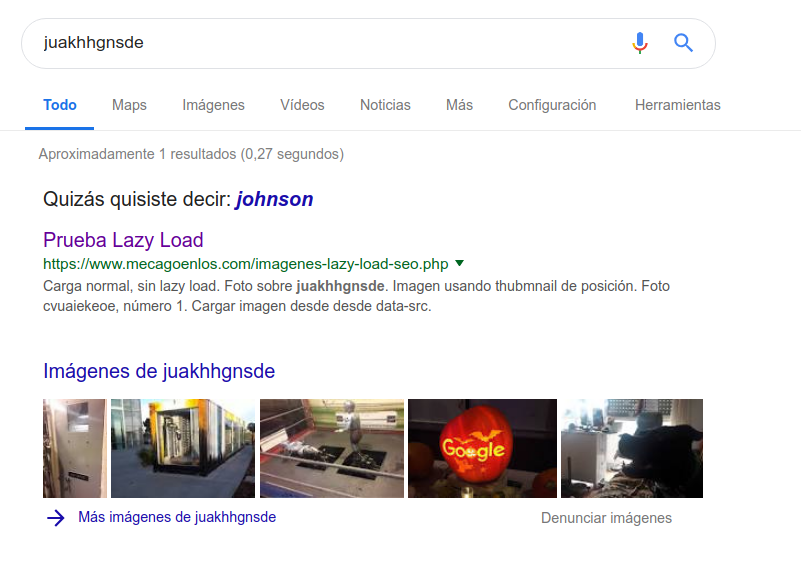
Publicado el 15 de febrero del 2019 por Lino Uruñuela índice de contenido Métodos probados en el experimento Carga normal, sin lazy load Imagen usando thubmnail de posición Cargar imagen desde desde data-src Imagen usando thubmnail de posición y noscript Sin usar thubmnail pero sí noscript Sin usar thubmnail ni tampoc…

Indexar imágenes en Google usando Lazy Load
Publicado el 23 de diciembre del 2018 por Lino Uruñuela índice de contenido ¿Qué es lazy load? Diferntes maneras de cargar imágenes medidante lazy load Miniatura de posición Usar < noscript > y miniatura de posición Añadir estilos para eliminar <noscript> Cómo aegurarnos que las imágenes serán indexables&l…
Cómo cargar css y js y no bloquear la carga de contenido | Experimento con canonical
Publicado el 5 de enero del 2018 por Lino Uruñuela Experimento con canonical, en el próximo post mostraré resultados, mirar el final de este para intentar entender algo Como muchos habréis notado he rediseñado el blog, que ya era hora después de 11 años con el mismo diseño. Los motivos han sido varios Mobile First El…
Cómo cargar css y js y no bloquear la carga de contenido
Publicado el 11 de Octubre del 2017 por Lino Uruñuela Como muchos habréis notado he rediseñado el blog, que ya era hora después de 11 años con el mismo diseño. Los motivos han sido varios Mobile First El híper anunciado índice móvil parece ser que está llegando este mes, cosa que ya anunció Google hace bastante tiempo…
¿Cómo ejecuta, interpreta e indexa Google el contenido cargado mediante javascript?
Publicado el 14 de agosto del 2017 by Lino Uruñuela, SEO El otro día realizamos un test de lo más interesante, ¿Interpreta Google cualquier JavaScript que esté en el onready? , para intentar entender cómo Google rastrea, renderiza e indexa el contenido cargado mediante JavaScript. Ya habíamos hecho muchos experimentos…
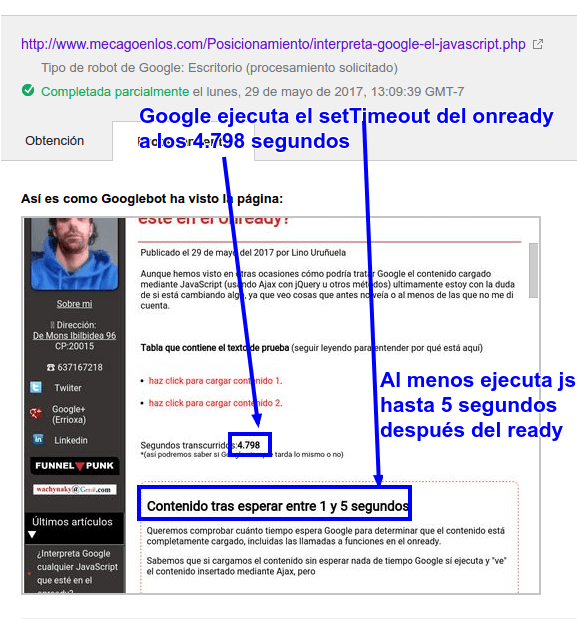
¿Interpreta Google cualquier JavaScript que esté en el onready?
Publicado el 29 de mayo del 2017 por Lino Uruñuela Aunque hemos visto en otras ocasiones cómo podría tratar Google el contenido cargado mediante JavaScript (usando Ajax con jQuery u otros métodos) ultimamente estoy con la duda de si está cambiando algo, ya que veo cosas que antes no veía o al menos de las que no me di…
Hola Lino, Nos conocemos de películas como: Los de Google son muy frikis o Pasodobles y SEO. Mi cuestión es la siguiente: entiendo que con una función setInterval() en la segunda ola renderice el contenido porque será el mismo pero saltarse el setTImeout () me parece "regular" porque podemos ir invocando cosas diferentes. ¿Qué opinas? Un placer leerte y, como siempre, gran post.
@Cesar saltarse alguna orden del código es un falta de respeto!, que para algo lo hice :D No se les da muy bien esperar, su tiempo es oro parece... Pero muchas veces sí espera el tiempo del Timeout. Pero pensando que, en tiempo de computación 10 segundos es una burrada, multiplica eso por la cantidad de urls que hay en internet
Hola, Lino: Genial el post, como siempre. Es genial contar con personas tan curiosas y que investigan al detalle el funcionamiento de Google. Quería lanzarte una pregunta. ¿Cómo se puede ver el onLoad y el onReady? ¿Son eventos que aprecen en la consola de Chrome/Mozilla? Agradecería que me pudieras explicar esto, o bien si lo prefieres escribir un post con este detalle. Gracias de antemano