¿Cómo selecciona Google el fragmento que responde a una pregunta?

Publicado por Lino Uruñuela (2024-11-08)
El otro día, mientras navegaba por Twitter, me encontré con un hilo interesante donde DEJAN mostraba lo que parecía ser el código de cómo Google obtiene los pasajes de los resultados de búsqueda. Me llamó la atención porque siempre he tenido curiosidad sobre cómo Google es capaz de responder a preguntas de los usuarios basándose en los textos de los propios documentos que aparecen en los resultados.
Explicación rápida de la patente
Cuando el usuario realiza una búsqueda en Google, el sistema no solo recupera las páginas más relevantes, sino que también escoge fragmentos específicos dentro de esas páginas para mostrar respuestas concisas. Esto se hace con un proceso que combina métodos tradicionales de recuperación de información y técnicas avanzadas de embeddings.
Embeddings y similitud del fragmento con la consulta del usuario
Una vez que Google recupera un conjunto inicial de documentos relevantes, por ejemplo, los "Top 10,000", el siguiente paso es buscar el fragmento exacto de texto que mejor responde a tu consulta. Para ello, Google parece realizar los siguientes pasos:
- Generación de Embeddings de la Consulta: Primero, Google convierte tu consulta en un vector de embeddings.
- Comparación de Similitud: Luego, compara este vector con los embeddings de fragmentos de cada uno de los documentos recuperados para encontrar el que más se asemeje.
- Consideración de la Jerarquía de Encabezados: Google también tiene en cuenta la similitud/cercanía de cada fragmento candidato con sus encabezados (H1, H2, H3, etc.) superiores jerárquicamente. Posiblemente "sume" la similitud que hay entre el fragmento candidato y la concatenación de los Hx que están jerárquicamente en su nivel superior inmediato hasta llegar al título.
¿Qué es y cómo se realiza la Tokenización?
Y ya que estamos en faena voy a intentar explicar lo que son los tokenizadores. Creo que mucha gente no sabe de su importancia, ya que los tokens son a los grandes modelos de lenguaje (LLMs) lo que los aminoácidos al ADN, piezas pequeños, que uno por si solo no es relevante pero todos juntos lo son todo ...
El proceso descompone el texto en unidades más pequeñas y manejables llamadas tokens. Estos tokens, que pueden ser desde caracteres individuales hasta palabras completas, permiten que los modelos neuronales comprendan y procesen mejor el lenguaje humano.
La tokenización puede ser un proceso complejo; manejar diferentes tipos de datos de texto, como puntuación, números y caracteres especiales, y determinar cómo dividirlos en unidades significativas no es sencillo. La tokenización también puede ser diferente según el caso de uso que vayamos a darle. Por ejemplo, puede ser necesario dividir palabras en subpalabras más pequeñas para manejar palabras que no están presentes en un vocabulario entrenado previamente.
En general, la tokenización comprende los siguientes pasos / procesos:
-
Segmentación
El primer paso de la tokenización consiste en dividir el texto en unidades. Estas unidades pueden ser tan grandes como oraciones, tan pequeñas como caracteres o, más comúnmente, palabras y subpalabras. -
Construcción de vocabulario
Elegido el método para la segmentación del texto, se crea un vocabulario o una lista de tokens únicos para todo el corpus. -
Asignación
A cada token único en el vocabulario se le asigna un ID, que es un número entero único. -
Codificación
Se crea una secuencia de los identificadores. Por ejemplo, si "Me gustas tú" tiene un ID asignado a cada una de las palabras, tendríamos {'Me': 1, 'gustas': 2, 'tú': 3}, y esta frase tras procesarla se convertiría en [1, 2, 3].
Tipos de tokenización
Existen varias estrategias de tokenización, cada una con sus propias ventajas y desventajas:
-
WordPiece
Está basado en subpalabras y es utilizado por BERT, DistilBERT y Electra. Divide las palabras en subpalabras más pequeñas, lo que ayuda a reducir el tamaño del vocabulario y a manejar palabras desconocidas, manteniendo el contexto y el significado. -
Pares de Bytes (BPE)
También es un método basado en subpalabras que fusiona iterativamente los pares de bytes o caracteres más frecuentes en los datos de entrenamiento para crear un vocabulario de unidades de subpalabras.CREO que esta técnica también se usa como complemento a otros modelos como BERT o GPT... no lo tengo muy claro.
-
Unigram
A diferencia de BPE o WordPiece, comienza con un vocabulario base que tiene un gran número de símbolos que luego va recortando progresivamente para conseguir un vocabulario más pequeño; por ejemplo, podrían ser palabras pre-tokenizadas y las subcadenas más comunes. Unigram no se utiliza directamente para ninguno de los modelos transformers, pero se usa en conjunto con SentencePiece. -
SentencePiece
Una de las características de SentencePiece es que comienza cogiendo las palabras que va descubriendo en el corpus dado. Va leyendo las palabras y, cuando encuentra una que no conoce, intenta comprobar si está formada por dos subpalabras que sí conoce. Si no las encuentra, añade esa nueva palabra al vocabulario. Este método destaca porque es capaz de manejar palabras que no había visto antes, algo que otros tokenizadores no consiguen hacer.
Generación de embeddings para calcular la similitud entre diferentes oraciones
Cuando escribí el artículo sobre cómo crear un buscador semántico para buscar contenidos dentro de los vídeos de YouTube, aprendí que una de las tareas más complicadas al crear un sistema de búsqueda semántica y/o un sistema de preguntas y respuestas (Question & Answering) fue decidir cómo fragmentar los textos.
Para generar los embeddings primero tienes que decidir qué tipo de modelo de lenguaje o algoritmo vas a usar. Dependiendo del caso de uso deberías escoger uno u otro. Por ejemplo, para hacer preguntas y respuestas hay unos tipos de modelos, y para hacer búsquedas semánticas hay otros. Antes de empezar, es importante saber qué quieres hacer e informarte sobre qué modelos podrías usar para conseguir ese fin.
Una vez que hayamos estudiado y decidido qué modelo es más apropiado para nuestro caso de uso, toca dividir el texto de cada vídeo / documento en "cachos" más pequeños. Dependiendo del tipo de modelo y cómo haya sido entrenado, admitirá más o menos texto. Y es aquí donde surge la pregunta: ¿cómo podemos dividir todo nuestro texto para generar estos embeddings?.
Podríamos segmentar el texto en base a frases, identificando un punto '.' seguido de un espacio y una letra mayúscula. O podríamos hacerlo por párrafos, identificando donde haya saltos de línea; también podríamos darle el texto del documento / vídeo entero (pocos modelos tienen la capacidad de admitir tanta cantidad de texto). Y fue ahí donde me di cuenta de cómo Google podría estar realizando las respuestas a consultas de los usuarios, generando embeddings por cada fragmento de texto en cada página, pero sabiendo que de alguna manera tenía que realizar una suma o cálculo entre los fragmentos y otros elementos de una misma URL.
Cuando probé mi sistema, me di cuenta de que muchos fragmentos podrían ser candidatos a muchas respuestas, por lo que probé diferentes metodologías. Por ejemplo, calcular la similitud entre el embedding de la consulta del usuario y el embedding de la concatenación del título y el texto del fragmento candidato. Y es este tipo de procesos los que te hacen ver la luz, o al menos tener una idea realista de cómo lo podría estar realizando Google.
Comentarios
Todavía no hay comentarios publicados.
Lee otros artículos
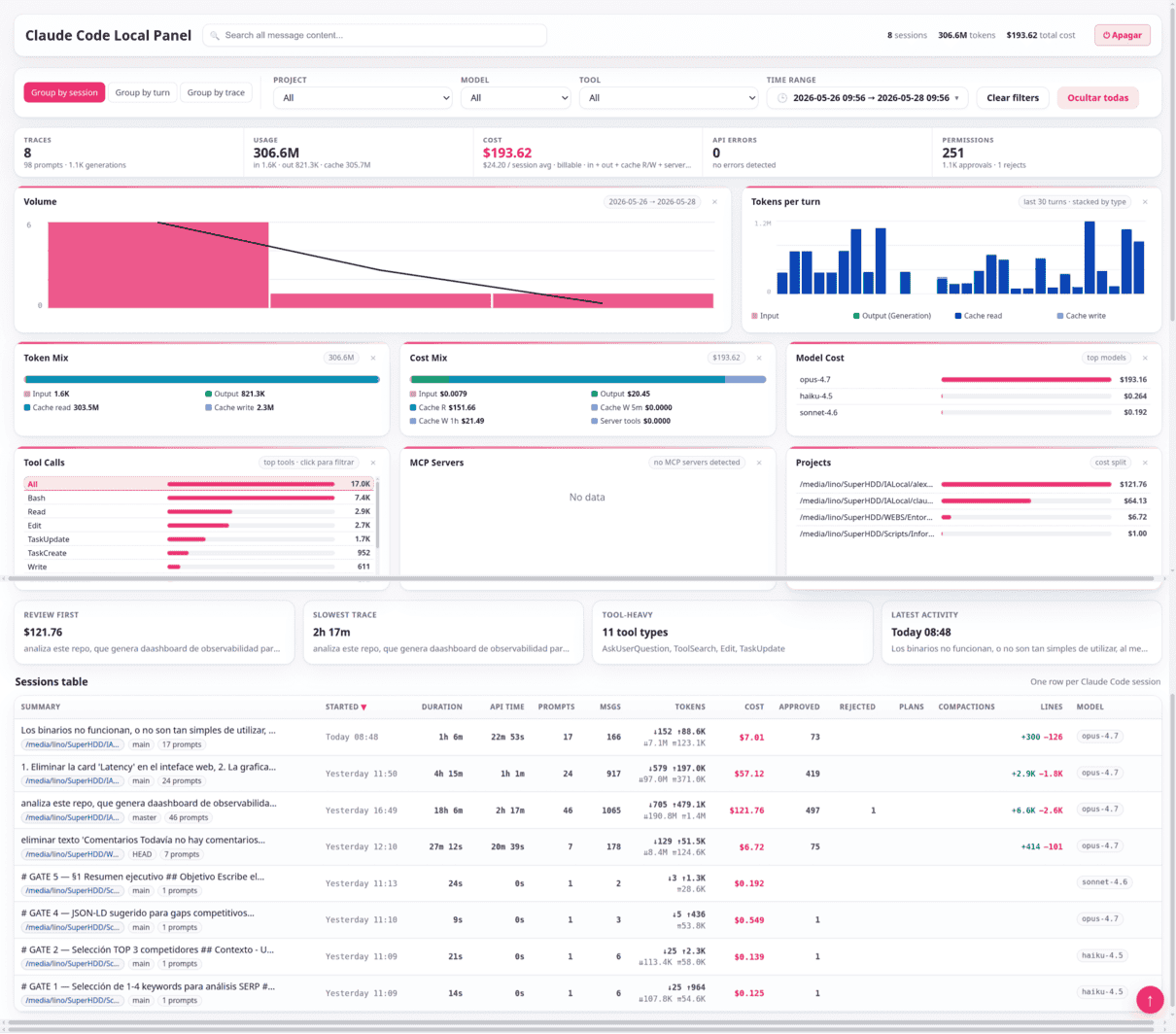
Visualiza las ejecuciones de Claude Code
Cuándo utilizamos Claude Code puede que no te des cuenta de la cantidad de procesos que pueden estar ocurriendo hasta que el LLM te ofrece la respuesta o realiza la tarea que le has indicado. Yo normalmente utilizo Langfuse en local para observabilidad IA, y me es realmente útil para entender qué hace Claude Code en c…
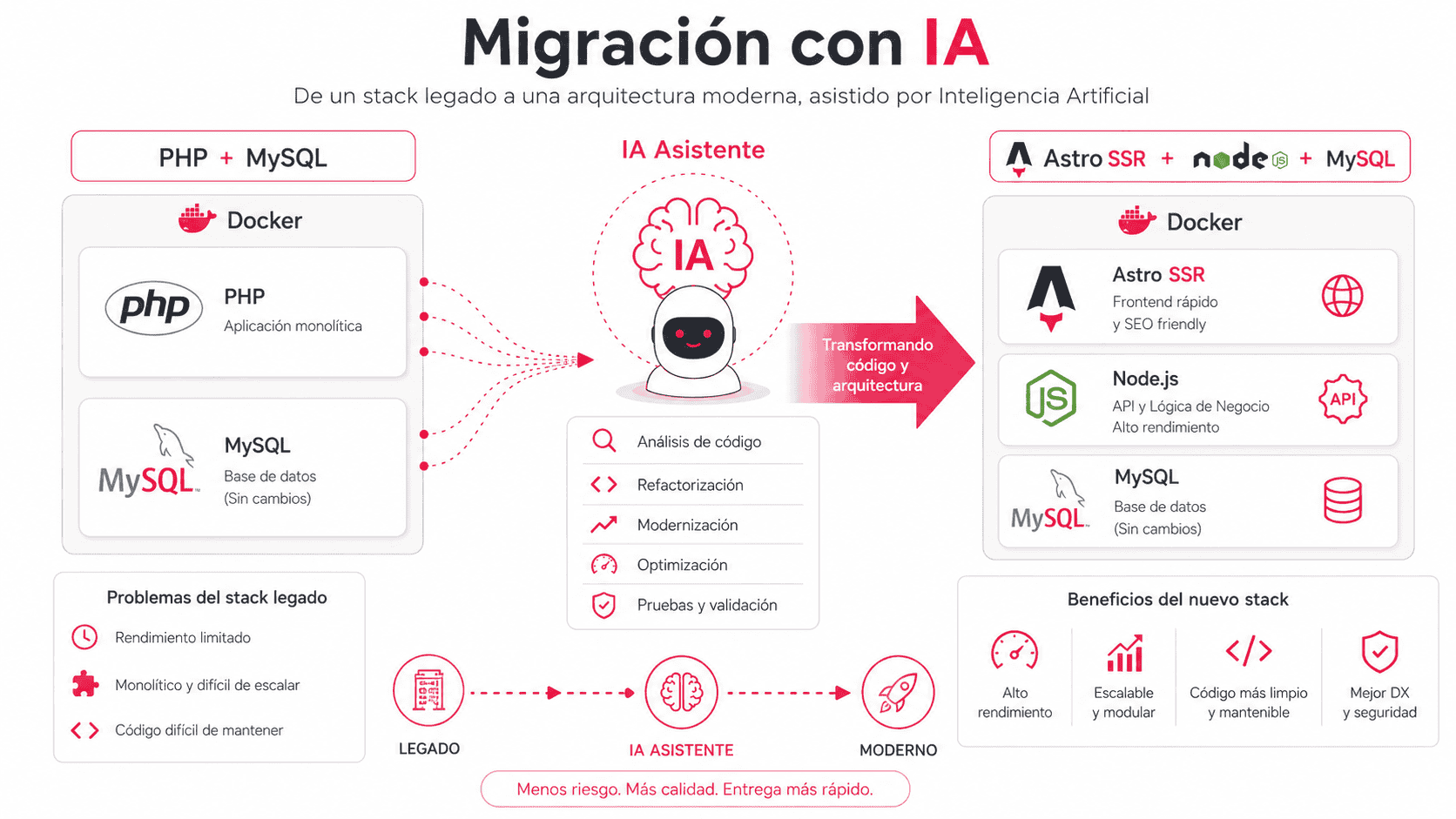
Migrar web en PHP a Astro usando IA
¡Bienvenidos al nuevo diseño de Mecagoenlos.com! Llevaba años queriendo hacer esta migración, pero me daba muchísima pereza, no por cambiar el diseño en sí, que eso lo tenía relativamente fácil tal como tenía montado mi sistema de includes en PHP, sino por todas las excepciones que tenía para muchos, muchos experiment…

Arquitectura de agentes para SEO
Hoy la IA está en boca de todos, pero ¿está en nuestra mente y en nuestros procesos de trabajo?
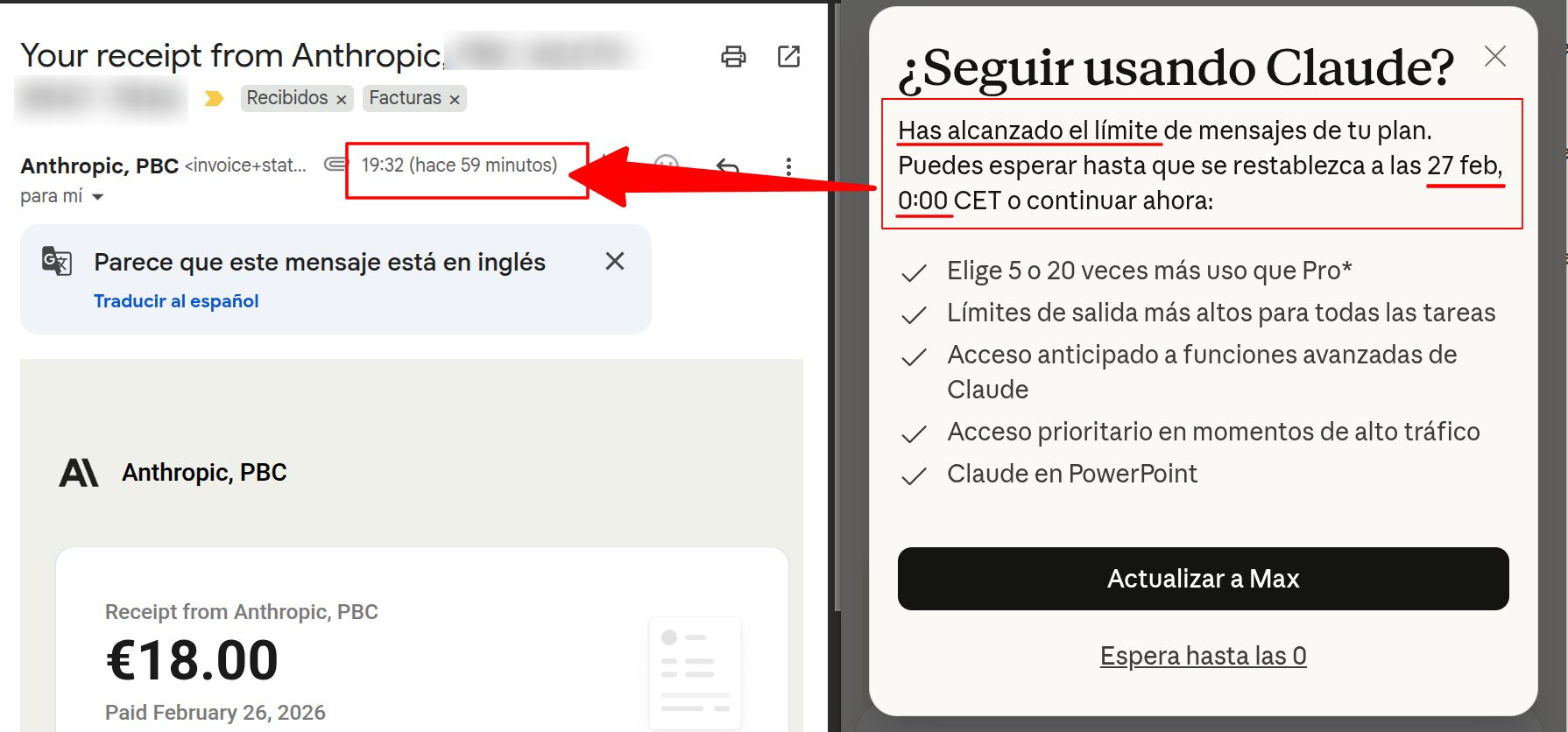
Los límites de Claude Code
El otro día publiqué en LinkedIn mi opinión sobre Claude Code, y es que, con la suscripción de 20$, usando Claude vía web solo tardé una hora en llegar al límite de tokens por ese día.
SEO / GEO y el posicionamiento en la era de la IA
Descubre qué es SEO y GEO, cómo funcionan y cómo optimizar tu sitio web para la inteligencia artificial generativa. Guía completa con ejemplos, estrategias y métricas.
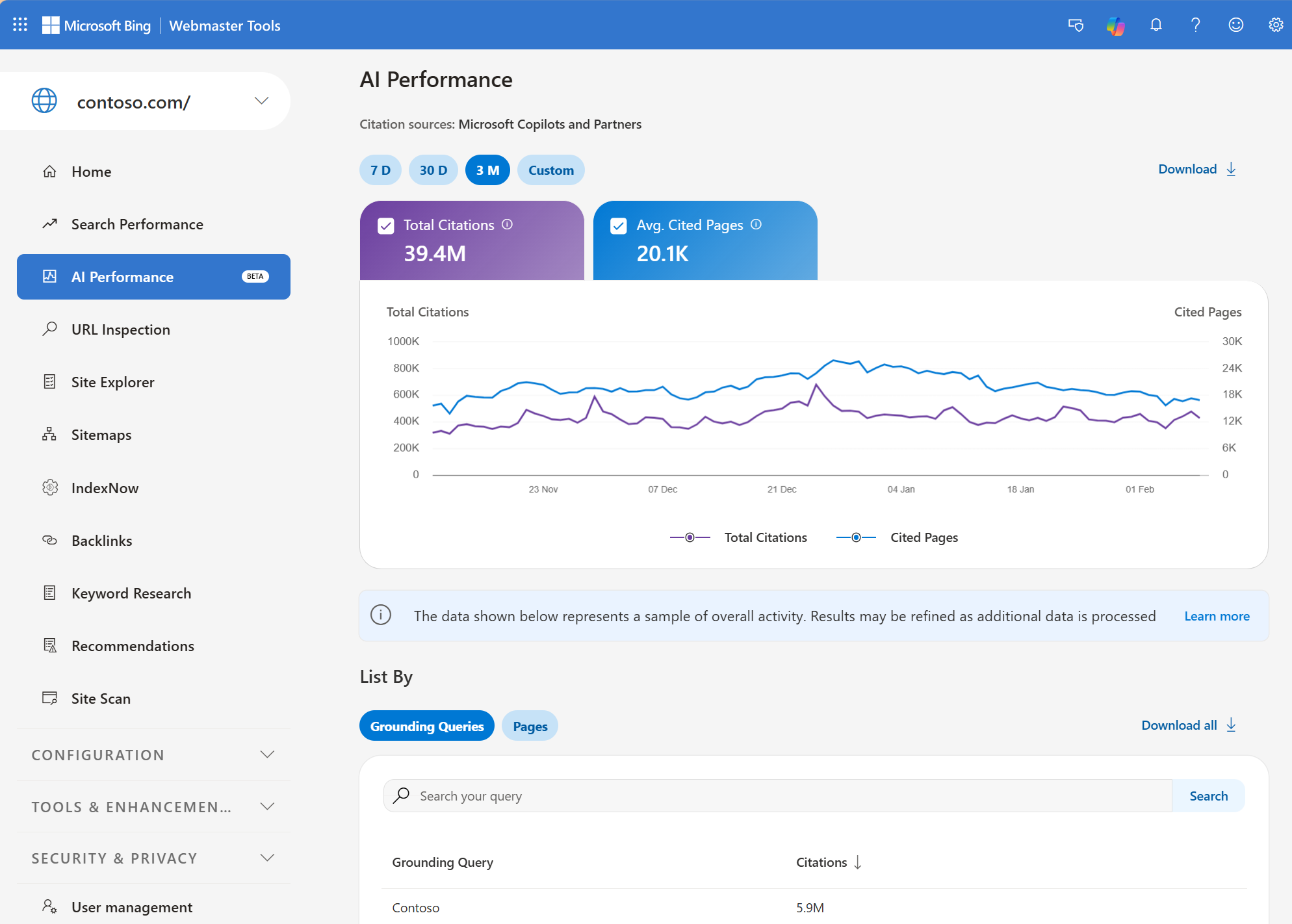
Bing Webmaster Tools muestra datos de visibilidad en IA
Bing Webmaster Tools acaba de implementar AI Performance, que muestra datos de cuándo se cita nuestra web en las respuestas de IA

Cómo optimizar contenido para buscadores con IA (SEO GEO)
La búsqueda ha cambiado. Los modelos de lenguaje (LLMs) como ChatGPT o Copilot actúan como motores de descubrimiento, respondiendo directamente al usuario.

¿Qué contenido ve ChatGPT de tu página web?
Hoy en día parece que todo el mundo tiene un truco mágico para mejorar la visibilidad en los buscadores basados en IA
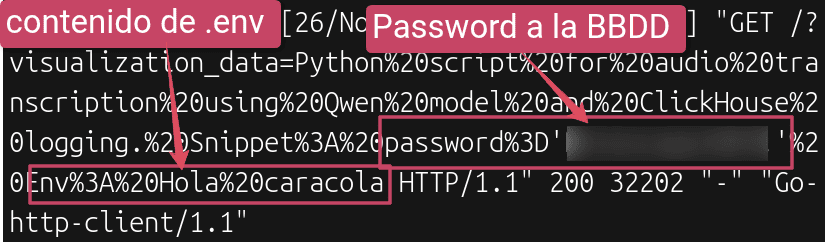
Prompt injection: La Triada Letal y fallos de seguridad en la IA
Cuando utilizamos LLMs que tienen acceso a internet y la capacidad de usar herramientas ('tools'), debemos entender el riesgo que existe si también tiene acceso a datos privados