Clustering de keywords SEO en Google Search Console - Parte II
Publicado el 6 de septiembre del 2021 por Lino Uruñuela
Índice de contenidos
El otro día vimos como podemos obtener la raíz de cada palabra clave de Google Search Console, sin duda un comienzo, y hoy vamos a mostrar cómo mejorar el proceso que realizamos y también vamos a facilitar una plantilla y un To-Do de cómo generar una tabla como la siguiente imagen con vuestros propios datos.
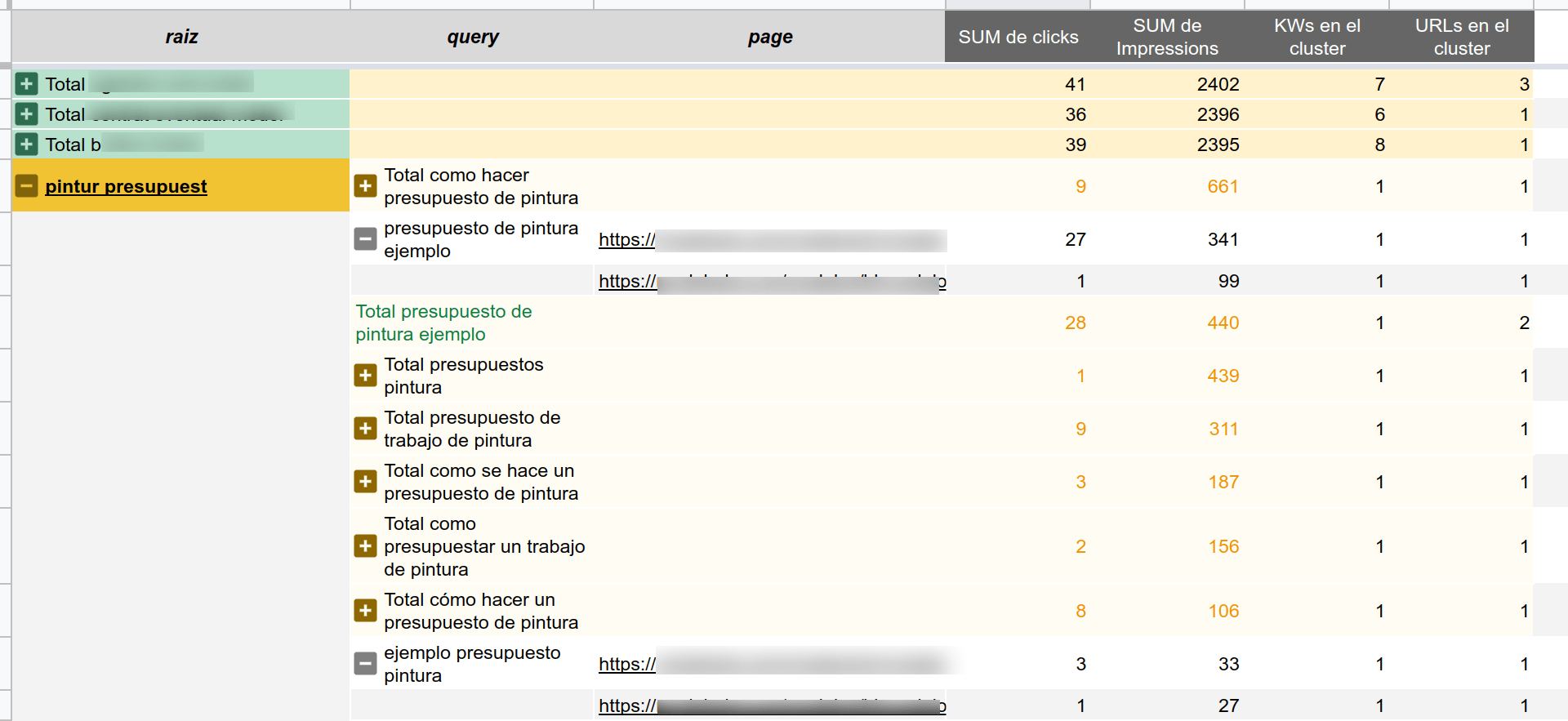
En esta tabla veremos los datos de nuestras palabras clave agrupadas, y también los datos desglosados para cada término de búsqueda y para cada URL. Una manera "sencilla" de poder comprobar con vuestros propios datos muchas cosas que antes se podrían escapar a la percepción.
Categorizar / clasificar palabras clave Vs Agrupar términos de búsqueda
Categorizar / Clasificar kws en base a una lista previamente definida
Hay bastantes artículos y plantillas en los que se usan diferentes métodos para identificar si la intención de una palabra clave es transaccional, informativa, etc, pero no he visto una agrupación accionable que mejore significativamente la comprensión de la variaedad de KWs por su propio significado y no solo por si es transaccional, informativa, etc.
Es útil tener esa información para determinar si son relevantes para NEGOCIO, o si es importante para el customer journey en el proceso de compra así que es aconsejable intentar categorizar las palabras clave en base a esa lista de intenciones, pero como digo no facilita comprender el universo de palabras clave, y no tiene sentido en todos los sites.
La clasificación o categorización de KWs también puede ser útil por ejemplo a la hora realizar el seguimiento evolutivo de SEO en las diferentres secciones, por ejemplo en una web de ropa, el identificar y asignar categorías a palabras clave peuden ser realmente útil para saber como evoluciona cada categoría, cuántas kws tienes en TOP3, TOP5, TOP10, etc, cuántos clicks tienes en kws que están en TOP3, TOP5, etc...
En FunnelPunk intentamos realizar este tipo de seguimiento... allá dónde tiene sentido :)
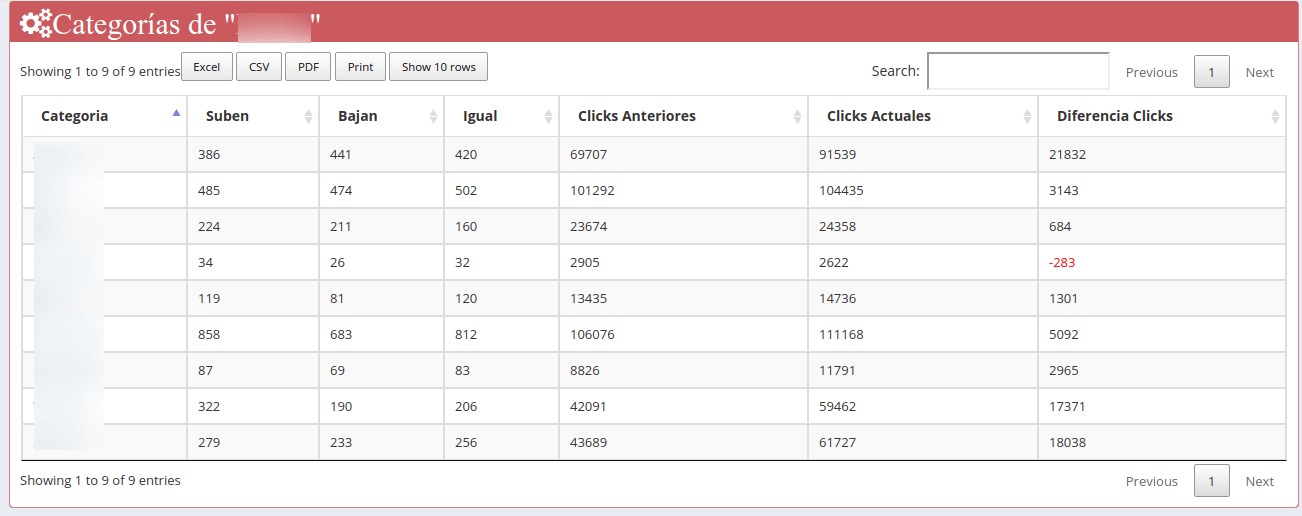
Para mi, agrupar o clusterizar es otra cosa a aplicar reglas que dicten si una KW pertenece a tal o cual categoría, para mi eso es clasificar o categorizar y como he dicho es muy útil para ciertas cosas, pero no para comprender por completo el universo de términos de búsqueda que realizan los usuarios sobre los diferentes temas que trata nuestro site.
Al crear agrupaciones de KW en base a su raíz, no partimos de una lista de secciones / términos o categorías finita y limitada en la que haya que incluír sí o sí estás búsquedas de usuario, la agrupación también evolucionará junto a los términos de búsqueda que usen los usuarios.
Agrupar términos de búsqueda
La agrupación que aquí describo es útil para poder ver las diferentes variaciones que tienen las keywords que significan prácticamente lo mismo, concer a qué URLs llegan esos clicks o impresiones del conjunto de cada cluster y todo ello sin sacrificar la riqueza en la variedad de terminología que los usaurios usan.
Digamos que con esta agrupación trabajas con las palabras clave que normalmente no trabajas porque están dispersas, y también se pueden comprobar fácilmente las variaciones que existen entre las diferentes keywords de un mismo cluster.
Podemos indetificar si los clusters están realmente bien definidos y no se mezclan términos ambiguos o incorrectos, o si existe algún tipo de problema por canibalización (aunque luego habría que mirar a fondo si la canibalización es positiva o negativa..)
A veces lo simple funciona mejor
En este ejemplo, no usamos vectores de palabras, ni usaremos la semántica para determinar si la palabra es un nombre, adjetivo, verbo, etc, para otorgarla un significado u otro dependiendo de ello, y mucho menos voy aquí a decir lo típico de Rey - hombre + mujer = Reina, que digo yo que si es tan útil como popular ¿por qué no habrá más ejemplo que ese y el de las capitales?....
En el mundo SEO los términos de búsqueda que manejamos son muy cortos para que este tipo de análisis sea eficaz y haga lo que queremos que haga.
Las keywords que obtenemos los SEOs apenas están formados por unas pocas palabras y los usuarios muchas veces no respetan la gramática ni la semántica al buscar por lo que podría ser inútil intentar darles significado según forme una parte u otra de la "frase".
Vimos en el post anterior como al lematizar no existen tantas agrupaciones y como verbos los cuales tiene la misma intención o significado dentro de la kw quedan en grupos diferentes al diferenciar su significado dependiendo del tiempo del verbo o de su posición en la oración.
Pongamos otro ejemplo de lematización Vs raíces para recordarlo
print("Raices")
print(stem_sentences(normalize("alquilar piso en San Sebastián")))
print(stem_sentences(normalize("alquiler de pisos en San sebastian")))
print(stem_sentences(normalize("alquilar piso en San Sebastian")))
print(stem_sentences(normalize("piso en alquiler en San Sebastian")))
print("Lemmatizar")
print(lematizar(normalize("alquilar piso en San Sebastián")))
print(lematizar(normalize("alquiler de pisos en San sebastian")))
print(lematizar(normalize("alquilar pisos en San Sebastian")))
print(lematizar(normalize("piso en alquiler en San Sebastian")))
Resultado
Raices
alquil pis san sebasti
alquil pis san sebasti
alquil pis san sebasti
alquil pis san sebasti
Lemmatizar
alquilar pisar santo sebastian
alquiler piso santo sebastian
alquilar piso santo sebastian
alquiler pisar santo sebastian
A la lematización se le va la pinza, primero con el término "piso", le otorga un significado diferente dependiendo de si es plural o singular, supongo que en base a la posición y significado del resto de términos en la frase.... y no digo nada acerca del término "santo sebastian", resumiendo... usando la lematización para este ejemplo no agruparía ninguna KW.
Por el contrario la raíz coincide en todas, por lo que agruparía todos los términos bajo el mismo grupo. Por eso creo que obtener las raízces para la agrupación de términos en infinitamente mejor que usar la lematización, aunque esta sea más sofisticada.
Tabla dinámica de palabras clave para SEO
Creo que no tardaremos mucho en acostumbrarnos a ver los datos agrupados de esta manera ya que cada vez es más accesible este tipo de procesamiento de texto básico, y será cuestión de tiempo que las herramientas SEO vayan adoptando esta funcionalidad. Y también me imagino vídeos en Youtube anunciando el no va más con el clustering de palabras clave SEO para tu nicho de .... ¿barbacoas??, en fin...
Hoy queremos compartir una manera más o menos funcional de poder visualizar los términos de Google Search Console desde otra prespectiva, y en posteriores artículos veremos lo que yo llamo "el estado del arte de Google Search Console" o bueno, mejor dicho el intento de "estado del arte", dónde veremos la utilidad que tiene tener acceso a todos los puntos de datos disponibles en Google Search Console ;)
[Resultado final de este post sobre del agrupamiento de palabras clave]
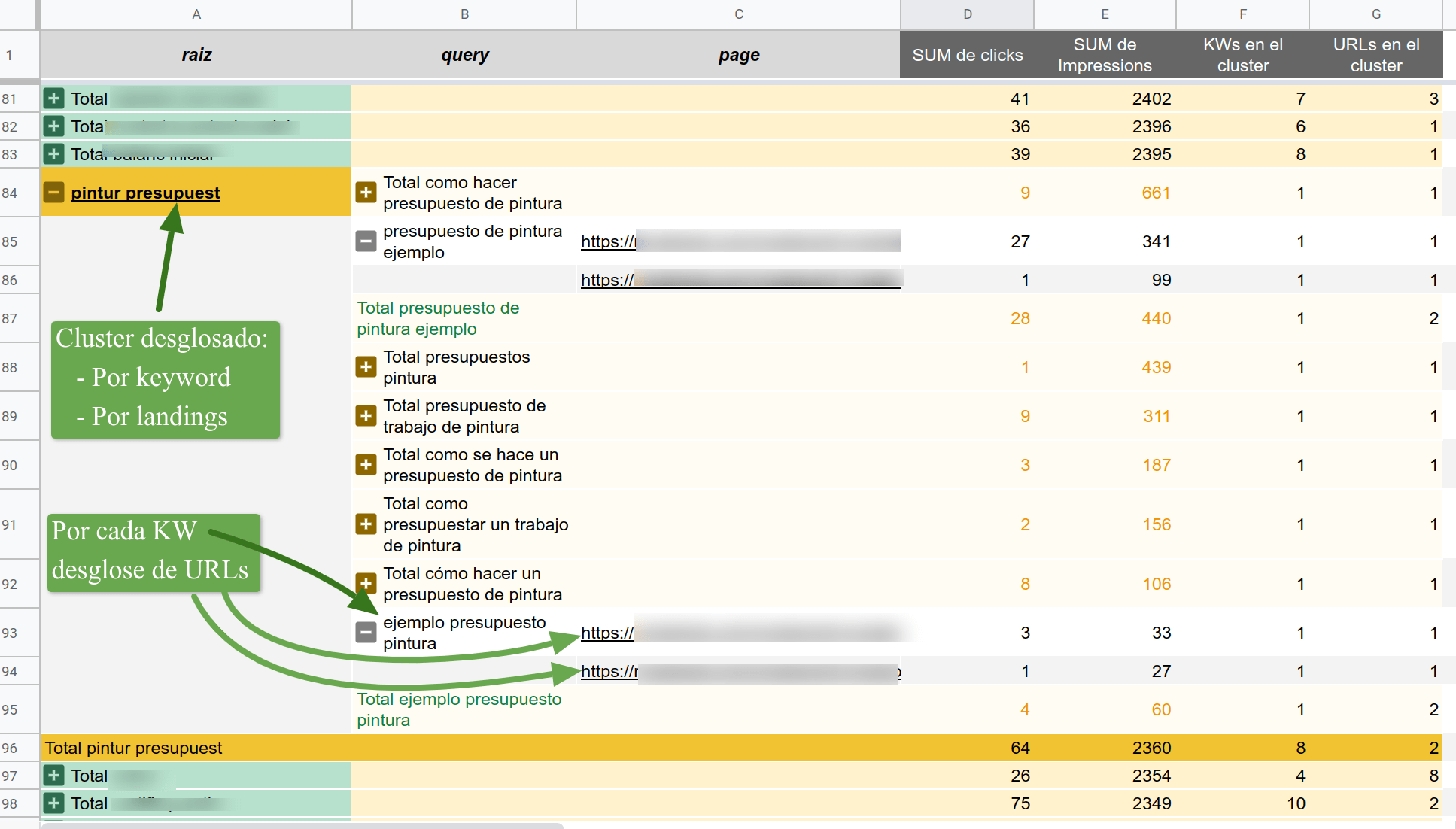
Aunque pueda parecer la ostia, a esta tabla le faltan datos de valor como veremos en próximos artículos, diría que son datos que no podremos procesar con Python así como así, por ejemplo la evolución mensual, semanal de los diferentes clusters, posición más frecuente para cada término y cuánto se podría desviar de las métricas de su grupo, pero eso será otro post de esta saga.
Si tenéis muchos datos puede que os desquiciéis un poco, ya que las tablas dinámicas con 50.000 filas en Google Spreadsheet valen para salir de un apuro, pero no para el día a día y mucho menos para poder rascar hasta el último dígito de nuestros datos.
Dentro del código
El código que dejamos abajo del artículo, el mismo que el nuevo cuaderno de Colab, no tiene muchas novedades, pero expliquemos algunas cosas que se nos quedaron en el tintero el anterior artículo.
Crear un diccionario para determinadas palabras
Una de las cosas que dejé a medias de explicar el otro día fue por qué debemos crear un diccionario para determinadas palabras clave.
No debemos confundir el diccionario con las stopwords, las stopwords las omite porque están definidas para ser omitidas a menos que las saques de la lista de stopwords.
A parte de las STOPWORDS tenemos otras restricciones para determinadas palabras. Si os fijáis en el código, concretamente en la función de normalizar vemos algo como esto
words = [t.orth_ for t in doc if not t.is_punct | t.is_stop]
lexical_tokens = [t.lower() for t in words if len(t) > 2 and t.isalpha() or re.findall("\d+", t)]
En la primera línea estamos almacenando cada palabra de nuestras KWs, con dos condiciones, tal como indica el "if not t.is_punct | t.is_stop"es decir, tenemos dos condiciones:
- is_punct: indica que si la palabra es un signo de puntuación, por ejemplo (. , : ;), la omitimos, pero no siempre querremos omitir todas las palabras con signo de puntuación. Quizás haya alguna palabra que contenga un signo de puntuación y que para nuestro proyecto sea relevante.
Por ejemplo, en SEO, puede que haya usuarios que busquen ¿Cómo configurar el robots.txt para impedir el acceso a Google? y ahí en la palabra "robots.txt" no deberíamos ignorar esa kw. - is_stop: esto la condiciona a que no esté en nuestras stopwords que ya vimos en el artículo anterior cómo añadir o eliminarlas.
En la segunda línea, lexical_tokens = [t.lower() for t in words if len(t) > 2 and t.isalpha() or re.findall("\d+", t)] tenemos otras 3 condiciones:
- len(t)>2: quiere decir que para tomar como válida la palabra, esta ha de tener al menos 3 caracteres. Pero también debemos comprobar qué palabras de dos letras tenemos en nuestros datos....
- isalpha(): nos dice si la palabra es alfanumérica, omitiendo así cosas como los emoticonos y otros caracteres "extraños".
- re.findall("\d",t): aquí estamos diciendo que si es un número no la omitamos.
Por ejemplo, pongamos que tenemos una una web sobre tecnología y tenemos las palabras clave "xioami mi 11", "xioami mi 11 12 gb", "xioami mi 5g", "xioami mi 11 5g", "xioami mi 11 6 gb", con las reglas anteriores estaríamos omitiendo tanto "mi" como "5g" cómo "gb" porque solamente contiene dos letras, no seríamos capaces de ver todas estas palabras clave en diferentes grupos y entrarían todas en un grupo llamado "xioami", pero claramente queremos diferenciar estos grupos.
Con la regla re.findall("\d",t) ya estamos "salvando" los dígitos de ser ignoradas, dependiendo de qué sites los dígitos pueden ser relevantes, muy relevantes o nada relevantes, aquí está la perspicacia de cada uno y la experiencia para saber qué nos es útil para qué y cuándo. Son cosas que quizás te las resuelva algunos algoritmos, por ejemplo si pertenecen a alguna entidad conocida dentro de una temática, pero aun resuelto esto siempre tendremos que pensar, supervisar y ajustar todo lo que hagamos, no sé mucho de Machine Learning pero de eso estoy seguro.
Volviendo al ejemplo, al tener en cuenta los dígitos como relevantes las agrupaciones que nos quedarían en este primer paso sería algo como esto.
- "xioami mi 11" → "xioami 11"
- "xioami mi 11 12 gb" → "xioami 11 12"
- "xioami mi 5g" → "xioami 5g"
- "xioami mi 11 5g" → "xioami 11 5g"
- "xioami 11 6 gb" → "xioami 11 6"
Pero vemos que no es suficiente, ya que no identificamos el modelo del teléfono "mi" y nos gustaría que además de valorar los dígitos también queremos que nos valore el modelo "mi".
Para esto usamos el diccionario, y lo que hacemos es algo bastante simple que es sustituir los términos "xioami mi" por "xioamimi", y lo realizamos antes de cualquier otra operación en nuestro tratamiento de texto, para que no sea ignorada.
En este caso para no ignorar "mi" lo asociamos al término "xioami" porque si no podría comenzar a valorarnos cualquier palabra que contenga "mi" por ejemplo "precio de mi movil", y no tiene nada que ver con el resto de términos en el cluster. En cambio si fuese "precio de Xioami mi" sí nos interesa.
Algunas veces es un poco coñazo, pero sin duda, en muchos sites es algo vital el hacer este ejercicio, todo depende....
Para realizar estas sustituciones podemos usar expresiones regulares como esta, dónde las palabras de dos letras que nos son de interés las sustituimos por la unión de ambas y así no las ignoraremos.
replace_dict = {re.compile(r'(.*)?xioami mi(.*)?'):r'\1xioamimi\2',
re.compile(r'(.*)?gb(.*)?'):r'\1gigas\2',
re.compile(r'(.*)?5g(.*)?'):r'\1cincog\2'}
En próximos artículos veremos cómo hacer esto eficientemente cuándo tenemos que escalar. No no hablo de escalada con cuerdas y demás artilugios, sino de hacer esto en tiempo real en sites con mucho volumen de tráfico y por ende muchísimas palabras a tratar.
Cuando Pandas no es suficiente
Cuando el número de filas no sea muy grande, por ejemplo 50.000 el código del anterior post puede resolvernos el problema, por ejemplo obteniendo 50.000 filas de la herramienta Search Console Punk Export tarda más o menos unos 20 minutos en procesarlas, aunque también varía dependiendo de la cantidad de términos de búsqueda únicos que tengamos y que puede variar mucho de un site a otro en el mismo número de filas.
En el caso de FunnelPunk, procesamos TODOS los datos disponibles de Google Search Console, es decir, volcamos diariamente unas 150.000 filas, 50.000 filas de un único por cada estrategia de volcado que tenemos.
Además, podemos procesar para otros menesteres cantidades bastante grandes de palabras y fue en uno de estos casos cuando me di cuenta de que la librería Pandas no era capaz de procesar todo.
Ejecuté el script y al inicio indicaba que faltaban unas 4 horas y media para terminar el proceso. Pasada media hora, marcaba que ahora faltaban 5 horas, es decir iba creciendo el tiempo que tardaba, cuánto más datos procesaba más tardaba... total, lo dejé funcionando y me fui a la cama.
Al día siguiente cuándo miré si había terminado cuál fue mi sorpresa (ingrata sorpresa) al ver que faltaban 80 horas... lo que parece indicar que jamás iba a terminar. He de reconocer que intenté ejecutar creo que un csv de unos 35 millones de filas, (¿somos punkis o no somos punkis? :p) que parece mucho, pero no lo es tanto...
Ya os contaré cuál es la mejor manera de hacer según que cosas para obtener datos relacionados con el SEO, pero ccómo veís aprendo probando, no hay otra a la hora de programar y de tratar datos.
Gracias a algunos amigos frikis de mi querida Salamank me dijeron isofacto que debería usar Dask, que es como Pandas pero capaz de dividir los sets de datos para procesarlos paralelamente.
Así lo hice y el script consiguió terminar en menos de 1 hora, mi querido Pandas había caído del pedestal.... aunque lo sigo adorando por lo fácil que son algunas cosas, otras no tanto :s
En este caso, "solo" vamos a procesar 50.000 filas de Google Search Console y he comprobado que el código con Pandas tarda poco más de 20 minutos, en este ejemplo concreto 23 minutos y 5 segundos en ejecutar el proceso
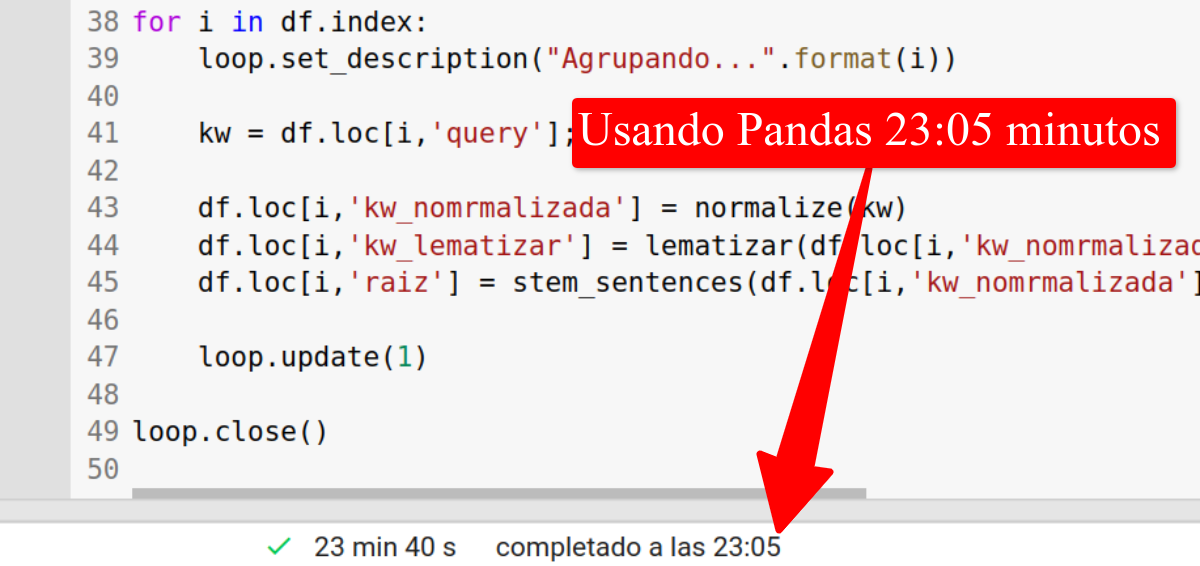
El mismo set de datos pero usando Dask lo ha terminado en 15 minutos y 18 segundos, es decir, un 30% más rápido.
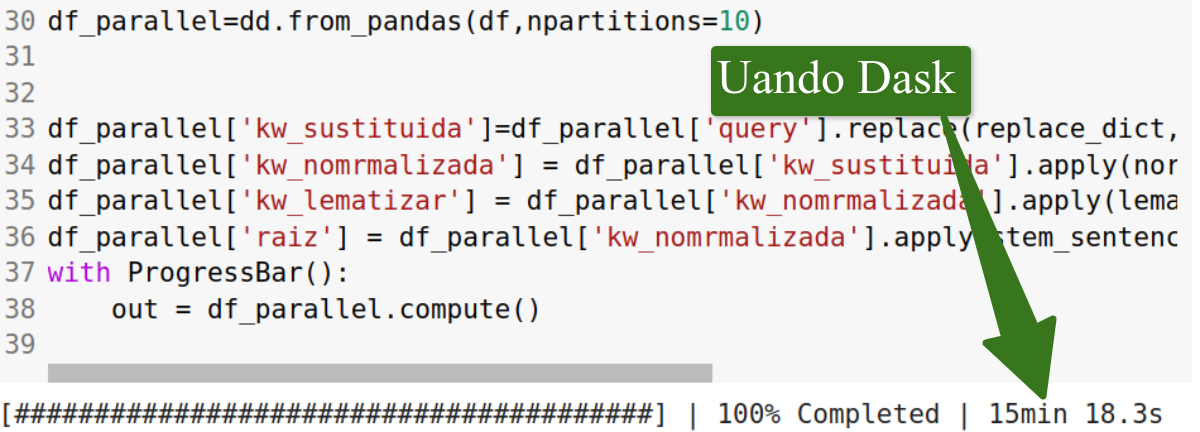
Como he dicho antes, seguramente cuánto mayor cantidad de datos más brecha habría entre uno y otro, y también es cierto que con mejoras en el hardware, concretamente en la RAM seguramente mejoraría. Pero cuando la cosa va de calcular, voy a aprendiendo que más valen 8 procesadores y poca RAM que al revés, mucha RAM y pocos procesadores, siempre y cuando lo que ejecutes sea capaz de distribuirlo entre estas cpus... Veremos más sobre esto en el futuro :)
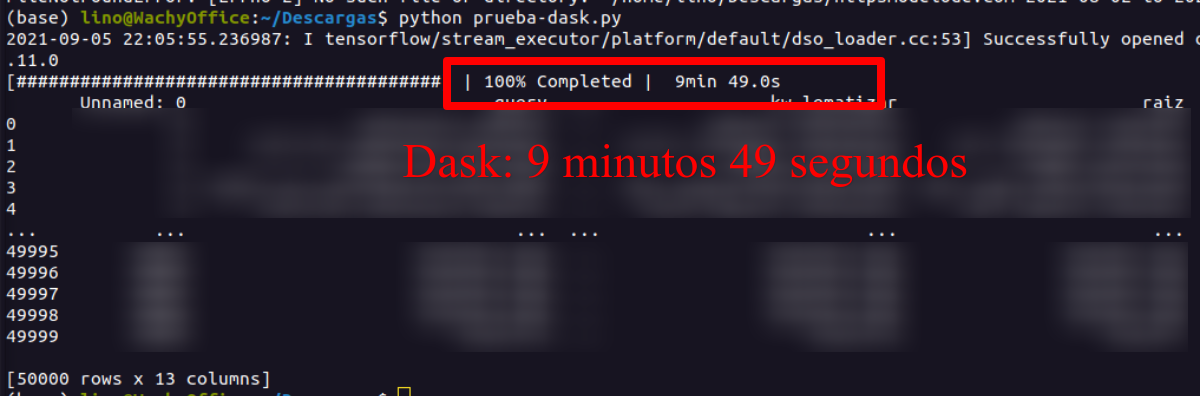
Cuando lo ejecuto en mi ordenador, la diferencia es bastante mayor, no me digas por qué, ya he dicho que no soy experto, pero puede que tenga que ver con que Colab depende del uso de su red en ese momento te asignará más o menos recursos.
Usando Pandas tardó 18 minutos, y es una de las veces que más rápido le he visto ejecutarlo, pero como os comentaba antes, si son muchos datos (hablo de algún millón de filas para arriba) Pandas puede eternizarse.
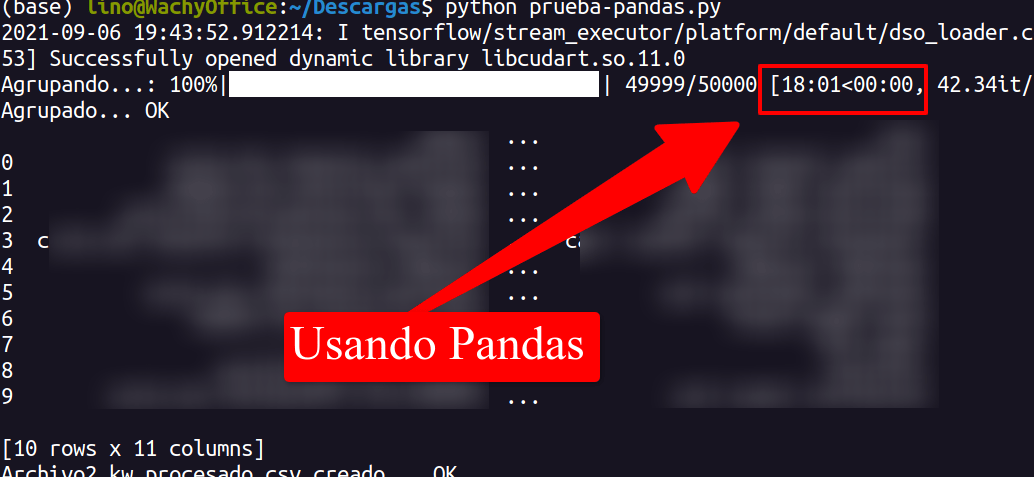
Mientras que usando Dask solo tardó 9 minutos y 49 segundos, es decir, la mitad de tiempo, esto aquí y así no parece mucho, pero cuándo son horas lo que ha de estar procesando y cuándo lo haces en servicios como AWS dónde te cobran por segundos, pues puede ser el doble de costes para la empresa, en este caso mi bolsillo, aunque con este poco tiempo de procesamiento no costaría apenas dinero, pero a la hora de escalar... otro gallo cantaría.
Reconocer cosas que no controlas
Aunque lidio con cualquier código, y como veis, al final consigo realizar lo que me propongo no soy experto en Python. No debemos subestimar a los desarrolladores que llevan años y años picando código Python. No me atrevería a decir, de momento, que con python hago "eso" en 5 minutos, siendo "eso" cualquier cosa... Está claro que este tipo de fakes solo lo dicen las personas que realmente no han programado algo seriamente.
Cuando hablamos de Machine Learning y copiamos código que vemos por ahí, está bien, es un comienzo, pero debemos saber que depende en qué cantidad o en qué escenario la cosa se suele complicar y mucho, quién no lo sepa es que no se ha enfrentado a entornos en producción, y mucho menos en grandes empresas...
Con esto quiero decir, que quizás se pueda hacer de otra manera, y que seguramente mi código sea muy mejorable! Si controlas Python y ves mejoras relevantes no dudes en enumerarlas en los comentarios de este Post :)
Nuevo código para agrupar palabras clave SEO usando Dask
Así que después de hablar sobre mi caso de uso y mi propia experiencia os dejo el mismo script que hicimos en la parte I de esta saga, pero usando Dask.
Como veréis algunas cosas cambian, sobretodo el cómo se aplican las funciones, y el comando out = df_parallel.compute() que sirve para unificar los diferentes procesos en los que ha dividido las operaciones Dask.
También estamos aplicando el diccionario, de una manera más efectiva, o mejor dicho menos redundante :)
Código Python
Necesitarás los datos de Google Search Console, te recomiendo uses mi herramienta para descargar hasta 50.000 kw, las veces que quieras :)
- Descarga desde Punk Export los datos de Google Search Console para obtener 50.000 filas (utiliza el botón "CSV")
Una vez hayas descargados los datos usando el formato CSV, guarda el fichero y cambia el nombre del fichero en el código python, en la línea que pone "df = pd.read_csv('datos-Google-Search-Console.csv')" cambia 'datos-Google-Search-Console.csv' por el nombre de tu CSV
# -*- coding: utf-8 -*-
import argparse
import sys
import pandas as pd
from dask import dataframe as dd
from dask.diagnostics import ProgressBar
from nltk import SnowballStemmer
import spacy
import es_core_news_sm
from tqdm import tqdm
from unidecode import unidecode
import glob
import re
import requests
import json
df = pd.read_csv('datos-Google-Search-Console.csv')
#mostramos 10 límeas para asegurarnos de que se ha subid correctamente
df.head(10)
from spacy.lang.es.stop_words import STOP_WORDS
nlp = es_core_news_sm.load()
spanishstemmer=SnowballStemmer('spanish')
#añade aquí las palabras que no quieres que sean ignoradas
nlp.Defaults.stop_words -= {"empleo","acuerdo","anterior","deprisa","ejemplo","emplear","horas","realizar","supuesto","tarde","tiempo","trabajo","trabajar","trabajan","trabajas","ultimo","ultima","ultimos","ultimas"}
#Lista de palabras que serán ignoradas
print(STOP_WORDS)
def normalize(text):
text = unidecode(str(text))
doc = nlp(text)
words = [t.orth_ for t in doc if not t.is_punct | t.is_stop]
lexical_tokens = [t.lower() for t in words if len(t) > 2 and t.isalpha() or re.findall("\d+", t)]
return ' '.join(lexical_tokens)
def lematizar(text):
lemma_text = unidecode(str(text))
doc = nlp(lemma_text)
lemma_words = [token.lemma_ for token in doc if not token.is_punct | token.is_stop]
lemma_tokens = [t.lower() for t in lemma_words if len(t) > 2 and t.isalpha() or re.findall("\d+", t)]
return ' '.join(sorted(lemma_tokens))
def stem_sentences(sentence):
tokens = sentence.split()
stemmed_tokens = [spanishstemmer.stem(token) for token in tokens]
return ' '.join(sorted(stemmed_tokens))
#como ejemplo de diccionario, vamos a modificar la palabra 'SEO' por 'posicionamiento web'.'xioami mi' y 'no index'
#debems añadir las 3 filas por cada palabra, ejemplo para "no index"
'''
re.compile(r'^no index (.*)'): r'noindex \1',
re.compile(r'(.*) no index (.*)'): r'\1 noindex \2',
re.compile(r'(.*) no index$'): r'\1 noindex'
'''
#ejemplo para "xioami mi"
'''
re.compile(r'^xioami mi (.*)'): r'xioamimi \1',
re.compile(r'(.*) xioami mi (.*)'): r'\1 xioamimi \2',
re.compile(r'(.*) xioami mi$'): r'\1 xioamimi'
'''
#Ejemplo completo para los tres términos:'SEO' por 'posicionamiento web'.'xioami mi' por 'xioamimi y 'no index' por 'noindex'
replace_dict = {re.compile(r'^seo (.*)'): r'posicionamiento web \1',
re.compile(r'(.*) seo (.*)'): r'\1 posicionamiento web \2',
re.compile(r'(.*) seo$'): r'\1 posicionamiento web',
re.compile(r'^xioami mi (.*)'): r'xioamimi \1',
re.compile(r'(.*) xioami mi (.*)'): r'\1 xioamimi \2',
re.compile(r'(.*) xioami mi$'): r'\1 xioamimi',
re.compile(r'^no index (.*)'): r'noindex \1',
re.compile(r'(.*) no index (.*)'): r'\1 noindex \2',
re.compile(r'(.*) no index$'): r'\1 noindex'}
df_parallel=dd.from_pandas(df,npartitions=10)
df_parallel['kw_sustituida']=df_parallel['query'].replace(replace_dict, regex=True)
df_parallel['kw_nomrmalizada'] = df_parallel['kw_sustituida'].apply(normalize,meta=('kw_sustituida', 'object'))
df_parallel['kw_lematizar'] = df_parallel['kw_nomrmalizada'].apply(lematizar,meta=('kw_nomrmalizada', 'object'))
df_parallel['raiz'] = df_parallel['kw_nomrmalizada'].apply(stem_sentences,meta=('kw_nomrmalizada', 'object'))
#Ahora unirá los datos de los diferentes procesos en paralelo que ha creado Dask, esto es lo que más tardará, paciencia :)
with ProgressBar():
out = df_parallel.compute()
out.to_csv('resultado-datos-Google-Search-Console.csv', header=None, encoding='utf-8-sig', index=False,sep='\t')
- Una vez terminado el proeso te generará un fichero, abre esta la plantilla y haz una copa ("Archivo" --> "Hacer una copia")
- Ahora abre el csv generado tras la ejecución del código y copia todas las filas.
- Pega en la hoja "datos-exportados-PunkExport" los datos del CSV y... magia :)
Código en Colab
He creado otro cuaderno de Google Colab para quien quiera ejecutar el código sin tener que instalar nada en su ordenador con todos los pasos a seguir para crear esta tabla dinámica.
He intentado definir lo mejor posible los pasos a realizar para que cualquiera pueda hacer esta agrupación y verlo en una tabla dináimica, por favor, cualquier duda, sugerencia o corrección no dudéis en ponerla en los comentarios, no lo hagáis en Twitter porque luego las discusiones y conocimiento se quedan ahí y no sirven para ningún usuario que llega al post ya que desde Twitter se llega al post, pero desde el post no se llega a las conversaciones sobre el artículo :(
Aquí dejo también la plantilla para la creación de la tabla dinámica de keywords, dónde una vez copiada a vuestro propio Google Drive solo tendréis que pegar los datos obtenidos al ejecutar el código del cuaderno Colab y podréis tener, usar y modicar todo a vuestro antojo o necesidad.
Seguro que gente como Juan es capaz de montar un buen Google Data Studio, aunque particularmente lo odio.. (no he visto cosa más lenta).
Para visualizar los clusters de Keywords es una manera un poco precaria, pero el cómo verlos de una manera mucho más eficiente y pudiendo filtrar fechas, recoger tendencias, volúmenes de búsqueda, posición en el último mes, última semana y alguna que otra sorpresa lo dejo para artículos posteriores.
En Funnel▼Punk estamos abiertos a brindar soluciones a medida a aquellas empresas que lo necesiten, si crees que podemos ayudarte no dudes en contactarnos :)


Fernando LEns (@)hace Hace más de 3 años y 309 días
Tremendo.
Ya bien testado, funciona muy bien. Incluso con muchos datos tira bien y no tarda mucho .
La pestaña de Cluster sin raiz sale vacía. ¿Imagino que me queda por hacer algún paso más?
Gracias Lino!
Lino (@errioxa)hace Hace más de 3 años y 309 días
@Fernando LEns es por si acaso falla en algo, pero viendo tu feedback y que no he dicho nada de esa hoja, la borraré :)
José B. Moreno Suárez (@jbmoreno)hace Hace más de 3 años y 282 días
Yo hace tiempo que agrupaba con stemmers. Ahora, además, comparo con un proceso las keywords que aportan impresiones a una URL determinada (datos de GSC) y con otro proceso paso un algoritmo de distancia de edición a los stemmers que -cuando encuentra- coincicidencias por debajo de un determinado umbral me manda una alerta para ver si son agrupables.