Borrar el historial del navegador con JavaScript
El otro día le dije a Sergio Blanco que me estaban convenciendo sus argumentos de por qué Google podría estar valorando la experiencia de usuario y si el comportamiento de los usuarios podría influír en los rankings del buscador.
A simple vista parece que sería lógico que cuanta menoss tasa de rebote tenga una url habrá más usuarios satisfechos que habrán encontrado lo que buscaban. Pero si te pones a pensarlo, como si fueses Google, ¿cómo puedes identificar si un usuario está comparando precios entre distintas webs y por ello luego volverá atrás sin que realmente haya salido insatisfecho?
Está claro que no es una cifra que la tomaría así a la ligera, la compararía con datos de otras webs del mismo sector/temática que consigue debido a todos los cacharros que Google tiene desplegados entre las páginas web (analytics, AdWords, AdSense,etc) y también entre los usuarios (crhome, barra de Google, Google+, etc) pero sobretodo se fijará en lo que los usuarios hacen en la página de resultados de Google. Detectaría por ejemplo cuando un usuario hace atrás en el navegador para volver a la página de Google, y luego pincha en otro resultado o hace una búsqueda muy similar, tendrías un puntito negativo, como en clase.
La idea sería que una búsqueda concreta tuviese asociada una tasa de rebote promedio y esa tasa seria la que se compararía con tu web. Si por ejemplo para la búsqueda "segunda ley de termodinamica" la tasa de rebote es de 43% de media entre los datos que Google dispone, y si tu página tiene una tasa de rebote del 92% será síntoma de que ese resultado no ha sido satisfactorio para los usuarios y por tanto irá rebajándola posiciones.
En cambio para la búsqueda "comprar samsung galaxy s" el comportamiento del usuario será diferente, supongo. Entrará en muchos resultados y muchas veces le dará atrás en el navegador, no porque no le haya gustado, sino para comparar precios. Para está búsqueda quizás la tasa de rebote media sería mucho mayor que la anterior y Google no la tendría en cuenta en su algoritmo a la hora de valorar los resultados a mostrar para esa búsqueda determinada.
Pero creo que esto no es tan fácil como parece, el comportamientos de los usuarios no son tan claros, no se comportan igual por muchísimos motivos, culturales, experiencia en internet por parte del usuario, etc... Eso es lo que siempre me ha hecho pensar que no se puede medir la calidad de un resultado para una búsqueda viendo esa tasa de rebote.
Incluso el comportamiento de un mismo usuario puede varíar! el "¿para que?" buscamos algo puede ser por diversos motivos de variar el comportamiento de un mismo usuario, imagina que lo estás viendo con otra persona interesada sentada tu lado, eso cambiaría mucho mi comportamiento de usuario, si lo hago mientras trabajo y estoy preocupado de que el jefe no me vea mi comportamiento también será diferente, si lo hago mientras como porque no tengo tiempo para nada pues me comportaré de otra forma, etc. Se me ocurren miles de cosas que hacemos habitualmente y que podría variar mucho mis datos de experiencia de usuario y por eso creo que no deberían ser relevantes.
¿Panda Dance?
Si ahora Google valorara el comportamiento de usuario podría ser uno de los motivos del por qué los grandes cambios en los resultados (Google Panda) sólo se dan cada cierto tiempo (¡como hace tiempo Google Dance!), ya que debería hallar la media para muchísimas busquedas disntitas de muchísimos datos y eso llevaría su tiempo.
También podría ser que el desvío de la tasa de rebote de una página con respecto a la media fuese un factor de alerta a Google. Y si entraras en esa alerta Google te evaluará mediante otro algoritmo para decidir si ese contenido es de calidad o no y apuntarlo, y que para el resto de web que no tieen esa alerta no lo hace.
Buscando patrones
Otras cosas que se están escuchando por ahí es la de que está usando un algoritmo capaz de identificar en las webs los patrones que tienen en común las que son satisfactorias para una búsqueda y las que no. Para ello se rumorea que primero se usan personas humanas con criterio y van identificando si una página es buena o no para determinadas búsquedas. Con muchos datos tan fiables podrían identificar lo que une a las buenas páginas y lo que las diferencia de las que han sido marcadas como malas y luego aplicarlo al resto de webs. Creo que esto está más cerca de la realidad que lo del comportamiento del usuario, aunque el comportamiento del usuario podría acabar siendo relevante si este es uno de los factores que encuentran en común... asi que como siempre habrá que intentar mejorar en lo que se pueda para evitar esas tasas de rebote.
De momento Google no da pistas y si las da no debemos creerle demasiado, no podéis olvidar que Google no quiere que los SEOs sepamos cómo lo hace, ya que nuestro principal trabajo es alterar esos resultados "justos" e influir en lo necesario para escalar posiciones, estamos en lucha contra él y nunca nos dirá pistas relevante, por lo menos adrede
Como vereis si navegais por un par de urls de esta web comprobaréis como el navegador se empeña en ir hacia adelante, estoy intentando reducir la tasa de rebote de la web, para después poder hacer algunas pruebas de cómo Google valoraría la tasa de rebote.
El código es fácil,
En la página la que no quires que vuelvan usa
<script language="javascript">
function NoBack(){
history.go(1)
}
</script>
Y al Body le añadimos OnLoad="NoBack();"
<BODY OnLoad="NoBack();">
Lo que hace es que cuando cargue la web, no sólo cuando le da atrás sino también cuando la carga normal, hacemos como si el usuario hiciese click en el botón de aldelante, si el usuario no le ha dado al botón de atrás esto es imposible porque aún no existe en su navegador, si le ha dado atrás pues le volverá a llevar hacia adelante. Esto se podría mejorar, pero vamos a ver si así altero las métricas de tasa de rebote.
Tengo otra manera mejor que la voy a intentar poner ahora, y es que cuando haga atrás, en vez de eso lo que haré será enviarle a Google directamente, con un window.location.href=www.google.es así el usuario volverá a Google y no a la misma página de resultados que le llevo a mi web.
No sé si a Google le gustará o no, pero a los usuarios seguro que no! Si Google comenzase a valorar la experiencia de usaurio para el posicionamiento los SEOs en vez de engañar a Google aprenderemos a

Comentarios
5Lee otros artículos
Cómo se adapta Googlebot al tamaño del contenido
Publicado por Lino uruñuela el 9 de febrero del 2021 índice Un poco de historia sobre Google y JavaScript en este blog Datos del último experimento Código JavaScript para capturar el evento resize Código JavaScript Código en .htaccess Fichero ResizeRenderizadoJS.php (PHP) Datos del último experimento Observaciones sob…
Cómo saber qué errores JavaScript genera Google cuando ejecuta JavaScript
Publicado por Lino Uruñuela el 1 de febrero del 2021 Ya hemos visto cómo podemos comprobar y monitorizar qué URLs renderiza Google, pero si queremos ir un poco más allá también podemos capturar y guardar en Google Analytics qué errores JavaScript se producen cuándo Google ejecuta el código JavaScript para renderizar e…
Cómo ver las URLs renderizadas por Google en Google Analytics
Publicado por Lino Uruñuela el 1 de febrero del 2021 Desde hace unos cuántos años Google está produciendo grandes avances en su capacidad rastrear y obtener el contenido cargado por JavaScript, tal como lo haría un usuario navegando desde un dispositivo móvil. Para ello deduzco que ha debido hacer grandes cambios en s…

Diferentes métodos para indexar contenido JavaScript - Ajax
Webs en JavaScript, metodos para la carga de contenido rastreable por Googlebot esta. basado en Chrome 41 sí soporta determinadas funcionalidades posteriores al número de su versión, pero no sabemos cuáles.
Carga de imagenes usando lazy load - Resultado del experimento
Publicado el 15 de febrero del 2019 por Lino Uruñuela índice de contenido Métodos probados en el experimento Carga normal, sin lazy load Imagen usando thubmnail de posición Cargar imagen desde desde data-src Imagen usando thubmnail de posición y noscript Sin usar thubmnail pero sí noscript Sin usar thubmnail ni tampoc…

Indexar imágenes en Google usando Lazy Load
Publicado el 23 de diciembre del 2018 por Lino Uruñuela índice de contenido ¿Qué es lazy load? Diferntes maneras de cargar imágenes medidante lazy load Miniatura de posición Usar < noscript > y miniatura de posición Añadir estilos para eliminar <noscript> Cómo aegurarnos que las imágenes serán indexables&l…
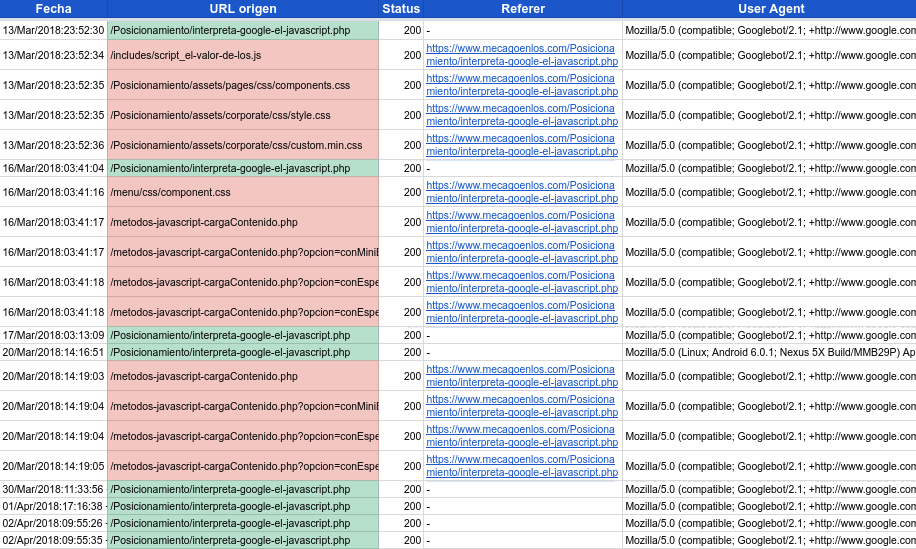
La segunda ola de indexación y cómo saber qué renderiza Google
Publicado por Lino Uruñuela el 23 de julio del 2018 Desde hace ya unos años venimos viendo cómo Google es capaz de cargar e indexar ciertos contenidos via javascript, en este blog hemos hecho muchos experimentos sobre cómo Google rastrea e indexa el contenido cargado mediante JavaScript. Los últimos experimentos sobre…
Cómo cargar css y js y no bloquear la carga de contenido | Experimento con canonical
Publicado el 5 de enero del 2018 por Lino Uruñuela Experimento con canonical, en el próximo post mostraré resultados, mirar el final de este para intentar entender algo Como muchos habréis notado he rediseñado el blog, que ya era hora después de 11 años con el mismo diseño. Los motivos han sido varios Mobile First El…
Cómo cargar css y js y no bloquear la carga de contenido
Publicado el 11 de Octubre del 2017 por Lino Uruñuela Como muchos habréis notado he rediseñado el blog, que ya era hora después de 11 años con el mismo diseño. Los motivos han sido varios Mobile First El híper anunciado índice móvil parece ser que está llegando este mes, cosa que ya anunció Google hace bastante tiempo…
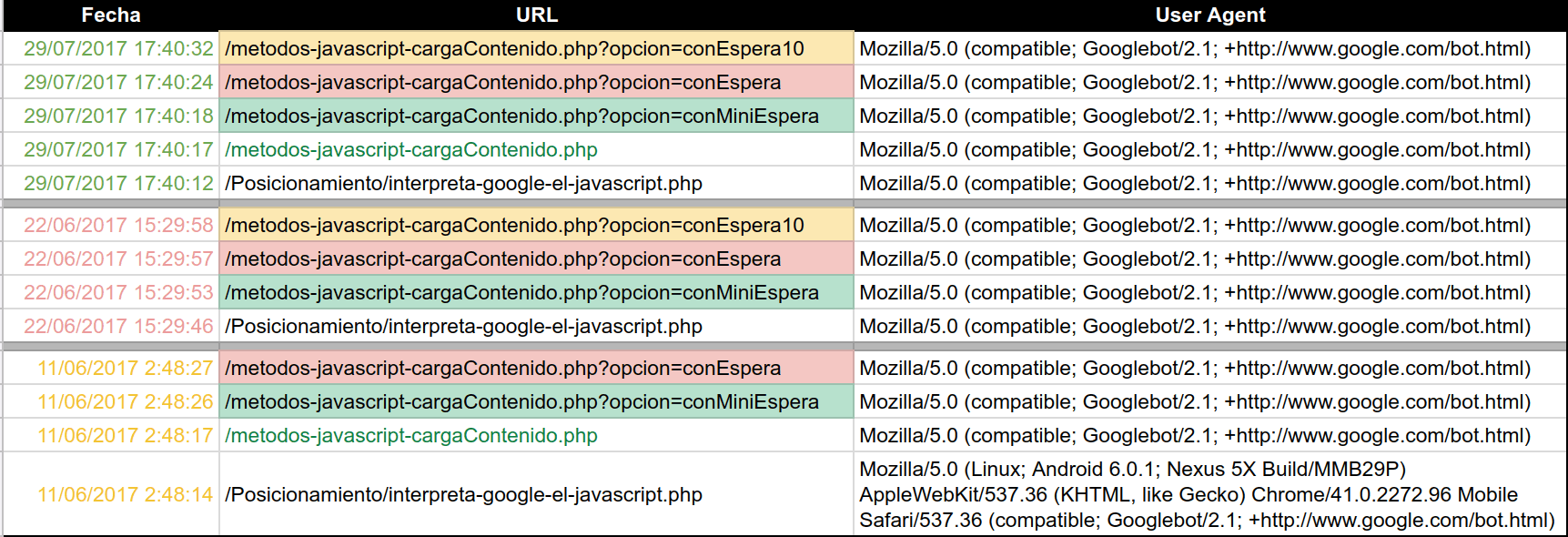
¿Cómo ejecuta, interpreta e indexa Google el contenido cargado mediante javascript?
Publicado el 14 de agosto del 2017 by Lino Uruñuela, SEO El otro día realizamos un test de lo más interesante, ¿Interpreta Google cualquier JavaScript que esté en el onready? , para intentar entender cómo Google rastrea, renderiza e indexa el contenido cargado mediante JavaScript. Ya habíamos hecho muchos experimentos…
Hola Abide Tienes razón en lo de que es una quimera de experimento, pero si funcionase sería muy revelador, aunque lo más seguro es que no varíe en nada. En lo demás también estoy de acuerdo, no es tan sencillo.
ok, estaré expectante a que publiques los resultados, tengo una gran curiosidad.. .. realmente envidio la creatividad que tienes para este tipo de cosas PD: la envidia además es de la insana ;-)
Mientras esperamos resultados... Creo que todo algoritmo puede ser artificialmente influido, lo es ahora con los link, a más calidad, y cantidad de links, mejor vamos a posicionarnos. Es como la democracia, no es perfecta, pero es mejor que cualquier otra opción ;) ¿Qué diferencia existe entre un voto (un link) de una web a otra y el voto de un usuario? Por qué hablamos de formas culturales de comportarnos, cuando google está midiendo ya todos los links por el mismo rasero y no nos importa? Al medir la experiencia de un usuario, sea cual sea la métrica, google estaría añadiendo una variable más a la ecuación, no LA VARIABLE. Una métrica por cierto, bastante menos influenciable a priori que el tema de los links. Pero ¿Cómo puede medir google objetivamente la calidad del contenido de una página sino? Me resisto a creer que un H1 va a decir si esta página tiene un contenido mejor o peor que otro. No puede ser así de simple. Yo no estoy diciendo que a menos rebote, mejor posicionamiento. Porque eso no funcionaría, no creo que vaya así. En tu ejemplo de la tasa de rebote de una página ¿Puedes sacar ese dato por keyword? o incluso por posición en las SERPS? porque la tasa de rebote de una página, puede indicarnos algo, o nada. En el ejemplo que comentas de comprar un samsung galaxy, si todas tienen la misma tasa de rebote, no cambia nada, pero ¿y si mide el tiempo que pasas en cada página para cada búsqueda? Has visitado 10 precios, pero en una has estado más tiempo, porque tiene más información extra.
Saludos, esta muy interesante tu experimento y me gustaría hacerte una pregunta que posiblemente puedas responder. Se me ha presentado una situación que cuando le de al botón de ir hacia adelante o hacia atrás poder ejecutar una función, pero lamentablemente esos botones a pertenecer al navegador no tengo ningún control sobre ellos. ¿Crees que sea posible controlar esos botones o ejecutar algún procesos al presionarlos?