Evita Contenido Duplicado
Ayer os hablábamos del nuevo formulario puesto por Google en la zona de sitemaps para que los webmasters podamos denunciar los links que se venden o se compran para alterar los resultados del buscador, hoy, nos podemos leer cómo Google hace por resolver una preocupación de muchos webmasters, el contenido duplicado.
Hoy Google ha publicado un nuevo artículo en su blog sobre el contenido duplicado, las maneras de evitarlo y las soluciones que está escuchando desde diversas fuentes. Por lo que leo y lo que entiendo, está dando algunos consejos a los webmasters para que no tengan contenido duplicado creados por ellos mismos, pero no llega a tener una solución para evitar el contenido duplicado por otros webmasters que se aprovechan de otras páginas, copiando y pegando.
Os resumo un poco los puntos del artículo, estos son las aclaraciones de Google sobre el contenido duplicado:
- Google quiere servir resultados únicos y hace un buen trabajo al escoger una versión de su contenido, cuando hay más de uno igual en un mismo dominio. Si usted no quiere preocuparse de revisar la duplicación sobre su sitio, Google lo hará por ti.
- El contenido duplicado no hace que su sitio sea castigado. Si páginas dobles son descubiertas, una versión será mostrada en los resultados. Dice que no es lo más óptimo para el posicionamiento ya que lo que ocurre es que el PageRank
se dispersa en lugar de concentrarse en una sola página
- El contenido duplicado no hace que su sitio sea colocado en el índice suplemental. La duplicación sí puede influir indirectamente en esto sin embargo, si se vincula a sus páginas son hendidos entre varias versiones, causando PageRank más abajo por página.
- Especificando la versión preferida de una URL en el archivo Sitemap del sitio. Una cosa de la que hablamos era la posibilidad de especificar la versión preferida de un URL en un archivo Sitemap, con la sugerencia que si encontráramos múltiple URLS que indica el mismo contenido.
- Usando el robots.txt. Proporcionando un método para indicar los parámetros que deberían ser quitados de un URL dinámica desde ael archivo robots.txt. Por ejemplo, si un URL contiene sesiones IDs, el administrador del sitio web podría indicar la variable para la sesión ID en el archivo robots.txt para que no fuesen indexadas las páginas con este parámetro.
- Proporcionando un modo de autenticar la propiedad de contenido por ejemplo usar la página con la fecha más temprana, pero las fechas de creación son no siempre fiables. Alguien también aconsejó permitir a dueños de sitio registrar el contenido, esto se lo propuse yo a Mutt Cutts, en los comentarios de uno de sus posts y fue borrado al cabo de unos días pero parece que lo escucharon, también lo describí aquí. La pega que le ponen a esto es que muchos no sabrían que habría que hacer esto y otros webmasters se podrían aprovechar de ellos, autentificando los contenidos antes que los originales. Yo creo que esto se podría dar, pero sólo al comienza de este sistema, luego todos lo haríamos cada vez que escribiésemos algo.
Según Google actualmente confían en varios factores como la autoridad del sitio y el número de links que vinculan a la página. Si el contenido es sindicado, no ssugieren que usted pregunte los sitios que usan su contenido para bloquear su versión con un archivo robots.txt .
- Hacer un duplicate content report, o sea que pusieran un formulario para denunciar el contenido duplicado por los propietarios de ese contenido.
- Hablar con los creadores de software para la creación de blogs, para llegar a un acuerdo de cómo identificar este contenido, por ejemplo en WordPress.
- ¿Si pongo muchos links con rel="nofollow" podría ser penalizado?
Según Google, no. Pero dice que no es la mejor manera de hacerlo y nos dice de nuevo que la mejor manera es usar el robots.txt para evitar esa indexación, haciendo por ejemplo una página intermedia en nuestro dominio que esté "capada" en el robots.txt, así el buscador nunca llegará a esas pñaginas y por lo tanto tampoco a la de destino.
- ¿Siguen los motores de búsqueda la alianza Sitemaps?
Supuestamente dicen que sí, y que han hecho avances como por ejemplo poder poner en el archivo robots.txt la localización de nuestro sitemaps.
- ¿Cómohacer en páginas que muestran imágenes o gráficos sin texto que identifiquen el contenido?
Pues como era de preveer, nos insta a crear en estás páginas, que los metas títle y description sean únicos, al igual que el alt de las imágenes.
- Tengo sindicado mi contenido a muchos afiliados y ahora algunos de aquellos sitios están para este contenido más bien que mi sitio. ¿Qué puedo hacer?
No dice que si usted libremente ha distribuido su contenido, usted debe tener que realzar y ampliar el contenido sobre su sitio para hacerlo único.
- Como un investigador, quiero ver duplicados en resultados de búsqueda. ¿Puede usted añadir esto como una opción?
Y nos dicen, hemos encontrado que la mayor parte de investigadores prefieren no tener resultados dobles. Un miembro de audiencia en particular comentó que ella no quiere conseguir la información de un solo sitio y le gustarían otras opciones, pero para este caso, otros sitios probablemente no tengan la información idéntica y por lo tanto se mostrarán en los resultados. Tenga en cuenta que usted puede añadir el parámetro "*filter=0" al final de una búsqueda Google de web URL para ver los resultados adicionales que podrían ser similares.
Comentarios
11Lee otros artículos
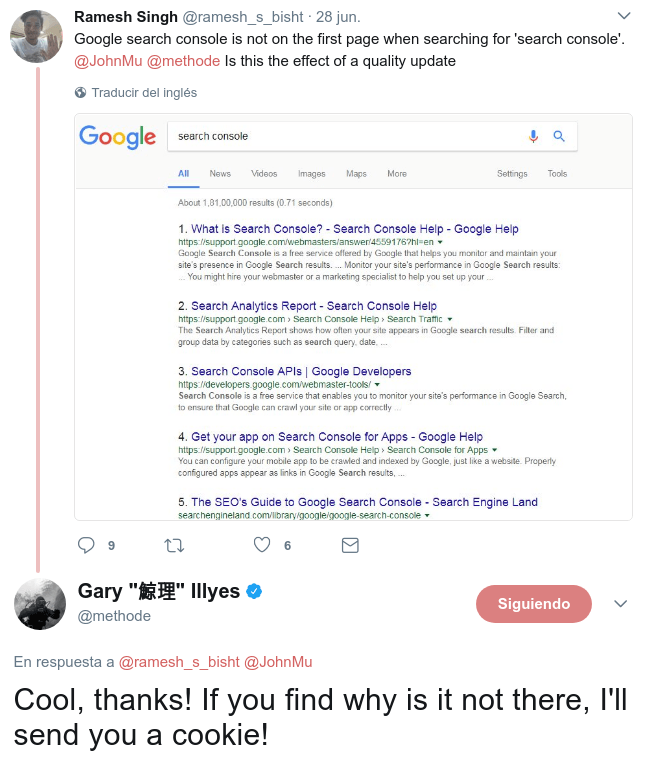
Descifrando mensajes ocultos de Google
Publicado el 14 de julio del 2017 por Lino Uruñuela El otro día, buscando algo con lo que entretenerme mientras estaba en el baño (sí, los botes de champú ya me los he leído todos.... tres veces) estaba inetntando resolver un reto lanzado por Gary Ullyes ( @methode ) a raíz de una pregunta de un twetero. ¿por qué Goog…
Cómo se presenta este 2015 para el mundo SEO
Publicado el 19 de enero del 2015 por Lino Uruñuela Este es el primer post del 2015, y vaticino que este año va a ser un año muy movido para los SEOs!! El segundo semestre del 2014 ha sido una auténtica locura, sobretodo a partir de Octubre y sin descanso por Navidades.... Este año habrá unos cuantos temas estrella pa…
Google se adelanta, celebra el dia de la mujer el 7 de marzo
Publicado el 7 de marzo del 2014, by Lino Uruñuela Ya sabemos que la gente de Google es muy visionaria y es capaz de adelantarse en el tiempo a muchas cosas, pero esta vez se han equivocado.... Hoy día 7 de Marzo nos ofrece un Doodle reivindicativo, un vídeo como homenaje a todas las mujeres, pero es que el día de la…
Los tiempos cambian, los periódicos se extinguen
Publicado el 6 de abr il del 2013 by Lino Uruñuela Hoy leo una noticia , o más bien debería llamarlo una opinión, sobre la tasa que se quiere imponer a Google por parte de algunos medios de comunicación europeos sobretodo los grandes periódicos. Desde hace bastantes años los periódicos van en declive, en mi opinión ha…
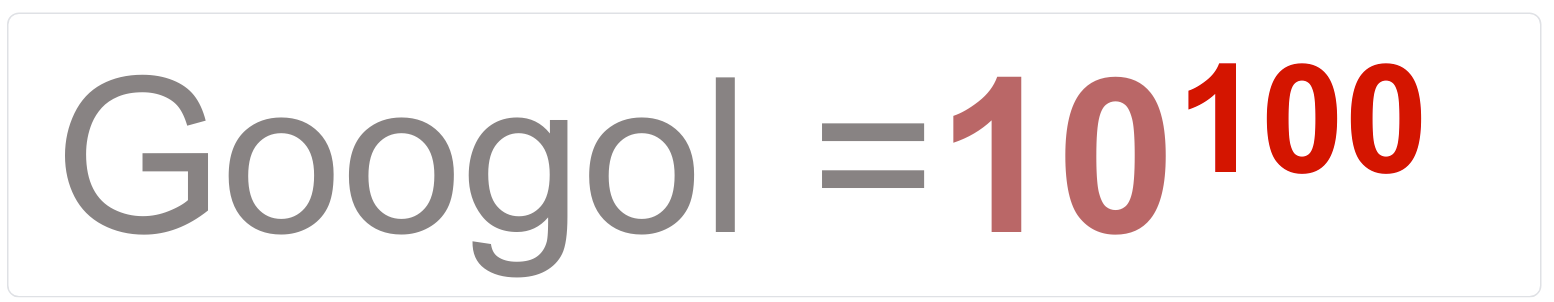
Representación visual de que es un Googol y Googolplex
Publicado el 21 de mayo del 2012 Como muchos ya saben la palabra Google que da nombre a nuestro Dios en la red proviene de Googol , que es el término que se le da a un uno seguido de cien ceros 1 googol = 10 100 Vamos a escribirlo aquí 10 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000…
Google da sonido a sus traducciones
Publicado el 12 de mayo del 2010 Siempre tuve interés en cómo se escucharía MeCagoEnLos.com en Griego y ya puedo hacerlo! Google ha sacado como parte de su traductor un sistema que le pone voz a las palabras. Así que si vemos esta búsqueda y le damos al icono de escuchar podremos ver cómo suena el nombre de este domin…
Google conmemora el 11M con una vela roja
Pues eso, Google recueda el 11M con una vela roja. He pillado esta captura de pantalla el día 10 de marzo a las 23:55 a veces sale y a veces no, supongo que a las 00:00 saldrá a todos en Google.es
Google se quita la autocensura en China
Google ha anunciado que quitará la autocensura que tenía en China y que le permitía operar en ese país. Bien por Google. Esto lo hace porque ha detectado ataques del gobierno chino a su servicio de correo Gmail, en un intento de sutraer información de personas perseguidas por el regimen dictatorial Chino, gente a favo…
GDrive, disco duro online
Publicado el 13 de enero del 2010 Una de las cosas que más tiempo lleva rumoreándose por la web es la de un servicio de Google llamado GDrive, el cual sería un disco duro virtual para los usuarios en los servidores de Google para el almacenamiento de cualquier tipo de documento, y posteriormente para la ejecución de c…
Google analizara 5 webs para SEO
Publicado el 17 de septiembre del 2009 ¿Quien será el afortunado al que Google le haga un seguimiento para la optimización on-page de su página? Yo creo que no... Acaban de anunciar , y de forma exclusiva para webs en idioma español, que Google hará con ejemplos reales de 3 a 5 webs un análisis de mejoras SEO on-page.…
A los puntos que indicas yo añadiria algunos más y que afectan a aquellos que mantienen sitios tipo portal con canales temáticos o verticales. Resulta que una misma noticia o reportaje puede ser publicada en uno o más canales debido a la existencia de un publico determinado que acude solamente a ese canal y no al conjunto del site. ¿Como solucionamos ese problema?
Lo primero en cada sitio que publiques la noticia que lleve un título, descripción y keys distintas. Lo segundo si se puede, que el html de la web no sean iguales. Lo tercero modificar algunas cosas en el código para que no sea completamente igual, por ejemplo en vez de separar párrafos con un tag "p" lo hacemos con tr, haciendo una nueva fila por parráfo, cosas así. Esto claro, si es que sea todo automático si no pues cambiar las palabras a mano para contar lo mismo :(
Gracias por tu aclaración sobre el contenido duplicado, pero creo que Google no entrega todas las herramientas para solucionar la distintas aristas de este tema. Actualmenten estoy trabajando para una empresa presente en varios países y que obviamente posee contenido duplicado bajo el mismo dominio. Podrías darme algunas directrices sobre cómo resolver el posicionamiento en estos casos. Al parecer, lo mejos es crear subdominos que incluyan los TLD de los países o dominios, aunque la duplicación de contendos obviamente no queda resuelta. SAludos
@pablo supongo que será en distintos idiomas ¿o es en el mismo idioma horientado a distintos países? <br><br> Lo mejor sería un dominio tld para cada país pero esto requiere más esfuerzo, se pueden usar carpetas también
Hola, me gusto lo que lei, anque no puedo escribe muy bien en español, pero queria preguntar si savias a donde puedo encuentrar a alguien que escriba informacion en español(Content writing) para una pagina que tengo, Gracias. -Ray
Como puedo notificar a google una empresa que tiene dos tiendas con dos dominios diferentes pero con el mismo contenido,misma direccion, mismo telefono, etc etc etc, ya que esto es pura codicia, porque teniendo una super bien posicionada, con la otra lo unico que hara es fastidiar a los demas, esto es ni comer ni dejar comer, creo que se deberian de parar estas situaciones, salvo que con la segunda tienda se lo curre con contenidos que no sean duplicados asi al menos tendra merito el posicionar la segunda tienda, de lo contrario todo el tema de posicionamento google toda la filosofia, criterios etc etc se van a desvanecer. Saludos Jordi
Muy buenas... No hace mucho que sigo esta web... Pero me parece muy interesante... En concreto, sobre este post, me gustaría saber si podemos usar las meta "Title, Description, Alt..." como keywords, o por el contrario esto se tacharía de spam y sería penalizado... Por ejemplo, si la web es de cereales... En keywords incluyo "cereales, nombre de la marca, ...,", y en una imagen incluyo un title="cereales, nombre de la marca, ...," Gracias, espero haberme explicado bien.
@David yo lo veo bien, eso si, si tienes 10 imágenes no le pongas a todas el mismo alt, variálo un poco para que sean únicos ;)
Hola! estoy desarrollando una plataforma para portales .travel, tenemos alrededor de 800. lo que hicimos fue una herramienta que permite configurar que contenidos carga cada portal, y cuando un entra a uno de los portales ej. a.travel, b.travel el portal se genera segun los contenidos configurados. teniendo esto en cuenta, van a haber varios portales iguales o muy similares, esto me podria penzalizar en google?
esmerate mas en los articulos que traduces al castellano
Hola, tengo una gran duda referente a este tema. ¿Como hacen entonces los blog que postean peliculas para descarga, si la descripcion de la pelicula es la misma, los textos y titulos? y sin embargo uno encuentra blogs de peliculas encabezando los primeros lugares en los resultados de busqueda. ¿Por qué ellos no nos penalizados? ¿qué tiene en cuenta google para ubicarlos en los primeros resultados de busqueda?