Evitar Contenido Duplicado
Muchos webmaster tienen la práctica de copiar contenido editado por otras páginas web y pegarlo directamente en la suya tal cual. Éste es un método para hacer una web sin esforzarse demasiado y poder obtener beneficios cuando haya copiado lo suficiente.
En principio desde un punto de vista informativo no está mal ya que es otra fuente más dando una noticia a la que alguien quiere acceder. El problema viene cuando copias información con claro ánimo de lucro y gana más el que copia que el que da la noticia.
Está claro que los buscadores cada vez saben detectar mejor que páginas son la fuente de la noticia y cuándo algún texto está copiado de otra página web, posicionando la primera en sus resultados. Pero hay muchos casos en lo que esto no es así y creadores de contenidos originales se ven desplazados por otras páginas que han copiado su noticia, artículo, etc.
Para eliminar este problema desde aquí me gustaría dar alguna idea a los buscadores como puede ser un sistema de autentificación de los contenidos. Este sistema podría ser un mecanismo de comunicación entre el webmaster y los buscadores ya sea en los sitemaps, haciendo un ping o simplemente pasárselo por medio de la URL, voy a poner un ejemplo:
Tengo una nueva noticia sobre los buscadores, y ya la redacté y se encuentra en la dirección
mecagoenlos.com/Posicionamiento/elcontenido-esel-rey.php
Pues podría ser algo como poner en la URL
google.com/?urlaut=https://www.mecagoenlos.com/Posicionamiento/elcontenido-esel-rey.php
Los buscadores en esa dirección deberían guardar la fecha y así ante la duda de que página mostrar en los resultados cuando se ha identificado contenido duplicado sabrían cuando fueron redactadas ambas noticias y cual es copia de cual.
Creo que esto sería un buen método para identificar el contenido duplicado y a ver si alguien es capaz de hacer que nos escuchen para que tomen medidas.
¿Se os ocurren más maneras de hacerlo?
Comentarios
4Lee otros artículos
¿Qué es SEO?
índice de contenido Definición de SEO SEO onPage SEO técnico Contenido del site SEO para imñagenes SEO nóvil Links internos JavaScript y SEO Resumen de los diferentes métodos que estamos probando Definición de SEO: SEO es la la capacidad de conseguir aparecer en los primeros resultados de los buscadores para determina…
Google aceptó mi regalo, por fin...
Publicado el 29 de diciembre del 2010 Siempre supe que este día llegaría, y que muchos de los experimentos aquí realizados dejarían de poder ser comprobrados transcurrido cierto tiempo. Y es que es lo que tiene hacer experimentos sobre un dominio llamado GoogleOffice.org que hasta ahora haía sido mio. No, no creáis qu…
Off Topic: prueba haciendo ping
Esta es una prueba para ver si Google entiende el ping que le hago desde mi CMS. A ver si indexa esto sesseyvpapdid Y si lo hace, a ver cuánto tarda.
Iniciando conexion
Publicado el 3 de enero del 2010 Hola de nuevo a todos los lectores que hayan tenido paciencia y no hayan borrado este blog de sus lectores de feeds por su poca acutalización ultimamente, pero esperemos que esto cambie este año. Llevo casi un mes desconectado, y a veces biene bien hacerlo para no perder el contacto co…
Muerte de Michael Jackson
Publicado el 26 de junio del 2009 Los que llevaban la campaña de marketing on-line de Michael Jackson deben estar de luto porque siguen ofrenciendo entradas para sus conciertos en anuncios AdWords. Noticia en El Mundo Tickets para su "próximo concierto" Y si es raro que se vendan cuando decían que estaban agotadas tod…
Off Topic: Google también se arrodilla ante la SGAE
Publicada el 25 de mayo del 2009 Una de las cosas que más me asombra en esta sociedad del Siglo XXI en la que vivimos, es que aún haya grupos de influencia que hagan arrodillarse a los más grandes a sus pies sin tener un ápice de razón en sus argumentos y teniendo a toda la opinión pública en contra. Es una de las úni…
Off Topic: Dile a la SGAE lo que quieras
Publicado el 7 de mayo del 2009 Ya vimos ayer la nueva funcionalidad que ha sacado Google en sus resultados , a parte de que podamos subir y bajar los resultados, también se pueden comentar. Se me ha venido a la cabeza... que podemos usar estos comentarios en las páginas webs para hacer ver a la SGAE, lo que pensamos…
Una vida nómada
Publicado el 26 de enero del 2009 Esta semana es una gran semana para mi porque me piro de Madrid ! Desde que empecé con mi vida nómada allá por 1999 cuando me fui a Salamanca a "estudiar" no he parado de viajar y vivir en distintos sitios, analizándolo bien creo que tengo un culo inquieto o más bien que no dejo pasar…

Off Topic: Solidaridad con Palestina
Publicado el 5 de enero del 2008 Para algunos hoy llegan los reyes magos, para otros los camellos, pero para casi 500.000 personas llegan las bombas y con ellas la muerte, la miseria y el dolor. Poco podemos hacer además de protestar para que esa gente que nos gobierna vea que hay un clamor popular que podría perjudic…
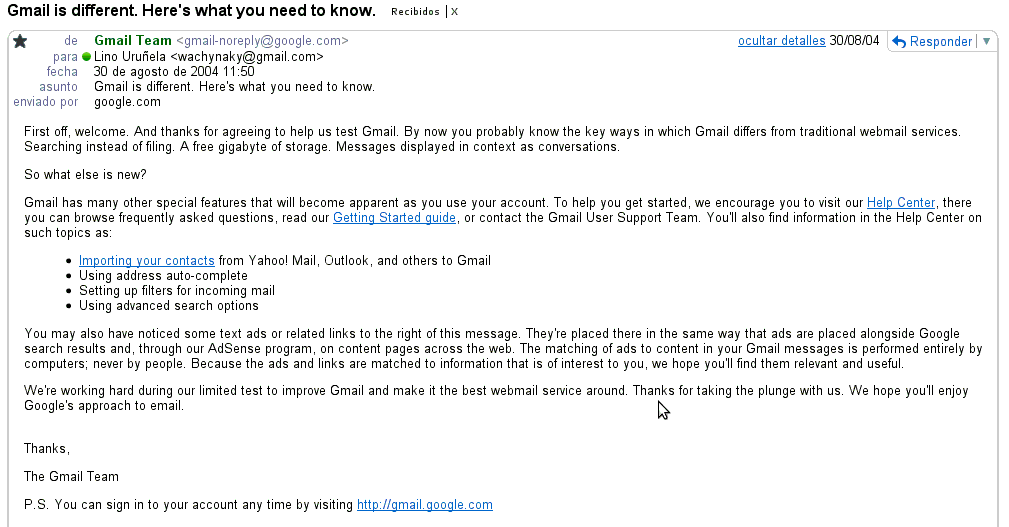
Mi primer correo de Gmail
Publicado el 4 de diciembre del 2008 Hoy mientras estaba mirando, que no leyendo, mi correo electrónico le he dado sin querer a "última página" en vez de a "Posterior" para ir a la página siguiente y me ha entrado la curiosidad de ver cuál era mi primer correo recibido en Gmail, allá por el 2004. El primer correo que…
A mi me pasa mucho. Tengo un blog sobre recursos online, que nunca ha llegado a funcionar bien en google, y me desespera ver gente que copia y pega mis artículos, aparece en google mucho antes que yo. En cuanto al tema de la fecha de los posts, creo que se debería hacer mediante los sitemaps de google. En los dos blogs que tengo, según escribo el post, lo primero que hago es reconstruir el sitemap y hacer un link a google sitemaps. Esta información debería servir a google para saber rápidamente qué contenido es el original y cual el copiado. saludos!
Ese puede ser el único método hoy en día, pero si cada vez que pubicas algo tienes que crear sitemaps y luego actualizarlo el tiempo que tardes tabién dependerá de la velocidad de Google cuando pase por tu web. De la otra manera sólo sería informarle mediante la URL y ya estaría, Google apuntaría la página, fecha y texto para cuando tenga dudas de qué contenido es el original.
es muy buena idea, ya me ha pasado ver como me copian toda mi web y la mia desaparece del mapa. algo deberian de hacer al respecto
Hola una vez crees la noticia compártelo en tantas redes sociales como puedas a si como también en marcadores e indexa la pagina con la herramienta de webmaster de google, google sabrá que es tuyo y eres el autor, aparte de todo esto te dará posicionamiento y visitas saludos