Otro META nuevo unavailable_after
Pues sí, unas cuantas neuronas mas ocupadas en mi cerebro por tener que memorizar otro META. Éste para decirle a Google cuando quremos que expire nuestro contenido y lo borre de sus resultados, !!está loco¡¡ con lo que cuesta crearlos. Yo no lo haría. Supongo que habrá casos muy puntuales en que les venga bien.
Ya soltaron en una conferencia hace poco en Inglaterra que iban a crear el unavailable_after, y hoy lo han publicado.
¿y por qué tienen interés en quitar páginas de sus servidores? igual es que andan escasos de espacio con tantas webs nuevas cada día...
También han anunciado que disponen de un método para que podamos decir a Google que archivos como Pdf, Word, XLS, etc.. no sean indexados o no sean mostrados en los resultados del buscador. En HTML ya podíamos usar un META para esto.
<meta name="robots" content="noindex,nofollow">
Pero en cualquier otro tipo de documento que no fuese HTML no podías decŕselo y Google que lo quiere todo, lo indexaba y mostraba si no le restringías el acceso por medio del robots.txt o por medio de contraseña en el directorio donde estuviera.
Ahora hay una nueva directiva en la cabecera Header que debemos enviársela si no queremos que algún documento sea indexado, por ejemplo así:
X-Robots-Tag: noarchive
X-Robots-Tag: unavailable_after: 23 Jul 2007 15:00:00 PST
Esto supone que tenemos que tener acceso a la configuración de nuestro servidor (archivo .htaccess) para poder controlar las solicitudes a determinadas extensiones de archivos.
Un ejemplo para enviar estas cabeceras para todos los documentos .doc .pdf sería escribir esto en el .htaccess de tu servidor: (no lo he probado porque parece que el .htaccess de mi hosting debo hacerlo desde el panel, otro día lo haré, pero debería fucionar)
<FilesMatch "\.(doc|pdf)$">
Header set X-Robots-Tag "noindex"
</FilesMatch>
Para hacerlo solamente para un fichero en concreto así:
<FilesMatch "nombre_archivo.doc$">
Header set X-Robots-Tag "noindex"
</FilesMatch>
Pero con este método no impedimos el que alguien teclee la ruta en la barra de direcciones y se descargue cualquier archivo. Para hacer esto en Apache estoy investigando.
En .Net hice algo parecido hace poco para que no se pudiesen descargar archivos por medio de la URL si no estaban autentificados por medio de un formulario y además tenías los permisos necesarios sobre ese archivo que yo comprobaba en mi base de datos, de esta manera aunque supieran o probaran suerte por medio de la URL no podían descargarlo. Por supuesto si no estaban logueados no podían descargarlo tampoco. Más o menos era así;
Primero tenías que configurar el servidor diciéndole que determinados archivos los tratase como archivos aspx. Entonces el servidor cada vez que haya una peticion http mirará por si ese tipo de archivo debe ser tratado como un aspx. Si es así, iría al Web.config donde pondremos
<httpHandlers>
<addverb="GET,POST"path="*.doc"
type="objeto.HttpHandler.downloadHandler,
objeto.MiHttpHandler/>
</httpHandlers>
y verá que DLL debe usar para tratar ese tripo de ficheros. Y si has llegado hasta aquí, no necesitarás enviar nada a Google porque si tu no quieres no le das acceso.
Aquí teneis una perfecta explicación para manejar los HttpHandlers con .Net
Pero en Apache no sé cómo hacerlo, no me sale
 . No
lo necesito porque documentos privados la verdad que no tengo, esto ya
es cabezonería. Pero puede ser muy importante para muchas páginas de
hospitales, ayuntamietos, etc, que guardan datos confidenciales y
deberían hacerlo todas, sin embargo la mayoría no lo hace y puedes
descargarte, si sabes o adivinas la ruta, todos sus documentos.
. No
lo necesito porque documentos privados la verdad que no tengo, esto ya
es cabezonería. Pero puede ser muy importante para muchas páginas de
hospitales, ayuntamietos, etc, que guardan datos confidenciales y
deberían hacerlo todas, sin embargo la mayoría no lo hace y puedes
descargarte, si sabes o adivinas la ruta, todos sus documentos.Lo ideal y lógico es no depender de Google para tener seguros tus datos confidenciales, y en este caso Google no lo pone tan fácil, porque hay que saber de programación y tener control sobre tu servidor.
Espero poder probarlo mañana y publico cómo es. También voy a hacer una prueba haciendo lo que dicen y poniendo un link para ver si lo lee.
Si alguien sabe como hacerlo en Apache que me lo diga, si no seguiré investigando. Creo que habría que modificar el .htaccess y poner algo así para redirigir las peticiones http cuando es a un archivo doc, mp3 o pdf
RewriteEngine on
RewriteCond %{QUERYSTRING} !^$
RewriteCond %{QUERYSTRING} !^http://([-a-z0-9]+\.)?mecagoenlos\.com[NC]
RewriteRule .*\.(doc|mp3|pdf)$ https://www.mecagoenlos.com/ [R,NC,L]
Pero a mi no me sale....
Lee otros artículos
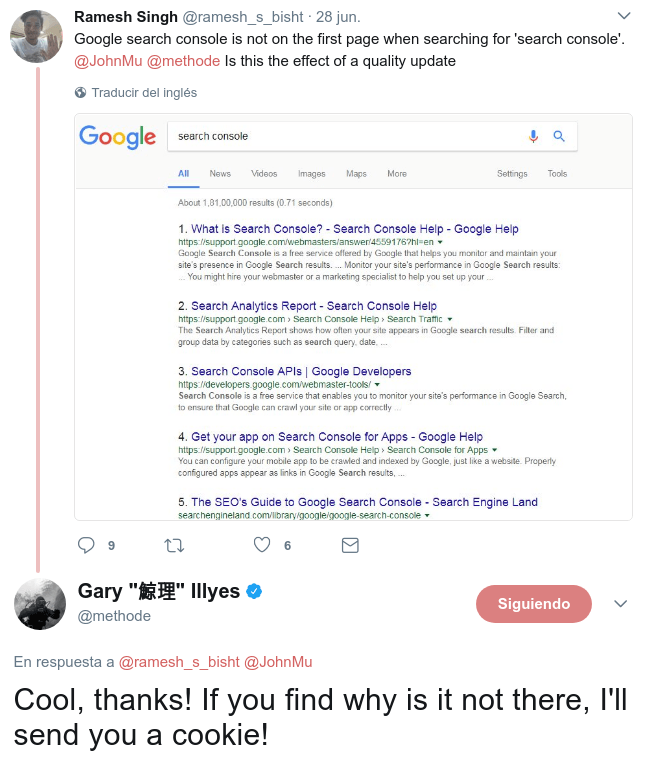
Descifrando mensajes ocultos de Google
Publicado el 14 de julio del 2017 por Lino Uruñuela El otro día, buscando algo con lo que entretenerme mientras estaba en el baño (sí, los botes de champú ya me los he leído todos.... tres veces) estaba inetntando resolver un reto lanzado por Gary Ullyes ( @methode ) a raíz de una pregunta de un twetero. ¿por qué Goog…
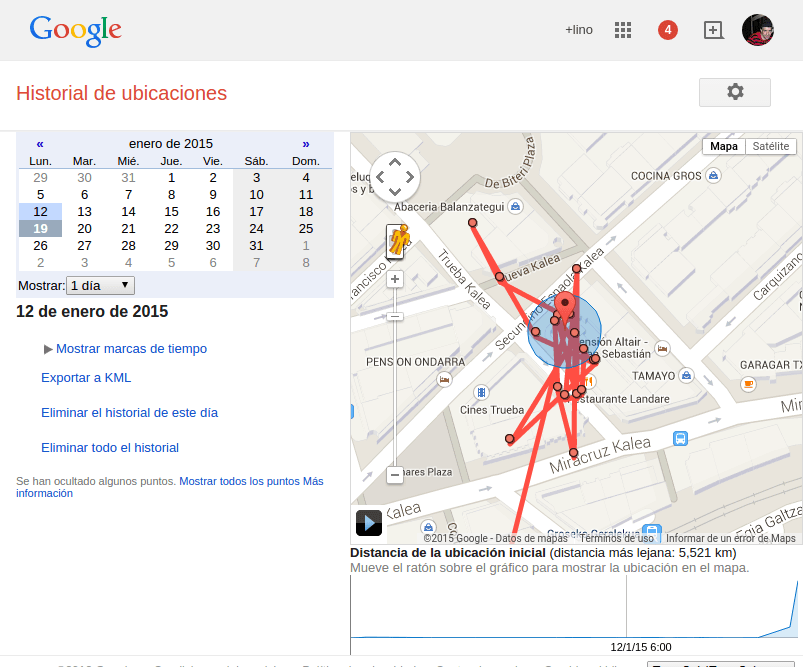
Cómo se presenta este 2015 para el mundo SEO
Publicado el 19 de enero del 2015 por Lino Uruñuela Este es el primer post del 2015, y vaticino que este año va a ser un año muy movido para los SEOs!! El segundo semestre del 2014 ha sido una auténtica locura, sobretodo a partir de Octubre y sin descanso por Navidades.... Este año habrá unos cuantos temas estrella pa…
Google se adelanta, celebra el dia de la mujer el 7 de marzo
Publicado el 7 de marzo del 2014, by Lino Uruñuela Ya sabemos que la gente de Google es muy visionaria y es capaz de adelantarse en el tiempo a muchas cosas, pero esta vez se han equivocado.... Hoy día 7 de Marzo nos ofrece un Doodle reivindicativo, un vídeo como homenaje a todas las mujeres, pero es que el día de la…
Los tiempos cambian, los periódicos se extinguen
Publicado el 6 de abr il del 2013 by Lino Uruñuela Hoy leo una noticia , o más bien debería llamarlo una opinión, sobre la tasa que se quiere imponer a Google por parte de algunos medios de comunicación europeos sobretodo los grandes periódicos. Desde hace bastantes años los periódicos van en declive, en mi opinión ha…
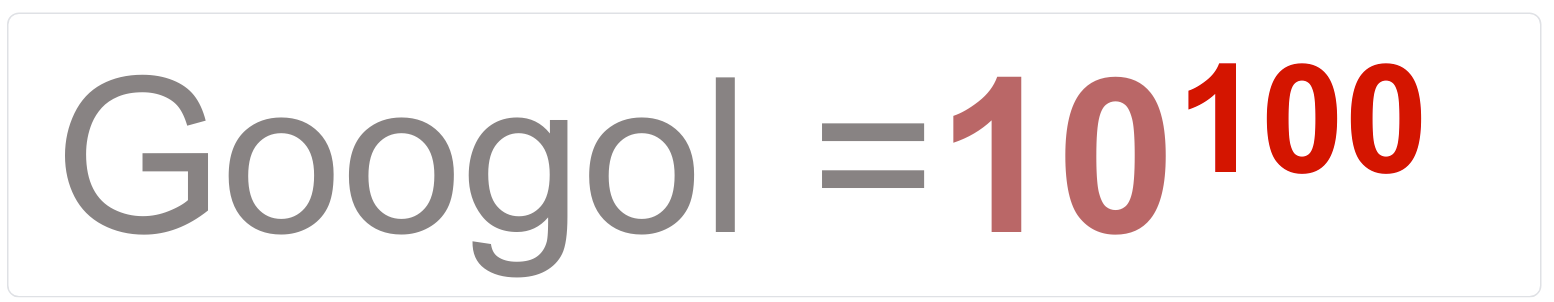
Representación visual de que es un Googol y Googolplex
Publicado el 21 de mayo del 2012 Como muchos ya saben la palabra Google que da nombre a nuestro Dios en la red proviene de Googol , que es el término que se le da a un uno seguido de cien ceros 1 googol = 10 100 Vamos a escribirlo aquí 10 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000…
Google da sonido a sus traducciones
Publicado el 12 de mayo del 2010 Siempre tuve interés en cómo se escucharía MeCagoEnLos.com en Griego y ya puedo hacerlo! Google ha sacado como parte de su traductor un sistema que le pone voz a las palabras. Así que si vemos esta búsqueda y le damos al icono de escuchar podremos ver cómo suena el nombre de este domin…
Google conmemora el 11M con una vela roja
Pues eso, Google recueda el 11M con una vela roja. He pillado esta captura de pantalla el día 10 de marzo a las 23:55 a veces sale y a veces no, supongo que a las 00:00 saldrá a todos en Google.es
Google se quita la autocensura en China
Google ha anunciado que quitará la autocensura que tenía en China y que le permitía operar en ese país. Bien por Google. Esto lo hace porque ha detectado ataques del gobierno chino a su servicio de correo Gmail, en un intento de sutraer información de personas perseguidas por el regimen dictatorial Chino, gente a favo…
GDrive, disco duro online
Publicado el 13 de enero del 2010 Una de las cosas que más tiempo lleva rumoreándose por la web es la de un servicio de Google llamado GDrive, el cual sería un disco duro virtual para los usuarios en los servidores de Google para el almacenamiento de cualquier tipo de documento, y posteriormente para la ejecución de c…
Google analizara 5 webs para SEO
Publicado el 17 de septiembre del 2009 ¿Quien será el afortunado al que Google le haga un seguimiento para la optimización on-page de su página? Yo creo que no... Acaban de anunciar , y de forma exclusiva para webs en idioma español, que Google hará con ejemplos reales de 3 a 5 webs un análisis de mejoras SEO on-page.…
Comentarios
Todavía no hay comentarios publicados.