Prueba con ficheros txt
Publicado el 10 de octubre del 2012, by Lino Uruñuela
Desde hace bastante tiempo tengo una duda sobre cómo valora Google los distintos tipos de documentos, HTML, PDF, Flash, txt.
Con los documentos PDF ya he realizado alguna prueba, no sacando nada concluyente en cuanto a que prefiere, sí sacamos en claro que los links en esos documentos cuentan. Pensando lógicamente, veo que en los resultados Google a veces muestra resultados de documentos PDF, cosa que no suele ocurrir con txt, por lo que creo que no los tiene muy bien valorados.

Desde hace bastante tiempo tengo una duda sobre cómo valora Google los distintos tipos de documentos, HTML, PDF, Flash, txt.
Con los documentos PDF ya he realizado alguna prueba, no sacando nada concluyente en cuanto a que prefiere, sí sacamos en claro que los links en esos documentos cuentan. Pensando lógicamente, veo que en los resultados Google a veces muestra resultados de documentos PDF, cosa que no suele ocurrir con txt, por lo que creo que no los tiene muy bien valorados.
¿Para que probar si Google valora más un txt o un HTML?.
A priori supongo que preferirá un documento HTML, ya que al ser un formato de hipertexto es muy probable que tenga más cosas que aportar al usuario. Muchos de estos txt provienen de un archivo PDF, depende del tema que busques encontrarás este tipo de txt que proviene de pdf (como es el caso de universidades que no sé cómo lo hacen pero indexan el txt y no el PDF) y otros muchos txt que son listas de correo, datos del boe y otro sin fín de documentos olvidados por la mano de dios.
Vamos a buscar un documento de texto, ya que estamos, sigamos con la marihuana, por ejemplo de esta búsqueda (he añadido el -filetype:pdf sin darme cuenta de la inutilidad de ese parámetro ya que en el anterior le digo que sólo quiero TXT, pero por no cambiar la imagen de abajo, lo dejo así) como veís voy a coger el siguiente resultado para hacer esta prueba, os lo muestro con una imagen para no enlazarlo desde aquí y así no influír en el experimento.
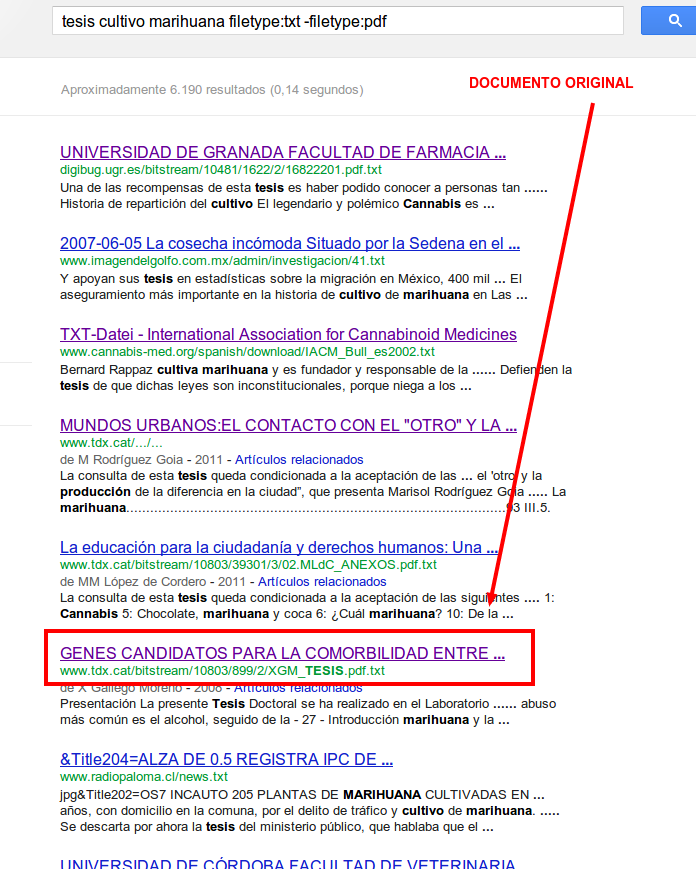
Acciones realizadas
Mi idea es que para la búsqueda del título se posicione el copiado antes que el original, en este caso la url de la web que linka al pdf, que es la que sale la primera, aunque realmente esa página no contiene la tesis :).
Si fuese así, para los que practican black hat SEO puede ser un filón, ya que documentos txt indexados hay de todos los temas, así que podría considerarse "contenido casi gratis", pero como siempre digo se corre un riesgo, así que yo no lo haría en una web que quieras que tenga futuro.
A priori supongo que preferirá un documento HTML, ya que al ser un formato de hipertexto es muy probable que tenga más cosas que aportar al usuario. Muchos de estos txt provienen de un archivo PDF, depende del tema que busques encontrarás este tipo de txt que proviene de pdf (como es el caso de universidades que no sé cómo lo hacen pero indexan el txt y no el PDF) y otros muchos txt que son listas de correo, datos del boe y otro sin fín de documentos olvidados por la mano de dios.
Vamos a buscar un documento de texto, ya que estamos, sigamos con la marihuana, por ejemplo de esta búsqueda (he añadido el -filetype:pdf sin darme cuenta de la inutilidad de ese parámetro ya que en el anterior le digo que sólo quiero TXT, pero por no cambiar la imagen de abajo, lo dejo así) como veís voy a coger el siguiente resultado para hacer esta prueba, os lo muestro con una imagen para no enlazarlo desde aquí y así no influír en el experimento.
Acciones realizadas
He copiado el documento y le he dado sólo unos saltos de línea.
El documento lo he publicado y lo podemos ver aquí, es el primer resultado, no lo quiero linkar desde aqiuí
Mi idea es que para la búsqueda del título se posicione el copiado antes que el original, en este caso la url de la web que linka al pdf, que es la que sale la primera, aunque realmente esa página no contiene la tesis :).
Si fuese así, para los que practican black hat SEO puede ser un filón, ya que documentos txt indexados hay de todos los temas, así que podría considerarse "contenido casi gratis", pero como siempre digo se corre un riesgo, así que yo no lo haría en una web que quieras que tenga futuro.
