El valor de los logs para el SEO
Publicado el martes 6 de septiembre del 2016 por Lino Uruñuela
Hace poco escribí el primero de una serie de post sobre el uso de Logs, Big Data y gráficas, en este caso continúo el análisis de la bajada que comenzamos a ver en Seo y logs (primera parte): Monitorización de Googlebot mediante logs , una caída importante en el tráfico orgánico del site sin que hubiesen cambios aparentes en el algoritmo de Google.
Vamos a ponernos en antecedentes para refrescar un poco la memoria.
Si había algo bueno en toda esta hecatombe es que al menos sabíamos qué estaba ocurriendo, y por lo tanto, podríamos pensar en cómo solucionar esos errores e intentar mitigar la caída todo lo posible.
Ahí nos dimos cuenta que esto se había producido por el caos de urls que había en la arquitectura del site, ya que la web tiene mucha historia y salían bichos de debajo de cada byte que movías... Las webs grandes y medianamente antiguas tienden a acumular mierda como si fuesen fans del mismísimo Diógenes.

Lo que hicimos fue dejarnos de parches aquí o allá y cogimos el toro por los cuernos. Vimos, y aceptamos, el grave problema que había en cuanto a la arquitectura y que si queríamos llevar esto a buen puerto deberíamos de ser más radicales y comenzar a diseñar la arquitectura de información, a pensar las urls indexables y las que no, a agrupar urls por el problema que tuviesen y a valorar y decidir qué hacer con cada grupo de urls con errores.
A parte de que más de 20.000 urls dieran error, o que casi 100.000 urls respondían un 200 cuando no debían haberse creado, ya tenían de por sí sus propios problemas. Típicas cosillas de sites con antigüedad... que si hace nos sé cuántos años creamos así las urls, luego asá...
Pero claro, hasta que un día saltó el muelle y al programador se le escapó algo erróneo en producción (cosa totalmente normal viendo lo que había) y la líada fue parda,, como diría aquella chavalilla punki después de quemar su escuela....
Pero para punkis www.FunnelPunk.com, nos remangamos, nos pusimos las gafas de científicos y fuimos uno a uno solucionando como mejor creímos los grupos de problemas/urls que teníamos.
En este caso concreto, no nos hacía falta saber desde donde se producían esas urls erróneas, era cosa nuestra en el enlazado interno y las distintas lógicas que a lo largo de los años había sufrido el site. Así que nos centramos en revisar toda la lógica, hacer las redirecciones correctas y voilá! poco a poco fuimos recuperando el tráfico perdido.
Era inviable seguir definiendo parches, ya que tarde o temprano algún técnico se iba a confundir, era inevitable y eso nos hizo afrontar esto de cara, sin parches. Pensamos en qué segmentos y qué facetas queríamos indexar y potenciar, todo ello en base a los datos de tráfico y crawleo de GoogleBot durante su pèriodo normal, no durante el caos.
Una vez tuvimos claro esto, nos pusimos a pensar qué hacer con los grupos de errores que había, si merecían o no la pena redirigirlo, si debíamos restringir el acceso mediante robots.txt, si le metíamos canonical allí o aquí, etc.
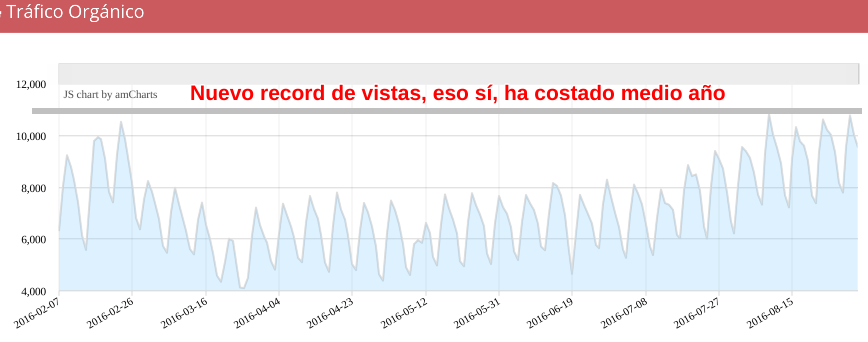
Parece fácil, pero no lo es, es un duro trabajo, y nada divertido debido a que la cagada había sido bien grande.. pero bueno, al ver la recuperación del site, que hoy bate récords de visitas en su historia, estamos orgullosos (yo por lo menos ;) ) del trabajo que estamos haciendo, y de ver que los tres en FunnelPunk (Natzir, Dani y yo), hemos conseguido un reto que es de los mayores en este juego de la Ginkana SEO, de los bomberos apagafuegos...
Espero que os haya gustado este post y bienvenida cualquier aportación , idea o duda.. vamos, que a ver si alguien se digna a comentar :p.
En los siguientes artículos seguiré con la serie de posts sobre crawleo, logs y bots
Hace poco escribí el primero de una serie de post sobre el uso de Logs, Big Data y gráficas, en este caso continúo el análisis de la bajada que comenzamos a ver en Seo y logs (primera parte): Monitorización de Googlebot mediante logs , una caída importante en el tráfico orgánico del site sin que hubiesen cambios aparentes en el algoritmo de Google.
Vamos a ponernos en antecedentes para refrescar un poco la memoria.
- Un día concreto, el 23 de febrero, el mismo día que el site batía récord de tráfico orgánico, comenzó la gran odisea, bajando el tráfico orgánico en un 30% con respecto a la semana anterior.
La línea roja es el tráfico orgánico del site, y las guías verticales son implementaciones y desarrollos técnicos en la web.

- Al analizar el comportamiento de GoogleBot en el site nos dimos cuenta que justo el día del récord en tráfico en el site comenzaba la odisea, y comenzamos a dar errores 410 en miles de urls, cuando lo habitual eran menos de 10 .
En esta gráfica y en las siguientes el área azul representa el tráfico orgánico

- Además, las urls que estaban generando estos miles de errores 410 eran las secciones más importantes del site, y que aportaban un amplio porcentaje del tráfico orgánico, por lo que el impacto fue importante. más de un 30% del tráfico se perdió en una semana.

- Por si fuese poco, ahora le iba a tocar el turno a los errores 404, siendo más de 20.000 las urls que arrojaban 404.
Por lo menos esta vez el segmento más importante del site no estaba afectado, ya había tenido bastante con los 410... pero sí se vio afectado el segundo segmento más importante, y en mayor medida todavía el tercero, que no aportaba tanto tráfico como los otros dos, pero que tenía muchísimas más urls.
El tráfico orgánico sigue cayendo.

- Para colmo, también las urls con código de estatus 200 rastreables e indexables llegaron casi a las 150.000 en un solo día, cuando lo normal venía siendo una media de 10.000 urls al día, con sus picos pero por ahí rondaba. Ya lo teníamos todo, sin querer, habíamos quintuplicado las urls del site dando errores y páginas sin contenido.

Si había algo bueno en toda esta hecatombe es que al menos sabíamos qué estaba ocurriendo, y por lo tanto, podríamos pensar en cómo solucionar esos errores e intentar mitigar la caída todo lo posible.
Ahí nos dimos cuenta que esto se había producido por el caos de urls que había en la arquitectura del site, ya que la web tiene mucha historia y salían bichos de debajo de cada byte que movías... Las webs grandes y medianamente antiguas tienden a acumular mierda como si fuesen fans del mismísimo Diógenes.
Comenzamos a solucionarlo
Como es lógico, desde el primer momento estuvimos pensando cómo solucionar esto, y ahí es cuando uno se da cuenta del valor que tienen los logs para el SEO, sin análisis de logs hubiéramos estado vendidos, o al menos nos hubiera costado mucho más esfuerzo y horas. Lo que venía a continuación iba a ser más parecido a un análisis forense que un trabajo de "informáticos".
OjO con los 410
Dar miles de errores 410 donde no se debe, se paga, y muy caro,. Creo que es una de las lecciones más valiosas que hemos aprendido, pero teníamos datos, una tool a medida hecha por nosotros, una gran preocupación y muchos, muchos frentes abiertos.Lo que hicimos fue dejarnos de parches aquí o allá y cogimos el toro por los cuernos. Vimos, y aceptamos, el grave problema que había en cuanto a la arquitectura y que si queríamos llevar esto a buen puerto deberíamos de ser más radicales y comenzar a diseñar la arquitectura de información, a pensar las urls indexables y las que no, a agrupar urls por el problema que tuviesen y a valorar y decidir qué hacer con cada grupo de urls con errores.
A parte de que más de 20.000 urls dieran error, o que casi 100.000 urls respondían un 200 cuando no debían haberse creado, ya tenían de por sí sus propios problemas. Típicas cosillas de sites con antigüedad... que si hace nos sé cuántos años creamos así las urls, luego asá...
Pero claro, hasta que un día saltó el muelle y al programador se le escapó algo erróneo en producción (cosa totalmente normal viendo lo que había) y la líada fue parda,, como diría aquella chavalilla punki después de quemar su escuela....
Pero para punkis www.FunnelPunk.com, nos remangamos, nos pusimos las gafas de científicos y fuimos uno a uno solucionando como mejor creímos los grupos de problemas/urls que teníamos.
En este caso concreto, no nos hacía falta saber desde donde se producían esas urls erróneas, era cosa nuestra en el enlazado interno y las distintas lógicas que a lo largo de los años había sufrido el site. Así que nos centramos en revisar toda la lógica, hacer las redirecciones correctas y voilá! poco a poco fuimos recuperando el tráfico perdido.
Era inviable seguir definiendo parches, ya que tarde o temprano algún técnico se iba a confundir, era inevitable y eso nos hizo afrontar esto de cara, sin parches. Pensamos en qué segmentos y qué facetas queríamos indexar y potenciar, todo ello en base a los datos de tráfico y crawleo de GoogleBot durante su pèriodo normal, no durante el caos.
Una vez tuvimos claro esto, nos pusimos a pensar qué hacer con los grupos de errores que había, si merecían o no la pena redirigirlo, si debíamos restringir el acceso mediante robots.txt, si le metíamos canonical allí o aquí, etc.
Parece fácil, pero no lo es, es un duro trabajo, y nada divertido debido a que la cagada había sido bien grande.. pero bueno, al ver la recuperación del site, que hoy bate récords de visitas en su historia, estamos orgullosos (yo por lo menos ;) ) del trabajo que estamos haciendo, y de ver que los tres en FunnelPunk (Natzir, Dani y yo), hemos conseguido un reto que es de los mayores en este juego de la Ginkana SEO, de los bomberos apagafuegos...
Espero que os haya gustado este post y bienvenida cualquier aportación , idea o duda.. vamos, que a ver si alguien se digna a comentar :p.
En los siguientes artículos seguiré con la serie de posts sobre crawleo, logs y bots

David barrera (@madridseo)hace Hace más de 7 años y 231 días
Maquinón! Gracias por el post.. la verdad es que no miro los logs, quizá porque no me ha surgido.. pero quiero pedirte un favor, si quieres por privado.. explicar un poco como podría revisar un log sin ese programa a medida.. un poco para bichear :D
Gracias y enhorabuena por ese levantamiento!
Errioxa (@)hace Hace más de 7 años y 231 días
@David barrena escribí hace tiempo un par de post que igual te pueden ayudar.
Este para hacerlo desde la consola de tu ordenador
Y este para hacerlo con Google Analytics.
Saludos!
David barrera (@madridseo)hace Hace más de 7 años y 230 días
Muchas gracias!!! :)
Lino (@funnelpunk)hace Hace más de 4 años y 34 días
@errioxa probando desde comentarios del site :)